
Hadoop vs Spark:頭對頭比較
已發表: 2022-11-02由 Apache Software Foundation 開發的 Hadoop 和 Spark 是廣泛使用的大數據架構開源框架。
我們現在確實處於大數據現象的核心,公司不能再忽視數據對其決策的影響。
提醒一下,被視為大數據的數據滿足三個標準:速度、速度和多樣性。 但是,您無法使用傳統系統和技術處理大數據。
為了克服這個問題,Apache Software Foundation 提出了最常用的解決方案,即 Hadoop 和 Spark。
但是,不熟悉大數據處理的人很難理解這兩種技術。 為了消除所有疑慮,在本文中,了解 Hadoop 和 Spark 之間的主要區別以及何時應該選擇一種或另一種,或者一起使用它們。
Hadoop
Hadoop 是一個軟件實用程序,由多個模塊組成,形成一個處理大數據的生態系統。 Hadoop 用於此處理的原理是數據的分佈式分佈以並行處理它們。

Hadoop的分佈式存儲系統設置是由幾台普通計算機組成,從而形成一個由多個節點組成的集群。 採用該系統後,Hadoop 可以同時、快速、高效地執行多項任務,從而有效地處理大量可用數據。
使用 Hadoop 處理的數據可以採用多種形式。 它們的結構可以類似於 Excel 表或傳統 DBMS 中的表。 此數據也可以以半結構化方式呈現,例如 JSON 或 XML 文件。 Hadoop 還支持非結構化數據,例如圖像、視頻或音頻文件。
主要成分
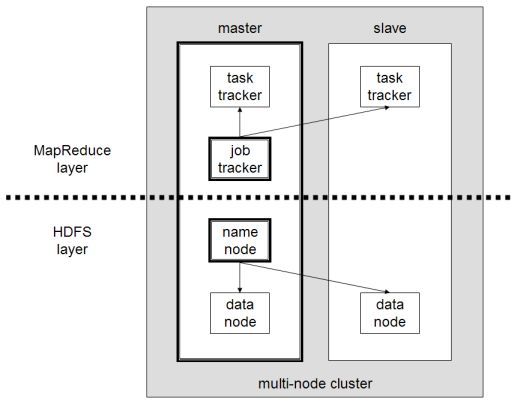
Hadoop的主要組件有:
- HDFS或Hadoop分佈式文件系統是Hadoop用於執行分佈式數據存儲的系統。 它由一個包含集群元數據的主節點和幾個存儲數據本身的從節點組成;
- MapReduce是用於處理這種分佈式數據的算法模型。 這種設計模式可以使用多種編程語言來實現,例如 Java、R、Scala、Go、JavaScript 或 Python。 它在每個節點內並行運行;
- Hadoop Common ,其中幾個實用程序和庫支持其他 Hadoop 組件;
- YARN是一個編排工具,用於管理 Hadoop 集群上的資源和每個節點執行的工作負載。 它還支持自該框架 2.0 版以來的 MapReduce 實現。
阿帕奇星火

Apache Spark 是一個開源框架,最初由計算機科學家 Matei Zaharia 作為其 2009 年博士學位的一部分創建。他隨後於 2010 年加入 Apache 軟件基金會。
Spark 是以分佈式方式分佈在多個節點上的計算和數據處理引擎。 Spark的主要特點是它執行內存中的處理,即它使用RAM來緩存和處理分佈在集群中的大數據。 它賦予它更高的性能和更高的處理速度。

