
Categorizzazione delle query in base ai risultati delle immagini
Pubblicato: 2022-04-27Google ha recentemente ottenuto un brevetto sulla categorizzazione delle query basata sui risultati delle immagini.
Il brevetto ci dice che: “i motori di ricerca su Internet forniscono informazioni sulle risorse accessibili a Internet (come pagine Web, immagini, documenti di testo, contenuti multimediali) che rispondono alla query di ricerca di un utente restituendo, durante la ricerca di immagini, un insieme di risultati di ricerca di immagini in risposta alla domanda”.
Un risultato di ricerca include, ad esempio, un URL (Uniform Resource Locator) di un'immagine o un documento contenente l'immagine e uno snippet di informazioni.
Classificare le SERP utilizzando una funzione di punteggio
I risultati della ricerca possono essere classificati (ad esempio in ordine) in base ai punteggi assegnati da una funzione di punteggio.
La funzione di punteggio classifica i risultati della ricerca in base a vari segnali:
- Dove (e con quale frequenza) viene visualizzato il testo della query nel testo del documento che circonda un'immagine
- Una didascalia dell'immagine o un testo alternativo per l'idea
- Quanto sono standard i termini della query nei risultati di ricerca indicizzati dal motore di ricerca.
In generale, l'oggetto descritto in questo brevetto è in un metodo che include:
- Ottenere immagini dai risultati della prima immagine per una prima query, in cui un numero di immagini acquisite associate a punteggi e dati sul comportamento dell'utente che affermano l'interazione dell'utente con le immagini ottenute quando le immagini ottenute sono risultati di ricerca per la query
- Selezione di un numero di immagini acquisite ciascuna avente i rispettivi dati di comportamento che soddisfano una soglia
- Associare le prime immagini scelte con più annotazioni basate sull'analisi del contenuto delle immagini selezionate
Questi possono includere facoltativamente le seguenti funzionalità.
La prima query può essere associata a categorie in base alle annotazioni. La categorizzazione della query e le associazioni di annotazione possono essere archiviate per un uso futuro. La seconda immagine risulta reattiva a una seconda query che è la stessa o come la prima query può essere ricevuta.
Ciascuna delle seconde immagini viene associata a un punteggio e la seconda immagine può essere modificata in base alle categorie relative alla prima query.
Una delle categorizzazioni di query può affermare che la prima query è una query di una sola persona e aumenta i punteggi della seconda immagine, le cui annotazioni dicono che l'insieme delle seconde immagini contiene una sola faccia.
Una categorizzazione di query può affermare che la prima query è diversa e aumentare i punteggi delle seconde immagini, le cui annotazioni dicono che l'insieme delle seconde immagini è diverso.
Una delle categorie può affermare che la prima query è una query di testo e aumentare i punteggi della seconda immagine, le cui annotazioni dicono che l'insieme delle seconde immagini contiene il testo.
La prima query può essere fornita a un classificatore addestrato per determinare una categorizzazione della query nelle categorie.
L'analisi del contenuto delle prime immagini selezionate può includere il raggruppamento dei risultati della prima immagine per determinare un'annotazione nelle annotazioni. I dati sul comportamento degli utenti possono essere il numero di volte in cui gli utenti selezionano l'immagine nei risultati di ricerca per la prima query.
L'oggetto descritto in questo brevetto può essere implementato in modo da realizzare i seguenti vantaggi:
Il set di risultati dell'immagine viene analizzato per derivare annotazioni di immagini e una categorizzazione di query e l'interazione dell'utente con i risultati di ricerca di immagini può essere utilizzata per derivare tipi per le query.
Categorizzazione delle query
Le categorie di query possono, a loro volta, migliorare la pertinenza, la qualità e la diversità dei risultati della ricerca di immagini.
La categorizzazione delle query può essere utilizzata anche come parte dell'elaborazione delle query o in un processo offline.
