
Hadoop と Spark: 直接比較
公開: 2022-11-02Apache Software Foundation によって開発された Hadoop と Spark は、ビッグ データ アーキテクチャに広く使用されているオープンソース フレームワークです。
現在、私たちはまさにビッグデータ現象の中心にいて、企業はデータが意思決定に与える影響をもはや無視することはできません。
ビッグデータと見なされるデータは、速度、速度、多様性の 3 つの基準を満たしていることに注意してください。 ただし、従来のシステムやテクノロジーではビッグデータを処理できません。
この問題を克服する目的で、Apache Software Foundation は最も使用されているソリューション、すなわち Hadoop と Spark を提案しました。
しかし、ビッグデータ処理に慣れていない人は、これら 2 つの技術を理解するのに苦労します。 すべての疑問を解消するために、この記事では、Hadoop と Spark の主な違いと、どちらを選択するか、またはそれらを一緒に使用する必要があるかについて説明します。
Hadoop
Hadoop は、ビッグ データを処理するためのエコシステムを形成する複数のモジュールで構成されるソフトウェア ユーティリティです。 Hadoop がこの処理に使用する原則は、データを分散分散して並列処理することです。

Hadoop の分散ストレージ システムのセットアップは、複数の通常のコンピューターで構成され、複数のノードのクラスターを形成します。 このシステムを採用することで、Hadoop は複数のタスクを同時に、迅速かつ効率的に実行することで、大量の利用可能なデータを効率的に処理できるようになります。
Hadoop で処理されるデータには、さまざまな形式があります。 これらは、Excel テーブルまたは従来の DBMS のテーブルのように構造化できます。 このデータは、JSON ファイルや XML ファイルなど、半構造化された方法で表示することもできます。 Hadoop は、画像、動画、音声ファイルなどの非構造化データもサポートしています。
メインコンポーネント
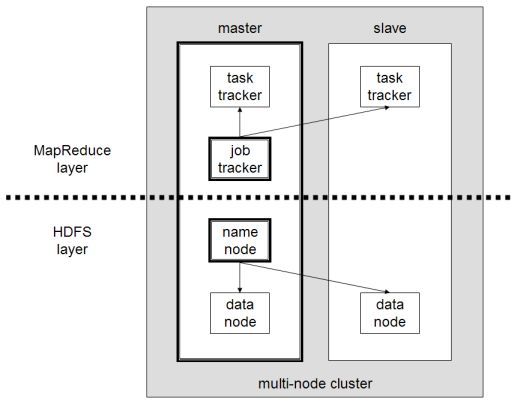
Hadoop の主なコンポーネントは次のとおりです。
- HDFSまたは Hadoop 分散ファイル システムは、Hadoop が分散データ ストレージを実行するために使用するシステムです。 これは、クラスター メタデータを含むマスター ノードと、データ自体が格納されるいくつかのスレーブ ノードで構成されます。
- MapReduceは、この分散データを処理するために使用されるアルゴリズム モデルです。 この設計パターンは、Java、R、Scala、Go、JavaScript、Python などのいくつかのプログラミング言語を使用して実装できます。 各ノード内で並行して実行されます。
- Hadoop Common 。いくつかのユーティリティとライブラリが他の Hadoop コンポーネントをサポートします。
- YARNは、Hadoop クラスター上のリソースと各ノードで実行されるワークロードを管理するためのオーケストレーション ツールです。 また、このフレームワークのバージョン 2.0 以降の MapReduce の実装もサポートしています。
アパッチスパーク

Apache Spark は、2009 年にコンピューター科学者の Matei Zaharia が博士課程の一環として最初に作成したオープンソース フレームワークです。その後、2010 年に Apache Software Foundation に参加しました。
Spark は、複数のノードに分散された計算およびデータ処理エンジンです。 Spark の主な特徴は、インメモリ処理を実行することです。つまり、RAM を使用してクラスター内に分散された大きなデータをキャッシュおよび処理します。 これにより、パフォーマンスが向上し、処理速度が大幅に向上します。