Spark 支持多種任務,包括批處理、實時流處理、機器學習和圖形計算。 我們還可以處理來自多個系統的數據,例如 HDFS、RDBMS 甚至 NoSQL 數據庫。 Spark 的實現可以用 Scala 或 Python 等多種語言完成。
主要成分
Apache Spark 的主要組件有:
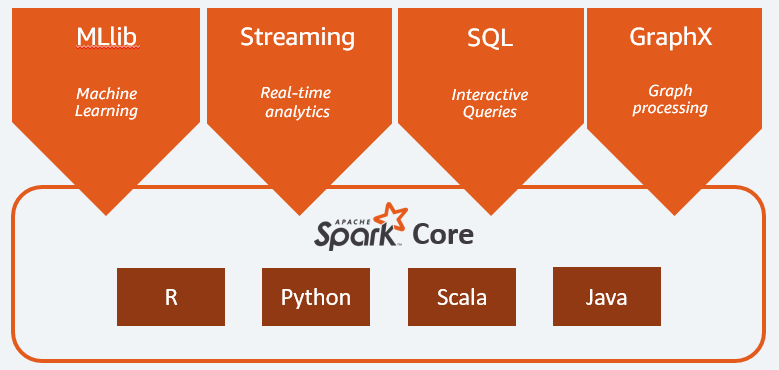
- Spark Core是整個平台的通用引擎。 它負責計劃和分配任務、協調輸入/輸出操作或從任何故障中恢復;
- Spark SQL是提供支持結構化和半結構化數據的 RDD 模式的組件。 特別是,它可以通過執行 SQL 或提供對 SQL 引擎的訪問來優化結構化類型數據的收集和處理;
- Spark Streaming允許流式數據分析。 Spark Streaming 支持來自不同來源的數據,例如 Flume、Kinesis 或 Kafka;
- MLib ,Apache Spark 用於機器學習的內置庫。 它提供了多種機器學習算法以及多種工具來創建機器學習管道;
- GraphX結合了一組 API,用於在分佈式架構中執行建模、計算和圖形分析。
Hadoop 與 Spark:差異

Spark 是一個大數據計算和數據處理引擎。 因此,理論上,它有點像 Hadoop MapReduce,因為它在內存中運行,所以速度要快得多。 那麼是什麼讓 Hadoop 和 Spark 不同呢? 我們來看一下:

- Spark 的效率要高得多,這要歸功於內存中的處理,而 Hadoop 是分批進行的;
- Spark 在成本方面要貴得多,因為它需要大量 RAM 才能維持其性能。 另一方面,Hadoop 只依賴普通機器進行數據處理;
- Hadoop更適合批處理,而Spark最適合處理流數據或非結構化數據流;
- Hadoop 具有更高的容錯性,因為它不斷複製數據,而 Spark 使用彈性分佈式數據集 (RDD),它本身依賴於 HDFS。
- Hadoop 更具可擴展性,因為您只需要在現有機器不再足夠的情況下添加另一台機器。 Spark依賴於其他框架的系統,例如HDFS,來擴展。
| 因素 | Hadoop | 火花 |
| 加工 | 批量處理 | 內存處理 |
| 文件管理 | 高密度文件系統 | 使用 Hadoop 的 HDFS |
| 速度 | 快速地 | 快 10 到 1000 倍 |
| 語言支持 | Java、Python、Scala、R、Go 和 JavaScript | Java、Python、Scala 和 R |
| 容錯 | 更寬容 | 不太寬容 |
| 成本 | 更便宜 | 更貴 |
| 可擴展性 | 更具可擴展性 | 可擴展性較差 |
Hadoop 適用於
如果處理速度不重要,Hadoop 是一個很好的解決方案。 例如,如果數據處理可以在一夜之間完成,那麼考慮使用 Hadoop 的 MapReduce 是有意義的。
Hadoop 允許您從數據倉庫中卸載相對難以處理的大型數據集,因為 Hadoop 的 HDFS 為組織提供了一種更好的方式來存儲和處理數據。
Spark 適用於:
Spark 的彈性分佈式數據集 (RDD) 允許多個內存映射操作,而 Hadoop MapReduce 必須將中間結果寫入磁盤,這使得 Spark 成為您想要進行實時交互式數據分析的首選。
Spark 的內存處理和對 Cassandra 或 MongoDB 等分佈式數據庫的支持是數據遷移和插入的絕佳解決方案——當從源數據庫檢索數據並將其發送到另一個目標系統時。
一起使用 Hadoop 和 Spark

通常您必須在 Hadoop 和 Spark 之間進行選擇; 然而,在大多數情況下,選擇可能是不必要的,因為這兩個框架可以很好地共存和協同工作。 事實上,開發 Spark 的主要原因是增強 Hadoop 而不是取代它。
正如我們在前幾節中看到的,Spark 可以使用其 HDFS 存儲系統與 Hadoop 集成。 實際上,它們都在分佈式環境中執行更快的數據處理。 同樣,您可以在 Hadoop 上分配數據並使用 Spark 處理它或在 Hadoop MapReduce 中運行作業。
結論
Hadoop 還是 Spark? 在選擇框架之前,您必須考慮您的架構,並且組成它的技術必須與您希望實現的目標一致。 此外,Spark 與 Hadoop 生態系統完全兼容,可與 Hadoop 分佈式文件系統和 Apache Hive 無縫協作。
您還可以探索一些大數據工具。