Le categorie di query possono essere utilizzate per fornire suggerimenti di query automatizzati come "mostra solo immagini con volti" o "mostra solo clip art".
Categorizzazione delle query in base ai risultati dell'immagine
Inventori: Anna Majkowska e Cristian Tapus
Assegnatario: GOOGLE LLC
Brevetto USA: 11.308.149
Concesso: 19 aprile 2022
Archiviato: 3 novembre 2017
Astratto
Metodi, sistemi e apparati, compresi programmi per computer codificati su un supporto di memorizzazione per computer, per la categorizzazione di query in base ai risultati delle immagini.
In un aspetto, un metodo include la ricezione di immagini dai risultati dell'immagine che rispondono a una query, in cui ciascuna delle foto viene associata a un ordine nei risultati dell'immagine e ai rispettivi dati sul comportamento dell'utente per l'immagine come risultato di ricerca per la prima query e l'associazione di le prime immagini con una pluralità di annotazioni basate sull'analisi del contenuto delle prime immagini selezionate.
Un sistema che utilizza la categorizzazione delle query per migliorare l'insieme dei risultati restituiti per una query
Un client, come un browser Web o un altro processo in esecuzione su un dispositivo informatico, invia una query di input a un motore di ricerca e il motore di ricerca restituisce i risultati della ricerca di immagini al client. In alcune implementazioni, una query comprende testo come caratteri in un set di caratteri (ad esempio, "pomodoro rosso").
Una query comprende immagini, suoni, video o combinazioni di questi. Sono possibili altri tipi di query. Il motore di ricerca cercherà i risultati in base a versioni di query alternative uguali, più ampie o più specifiche della query di input.
I risultati della ricerca di immagini sono un elenco ordinato o classificato di documenti o collegamenti a tali documenti, che sono determinati per rispondere alla query di input, con i documenti determinati come più rilevanti con il punteggio più alto. Una copia è una pagina web, un'immagine o un altro file elettronico.
Nel caso della ricerca di immagini, il motore di ricerca determina la pertinenza di un'immagine basandosi, almeno in parte, su quanto segue:
- Contenuto dell'immagine
- Il testo che circonda l'immagine
- Didascalia immagine
- Testo alternativo per l'immagine
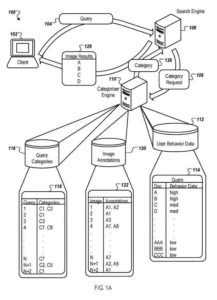
Categorie associate a una query
Nel produrre i risultati della ricerca di immagini, il motore di ricerca in alcune implementazioni invia una richiesta per le categorie associate alla query. Il motore di ricerca può utilizzare le categorie associate per riordinare i risultati della ricerca di immagini aumentando il rango dei risultati di immagini che si ritiene appartengano alle categorie correlate.
In alcuni casi, può ridurre i risultati delle immagini che non appartengono alle categorie associate o a entrambe.
Il motore di ricerca può anche utilizzare le categorie dei risultati per determinare come dovrebbero essere classificati nell'insieme di risultati finalizzato in combinazione con o della categoria di query.
Un motore di classificazione o un altro processo utilizza i risultati delle immagini recuperati per la query e un repository di dati sul comportamento dell'utente per derivare le categorie per la query. Il repository contiene dati sul comportamento dell'utente. L'archiviazione indica il numero di volte in cui le popolazioni di utenti hanno selezionato un risultato di immagine per una determinata query.
La selezione dell'immagine può essere eseguita in vari modi, incluso l'utilizzo della tastiera, del mouse del computer o del gesto del dito, di un comando vocale o di altri metodi. I dati sul comportamento degli utenti includono i "dati sui clic".
Dati clic indica per quanto tempo un utente visualizza o "si sofferma" su un risultato di immagine
I dati sui clic indicano per quanto tempo un utente visualizza o "si sofferma" sul risultato di un'immagine dopo averlo selezionato in un elenco di risultati per la query. Ad esempio, soffermarsi a lungo su un'immagine (ad esempio superiore a 1 minuto), denominata "clic lungo", può affermare che un utente ha trovato l'immagine pertinente alla query dell'utente.
