
Hadoop vs Spark: bezpośrednie porównanie
Opublikowany: 2022-11-02Hadoop i Spark, oba opracowane przez Apache Software Foundation, są szeroko stosowanymi platformami typu open source dla architektur Big Data.
Jesteśmy teraz naprawdę w centrum fenomenu Big Data, a firmy nie mogą dłużej ignorować wpływu danych na podejmowanie decyzji.
Przypominamy, że dane zaliczane do Big Data spełniają trzy kryteria: prędkość, szybkość i różnorodność. Nie możesz jednak przetwarzać Big Data za pomocą tradycyjnych systemów i technologii.
To właśnie z myślą o przezwyciężeniu tego problemu Apache Software Foundation zaproponowała najczęściej używane rozwiązania, czyli Hadoop i Spark.
Jednak osoby, które dopiero zaczynają przetwarzać duże zbiory danych, mają trudności ze zrozumieniem tych dwóch technologii. Aby rozwiać wszelkie wątpliwości, w tym artykule poznaj kluczowe różnice między Hadoop i Spark oraz kiedy powinieneś wybrać jeden lub drugi lub użyć ich razem.
Hadoop
Hadoop to narzędzie programowe składające się z kilku modułów tworzących ekosystem do przetwarzania Big Data. Zasadą stosowaną przez Hadoop do tego przetwarzania jest rozproszona dystrybucja danych w celu ich równoległego przetwarzania.

Konfiguracja rozproszonego systemu pamięci masowej Hadoop składa się z kilku zwykłych komputerów, tworząc w ten sposób klaster kilku węzłów. Przyjęcie tego systemu umożliwia Hadoop wydajne przetwarzanie ogromnej ilości dostępnych danych poprzez jednoczesne, szybkie i wydajne wykonywanie wielu zadań.
Dane przetwarzane przez Hadoop mogą przybierać różne formy. Mogą mieć strukturę jak tabele Excela lub tabele w konwencjonalnym DBMS. Dane te mogą być również prezentowane w sposób częściowo ustrukturyzowany, np. pliki JSON lub XML. Hadoop obsługuje również nieustrukturyzowane dane, takie jak obrazy, filmy lub pliki audio.
Główne składniki
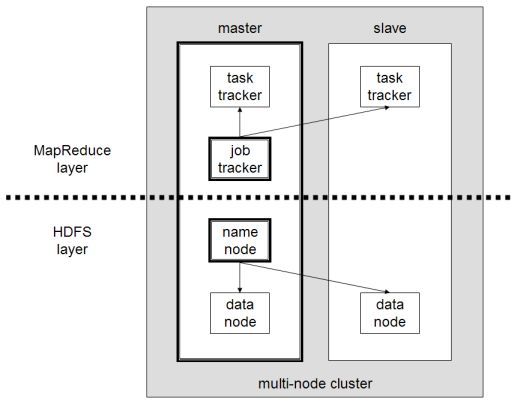
Główne składniki Hadoop to:
- HDFS lub Hadoop Distributed File System to system używany przez Hadoop do wykonywania rozproszonego przechowywania danych. Składa się z węzła głównego zawierającego metadane klastra i kilku węzłów podrzędnych, w których przechowywane są same dane;
- MapReduce to model algorytmiczny używany do przetwarzania tych rozproszonych danych. Ten wzorzec projektowy można zaimplementować za pomocą kilku języków programowania, takich jak Java, R, Scala, Go, JavaScript czy Python. Działa równolegle w każdym węźle;
- Hadoop Common , w którym kilka narzędzi i bibliotek obsługuje inne składniki Hadoop;
- YARN to narzędzie do aranżacji służące do zarządzania zasobami w klastrze Hadoop i obciążeniem wykonywanym przez każdy węzeł. Obsługuje również implementację MapReduce od wersji 2.0 tego frameworka.
Apache Spark

Apache Spark to platforma typu open source stworzona przez informatyka Matei Zaharię w ramach jego doktoratu w 2009 roku. Następnie dołączył do Apache Software Foundation w 2010 roku.
Spark to silnik obliczeniowy i przetwarzający dane rozproszony w kilku węzłach. Główną specyfiką Sparka jest to, że wykonuje przetwarzanie w pamięci, czyli wykorzystuje pamięć RAM do buforowania i przetwarzania dużych danych rozproszonych w klastrze. Daje mu wyższą wydajność i znacznie większą szybkość przetwarzania.

Spark obsługuje kilka zadań, w tym przetwarzanie wsadowe, przetwarzanie strumienia rzeczywistego, uczenie maszynowe i obliczanie wykresów. Możemy również przetwarzać dane z kilku systemów, takich jak HDFS, RDBMS czy nawet bazy danych NoSQL. Implementację Sparka można wykonać za pomocą kilku języków, takich jak Scala czy Python.
Główne składniki
Główne komponenty Apache Spark to:
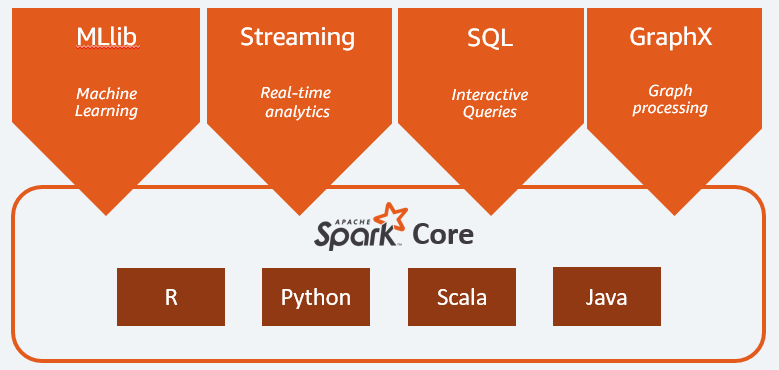
- Spark Core jest głównym silnikiem całej platformy. Odpowiada za planowanie i dystrybucję zadań, koordynację operacji wejścia/wyjścia lub naprawę po wszelkich awariach;
- Spark SQL to składnik udostępniający schemat RDD, który obsługuje dane strukturalne i częściowo ustrukturyzowane. W szczególności umożliwia optymalizację zbierania i przetwarzania danych typu strukturalnego poprzez wykonanie SQL lub poprzez udostępnienie silnika SQL;
- Spark Streaming , który umożliwia strumieniową analizę danych. Spark Streaming obsługuje dane z różnych źródeł, takich jak Flume, Kinesis lub Kafka;
- MLib , wbudowana biblioteka Apache Spark do uczenia maszynowego. Zapewnia kilka algorytmów uczenia maszynowego, a także kilka narzędzi do tworzenia potoków uczenia maszynowego;
- GraphX łączy zestaw interfejsów API do wykonywania modelowania, obliczeń i analiz wykresów w ramach architektury rozproszonej.
Hadoop vs Spark: różnice

