
Hadoop vs Spark: การเปรียบเทียบแบบตัวต่อตัว
เผยแพร่แล้ว: 2022-11-02Hadoop และ Spark ซึ่งพัฒนาโดย Apache Software Foundation เป็นเฟรมเวิร์กโอเพนซอร์สที่ใช้กันอย่างแพร่หลายสำหรับสถาปัตยกรรมบิ๊กดาต้า
ขณะนี้เราเป็นหัวใจสำคัญของปรากฏการณ์บิ๊กดาต้า และบริษัทต่างๆ ก็ไม่สามารถเพิกเฉยต่อผลกระทบของข้อมูลที่มีต่อการตัดสินใจได้อีกต่อไป
เพื่อเป็นการเตือนความจำ ข้อมูลที่พิจารณาว่า Big Data ตรงตามเกณฑ์สามประการ: ความเร็ว ความเร็ว และความหลากหลาย อย่างไรก็ตาม คุณไม่สามารถประมวลผล Big Data ด้วยระบบและเทคโนโลยีแบบเดิมได้
เพื่อที่จะเอาชนะปัญหานี้ Apache Software Foundation ได้เสนอวิธีแก้ปัญหาที่ใช้กันมากที่สุด ได้แก่ Hadoop และ Spark
อย่างไรก็ตาม ผู้ที่ยังใหม่ต่อการประมวลผลข้อมูลขนาดใหญ่มักไม่ค่อยเข้าใจเทคโนโลยีทั้งสองนี้ เพื่อขจัดข้อสงสัยทั้งหมด ในบทความนี้ เรียนรู้ความแตกต่างที่สำคัญระหว่าง Hadoop และ Spark และเวลาที่คุณควรเลือกอย่างใดอย่างหนึ่ง หรือใช้ร่วมกัน
Hadoop
Hadoop เป็นซอฟต์แวร์ยูทิลิตี้ที่ประกอบด้วยโมดูลหลายตัวที่สร้างระบบนิเวศสำหรับการประมวลผล Big Data หลักการที่ Hadoop ใช้สำหรับการประมวลผลนี้คือการกระจายข้อมูลแบบกระจายเพื่อประมวลผลแบบขนาน

การตั้งค่าระบบจัดเก็บข้อมูลแบบกระจายของ Hadoop ประกอบด้วยคอมพิวเตอร์ทั่วไปหลายเครื่อง ทำให้เกิดคลัสเตอร์หลายโหนด การใช้ระบบนี้ทำให้ Hadoop สามารถประมวลผลข้อมูลที่มีอยู่จำนวนมากได้อย่างมีประสิทธิภาพ โดยการทำงานหลายอย่างพร้อมกัน รวดเร็ว และมีประสิทธิภาพ
ข้อมูลที่ประมวลผลด้วย Hadoop มีได้หลายรูปแบบ สามารถจัดโครงสร้างได้เหมือนตาราง Excel หรือตารางใน DBMS ทั่วไป ข้อมูลนี้ยังสามารถนำเสนอในลักษณะกึ่งโครงสร้าง เช่น ไฟล์ JSON หรือ XML Hadoop ยังรองรับข้อมูลที่ไม่มีโครงสร้าง เช่น รูปภาพ วิดีโอ หรือไฟล์เสียง
องค์ประกอบหลัก
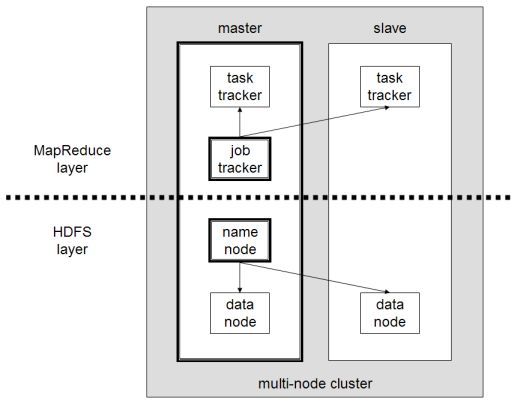
ส่วนประกอบหลักของ Hadoop คือ:
- HDFS หรือ Hadoop Distributed File System คือระบบที่ Hadoop ใช้เพื่อดำเนินการจัดเก็บข้อมูลแบบกระจาย ประกอบด้วยโหนดหลักที่มีข้อมูลเมตาของคลัสเตอร์และโหนดสเลฟหลายโหนดที่เก็บข้อมูลไว้