Un breve periodo di visualizzazione di un'immagine (ad es. meno di 30 secondi), definito "clic breve", può essere interpretato come una mancanza di rilevanza dell'immagine. Sono possibili altri tipi di dati sul comportamento degli utenti.
A titolo illustrativo, i dati sul comportamento degli utenti possono essere generati da un processo che crea un record per i documenti dei risultati selezionati dagli utenti in risposta a una query specifica. Ogni form può essere rappresentato come una tupla: <document, query, data>) che include:
- Una domanda posta dagli utenti
- Un riferimento alla query che indica la query
- Un documento fa riferimento a un documento selezionato dagli utenti in risposta alla query
- Aggregazione dei dati sui clic (come il conteggio di ogni tipo di clic) per tutti gli utenti o un sottoinsieme di tutti gli utenti che hanno selezionato il riferimento al documento in risposta alla query.
Sono possibili estensioni di questo approccio basato su tuple ai dati sul comportamento degli utenti. Ad esempio, i dati sul comportamento dell'utente possono essere estesi per includere identificatori specifici della località (come paese o stato) o specifici della lingua.
Con tali identificatori inclusi, una tupla specifica per paese sarebbe costituita dal paese da cui ha avuto origine la query dell'utente e una tupla specifica per la lingua sarebbe costituita dalla lingua della query dell'utente.
Per semplicità di presentazione, i dati sul comportamento dell'utente associati ai documenti A-CCC per la query vengono rappresentati nella tabella come una quantità "alta", "media" o "bassa" di dati sul comportamento dell'utente favorevole (come il comportamento dell'utente dati che indicano la rilevanza tra il documento e la query).
Dati sul comportamento dell'utente per un documento
I dati favorevoli sul comportamento degli utenti per un documento possono indicare che il documento è selezionato dagli utenti quando viene visualizzato nei risultati della query o quando un utente visualizza il documento dopo averlo scelto dai risultati della query, gli utenti visualizzano il documento per un periodo prolungato (come l'utente ritiene che il documento sia pertinente alla domanda).
Il motore di classificazione funziona insieme al motore di ricerca utilizzando i risultati restituiti ei dati sul comportamento dell'utente per determinare le categorie di query e quindi riclassificare i risultati prima che vengano restituiti all'utente.
In generale, per la query (come una query o una forma alternativa della query) specificata nella richiesta della categoria di query, il motore di classificazione analizza i risultati dell'immagine per la query per determinare se la query appartiene a categorie. I risultati delle immagini analizzati in alcune implementazioni sono stati selezionati dagli utenti come risultato di ricerca per la query un numero totale di volte al di sopra di una soglia (ad esempio impostata almeno dieci volte).
Il motore di classificazione analizza tutti i risultati delle immagini recuperati dal motore di ricerca per una determinata query. in altre implementazioni
Il motore di classificazione analizza i risultati dell'immagine per la query in cui una metrica (ad esempio, il numero totale di selezioni o un'altra misura) per i dati sui clic è al di sopra di una soglia.
I risultati dell'immagine possono essere analizzati online utilizzando tecniche di visione artificiale in vari modi, offline o online, durante il processo di punteggio. Le immagini vengono annotate con le informazioni estratte dal loro contenuto visivo.
Annotazioni immagine
Ad esempio, le annotazioni delle immagini possono essere archiviate nell'archivio delle annotazioni. Ogni immagine analizzata (ad esempio, immagine 1, immagine 2, ecc.) viene associata ad annotazioni (ad esempio, A1, A2 e così via) in una foto all'associazione di annotazioni.
