
Hadoop vs Spark: comparação direta
Publicados: 2022-11-02Hadoop e Spark, ambos desenvolvidos pela Apache Software Foundation, são estruturas de código aberto amplamente utilizadas para arquiteturas de big data.
Estamos realmente no centro do fenômeno do Big Data agora, e as empresas não podem mais ignorar o impacto dos dados em suas tomadas de decisão.
Como lembrete, os dados considerados Big Data atendem a três critérios: velocidade, velocidade e variedade. No entanto, você não pode processar Big Data com sistemas e tecnologias tradicionais.
É com vista a ultrapassar este problema que a Apache Software Foundation propôs as soluções mais utilizadas, nomeadamente Hadoop e Spark.
No entanto, as pessoas que são novas no processamento de big data têm dificuldade em entender essas duas tecnologias. Para tirar todas as dúvidas, neste artigo, conheça as principais diferenças entre Hadoop e Spark e quando você deve escolher um ou outro, ou usá-los juntos.
Hadoop
O Hadoop é um utilitário de software composto por vários módulos que formam um ecossistema para processamento de Big Data. O princípio utilizado pelo Hadoop para esse processamento é a distribuição distribuída de dados para processá-los em paralelo.

A configuração do sistema de armazenamento distribuído do Hadoop é composta por vários computadores comuns, formando assim um cluster de vários nós. A adoção desse sistema permite que o Hadoop processe com eficiência a enorme quantidade de dados disponíveis, executando várias tarefas simultaneamente, de forma rápida e eficiente.
Os dados processados com o Hadoop podem assumir várias formas. Eles podem ser estruturados como tabelas do Excel ou tabelas em um SGBD convencional. Esses dados também podem ser apresentados de forma semiestruturada, como arquivos JSON ou XML. O Hadoop também oferece suporte a dados não estruturados, como imagens, vídeos ou arquivos de áudio.
Componentes principais
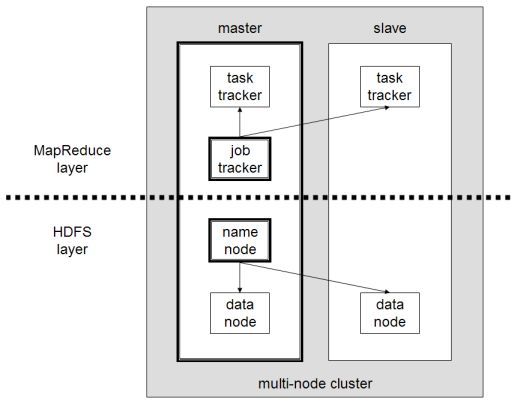
Os principais componentes do Hadoop são:
- HDFS ou Hadoop Distributed File System é o sistema usado pelo Hadoop para realizar armazenamento distribuído de dados. É composto por um nó mestre contendo os metadados do cluster e vários nós escravos nos quais os próprios dados são armazenados;
- MapReduce é o modelo algorítmico usado para processar esses dados distribuídos. Esse padrão de design pode ser implementado usando várias linguagens de programação, como Java, R, Scala, Go, JavaScript ou Python. Ele é executado em cada nó em paralelo;
- Hadoop Common , no qual vários utilitários e bibliotecas suportam outros componentes do Hadoop;
- O YARN é uma ferramenta de orquestração para gerenciar o recurso no cluster Hadoop e a carga de trabalho executada por cada nó. Também suporta a implementação do MapReduce desde a versão 2.0 deste framework.
Apache Spark

Apache Spark é uma estrutura de código aberto inicialmente criada pelo cientista da computação Matei Zaharia como parte de seu doutorado em 2009. Ele então ingressou na Apache Software Foundation em 2010.
Spark é um mecanismo de cálculo e processamento de dados distribuído de maneira distribuída em vários nós. A principal especificidade do Spark é que ele realiza processamento in-memory, ou seja, usa RAM para armazenar em cache e processar grandes dados distribuídos no cluster. Dá-lhe maior desempenho e velocidade de processamento muito maior.

