
Hadoop vs Spark: Perbandingan Head-to-Head
Diterbitkan: 2022-11-02Hadoop dan Spark, keduanya dikembangkan oleh Apache Software Foundation, banyak digunakan kerangka kerja sumber terbuka untuk arsitektur data besar.
Kami benar-benar berada di jantung fenomena Big Data saat ini, dan perusahaan tidak dapat lagi mengabaikan dampak data pada pengambilan keputusan mereka.
Sebagai pengingat, data yang dianggap Big Data memenuhi tiga kriteria: kecepatan, kecepatan, dan variasi. Namun, Anda tidak dapat memproses Big Data dengan sistem dan teknologi tradisional.
Untuk mengatasi masalah ini Apache Software Foundation telah mengusulkan solusi yang paling sering digunakan, yaitu Hadoop dan Spark.
Namun, orang yang baru mengenal pemrosesan data besar mengalami kesulitan memahami kedua teknologi ini. Untuk menghilangkan semua keraguan, dalam artikel ini, pelajari perbedaan utama antara Hadoop dan Spark dan kapan Anda harus memilih satu atau yang lain, atau menggunakannya bersama-sama.
hadoop
Hadoop adalah utilitas perangkat lunak yang terdiri dari beberapa modul yang membentuk ekosistem untuk memproses Big Data. Prinsip yang digunakan Hadoop untuk pemrosesan ini adalah distribusi data yang terdistribusi untuk memprosesnya secara paralel.

Pengaturan sistem penyimpanan terdistribusi Hadoop terdiri dari beberapa komputer biasa, sehingga membentuk sekelompok beberapa node. Mengadopsi sistem ini memungkinkan Hadoop untuk secara efisien memproses sejumlah besar data yang tersedia dengan melakukan banyak tugas secara bersamaan, cepat, dan efisien.
Data yang diproses dengan Hadoop dapat mengambil banyak bentuk. Mereka dapat disusun seperti tabel Excel atau tabel dalam DBMS konvensional. Data ini juga dapat disajikan dengan cara semi-terstruktur, seperti file JSON atau XML. Hadoop juga mendukung data tidak terstruktur seperti gambar, video, atau file audio.
Komponen utama
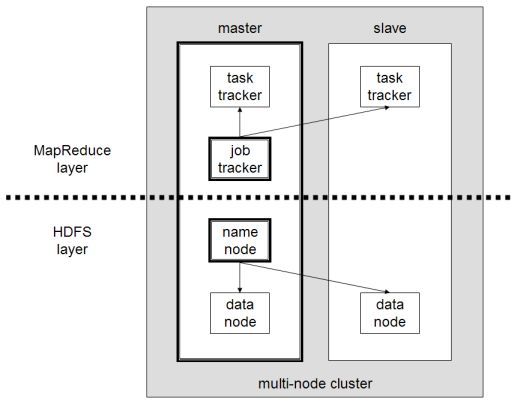
Komponen utama Hadoop adalah:
- HDFS atau Hadoop Distributed File System adalah sistem yang digunakan Hadoop untuk melakukan penyimpanan data terdistribusi. Ini terdiri dari node master yang berisi metadata cluster dan beberapa node slave di mana data itu sendiri disimpan;
- MapReduce adalah model algoritmik yang digunakan untuk memproses data terdistribusi ini. Pola desain ini dapat diimplementasikan dengan menggunakan beberapa bahasa pemrograman, seperti Java, R, Scala, Go, JavaScript atau Python. Ini berjalan dalam setiap node secara paralel;
- Hadoop Common , di mana beberapa utilitas dan perpustakaan mendukung komponen Hadoop lainnya;
- YARN adalah alat orkestrasi untuk mengelola sumber daya di cluster Hadoop dan beban kerja yang dilakukan oleh setiap node. Ini juga mendukung implementasi MapReduce sejak versi 2.0 dari kerangka kerja ini.
Apache Spark

Apache Spark adalah kerangka kerja sumber terbuka yang awalnya dibuat oleh ilmuwan komputer Matei Zaharia sebagai bagian dari gelar doktornya pada tahun 2009. Ia kemudian bergabung dengan Apache Software Foundation pada tahun 2010.
Spark adalah mesin penghitung dan pemrosesan data yang didistribusikan secara terdistribusi ke beberapa node. Kekhususan utama Spark adalah ia melakukan pemrosesan dalam memori, yaitu menggunakan RAM untuk menyimpan dan memproses data besar yang didistribusikan di cluster. Ini memberikan kinerja yang lebih tinggi dan kecepatan pemrosesan yang jauh lebih tinggi.