Le annotazioni possono includere:
- Il numero di volti nell'immagine
- La dimensione di ogni faccia
- I colori dominanti dell'immagine
- Se un'immagine contiene testo o un grafico
- Se un'immagine è uno screenshot
Inoltre, ogni immagine può essere annotata con un'impronta digitale che può quindi determinare se due immagini sono identiche o identiche.
Successivamente, il motore di classificazione analizza i risultati dell'immagine per una determinata query e le relative annotazioni per determinare le categorie di query. Le associazioni di categorie di query (ad esempio, C1, C2 e così via) per una determinata query (come query 1, query 2, ecc.) possono essere determinate in molti modi, ad esempio utilizzando una semplice euristica o utilizzando un classificatore automatizzato.
Un classificatore di query semplice basato su un'euristica
Ad esempio, un semplice classificatore di query basato su un'euristica può essere utilizzato per determinare il colore dominante desiderato per la query (e se esiste).
L'euristica può essere, ad esempio, che se delle prime 20 immagini cliccate più spesso per la query, almeno il 70% ha un colore dominante rosso, la query può essere classificata come "query rossa". Per tali query, il motore di ricerca può riordinare i risultati recuperati per aumentare il rango di tutte le immagini annotate con il rosso come colore dominante.
La stessa categorizzazione può essere utilizzata con tutti gli altri colori standard. Un vantaggio di questo approccio all'analisi eccessiva del testo della query è che funziona per tutte le lingue senza la necessità di traduzione (ad esempio promuoverà immagini con colore rosso dominante per la domanda "mela rossa" in qualsiasi lingua). È più robusto (in quanto non aumenterà il rango delle immagini rosse per la query "mar rosso").
Un esempio di motore classificatore
Il motore di classificazione può funzionare in modalità online o offline in cui le associazioni di categorie di query vengono archiviate in anticipo (ad esempio, nella tabella) per essere utilizzate dal motore di ricerca durante l'elaborazione delle query.
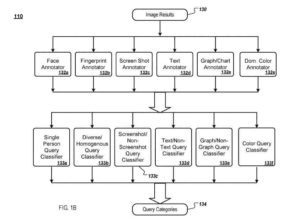
Il motore riceve i risultati dell'immagine della query per una determinata query e fornisce i risultati dell'immagine agli annotatori dell'immagine. Ciascun annotatore dell'immagine analizza i risultati dell'immagine ed estrae informazioni sul contenuto visivo dell'immagine, che vengono archiviate come annotazione dell'immagine (ad es. annotazioni dell'immagine) per l'idea.
Un annotatore di immagini di volti
A titolo illustrativo, un annotatore di immagini di volti:
- Determina quanti volti ci sono in un'immagine e le dimensioni di ogni volto
- un annotatore dell'immagine dell'impronta digitale estrae le caratteristiche dell'immagine visiva in una forma condensata (impronta digitale) che può quindi essere confrontata con l'impronta digitale di un'altra immagine per determinare se le due immagini sono simili
- Un annotatore dell'immagine dello screenshot determina se un'immagine è uno screenshot
- Un annotatore di immagini di testo determina se un'immagine contiene testo
- Una query grafico/immagine grafico determina se un'immagine include grafici o grafici (ad es. grafici a barre)
- Un annotatore del colore dominante determina se un'immagine contiene un colore dominante
È possibile utilizzare anche altri annotatori di immagini. Ad esempio, diversi annotatori di immagini vengono descritti in un documento intitolato "Rilevamento rapido di oggetti utilizzando una cascata potenziata di funzioni semplici", di Viola, P.; Jones, M., Mitsubishi Electric Research Laboratories, TR2004-043 (maggio 2004).
Successivamente, il motore di classificazione analizza i risultati dell'immagine per una determinata query e le relative annotazioni per determinare le categorie di query (ad esempio, le categorie di query). Le categorie di query vengono determinate utilizzando un classificatore e un classificatore di query può essere realizzato utilizzando un sistema di apprendimento automatico.