Spark は、バッチ処理、リアル ストリーム処理、機械学習、グラフ計算など、いくつかのタスクをサポートしています。 HDFS、RDBMS、さらには NoSQL データベースなど、複数のシステムからのデータを処理することもできます。 Spark の実装は、Scala や Python などのいくつかの言語で行うことができます。
メインコンポーネント
Apache Spark の主なコンポーネントは次のとおりです。
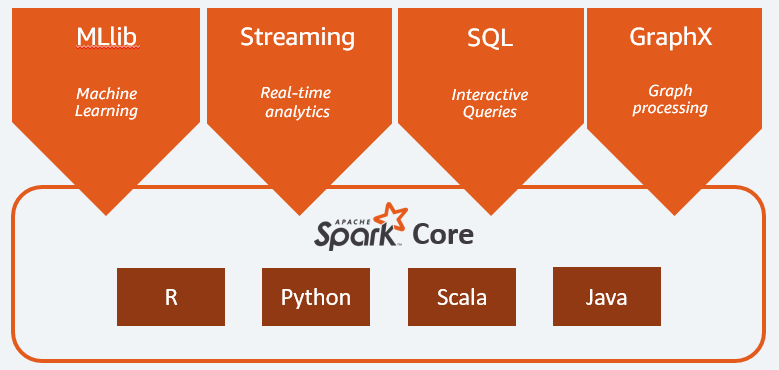
- Spark Coreは、プラットフォーム全体の一般的なエンジンです。 タスクの計画と配布、入出力操作の調整、または故障からの回復を担当します。
- Spark SQLは、構造化データと半構造化データをサポートする RDD スキーマを提供するコンポーネントです。 特に、SQL を実行するか、SQL エンジンへのアクセスを提供することにより、構造化された型データの収集と処理を最適化することができます。
- ストリーミング データ分析を可能にするSpark Streaming 。 Spark Streaming は、Flume、Kinesis、Kafka などのさまざまなソースからのデータをサポートします。
- MLib 、機械学習用の Apache Spark の組み込みライブラリ。 いくつかの機械学習アルゴリズムと、機械学習パイプラインを作成するためのいくつかのツールを提供します。
- GraphXは、分散アーキテクチャ内でモデリング、計算、およびグラフ分析を実行するための一連の API を組み合わせたものです。
Hadoop と Spark: 違い

Spark は、ビッグ データの計算およびデータ処理エンジンです。 したがって、理論的には、Hadoop MapReduce に少し似ており、インメモリで実行されるため、はるかに高速です。 それでは、Hadoop と Spark の違いは何でしょうか? みてみましょう:

- Spark は、特にメモリ内処理のおかげではるかに効率的ですが、Hadoop はバッチで処理されます。
- Spark は、パフォーマンスを維持するために大量の RAM を必要とするため、コストの点ではるかに高価です。 一方、Hadoop はデータ処理を通常のマシンにのみ依存します。
- Hadoop はバッチ処理により適していますが、Spark はストリーミング データまたは非構造化データ ストリームを処理する場合に最も適しています。
- Hadoop は継続的にデータをレプリケートするため、耐障害性に優れていますが、Spark はそれ自体が HDFS に依存する回復力のある分散データセット (RDD) を使用します。
- Hadoop は、既存のマシンでは不十分な場合にのみ別のマシンを追加する必要があるため、よりスケーラブルです。 Spark は、HDFS などの他のフレームワークのシステムに依存して拡張します。
| 要素 | Hadoop | スパーク |
| 処理 | バッチ処理 | インメモリ処理 |
| ファイル管理 | HDFS | Hadoop の HDFS を使用 |
| スピード | 速い | 10~1000倍高速 |
| 言語サポート | Java、Python、Scala、R、Go、JavaScript | Java、Python、Scala、R |
| 耐障害性 | より寛容 | 寛容度が低い |
| 料金 | より安価な | もっと高い |
| スケーラビリティ | よりスケーラブル | スケーラビリティが低い |
Hadoop は次の用途に適しています
処理速度が重要でない場合、Hadoop は優れたソリューションです。 たとえば、データ処理が一晩でできる場合は、Hadoop の MapReduce の使用を検討するのが理にかなっています。
Hadoop を使用すると、処理が比較的困難なデータ ウェアハウスから大規模なデータセットをオフロードできます。Hadoop の HDFS により、組織はデータをより適切に保存および処理できます。
Spark は次の用途に適しています。
Spark の回復力のある分散データセット (RDD) は、複数のメモリ内マップ操作を可能にしますが、Hadoop MapReduce は中間結果をディスクに書き込む必要があるため、リアルタイムのインタラクティブなデータ分析を行う場合は、Spark が推奨されるオプションになります。
Spark のメモリ内処理と Cassandra や MongoDB などの分散データベースのサポートは、データの移行と挿入 (ソース データベースからデータを取得して別のターゲット システムに送信する場合) の優れたソリューションです。
Hadoop と Spark の併用

多くの場合、Hadoop と Spark のどちらかを選択する必要があります。 ただし、ほとんどの場合、これら 2 つのフレームワークは非常にうまく共存して連携できるため、選択する必要はありません。 実際、Spark の開発の背後にある主な理由は、Hadoop を置き換えるのではなく、強化することでした。
前のセクションで説明したように、Spark は HDFS ストレージ システムを使用して Hadoop と統合できます。 実際、どちらも分散環境内でより高速なデータ処理を実行します。 同様に、Hadoop にデータを割り当て、Spark を使用して処理したり、Hadoop MapReduce 内でジョブを実行したりできます。
結論
Hadoop か Spark か? フレームワークを選択する前に、アーキテクチャを検討する必要があり、それを構成するテクノロジは、達成したい目的と一致している必要があります。 さらに、Spark は Hadoop エコシステムと完全に互換性があり、Hadoop Distributed File System および Apache Hive とシームレスに連携します。
また、いくつかのビッグ データ ツールを探索することもできます。