Spark to silnik obliczeniowy i przetwarzający dane Big Data. Więc teoretycznie jest trochę jak MapReduce Hadoop, który jest znacznie szybszy, ponieważ działa w pamięci. Co zatem wyróżnia Hadoop i Spark? Spójrzmy:

- Spark jest znacznie bardziej wydajny, w szczególności dzięki przetwarzaniu w pamięci, podczas gdy Hadoop działa w partiach;
- Spark jest znacznie droższy pod względem kosztów, ponieważ wymaga znacznej ilości pamięci RAM, aby utrzymać swoją wydajność. Z drugiej strony Hadoop opiera się tylko na zwykłej maszynie do przetwarzania danych;
- Hadoop jest bardziej odpowiedni do przetwarzania wsadowego, podczas gdy Spark najlepiej sprawdza się w przypadku przesyłania strumieniowego danych lub nieustrukturyzowanych strumieni danych;
- Hadoop jest bardziej odporny na błędy, ponieważ stale replikuje dane, podczas gdy Spark używa odpornego rozproszonego zestawu danych (RDD), który sam opiera się na HDFS.
- Hadoop jest bardziej skalowalny, ponieważ wystarczy dodać kolejną maszynę tylko wtedy, gdy istniejące już nie wystarczają. Spark polega na systemie innych frameworków, takich jak HDFS, aby się rozszerzyć.
| Czynnik | Hadoop | Iskra |
| Przetwarzanie | Przetwarzanie wsadowe | Przetwarzanie w pamięci |
| Zarządzanie plikami | HDFS | Wykorzystuje HDFS firmy Hadoop |
| Prędkość | Szybko | 10 do 1000 razy szybciej |
| Wsparcie językowe | Java, Python, Scala, R, Go i JavaScript | Java, Python, Scala i R |
| Tolerancja błędów | Bardziej tolerancyjny | Mniej tolerancyjny |
| Koszt | Tańszy | Droższe |
| Skalowalność | Bardziej skalowalny | Mniej skalowalny |
Hadoop jest dobry dla
Hadoop to dobre rozwiązanie, jeśli szybkość przetwarzania nie jest krytyczna. Na przykład, jeśli przetwarzanie danych można wykonać w nocy, warto rozważyć użycie MapReduce Hadoop.
Hadoop umożliwia odciążenie dużych zestawów danych z hurtowni danych, w których jest to stosunkowo trudne do przetworzenia, ponieważ HDFS Hadoop zapewnia organizacjom lepszy sposób przechowywania i przetwarzania danych.
Spark jest dobry dla:
Odporne rozproszone zestawy danych (RDD) Spark umożliwiają wiele operacji na mapach w pamięci, podczas gdy Hadoop MapReduce musi zapisywać wyniki pośrednie na dysku, co czyni Spark preferowaną opcją, jeśli chcesz przeprowadzać interaktywną analizę danych w czasie rzeczywistym.
Przetwarzanie w pamięci Spark i obsługa rozproszonych baz danych, takich jak Cassandra czy MongoDB, to doskonałe rozwiązanie do migracji i wstawiania danych – gdy dane są pobierane ze źródłowej bazy danych i wysyłane do innego systemu docelowego.
Używanie Hadoop i Spark razem

Często musisz wybierać między Hadoop i Spark; jednak w większości przypadków wybór może być niepotrzebny, ponieważ te dwie struktury mogą bardzo dobrze współistnieć i współpracować. Rzeczywiście, głównym powodem rozwoju Sparka było ulepszenie Hadoopa, a nie jego zastępowanie.
Jak widzieliśmy w poprzednich sekcjach, Spark można zintegrować z Hadoop za pomocą systemu pamięci masowej HDFS. Rzeczywiście, oba wykonują szybsze przetwarzanie danych w środowisku rozproszonym. Podobnie możesz alokować dane w usłudze Hadoop i przetwarzać je przy użyciu platformy Spark lub uruchamiać zadania w usłudze Hadoop MapReduce.
Wniosek
Hadoop czy Spark? Przed wyborem frameworka należy wziąć pod uwagę swoją architekturę, a tworzące ją technologie muszą być zgodne z celem, który chcesz osiągnąć. Co więcej, Spark jest w pełni kompatybilny z ekosystemem Hadoop i bezproblemowo współpracuje z rozproszonym systemem plików Hadoop i Apache Hive.
Możesz także zapoznać się z niektórymi narzędziami Big Data.