- MapReduce เป็นโมเดลอัลกอริทึมที่ใช้ในการประมวลผลข้อมูลที่กระจายนี้ รูปแบบการออกแบบนี้สามารถใช้งานได้โดยใช้ภาษาโปรแกรมหลายภาษา เช่น Java, R, Scala, Go, JavaScript หรือ Python มันทำงานภายในแต่ละโหนดในแบบคู่ขนาน
- Hadoop Common ซึ่งยูทิลิตี้และไลบรารีหลายตัวรองรับส่วนประกอบ Hadoop อื่น ๆ
- YARN เป็นเครื่องมือประสานเพื่อจัดการทรัพยากรบนคลัสเตอร์ Hadoop และปริมาณงานที่ดำเนินการโดยแต่ละโหนด นอกจากนี้ยังรองรับการใช้งาน MapReduce ตั้งแต่เวอร์ชัน 2.0 ของเฟรมเวิร์กนี้
Apache Spark

Apache Spark เป็นเฟรมเวิร์กโอเพ่นซอร์สที่สร้างขึ้นโดยนักวิทยาศาสตร์คอมพิวเตอร์ Matei Zaharia ซึ่งเป็นส่วนหนึ่งของปริญญาเอกของเขาในปี 2552 จากนั้นเขาก็เข้าร่วม Apache Software Foundation ในปี 2010
Spark เป็นเครื่องมือคำนวณและประมวลผลข้อมูลที่กระจายในลักษณะกระจายบนหลายโหนด ความจำเพาะหลักของ Spark คือการประมวลผลในหน่วยความจำ เช่น ใช้ RAM เพื่อแคชและประมวลผลข้อมูลขนาดใหญ่ที่แจกจ่ายในคลัสเตอร์ มันให้ประสิทธิภาพที่สูงขึ้นและความเร็วในการประมวลผลที่สูงขึ้นมาก

Spark รองรับงานหลายอย่าง รวมถึงการประมวลผลแบบแบตช์ การประมวลผลแบบเรียลไทม์ แมชชีนเลิร์นนิง และการคำนวณกราฟ นอกจากนี้เรายังสามารถประมวลผลข้อมูลจากหลายระบบ เช่น HDFS, RDBMS หรือแม้แต่ฐานข้อมูล NoSQL การใช้งาน Spark สามารถทำได้ด้วยหลายภาษา เช่น Scala หรือ Python
องค์ประกอบหลัก
องค์ประกอบหลักของ Apache Spark คือ:
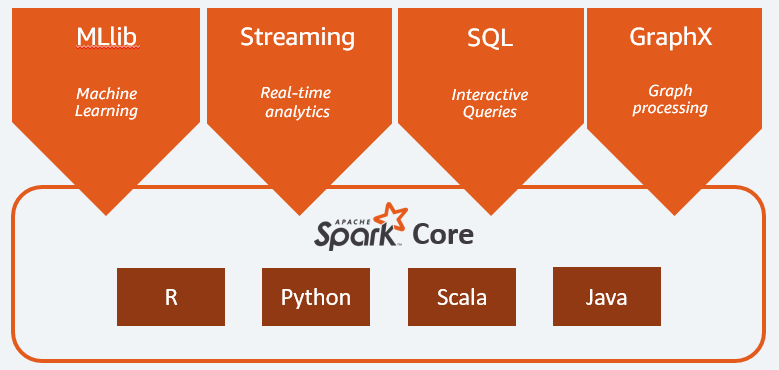
- Spark Core เป็นเอ็นจิ้นทั่วไปของทั้งแพลตฟอร์ม มีหน้าที่รับผิดชอบในการวางแผนและแจกจ่ายงาน ประสานงานการดำเนินการอินพุต/เอาท์พุต หรือการกู้คืนจากความล้มเหลวใดๆ
- Spark SQL เป็นส่วนประกอบที่มีสคีมา RDD ที่สนับสนุนข้อมูลที่มีโครงสร้างและกึ่งโครงสร้าง โดยเฉพาะอย่างยิ่ง มันทำให้เป็นไปได้ที่จะเพิ่มประสิทธิภาพการรวบรวมและการประมวลผลข้อมูลประเภทที่มีโครงสร้างโดยดำเนินการ SQL หรือโดยให้การเข้าถึงเอ็นจิน SQL