Spark mendukung beberapa tugas, termasuk pemrosesan batch, pemrosesan aliran nyata, pembelajaran mesin, dan komputasi grafik. Kami juga dapat memproses data dari beberapa sistem, seperti HDFS, RDBMS atau bahkan database NoSQL. Implementasi Spark dapat dilakukan dengan beberapa bahasa seperti Scala atau Python.
Komponen utama
Komponen utama Apache Spark adalah:
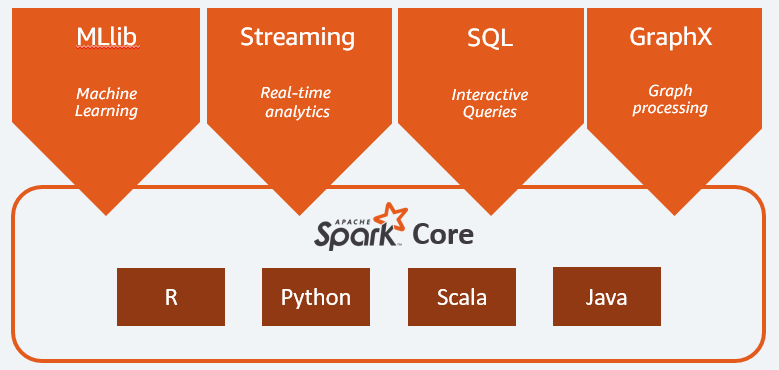
- Spark Core adalah mesin umum dari seluruh platform. Bertanggung jawab untuk merencanakan dan mendistribusikan tugas, mengoordinasikan operasi input/output atau memulihkan dari kerusakan apa pun;
- Spark SQL adalah komponen yang menyediakan skema RDD yang mendukung data terstruktur dan semi terstruktur. Secara khusus, memungkinkan untuk mengoptimalkan pengumpulan dan pemrosesan tipe data terstruktur dengan mengeksekusi SQL atau dengan menyediakan akses ke mesin SQL;
- Spark Streaming yang memungkinkan analisis data streaming. Spark Streaming mendukung data dari berbagai sumber seperti Flume, Kinesis, atau Kafka;
- MLib , perpustakaan bawaan Apache Spark untuk pembelajaran mesin. Ini menyediakan beberapa algoritme pembelajaran mesin serta beberapa alat untuk membuat saluran pembelajaran mesin;
- GraphX menggabungkan satu set API untuk melakukan pemodelan, perhitungan, dan analisis grafik dalam arsitektur terdistribusi.
Hadoop vs Spark: Perbedaan

Spark adalah mesin penghitung dan pemrosesan data Big Data. Jadi, secara teori, ini sedikit mirip dengan Hadoop MapReduce, yang jauh lebih cepat karena berjalan di dalam Memori. Lalu apa yang membuat Hadoop dan Spark berbeda? Mari kita lihat:

- Spark jauh lebih efisien, khususnya berkat pemrosesan dalam memori, sementara Hadoop memproses dalam batch;
- Spark jauh lebih mahal dari segi biaya karena membutuhkan sejumlah besar RAM untuk mempertahankan kinerjanya. Hadoop, di sisi lain, hanya mengandalkan mesin biasa untuk pemrosesan data;
- Hadoop lebih cocok untuk pemrosesan batch, sedangkan Spark paling cocok saat menangani data streaming atau aliran data tidak terstruktur;
- Hadoop lebih toleran terhadap kesalahan karena terus mereplikasi data sedangkan Spark menggunakan dataset terdistribusi tangguh (RDD) yang mengandalkan HDFS.
- Hadoop lebih terukur, karena Anda hanya perlu menambahkan mesin lain jika yang sudah ada tidak lagi memadai. Spark bergantung pada sistem kerangka kerja lain, seperti HDFS, untuk diperluas.
| Faktor | hadoop | Percikan |
| Pengolahan | Pemrosesan Batch | Pemrosesan dalam memori |
| Manajemen file | HDFS | Menggunakan HDFS Hadoop |
| Kecepatan | Cepat | 10 hingga 1000 kali lebih cepat |
| Dukungan bahasa | Java, Python, Scala, R, Go, dan JavaScript | Java, Python, Scala, dan R |
| Toleransi kesalahan | Lebih Toleran | Kurang Toleran |
| Biaya | Lebih murah | Lebih mahal |
| Skalabilitas | Lebih Skalabel | Kurang Terukur |
Hadoop baik untuk
Hadoop adalah solusi yang baik jika kecepatan pemrosesan tidak kritis. Misalnya, jika pemrosesan data dapat dilakukan dalam semalam, masuk akal untuk mempertimbangkan penggunaan MapReduce Hadoop.
Hadoop memungkinkan Anda untuk membongkar kumpulan data besar dari gudang data yang relatif sulit untuk diproses, karena HDFS Hadoop memberi organisasi cara yang lebih baik untuk menyimpan dan memproses data.
Percikan Baik untuk:
Dataset Terdistribusi (RDD) Spark yang tangguh memungkinkan beberapa operasi peta dalam memori, sementara Hadoop MapReduce harus menulis hasil sementara ke disk yang menjadikan Spark pilihan yang lebih disukai jika Anda ingin melakukan analisis data interaktif real-time.
Pemrosesan dalam memori Spark dan dukungan untuk database terdistribusi seperti Cassandra atau MongoDB adalah solusi yang sangat baik untuk migrasi dan penyisipan data – ketika data diambil dari database sumber dan dikirim ke sistem target lain.
Menggunakan Hadoop dan Spark Bersama

Seringkali Anda harus memilih antara Hadoop dan Spark; namun, dalam banyak kasus, memilih mungkin tidak diperlukan karena kedua kerangka kerja ini dapat hidup berdampingan dan bekerja sama dengan sangat baik. Memang, alasan utama di balik pengembangan Spark adalah untuk meningkatkan Hadoop daripada menggantinya.
Seperti yang telah kita lihat di bagian sebelumnya, Spark dapat diintegrasikan dengan Hadoop menggunakan sistem penyimpanan HDFS-nya. Memang, keduanya melakukan pemrosesan data lebih cepat dalam lingkungan terdistribusi. Demikian pula, Anda dapat mengalokasikan data di Hadoop dan memprosesnya menggunakan Spark atau menjalankan pekerjaan di dalam Hadoop MapReduce.
Kesimpulan
Hadoop atau Spark? Sebelum memilih kerangka kerja, Anda harus mempertimbangkan arsitektur Anda, dan teknologi yang menyusunnya harus konsisten dengan tujuan yang ingin Anda capai. Selain itu, Spark sepenuhnya kompatibel dengan ekosistem Hadoop dan bekerja dengan mulus dengan Sistem File Terdistribusi Hadoop dan Apache Hive.
Anda juga dapat menjelajahi beberapa alat data besar.