Uso del potenziamento adattivo
A titolo illustrativo, AdaBoost, abbreviazione di Adaptive Boosting, è un sistema di apprendimento automatico che può essere utilizzato con altri algoritmi di apprendimento per migliorare le proprie prestazioni. AdaBoost viene utilizzato per generare una categorizzazione di query. (Sono possibili più algoritmi di apprendimento)
AdaBoost invoca un annotatore di immagini "debole" in una serie di round. A titolo illustrativo, il classificatore di query a persona singola può basarsi su un algoritmo della macchina di apprendimento addestrato per determinare se una query richiede immagini di una singola persona.
A titolo illustrativo, un tale classificatore di query può essere addestrato con set di dati comprendenti una query, un insieme di vettori di funzionalità che rappresentano immagini dei risultati per la domanda con zero o più facce e la corretta categorizzazione per la query (ad esempio, facce o meno) . Per ogni chiamata, il classificatore di query aggiorna una distribuzione di pesi che indica l'importanza degli esempi nel set di dati di addestramento per la classificazione.
In ogni round, i pesi di ciascun esempio di formazione classificato vengono aumentati (o le conseguenze di ciascun esempio di formazione classificato vengono diminuite), quindi la nuova categorizzazione delle query si concentra maggiormente su tali esempi. La categorizzazione della query addestrata risultante può prendere come input una query e generare una probabilità che la query richieda immagini contenenti singole persone.
Un classificatore di query diversificato/omogeneo prende come input una query e restituisce una probabilità che la query riguardi varie immagini. Il classificatore utilizza un algoritmo di clustering per raggruppare i risultati delle immagini in base alle loro impronte digitali in base a una misura della distanza l'uno dall'altro. Ogni immagine viene associata a un identificatore di cluster.
L'identificatore del cluster di immagini viene utilizzato per determinare il numero di cluster, la dimensione dei gruppi e la somiglianza tra i cluster formati dalle immagini nel set di risultati. Ad esempio, queste informazioni vengono utilizzate per associare una probabilità che la query sia specifica (o che inviti duplicati) o meno,

Associazione di query con significati e rappresentazioni canoniche
La categorizzazione delle query può anche essere utilizzata per associare query a significati e rappresentazioni canoniche. Ad esempio, se è presente un singolo cluster di grandi dimensioni o più cluster di grandi dimensioni, la probabilità che la domanda venga correlata a risultati di immagini duplicate è elevata. Se sono presenti molti cluster più piccoli, la probabilità che la query venga associata agli stessi risultati dell'immagine è bassa.
I duplicati delle immagini di solito non sono molto utili in quanto non forniscono ulteriori informazioni, quindi dovrebbero essere retrocessi come risultati della query. Ma ci sono delle eccezioni. Ad esempio, se sono presenti molti duplicati nei risultati iniziali (pochi cluster di grandi dimensioni), la query è particolare e i duplicati non devono essere retrocessi.
Una categorizzazione di query screenshot/non screenshot prende come input una query e genera una probabilità che la query richieda immagini che sono screenshot. Un classificatore di query di testo/non di testo accetta come input una query e restituisce la possibilità che la query richieda immagini che contengono testo.
Una categorizzazione di query grafico/non grafico accetta un input di una query e genera una probabilità che la query richieda immagini che contengono un grafico o un grafico. Un classificatore di query di colore 133f accetta una query di informazioni e restituisce la possibilità che la query richiami scatti che vengono dominati da un singolo colore. Sono possibili altri classificatori di query.
Miglioramento della pertinenza dei risultati delle immagini in base alla categorizzazione delle query
Un ricercatore può interagire con il sistema tramite un client o un altro dispositivo. Ad esempio, il dispositivo client può essere un terminale di computer all'interno di una rete locale (LAN) o di una rete vasta (WAN). Il dispositivo client può essere un dispositivo mobile (ad es. un telefono cellulare, un computer portatile, un assistente desktop personale, ecc.) in grado di comunicare su una LAN, una WAN o un'altra rete (ad es. una rete di telefoni cellulari).