O Spark oferece suporte a várias tarefas, incluindo processamento em lote, processamento de fluxo real, aprendizado de máquina e computação gráfica. Também podemos processar dados de diversos sistemas, como HDFS, RDBMS ou até mesmo bancos de dados NoSQL. A implementação do Spark pode ser feita com várias linguagens como Scala ou Python.
Componentes principais
Os principais componentes do Apache Spark são:
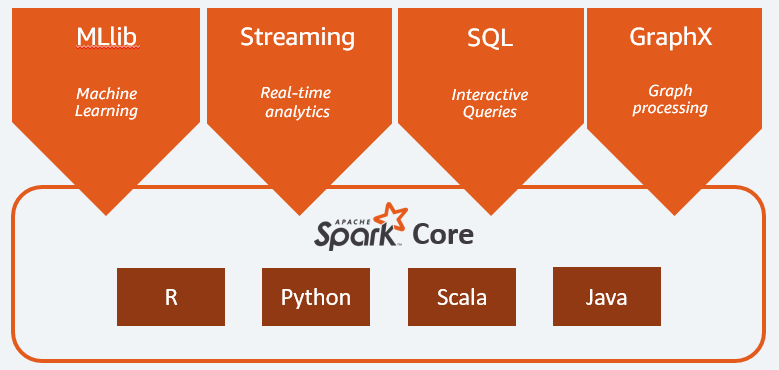
- Spark Core é o motor geral de toda a plataforma. É responsável pelo planejamento e distribuição de tarefas, coordenando as operações de entrada/saída ou recuperando-se de eventuais avarias;
- Spark SQL é o componente que fornece o esquema RDD que dá suporte a dados estruturados e semiestruturados. Em particular, permite otimizar a coleta e o processamento de dados do tipo estruturado executando SQL ou fornecendo acesso ao mecanismo SQL;
- Spark Streaming que permite a análise de dados de streaming. O Spark Streaming oferece suporte a dados de diferentes fontes, como Flume, Kinesis ou Kafka;
- MLib , a biblioteca integrada do Apache Spark para aprendizado de máquina. Ele fornece vários algoritmos de aprendizado de máquina, bem como várias ferramentas para criar pipelines de aprendizado de máquina;
- O GraphX combina um conjunto de APIs para realizar modelagem, cálculos e análises de gráficos em uma arquitetura distribuída.
Hadoop vs Spark: Diferenças

Spark é um mecanismo de cálculo e processamento de dados de Big Data. Então, em teoria, é um pouco como o Hadoop MapReduce, que é muito mais rápido, pois é executado na memória. Então, o que torna o Hadoop e o Spark diferentes? Vamos dar uma olhada:

- O Spark é muito mais eficiente, principalmente graças ao processamento na memória, enquanto o Hadoop procede em lotes;
- O Spark é muito mais caro em termos de custo, pois requer uma quantidade significativa de RAM para manter seu desempenho. O Hadoop, por outro lado, depende apenas de uma máquina comum para processamento de dados;
- O Hadoop é mais adequado para processamento em lote, enquanto o Spark é mais adequado para lidar com dados de streaming ou fluxos de dados não estruturados;
- O Hadoop é mais tolerante a falhas, pois replica dados continuamente, enquanto o Spark usa um conjunto de dados distribuído resiliente (RDD) que depende do HDFS.
- O Hadoop é mais escalável, pois você só precisa adicionar outra máquina se as existentes não forem mais suficientes. O Spark depende do sistema de outras estruturas, como HDFS, para estender.
| Fator | Hadoop | Fagulha |
| Em processamento | Processamento em lote | Processamento na memória |
| Gerenciamento de arquivos | HDFS | Usa o HDFS do Hadoop |
| Velocidade | Velozes | 10 a 1000 vezes mais rápido |
| Suporte de linguas | Java, Python, Scala, R, Go e JavaScript | Java, Python, Scala e R |
| Tolerância ao erro | Mais Tolerante | Menos Tolerante |
| Custo | Menos caro | Mais caro |
| Escalabilidade | Mais escalável | Menos escalável |
Hadoop é bom para
O Hadoop é uma boa solução se a velocidade de processamento não for crítica. Por exemplo, se o processamento de dados pode ser feito durante a noite, faz sentido considerar o uso do MapReduce do Hadoop.
O Hadoop permite que você descarregue grandes conjuntos de dados de data warehouses onde é comparativamente difícil de processar, pois o HDFS do Hadoop oferece às organizações uma maneira melhor de armazenar e processar dados.
Spark é bom para:
Os conjuntos de dados distribuídos (RDDs) resilientes do Spark permitem várias operações de mapa na memória, enquanto o Hadoop MapReduce precisa gravar resultados provisórios em disco, o que torna o Spark uma opção preferida se você deseja fazer análises de dados interativas em tempo real.
O processamento na memória do Spark e o suporte a bancos de dados distribuídos, como Cassandra ou MongoDB, é uma excelente solução para migração e inserção de dados – quando os dados são recuperados de um banco de dados de origem e enviados para outro sistema de destino.
Usando Hadoop e Spark juntos

Muitas vezes você tem que escolher entre Hadoop e Spark; no entanto, na maioria dos casos, a escolha pode ser desnecessária, pois essas duas estruturas podem muito bem coexistir e trabalhar juntas. De fato, a principal razão por trás do desenvolvimento do Spark foi aprimorar o Hadoop em vez de substituí-lo.
Como vimos nas seções anteriores, o Spark pode ser integrado ao Hadoop usando seu sistema de armazenamento HDFS. De fato, ambos executam um processamento de dados mais rápido em um ambiente distribuído. Da mesma forma, você pode alocar dados no Hadoop e processá-los usando o Spark ou executar trabalhos no Hadoop MapReduce.
Conclusão
Hadoop ou Spark? Antes de escolher o framework, você deve considerar sua arquitetura, e as tecnologias que o compõem devem ser consistentes com o objetivo que você deseja alcançar. Além disso, o Spark é totalmente compatível com o ecossistema Hadoop e funciona perfeitamente com o Hadoop Distributed File System e o Apache Hive.
Você também pode explorar algumas ferramentas de big data.