
Hadoop vs Spark: comparație față în față
Publicat: 2022-11-02Hadoop și Spark, ambele dezvoltate de Apache Software Foundation, sunt cadre open-source utilizate pe scară largă pentru arhitecturi de date mari.
Ne aflăm cu adevărat în centrul fenomenului Big Data în acest moment, iar companiile nu mai pot ignora impactul datelor asupra luării lor de decizii.
Ca o reamintire, datele considerate Big Data îndeplinesc trei criterii: viteză, viteză și varietate. Cu toate acestea, nu puteți procesa Big Data cu sisteme și tehnologii tradiționale.
Tocmai în vederea depășirii acestei probleme, Apache Software Foundation a propus cele mai utilizate soluții, și anume Hadoop și Spark.
Cu toate acestea, persoanele care sunt noi în procesarea datelor mari le este greu să înțeleagă aceste două tehnologii. Pentru a elimina toate îndoielile, în acest articol, aflați diferențele cheie dintre Hadoop și Spark și când ar trebui să alegeți unul sau altul sau să le folosiți împreună.
Hadoop
Hadoop este un utilitar software compus din mai multe module care formează un ecosistem pentru procesarea Big Data. Principiul folosit de Hadoop pentru această prelucrare este distribuția distribuită a datelor pentru a le procesa în paralel.

Configurarea sistemului de stocare distribuită a Hadoop este compusă din mai multe computere obișnuite, formând astfel un grup de mai multe noduri. Adoptarea acestui sistem permite Hadoop să proceseze eficient cantitatea uriașă de date disponibile, efectuând mai multe sarcini simultan, rapid și eficient.
Datele procesate cu Hadoop pot lua mai multe forme. Ele pot fi structurate ca tabele Excel sau tabele într-un SGBD convențional. Aceste date pot fi prezentate și într-un mod semi-structurat, cum ar fi fișierele JSON sau XML. Hadoop acceptă și date nestructurate, cum ar fi imagini, videoclipuri sau fișiere audio.
Componentele principale
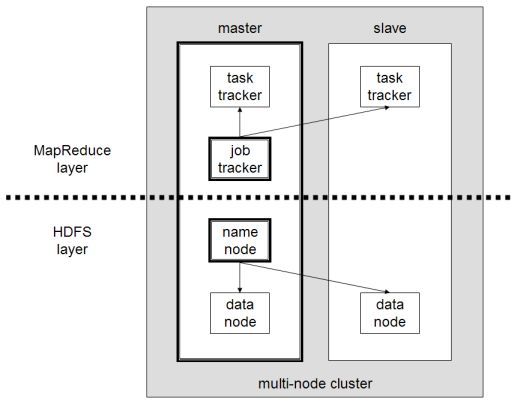
Principalele componente ale Hadoop sunt:
- HDFS sau Hadoop Distributed File System este sistemul folosit de Hadoop pentru a realiza stocarea distribuită a datelor. Este compus dintr-un nod master care conține metadatele cluster și mai multe noduri slave în care sunt stocate datele în sine;
- MapReduce este modelul algoritmic folosit pentru a procesa aceste date distribuite. Acest model de design poate fi implementat folosind mai multe limbaje de programare, cum ar fi Java, R, Scala, Go, JavaScript sau Python. Se execută în cadrul fiecărui nod în paralel;
- Hadoop Common , în care mai multe utilitare și biblioteci acceptă alte componente Hadoop;
- YARN este un instrument de orchestrare pentru a gestiona resursele de pe clusterul Hadoop și volumul de lucru efectuat de fiecare nod. De asemenea, acceptă implementarea MapReduce începând cu versiunea 2.0 a acestui cadru.
Apache Spark

Apache Spark este un framework open-source creat inițial de informaticianul Matei Zaharia ca parte a doctoratului său în 2009. Apoi s-a alăturat Apache Software Foundation în 2010.
Spark este un motor de calcul și procesare a datelor distribuit într-o manieră distribuită pe mai multe noduri. Principala specificitate a lui Spark este că efectuează procesări în memorie, adică folosește RAM pentru a stoca în cache și a procesa date mari distribuite în cluster. Îi oferă performanțe mai mari și viteză de procesare mult mai mare.

