
Hadoop vs Spark: confronto testa a testa
Pubblicato: 2022-11-02Hadoop e Spark, entrambi sviluppati dalla Apache Software Foundation, sono framework open source ampiamente utilizzati per le architetture di big data.
Siamo davvero al centro del fenomeno dei Big Data in questo momento e le aziende non possono più ignorare l'impatto dei dati sul loro processo decisionale.
Ricordiamo che i dati considerati Big Data soddisfano tre criteri: velocità, velocità e varietà. Tuttavia, non è possibile elaborare Big Data con sistemi e tecnologie tradizionali.
È nell'ottica di superare questo problema che Apache Software Foundation ha proposto le soluzioni più utilizzate, ovvero Hadoop e Spark.
Tuttavia, le persone che non conoscono l'elaborazione dei big data hanno difficoltà a comprendere queste due tecnologie. Per rimuovere tutti i dubbi, in questo articolo, impara le differenze chiave tra Hadoop e Spark e quando dovresti sceglierne uno o l'altro, o usarli insieme.
Hadoop
Hadoop è un'utilità software composta da diversi moduli che formano un ecosistema per l'elaborazione di Big Data. Il principio utilizzato da Hadoop per questo trattamento è la distribuzione distribuita dei dati per elaborarli in parallelo.

La configurazione del sistema di archiviazione distribuito di Hadoop è composta da diversi computer ordinari, formando così un cluster di diversi nodi. L'adozione di questo sistema consente a Hadoop di elaborare in modo efficiente l'enorme quantità di dati disponibili eseguendo più attività contemporaneamente, in modo rapido ed efficiente.
I dati elaborati con Hadoop possono assumere molte forme. Possono essere strutturati come tabelle di Excel o tabelle in un DBMS convenzionale. Questi dati possono anche essere presentati in modo semi-strutturato, come file JSON o XML. Hadoop supporta anche dati non strutturati come immagini, video o file audio.
Componenti principali
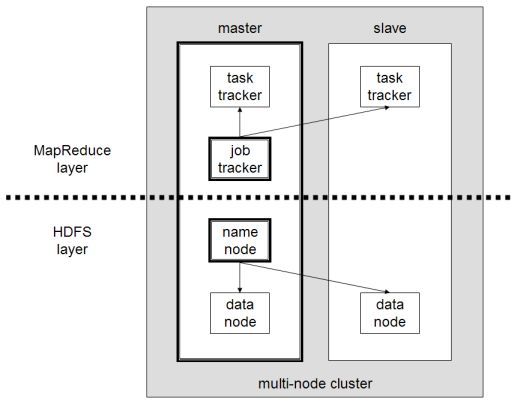
I componenti principali di Hadoop sono:
- HDFS o Hadoop Distributed File System è il sistema utilizzato da Hadoop per eseguire l'archiviazione dei dati distribuiti. È composto da un nodo master contenente i metadati del cluster e da diversi nodi slave in cui sono archiviati i dati stessi;
- MapReduce è il modello algoritmico utilizzato per elaborare questi dati distribuiti. Questo modello di progettazione può essere implementato utilizzando diversi linguaggi di programmazione, come Java, R, Scala, Go, JavaScript o Python. Funziona all'interno di ogni nodo in parallelo;
- Hadoop Common , in cui diverse utilità e librerie supportano altri componenti Hadoop;
- YARN è uno strumento di orchestrazione per gestire la risorsa sul cluster Hadoop e il carico di lavoro eseguito da ciascun nodo. Supporta anche l'implementazione di MapReduce dalla versione 2.0 di questo framework.
Apache Scintilla

Apache Spark è un framework open source inizialmente creato dallo scienziato informatico Matei Zaharia come parte del suo dottorato nel 2009. Successivamente è entrato a far parte della Apache Software Foundation nel 2010.
Spark è un motore di calcolo ed elaborazione dati distribuito in maniera distribuita su più nodi. La principale specificità di Spark è che esegue l'elaborazione in-memory, ovvero utilizza la RAM per memorizzare nella cache ed elaborare dati di grandi dimensioni distribuiti nel cluster. Offre prestazioni più elevate e velocità di elaborazione molto più elevate.

