
Hadoop vs Spark: مقارنة وجهاً لوجه
نشرت: 2022-11-02Hadoop و Spark ، اللذان تم تطويرهما بواسطة Apache Software Foundation ، هما أطر عمل مفتوحة المصدر على نطاق واسع لهياكل البيانات الضخمة.
نحن حقًا في قلب ظاهرة البيانات الضخمة في الوقت الحالي ، ولم يعد بإمكان الشركات تجاهل تأثير البيانات على اتخاذ قراراتها.
للتذكير ، فإن البيانات التي يتم اعتبارها البيانات الضخمة تفي بثلاثة معايير: السرعة والسرعة والتنوع. ومع ذلك ، لا يمكنك معالجة البيانات الضخمة باستخدام الأنظمة والتقنيات التقليدية.
بهدف التغلب على هذه المشكلة ، اقترحت Apache Software Foundation الحلول الأكثر استخدامًا ، وهي Hadoop و Spark.
ومع ذلك ، فإن الأشخاص الجدد في معالجة البيانات الضخمة يجدون صعوبة في فهم هاتين التقنيتين. لإزالة كل الشكوك ، في هذه المقالة ، تعرف على الاختلافات الرئيسية بين Hadoop و Spark ومتى يجب عليك اختيار واحد أو آخر ، أو استخدامهما معًا.
هادوب
Hadoop هي أداة برمجية تتكون من عدة وحدات تشكل نظامًا بيئيًا لمعالجة البيانات الضخمة. المبدأ الذي يستخدمه Hadoop لهذه المعالجة هو التوزيع الموزع للبيانات لمعالجتها بالتوازي.

يتكون إعداد نظام التخزين الموزع لـ Hadoop من عدة أجهزة كمبيوتر عادية ، وبالتالي تشكل مجموعة من عدة عقد. يتيح اعتماد هذا النظام لـ Hadoop معالجة الكمية الهائلة من البيانات المتاحة بكفاءة من خلال أداء مهام متعددة في وقت واحد وبسرعة وكفاءة.
يمكن أن تتخذ البيانات التي تتم معالجتها باستخدام Hadoop عدة أشكال. يمكن تنظيمها مثل جداول Excel أو الجداول في نظام DBMS التقليدي. يمكن أيضًا تقديم هذه البيانات بطريقة شبه منظمة ، مثل ملفات JSON أو XML. يدعم Hadoop أيضًا البيانات غير المنظمة مثل الصور أو مقاطع الفيديو أو الملفات الصوتية.
المكونات الرئيسية
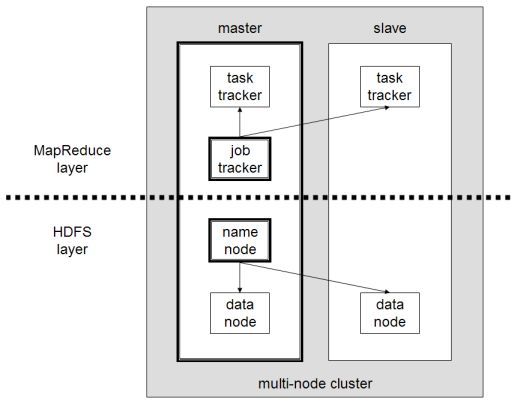
المكونات الرئيسية لبرنامج Hadoop هي:
- HDFS أو Hadoop Distributed File System هو النظام الذي يستخدمه Hadoop لأداء تخزين البيانات الموزعة. يتكون من عقدة رئيسية تحتوي على البيانات الوصفية للكتلة والعديد من العقد التابعة التي يتم فيها تخزين البيانات نفسها ؛
- MapReduce هو النموذج الحسابي المستخدم لمعالجة هذه البيانات الموزعة. يمكن تنفيذ نمط التصميم هذا باستخدام العديد من لغات البرمجة ، مثل Java أو R أو Scala أو Go أو JavaScript أو Python. يعمل داخل كل عقدة بالتوازي ؛
- Hadoop Common ، حيث تدعم العديد من الأدوات المساعدة والمكتبات مكونات Hadoop الأخرى ؛
- YARN هي أداة تنسيق لإدارة المورد على كتلة Hadoop وعبء العمل الذي تقوم به كل عقدة. كما أنه يدعم تنفيذ MapReduce منذ الإصدار 2.0 من إطار العمل هذا.
اباتشي سبارك