- Spark Streaming ซึ่งช่วยให้สามารถวิเคราะห์ข้อมูลสตรีมมิ่งได้ Spark Streaming รองรับข้อมูลจากแหล่งต่างๆ เช่น Flume, Kinesis หรือ Kafka;
- MLib ไลบรารี ในตัวของ Apache Spark สำหรับการเรียนรู้ของเครื่อง มันมีอัลกอริธึมการเรียนรู้ด้วยเครื่องหลายตัวรวมถึงเครื่องมือหลายอย่างเพื่อสร้างไปป์ไลน์การเรียนรู้ด้วยเครื่อง
- GraphX รวมชุดของ API สำหรับการสร้างแบบจำลอง การคำนวณ และการวิเคราะห์กราฟภายในสถาปัตยกรรมแบบกระจาย
Hadoop vs Spark: ความแตกต่าง

Spark เป็นเครื่องมือคำนวณและประมวลผลข้อมูลขนาดใหญ่ ตามทฤษฎีแล้วมันคล้ายกับ Hadoop MapReduce ซึ่งเร็วกว่ามากเนื่องจากทำงานในหน่วยความจำ แล้วอะไรที่ทำให้ Hadoop และ Spark แตกต่างกัน? มาดูกัน:

- Spark มีประสิทธิภาพมากกว่ามาก โดยเฉพาะอย่างยิ่งต้องขอบคุณการประมวลผลในหน่วยความจำ ในขณะที่ Hadoop ดำเนินการเป็นชุด
- Spark มีราคาแพงกว่ามากในแง่ของต้นทุนเนื่องจากต้องใช้ RAM จำนวนมากเพื่อรักษาประสิทธิภาพ ในทางกลับกัน Hadoop อาศัยเครื่องธรรมดาสำหรับการประมวลผลข้อมูลเท่านั้น
- Hadoop เหมาะสมกว่าสำหรับการประมวลผลแบบแบตช์ ในขณะที่ Spark เหมาะสมที่สุดเมื่อจัดการกับข้อมูลการสตรีมหรือสตรีมข้อมูลที่ไม่มีโครงสร้าง
- Hadoop มีความทนทานต่อข้อผิดพลาดมากกว่าเนื่องจากทำซ้ำข้อมูลอย่างต่อเนื่องในขณะที่ Spark ใช้ชุดข้อมูลแบบกระจายที่ยืดหยุ่น (RDD) ซึ่งตัวเองอาศัย HDFS
- Hadoop สามารถปรับขนาดได้มากขึ้น เนื่องจากคุณจำเป็นต้องเพิ่มเครื่องอื่นหากเครื่องที่มีอยู่ไม่เพียงพออีกต่อไป Spark อาศัยระบบของเฟรมเวิร์กอื่นๆ เช่น HDFS เพื่อขยาย
| ปัจจัย | Hadoop | Spark |
| กำลังประมวลผล | การประมวลผลแบทช์ | การประมวลผลในหน่วยความจำ |
| การจัดการไฟล์ | HDFS | ใช้ HDFS ของ Hadoop |
| ความเร็ว | เร็ว | เร็วกว่า 10 ถึง 1,000 เท่า |
| รองรับภาษา | Java, Python, Scala, R, Go และ JavaScript | Java, Python, Scala และ R |
| ค่าเผื่อความผิดพลาด | อดทนมากขึ้น | อดทนน้อยลง |
| ค่าใช้จ่าย | ที่ราคาไม่แพง | แพงมาก |
