
Hadoop против Spark: прямое сравнение
Опубликовано: 2022-11-02Hadoop и Spark, разработанные Apache Software Foundation, являются широко используемыми платформами с открытым исходным кодом для архитектур больших данных.
Сейчас мы действительно находимся в центре феномена больших данных, и компании больше не могут игнорировать влияние данных на принятие ими решений.
Напоминаем, что данные, которые считаются большими данными, соответствуют трем критериям: скорость, скорость и разнообразие. Однако вы не можете обрабатывать большие данные с помощью традиционных систем и технологий.
Именно для решения этой проблемы Apache Software Foundation предложила наиболее часто используемые решения, а именно Hadoop и Spark.
Однако людям, которые плохо знакомы с обработкой больших данных, трудно понять эти две технологии. Чтобы развеять все сомнения, в этой статье узнайте о ключевых различиях между Hadoop и Spark и о том, когда следует выбирать тот или иной вариант или использовать их вместе.
Хадуп
Hadoop — это программная утилита, состоящая из нескольких модулей, образующих экосистему для обработки больших данных. Принцип, используемый Hadoop для этой обработки, заключается в распределенном распределении данных для их параллельной обработки.

Распределенная система хранения данных Hadoop состоит из нескольких обычных компьютеров, образующих кластер из нескольких узлов. Внедрение этой системы позволяет Hadoop эффективно обрабатывать огромное количество доступных данных, выполняя несколько задач одновременно, быстро и эффективно.
Данные, обрабатываемые с помощью Hadoop, могут принимать различные формы. Они могут быть структурированы как таблицы Excel или таблицы в обычной СУБД. Эти данные также могут быть представлены в полуструктурированном виде, например, в виде файлов JSON или XML. Hadoop также поддерживает неструктурированные данные, такие как изображения, видео или аудиофайлы.
Основные компоненты
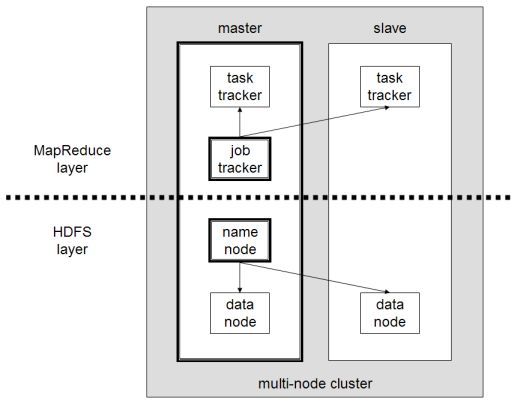
Основными компонентами Hadoop являются:
- HDFS или распределенная файловая система Hadoop — это система, используемая Hadoop для выполнения распределенного хранения данных. Он состоит из главного узла, содержащего метаданные кластера, и нескольких подчиненных узлов, в которых хранятся сами данные;
- MapReduce — это алгоритмическая модель, используемая для обработки этих распределенных данных. Этот шаблон проектирования может быть реализован с использованием нескольких языков программирования, таких как Java, R, Scala, Go, JavaScript или Python. Он работает внутри каждого узла параллельно;
- Hadoop Common , в котором несколько утилит и библиотек поддерживают другие компоненты Hadoop;
- YARN — это инструмент оркестровки для управления ресурсами в кластере Hadoop и рабочей нагрузкой, выполняемой каждым узлом. Он также поддерживает реализацию MapReduce, начиная с версии 2.0 этого фреймворка.
Апач Спарк

Apache Spark — это фреймворк с открытым исходным кодом, первоначально созданный ученым-компьютерщиком Матеем Захарией в рамках его докторской диссертации в 2009 году. Затем в 2010 году он присоединился к Apache Software Foundation.
Spark — это механизм вычислений и обработки данных, распределенно распределенный по нескольким узлам. Основная особенность Spark заключается в том, что он выполняет обработку в памяти, т.е. использует оперативную память для кэширования и обработки больших данных, распределенных в кластере. Это дает ему более высокую производительность и гораздо более высокую скорость обработки.