Il dispositivo client può includere una memoria ad accesso casuale (RAM) (o altra memoria e un dispositivo di archiviazione) e un processore.
Il processore viene strutturato per elaborare istruzioni e dati all'interno del sistema. Il processore è un microprocessore a thread singolo o multi-thread con core di elaborazione. Il processore riceve strutturato per eseguire istruzioni memorizzate nella RAM (o altra memoria e un dispositivo di archiviazione incluso con il dispositivo client) per rendere le informazioni grafiche per un'interfaccia utente.
Un ricercatore può connettersi al motore di ricerca all'interno di un sistema server per inviare una query di input. Il motore di ricerca è un motore di ricerca di immagini o un motore di ricerca generico in grado di recuperare immagini e altri tipi di contenuto come documenti (ad esempio pagine HTML).
Quando l'utente invia la query di input tramite un dispositivo di input collegato a un dispositivo client, una domanda lato client viene inviata in una rete e inoltrata al sistema server come query lato server. Il sistema server può essere costituito da dispositivi server in posizioni. Un dispositivo server include un dispositivo di memoria costituito dal motore di ricerca in esso caricato.
Un processore viene strutturato per elaborare le istruzioni all'interno del dispositivo. Queste istruzioni possono installare componenti del motore di ricerca. Il processore può essere a thread singolo o multi-thread e includere molti core di elaborazione. Il processore può elaborare le istruzioni archiviate nella memoria relative al motore di ricerca e inviare informazioni al dispositivo client attraverso la rete per creare una presentazione grafica nell'interfaccia utente del dispositivo client (ad es. risultati di ricerca su una pagina Web visualizzata in un browser).
La query lato server viene ricevuta dal motore di ricerca. Il motore di ricerca utilizza le informazioni all'interno della query di input (come i termini della query) per trovare i documenti pertinenti. Il motore di ricerca può includere un motore di indicizzazione che ricerca un corpus (ad esempio, pagine Web su Internet) per indicizzare i documenti trovati in quel corpus. Le informazioni di indice per i documenti del corpus possono essere archiviate in un database di indice.
È possibile accedere a questo database dell'indice per identificare i documenti relativi all'utente. Si noti che una copia elettronica (che verrà denominata documento) non corrisponde a un file. Un record può essere archiviato in una parte di un file che contiene altri documenti, in un unico file dedicato al documento in questione o in più file coordinati. Inoltre, una copia può essere archiviata in una memoria senza essere archiviata in un file.
Il motore di ricerca può includere un motore di classificazione per classificare i documenti relativi alla query di input. La classificazione dei documenti può essere eseguita utilizzando le tecniche tradizionali per determinare un punteggio di recupero delle informazioni (IR) per i record indicizzati in base a una determinata query.
Qualsiasi metodo appropriato può determinare la pertinenza di un particolare documento in un termine di ricerca specifico o per altre informazioni fornite. Ad esempio, il livello generale dei collegamenti a ritroso a un documento contenente corrispondenze per un termine di ricerca può essere utilizzato per dedurre la pertinenza di un documento.
In particolare, se un documento viene collegato (ad esempio, è la destinazione di un collegamento ipertestuale) da molti altri documenti rilevanti (come documenti contenenti corrispondenze per i termini di ricerca), si può dedurre che il documento di destinazione è particolarmente rilevante. Questa inferenza può essere fatta perché gli autori dei documenti indicativi presumibilmente puntano, per la maggior parte, ad altri documenti rilevanti per il loro pubblico.
I documenti di puntamento prendono di mira collegamenti da altri documenti rilevanti, che possono essere considerati più rilevanti. Il primo documento è particolarmente appropriato perché si rivolge a documenti applicabili (o anche molto rilevanti).
Tale tecnica può determinare la pertinenza di un documento o uno dei tanti determinanti. Possono anche essere adottati metodi appropriati per identificare e ridurre i tentativi di esprimere voti fraudolenti per aumentare la pertinenza di una pagina.