Spark acceptă mai multe sarcini, inclusiv procesarea în lot, procesarea în flux real, învățarea automată și calculul grafic. De asemenea, putem procesa date din mai multe sisteme, precum HDFS, RDBMS sau chiar baze de date NoSQL. Implementarea lui Spark se poate face cu mai multe limbaje precum Scala sau Python.
Componentele principale
Principalele componente ale Apache Spark sunt:
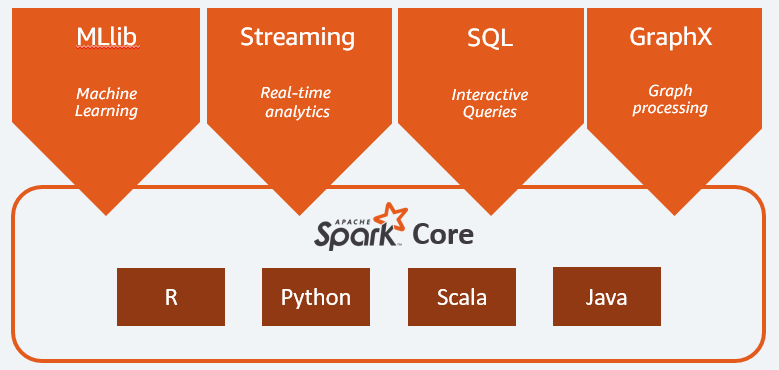
- Spark Core este motorul general al întregii platforme. Este responsabil pentru planificarea și distribuirea sarcinilor, coordonarea operațiunilor de intrare/ieșire sau de recuperare după orice defecțiuni;
- Spark SQL este componenta care furnizează schema RDD care acceptă date structurate și semi-structurate. În special, face posibilă optimizarea colectării și procesării datelor de tip structurat prin executarea SQL sau prin furnizarea accesului la motorul SQL;
- Spark Streaming care permite analiza datelor în flux. Spark Streaming acceptă date din diferite surse, cum ar fi Flume, Kinesis sau Kafka;
- MLib , biblioteca încorporată a Apache Spark pentru învățarea automată. Acesta oferă mai mulți algoritmi de învățare automată, precum și mai multe instrumente pentru a crea conducte de învățare automată;
- GraphX combină un set de API-uri pentru realizarea modelării, calculelor și analizelor grafice într-o arhitectură distribuită.
Hadoop vs Spark: diferențe

Spark este un motor de calcul și procesare a datelor Big Data. Deci, în teorie, este un pic ca Hadoop MapReduce, care este mult mai rapid, deoarece rulează în memorie. Atunci, ce face diferite Hadoop și Spark? Hai să aruncăm o privire:

- Spark este mult mai eficient, în special datorită procesării în memorie, în timp ce Hadoop procedează în loturi;
- Spark este mult mai scump din punct de vedere al costului, deoarece necesită o cantitate semnificativă de memorie RAM pentru a-și menține performanța. Hadoop, pe de altă parte, se bazează doar pe o mașină obișnuită pentru prelucrarea datelor;
- Hadoop este mai potrivit pentru procesarea în lot, în timp ce Spark este cel mai potrivit atunci când se ocupă cu date în flux sau fluxuri de date nestructurate;
- Hadoop este mai tolerant la erori, deoarece reproduce continuu datele, în timp ce Spark utilizează un set de date distribuite rezistent (RDD) care se bazează pe HDFS.
- Hadoop este mai scalabil, deoarece trebuie să adăugați o altă mașină doar dacă cele existente nu mai sunt suficiente. Spark se bazează pe sistemul altor cadre, cum ar fi HDFS, pentru a se extinde.
| Factor | Hadoop | Scânteie |
| Prelucrare | Procesare în loturi | Procesare în memorie |
| Gestionarea fișierelor | HDFS | Utilizează HDFS de la Hadoop |
| Viteză | Rapid | De 10 până la 1000 de ori mai rapid |
| Suport lingvistic | Java, Python, Scala, R, Go și JavaScript | Java, Python, Scala și R |
| Toleranță la erori | Mai tolerant | Mai puțin tolerant |
| Cost | Ieftin | Mai scump |
| Scalabilitate | Mai scalabil | Mai puțin scalabil |
Hadoop este bun pentru
Hadoop este o soluție bună dacă viteza de procesare nu este critică. De exemplu, dacă procesarea datelor se poate face peste noapte, este logic să luați în considerare utilizarea MapReduce de la Hadoop.
Hadoop vă permite să descărcați seturi mari de date din depozitele de date unde este relativ dificil de procesat, deoarece HDFS-ul Hadoop oferă organizațiilor o modalitate mai bună de stocare și procesare a datelor.
Spark este bun pentru:
Seturile de date distribuite (RDD) rezistente ale Spark permit operațiuni multiple de hărți în memorie, în timp ce Hadoop MapReduce trebuie să scrie rezultate intermediare pe disc, ceea ce face din Spark o opțiune preferată dacă doriți să faceți analize interactive de date în timp real.
Procesarea în memorie și suportul Spark pentru baze de date distribuite precum Cassandra sau MongoDB este o soluție excelentă pentru migrarea și inserarea datelor - atunci când datele sunt preluate dintr-o bază de date sursă și trimise către un alt sistem țintă.
Folosind Hadoop și Spark împreună

De multe ori trebuie să alegeți între Hadoop și Spark; cu toate acestea, în majoritatea cazurilor, alegerea poate fi inutilă, deoarece aceste două cadre pot coexista foarte bine și pot funcționa împreună. Într-adevăr, principalul motiv din spatele dezvoltării Spark a fost să îmbunătățească Hadoop, mai degrabă decât să-l înlocuiască.
După cum am văzut în secțiunile anterioare, Spark poate fi integrat cu Hadoop folosind sistemul său de stocare HDFS. Într-adevăr, ambele efectuează o procesare mai rapidă a datelor într-un mediu distribuit. În mod similar, puteți aloca date pe Hadoop și le puteți procesa folosind Spark sau puteți rula joburi în Hadoop MapReduce.
Concluzie
Hadoop sau Spark? Înainte de a alege cadrul, trebuie să iei în considerare arhitectura ta, iar tehnologiile care o compun trebuie să fie în concordanță cu obiectivul pe care vrei să-l atingi. În plus, Spark este pe deplin compatibil cu ecosistemul Hadoop și funcționează perfect cu Hadoop Distributed File System și Apache Hive.
De asemenea, puteți explora câteva instrumente de date mari.