Spark поддерживает несколько задач, включая пакетную обработку, обработку в реальном времени, машинное обучение и вычисление графов. Мы также можем обрабатывать данные из нескольких систем, таких как HDFS, RDBMS или даже базы данных NoSQL. Реализация Spark может быть выполнена на нескольких языках, таких как Scala или Python.
Основные компоненты
Основные компоненты Apache Spark:
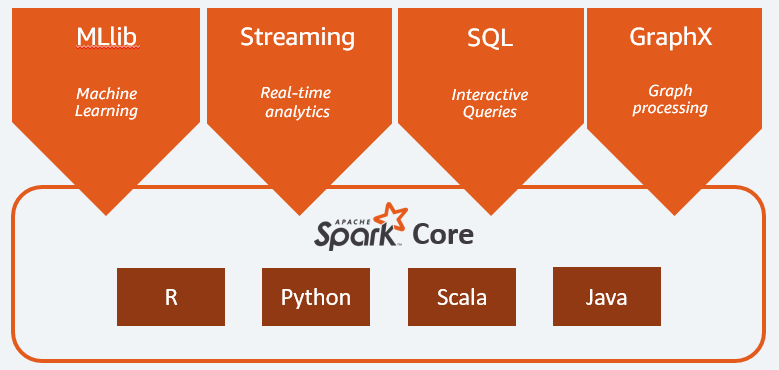
- Spark Core — это общий движок всей платформы. Он отвечает за планирование и распределение задач, координацию операций ввода/вывода или восстановление после любых сбоев;
- Spark SQL — это компонент, предоставляющий схему RDD, которая поддерживает структурированные и частично структурированные данные. В частности, он позволяет оптимизировать сбор и обработку данных структурированного типа путем выполнения SQL или предоставления доступа к механизму SQL;
- Spark Streaming , который позволяет анализировать потоковые данные. Spark Streaming поддерживает данные из различных источников, таких как Flume, Kinesis или Kafka;
- MLib — встроенная библиотека Apache Spark для машинного обучения. Он предоставляет несколько алгоритмов машинного обучения, а также несколько инструментов для создания конвейеров машинного обучения;
- GraphX сочетает в себе набор API для моделирования, расчетов и анализа графиков в распределенной архитектуре.
Hadoop против Spark: различия

Spark — это механизм расчета и обработки больших данных. Таким образом, теоретически это немного похоже на Hadoop MapReduce, который намного быстрее, поскольку работает в памяти. Что же тогда отличает Hadoop и Spark? Давайте посмотрим:

- Spark намного эффективнее, в частности, благодаря обработке в памяти, в то время как Hadoop работает в пакетном режиме;
- Spark намного дороже с точки зрения стоимости, так как требует значительного объема оперативной памяти для поддержания своей производительности. Hadoop, с другой стороны, полагается только на обычную машину для обработки данных;
- Hadoop больше подходит для пакетной обработки, тогда как Spark лучше всего подходит для обработки потоковых данных или потоков неструктурированных данных;
- Hadoop более отказоустойчив, поскольку он постоянно реплицирует данные, тогда как Spark использует отказоустойчивый распределенный набор данных (RDD), который сам полагается на HDFS.
- Hadoop более масштабируем, так как вам нужно добавить еще одну машину только в том случае, если существующих уже недостаточно. Для расширения Spark использует систему других фреймворков, таких как HDFS.
| Фактор | Хадуп | Искра |
| Обработка | Пакетная обработка | Обработка в памяти |
| Управление файлами | HDFS | Использует HDFS Hadoop |
| Скорость | Быстро | От 10 до 1000 раз быстрее |
| Языковая поддержка | Java, Python, Scala, R, Go и JavaScript | Java, Python, Scala и R |
| Отказоустойчивость | Более терпимый | Менее терпимый |
| Расходы | Дешевле | Более дорогой |
| Масштабируемость | Более масштабируемый | Менее масштабируемый |
Hadoop хорош для
Hadoop — хорошее решение, если скорость обработки не критична. Например, если обработку данных можно выполнить за одну ночь, имеет смысл рассмотреть возможность использования MapReduce от Hadoop.
Hadoop позволяет выгружать большие наборы данных из хранилищ данных, где их относительно сложно обрабатывать, поскольку HDFS Hadoop предоставляет организациям лучший способ хранения и обработки данных.
Искра хороша для:
Устойчивые распределенные наборы данных (RDD) Spark позволяют выполнять несколько операций с картами в памяти, в то время как Hadoop MapReduce должен записывать промежуточные результаты на диск, что делает Spark предпочтительным вариантом, если вы хотите выполнять интерактивный анализ данных в реальном времени.
Обработка в памяти Spark и поддержка распределенных баз данных, таких как Cassandra или MongoDB, — отличное решение для миграции и вставки данных, когда данные извлекаются из исходной базы данных и отправляются в другую целевую систему.
Использование Hadoop и Spark вместе

Часто приходится выбирать между Hadoop и Spark; однако в большинстве случаев выбор может быть ненужным, поскольку эти две структуры могут очень хорошо сосуществовать и работать вместе. Действительно, основная причина разработки Spark заключалась в том, чтобы улучшить Hadoop, а не заменить его.
Как мы видели в предыдущих разделах, Spark можно интегрировать с Hadoop с помощью его системы хранения HDFS. Действительно, они оба выполняют более быструю обработку данных в распределенной среде. Точно так же вы можете размещать данные в Hadoop и обрабатывать их с помощью Spark или запускать задания внутри Hadoop MapReduce.
Вывод
Хадуп или Спарк? Прежде чем выбрать фреймворк, вы должны рассмотреть свою архитектуру, а составляющие ее технологии должны соответствовать цели, которую вы хотите достичь. Кроме того, Spark полностью совместим с экосистемой Hadoop и безупречно работает с распределенной файловой системой Hadoop и Apache Hive.
Вы также можете изучить некоторые инструменты для работы с большими данными.