Per migliorare ulteriormente tali tecniche tradizionali di classificazione dei documenti, il motore di classificazione può ricevere più segnali da un motore di modifica della classificazione per aiutare a determinare una classificazione appropriata per i documenti.
Insieme agli annotatori di immagini e alla categorizzazione delle query sopra descritti, il motore di modifica del rango fornisce misure di pertinenza per i documenti. Il motore di ranking può essere utilizzato per migliorare il ranking dei risultati di ricerca fornito all'utente.
Il motore di modifica del rango può eseguire operazioni per generare le misure di pertinenza.
Se il punteggio del risultato di un'immagine aumenta o diminuisce, dipende dal fatto che il contenuto visivo dell'immagine (come rappresentato nelle annotazioni dell'immagine) corrisponda alla categorizzazione della query, ogni categoria di immagine viene presa in considerazione.
Ad esempio, se la categorizzazione della query è "single persona", il risultato di un'immagine che viene classificato sia come "screenshot" che come "single face" subirà una riduzione del punteggio a causa della categoria "screenshot". Può quindi aumentare il suo punteggio a causa della categoria "faccia singola".
Il motore di ricerca può inoltrare l'elenco dei risultati finali e classificati all'interno dei risultati di ricerca lato server attraverso la rete. Uscendo dalla rete, i risultati della ricerca lato client possono essere ricevuti dal dispositivo client, dove i risultati possono essere archiviati nella RAM e utilizzati dal processore per visualizzare i risultati su un dispositivo di output per l'utente.
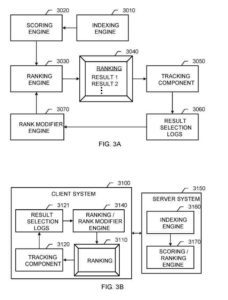
Un sistema di recupero delle informazioni
Questi componenti includono un:
- Motore di indicizzazione
- Motore di punteggio
- Motore di classifica
- Motore di modifica del grado
Il motore di indicizzazione funziona come descritto sopra per il motore di indicizzazione. Il motore di punteggio genera punteggi per i risultati dei documenti in base a molte funzionalità, comprese le funzionalità basate sul contenuto che collegano una query ai risultati del documento e le parti indipendenti dalla query che generalmente indicano la qualità dei risultati dei documenti.
Le funzionalità basate sul contenuto per le immagini includono aspetti del documento che contiene l'immagine, come le corrispondenze delle query al titolo del documento o alla didascalia dell'immagine.
Le funzionalità indipendenti dalla query includono, ad esempio, aspetti del riferimento incrociato del documento del documento o delle dimensioni del dominio o dell'immagine.
Inoltre, le particolari funzioni utilizzate dal motore di punteggio possono essere messe a punto per regolare i vari contributi delle funzioni al punteggio IR finale, utilizzando processi automatici o semiautomatici.
Il motore di classificazione classifica i risultati del documento per la visualizzazione a un utente in base ai punteggi IR ricevuti dalla macchina di punteggio e ai segnali dal motore di modifica del grado.
Il motore di modifica del ranking fornisce misure di rilevanza per i documenti, che il motore di ranking può utilizzare per migliorare il ranking dei risultati di ricerca fornito all'utente. Un componente di monitoraggio registra le informazioni sul comportamento dell'utente, come le selezioni dei singoli utenti dei risultati presentati nell'ordine.
Il componente di monitoraggio ottiene il codice JavaScript incorporato incluso in una classifica della pagina Web che identifica le selezioni utente dei risultati dei singoli documenti e identifica quando l'utente torna alla pagina dei risultati, indicando così la quantità di tempo che l'utente ha trascorso a visualizzare il risultato del documento selezionato.