| ความสามารถในการปรับขนาด | ปรับขนาดได้มากขึ้น | ปรับขนาดได้น้อยลง |
Hadoop เหมาะสำหรับ
Hadoop เป็นทางออกที่ดีหากความเร็วในการประมวลผลไม่สำคัญ ตัวอย่างเช่น หากการประมวลผลข้อมูลสามารถทำได้ในชั่วข้ามคืน ควรพิจารณาใช้ MapReduce ของ Hadoop
Hadoop ช่วยให้คุณสามารถถ่ายชุดข้อมูลขนาดใหญ่จากคลังข้อมูลซึ่งประมวลผลได้ยาก เนื่องจาก HDFS ของ Hadoop ช่วยให้องค์กรมีวิธีการจัดเก็บและประมวลผลข้อมูลที่ดีขึ้น
Spark ดีสำหรับ:
Distributed Datasets (RDD) ที่ยืดหยุ่นของ Spark อนุญาตการดำเนินการแผนที่ในหน่วยความจำหลายรายการ ในขณะที่ Hadoop MapReduce ต้องเขียนผลลัพธ์ระหว่างกาลลงในดิสก์ ซึ่งทำให้ Spark เป็นตัวเลือกที่ต้องการหากคุณต้องการวิเคราะห์ข้อมูลเชิงโต้ตอบแบบเรียลไทม์
การประมวลผลในหน่วยความจำของ Spark และการสนับสนุนสำหรับฐานข้อมูลแบบกระจาย เช่น Cassandra หรือ MongoDB เป็นโซลูชันที่ยอดเยี่ยมสำหรับการย้ายข้อมูลและการแทรกข้อมูล - เมื่อดึงข้อมูลจากฐานข้อมูลต้นทางและส่งไปยังระบบเป้าหมายอื่น
ใช้ Hadoop และ Spark ร่วมกัน

บ่อยครั้งที่คุณต้องเลือกระหว่าง Hadoop และ Spark; อย่างไรก็ตาม ในกรณีส่วนใหญ่ การเลือกอาจไม่จำเป็นเนื่องจากทั้งสองเฟรมเวิร์กสามารถอยู่ร่วมกันและทำงานร่วมกันได้เป็นอย่างดี อันที่จริง เหตุผลหลักที่อยู่เบื้องหลังการพัฒนา Spark คือการปรับปรุง Hadoop แทนที่จะแทนที่มัน
ดังที่เราได้เห็นในหัวข้อก่อนหน้านี้ Spark สามารถรวมเข้ากับ Hadoop โดยใช้ระบบจัดเก็บข้อมูล HDFS อันที่จริง ทั้งคู่ดำเนินการประมวลผลข้อมูลได้เร็วขึ้นภายในสภาพแวดล้อมแบบกระจาย ในทำนองเดียวกัน คุณสามารถจัดสรรข้อมูลบน Hadoop และประมวลผลโดยใช้ Spark หรือเรียกใช้งานภายใน Hadoop MapReduce
บทสรุป
Hadoop หรือ Spark? ก่อนเลือกเฟรมเวิร์ก คุณต้องพิจารณาสถาปัตยกรรมของคุณ และเทคโนโลยีที่ประกอบขึ้นต้องสอดคล้องกับวัตถุประสงค์ที่คุณต้องการบรรลุ นอกจากนี้ Spark ยังเข้ากันได้อย่างสมบูรณ์กับระบบนิเวศ Hadoop และทำงานได้อย่างราบรื่นกับ Hadoop Distributed File System และ Apache Hive
คุณอาจสำรวจเครื่องมือข้อมูลขนาดใหญ่บางอย่าง