Spark supporta diverse attività, tra cui elaborazione batch, elaborazione in flusso reale, apprendimento automatico e calcolo grafico. Possiamo anche elaborare dati da diversi sistemi, come HDFS, RDBMS o persino database NoSQL. L'implementazione di Spark può essere eseguita con diversi linguaggi come Scala o Python.
Componenti principali
I componenti principali di Apache Spark sono:
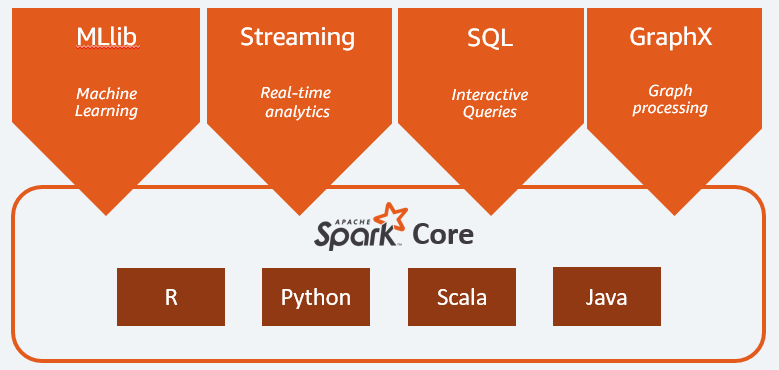
- Spark Core è il motore generale dell'intera piattaforma. È responsabile della pianificazione e della distribuzione dei compiti, del coordinamento delle operazioni di input/output o del recupero da eventuali guasti;
- Spark SQL è il componente che fornisce lo schema RDD che supporta i dati strutturati e semi-strutturati. In particolare permette di ottimizzare la raccolta e l'elaborazione di dati di tipo strutturato eseguendo SQL o fornendo l'accesso al motore SQL;
- Spark Streaming che consente l'analisi dei dati in streaming. Spark Streaming supporta dati da diverse fonti come Flume, Kinesis o Kafka;
- MLib , la libreria integrata di Apache Spark per l'apprendimento automatico. Fornisce diversi algoritmi di apprendimento automatico e diversi strumenti per creare pipeline di apprendimento automatico;
- GraphX combina un set di API per l'esecuzione di modellazione, calcoli e analisi dei grafici all'interno di un'architettura distribuita.
Hadoop vs Spark: differenze

Spark è un motore di calcolo ed elaborazione dati di Big Data. Quindi, in teoria, è un po' come Hadoop MapReduce, che è molto più veloce poiché funziona in memoria. Allora cosa rende Hadoop e Spark diversi? Diamo un'occhiata:

- Spark è molto più efficiente, in particolare grazie all'elaborazione in-memory, mentre Hadoop procede in batch;
- Spark è molto più costoso in termini di costi poiché richiede una quantità significativa di RAM per mantenere le sue prestazioni. Hadoop, invece, si affida solo a una normale macchina per l'elaborazione dei dati;
- Hadoop è più adatto per l'elaborazione batch, mentre Spark è più adatto quando si tratta di dati in streaming o flussi di dati non strutturati;
- Hadoop è più tollerante ai guasti poiché replica continuamente i dati mentre Spark utilizza un set di dati distribuito resiliente (RDD) che a sua volta si basa su HDFS.
- Hadoop è più scalabile, poiché è necessario aggiungere un'altra macchina solo se quelle esistenti non sono più sufficienti. Spark si basa sul sistema di altri framework, come HDFS, per l'estensione.
| Fattore | Hadoop | Scintilla |
| in lavorazione | Elaborazione in lotti | Elaborazione in memoria |
| Gestione dei file | HDFS | Utilizza HDFS di Hadoop |
| Velocità | Veloce | Da 10 a 1000 volte più veloce |
| Supporto linguistico | Java, Python, Scala, R, Go e JavaScript | Java, Python, Scala e R |
| Tolleranza ai guasti | Più tollerante | Meno tollerante |
| Costo | Meno caro | Più costoso |
| Scalabilità | Più scalabile | Meno scalabile |
Hadoop è buono per
Hadoop è una buona soluzione se la velocità di elaborazione non è critica. Ad esempio, se l'elaborazione dei dati può essere eseguita durante la notte, ha senso considerare l'utilizzo di MapReduce di Hadoop.
Hadoop consente di scaricare set di dati di grandi dimensioni da data warehouse in cui è relativamente difficile da elaborare, poiché HDFS di Hadoop offre alle organizzazioni un modo migliore per archiviare ed elaborare i dati.
Spark va bene per:
I resilienti Distributed Dataset (RDD) di Spark consentono più operazioni di mappa in memoria, mentre Hadoop MapReduce deve scrivere i risultati provvisori su disco, il che rende Spark un'opzione preferita se si desidera eseguire analisi dei dati interattive in tempo reale.
L'elaborazione in memoria di Spark e il supporto per database distribuiti come Cassandra o MongoDB è un'ottima soluzione per la migrazione e l'inserimento dei dati, quando i dati vengono recuperati da un database di origine e inviati a un altro sistema di destinazione.
Usare Hadoop e Spark insieme

Spesso devi scegliere tra Hadoop e Spark; tuttavia, nella maggior parte dei casi, la scelta potrebbe non essere necessaria poiché questi due framework possono benissimo coesistere e lavorare insieme. In effetti, il motivo principale alla base dello sviluppo di Spark è stato quello di migliorare Hadoop piuttosto che sostituirlo.
Come abbiamo visto nelle sezioni precedenti, Spark può essere integrato con Hadoop utilizzando il suo sistema di archiviazione HDFS. In effetti, entrambi eseguono un'elaborazione dei dati più rapida all'interno di un ambiente distribuito. Allo stesso modo, puoi allocare i dati su Hadoop ed elaborarli utilizzando Spark o eseguire lavori all'interno di Hadoop MapReduce.
Conclusione
Hadoop o Spark? Prima di scegliere il framework, devi considerare la tua architettura e le tecnologie che la compongono devono essere coerenti con l'obiettivo che desideri raggiungere. Inoltre, Spark è completamente compatibile con l'ecosistema Hadoop e funziona perfettamente con Hadoop Distributed File System e Apache Hive.
Puoi anche esplorare alcuni strumenti per big data.