Apache Spark هو إطار عمل مفتوح المصدر تم إنشاؤه في البداية بواسطة عالم الكمبيوتر ماتي زهاريا كجزء من الدكتوراه في عام 2009. ثم انضم إلى مؤسسة أباتشي للبرمجيات في عام 2010.
Spark هو محرك حساب ومعالجة البيانات موزع بطريقة موزعة على عدة عقد. تتمثل الخصوصية الرئيسية لـ Spark في أنها تقوم بمعالجة داخل الذاكرة ، أي أنها تستخدم ذاكرة الوصول العشوائي (RAM) لتخزين ومعالجة البيانات الكبيرة الموزعة في الكتلة. إنه يمنحها أداءً أعلى وسرعة معالجة أعلى بكثير.

يدعم Spark العديد من المهام ، بما في ذلك معالجة الدُفعات والمعالجة الفورية والتعلم الآلي وحساب الرسم البياني. يمكننا أيضًا معالجة البيانات من عدة أنظمة ، مثل HDFS أو RDBMS أو حتى قواعد بيانات NoSQL. يمكن تنفيذ تطبيق Spark بعدة لغات مثل Scala أو Python.
المكونات الرئيسية
المكونات الرئيسية لـ Apache Spark هي:
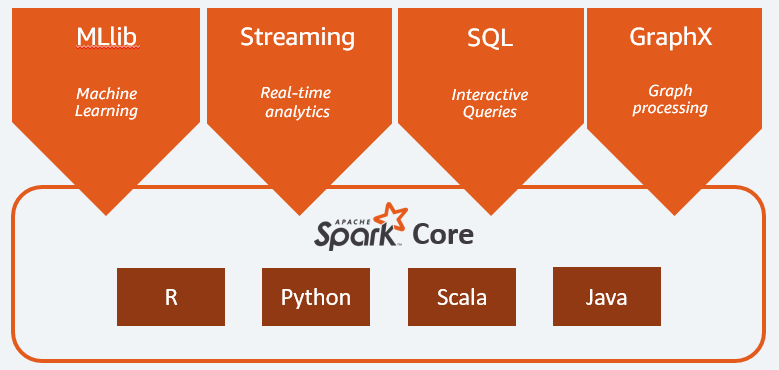
- Spark Core هو المحرك العام للمنصة بأكملها. وهي مسؤولة عن تخطيط وتوزيع المهام وتنسيق عمليات الإدخال / الإخراج أو التعافي من أي أعطال ؛
- Spark SQL هو المكون الذي يوفر مخطط RDD الذي يدعم البيانات المنظمة وشبه المنظمة. على وجه الخصوص ، فإنه يجعل من الممكن تحسين جمع ومعالجة بيانات النوع المهيكلة عن طريق تنفيذ SQL أو عن طريق توفير الوصول إلى محرك SQL ؛
- Spark Streaming الذي يسمح بتدفق تحليل البيانات. يدعم Spark Streaming البيانات من مصادر مختلفة مثل Flume أو Kinesis أو Kafka ؛
- MLib ، مكتبة Apache Spark المدمجة للتعلم الآلي. يوفر العديد من خوارزميات التعلم الآلي بالإضافة إلى العديد من الأدوات لإنشاء خطوط أنابيب للتعلم الآلي ؛
- تجمع GraphX بين مجموعة من واجهات برمجة التطبيقات لأداء النمذجة والحسابات وتحليلات الرسم البياني داخل بنية موزعة.
Hadoop مقابل سبارك: الاختلافات

Spark هو محرك لحساب البيانات الضخمة ومعالجة البيانات. لذلك ، من الناحية النظرية ، يشبه إلى حد ما Hadoop MapReduce ، وهو أسرع بكثير لأنه يعمل في الذاكرة. ثم ما الذي يجعل Hadoop و Spark مختلفين؟ لنلقي نظرة:

- يعد Spark أكثر كفاءة ، خاصة بفضل المعالجة في الذاكرة ، بينما يستمر Hadoop على دفعات ؛
- تعد Spark أغلى بكثير من حيث التكلفة لأنها تتطلب قدرًا كبيرًا من ذاكرة الوصول العشوائي للحفاظ على أدائها. من ناحية أخرى ، يعتمد Hadoop فقط على آلة عادية لمعالجة البيانات ؛
- يعد Hadoop أكثر ملاءمة لمعالجة الدُفعات ، بينما يكون Spark هو الأنسب عند التعامل مع تدفق البيانات أو تدفقات البيانات غير المنظمة ؛
- يعد Hadoop أكثر تحملاً للأخطاء لأنه يكرر البيانات باستمرار بينما يستخدم Spark مجموعة بيانات موزعة مرنة (RDD) تعتمد في حد ذاتها على HDFS.
- يعد Hadoop أكثر قابلية للتوسع ، حيث تحتاج فقط إلى إضافة جهاز آخر إذا لم تعد الأجهزة الموجودة كافية. يعتمد Spark على نظام الأطر الأخرى ، مثل HDFS ، للتمديد.
| عامل | هادوب | شرارة |
| يعالج | تجهيز الدفعات | معالجة في الذاكرة |
| إدارة الملفات | HDFS | يستخدم Hadoop's HDFS |
| سرعة | سريع | 10 إلى 1000 مرة أسرع |
| دعم اللغة | Java و Python و Scala و R و Go و JavaScript | Java و Python و Scala و R. |
| التسامح مع الخطأ | أكثر تسامحا | أقل تسامحا |
| كلفة | أقل غلاء | أغلى |
| قابلية التوسع | أكثر قابلية للتحجيم | أقل قابلية للتحجيم |
Hadoop جيد لـ
يعد Hadoop حلاً جيدًا إذا لم تكن سرعة المعالجة حرجة. على سبيل المثال ، إذا كان من الممكن إجراء معالجة البيانات بين عشية وضحاها ، فمن المنطقي التفكير في استخدام MapReduce Hadoop.
يتيح لك Hadoop تفريغ مجموعات البيانات الكبيرة من مستودعات البيانات حيث يكون من الصعب نسبيًا معالجتها ، حيث أن Hadoop's HDFS يمنح المؤسسات طريقة أفضل لتخزين البيانات ومعالجتها.
شرارة جيدة من أجل:
تسمح مجموعات البيانات الموزعة المرنة (RDDs) من Spark بعمليات خرائط متعددة في الذاكرة ، بينما يتعين على Hadoop MapReduce كتابة نتائج مؤقتة على القرص مما يجعل Spark خيارًا مفضلًا إذا كنت تريد إجراء تحليل بيانات تفاعلي في الوقت الفعلي.
تعد معالجة Spark في الذاكرة ودعم قواعد البيانات الموزعة مثل Cassandra أو MongoDB حلاً ممتازًا لترحيل البيانات وإدراجها - عندما يتم استرداد البيانات من قاعدة بيانات المصدر وإرسالها إلى نظام هدف آخر.
استخدام Hadoop و Spark معًا

غالبًا ما يتعين عليك الاختيار بين Hadoop و Spark ؛ ومع ذلك ، في معظم الحالات ، قد يكون الاختيار غير ضروري لأن هذين الإطارين يمكن أن يتعايشا جيدًا ويعملان معًا. في الواقع ، كان السبب الرئيسي وراء تطوير Spark هو تحسين Hadoop بدلاً من استبداله.
كما رأينا في الأقسام السابقة ، يمكن دمج Spark مع Hadoop باستخدام نظام التخزين HDFS الخاص به. في الواقع ، كلاهما يؤديان معالجة أسرع للبيانات داخل بيئة موزعة. وبالمثل ، يمكنك تخصيص البيانات على Hadoop ومعالجتها باستخدام Spark أو تشغيل الوظائف داخل Hadoop MapReduce.
استنتاج
Hadoop أم سبارك؟ قبل اختيار إطار العمل ، يجب أن تفكر في التصميم الخاص بك ، ويجب أن تكون التقنيات المكونة له متوافقة مع الهدف الذي ترغب في تحقيقه. علاوة على ذلك ، فإن Spark متوافق تمامًا مع نظام Hadoop البيئي ويعمل بسلاسة مع نظام الملفات الموزعة Hadoop و Apache Hive.
يمكنك أيضًا استكشاف بعض أدوات البيانات الضخمة.