Il componente di monitoraggio è un sistema proxy attraverso il quale vengono instradate le selezioni utente dei risultati del documento. Il componente di monitoraggio può anche includere software preinstallato per il client (come un plug-in della barra degli strumenti per il sistema operativo del client).
Sono possibili anche altre implementazioni, ad esempio quella che utilizza una funzionalità di un browser Web che consente a un tag/direttiva di essere incluso in una pagina, che richiede al browser di riconnettersi al server con messaggi sui collegamenti cliccati dall'utente.
Le informazioni registrate vengono archiviate nei registri di selezione dei risultati. Le informazioni registrate includono voci di registro che indicano l'interazione dell'utente con ogni documento risultato presentato per ciascuna query inviata.
Per ogni selezione utente di un documento risultato presentato per una query, le voci di registro indicano la query (Q), il documento (D), il tempo di permanenza dell'utente (T) sul documento, la lingua (L) utilizzata dall'utente, e il paese (C) in cui è probabile che l'utente si trovi (ad esempio, in base al server utilizzato per accedere al sistema IR) e un codice regionale (R) che identifica l'area metropolitana dell'utente.
Le voci di registro registrano anche informazioni negative, ad esempio che il risultato di un documento viene presentato a un utente ma non è stato selezionato.
Altre informazioni come:
- Posizioni dei clic (ovvero, selezioni utente nell'interfaccia utente
- Informazioni sulla sessione (come esistenza e tipo di clic precedenti (attività della sessione post-clic))
- Punteggi R dei risultati cliccati
- Punteggi IR di tutti i risultati mostrati prima del clic
- I titoli e gli snippet vengono visualizzati all'utente prima del clic
- Cookie dell'utente
- L'età dei biscotti
- Indirizzo IP (protocollo Internet).
- User-agent del browser
- Presto
Viene registrato anche il tempo (T) tra il click-through iniziale sul risultato del documento e il ritorno degli utenti alla pagina principale e il clic su un altro risultato del documento (o l'invio di una nuova query di ricerca).
Viene effettuata una valutazione sul tempo (T) se questo tempo indica una visualizzazione più lunga del documento o una più breve poiché argomenti più estesi generalmente mostrano qualità o rilevanza per il risultato cliccato. Questa valutazione del tempo (T) può essere effettuata in combinazione con varie tecniche di ponderazione.
I componenti mostrati possono essere combinati in vari modi e configurazioni multiple del sistema. I motori di conteggio finale del punteggio si fondono in un unico motore di classifica, come il motore di classifica. Anche il motore di modifica del grado e il motore di classificazione possono essere uniti. In generale, un motore di classificazione include qualsiasi componente software che genera una classificazione dei risultati del documento dopo una query. Inoltre, un motore di classificazione può adattarsi a un sistema client anche (o piuttosto che) in un sistema server.
Un altro esempio è il sistema di recupero delle informazioni. Il sistema del server include un motore di indicizzazione e un motore di punteggio/classifica.
In questo sistema, un sistema client include:
- Un'interfaccia utente per presentare una classifica
- Un componente di tracciamento
- Registri di selezione dei risultati
- Un motore di modifica della classifica/grado.
Ad esempio, il sistema client può includere la rete aziendale e i personal computer di un'azienda, in cui un plug-in del browser incorpora il motore di modifica della classifica/classifica.
Quando un dipendente dell'azienda avvia una ricerca sul sistema del server, il motore di punteggio/classifica può restituire i risultati della ricerca. Una classifica iniziale o i punteggi IR effettivi per i risultati. Il plug-in del browser riclassifica quindi i risultati in base alle selezioni di pagine tracciate per la base di utenti specifica dell'azienda.
Una tecnica per la categorizzazione delle query
Questa tecnica può essere eseguita online (come parte dell'elaborazione delle query) o offline.
Vengono ricevuti i primi risultati dell'immagine che rispondono alla prima query. Ciascuna delle prime immagini viene associata a un ordine (come un punteggio IR) e ai rispettivi dati sul comportamento dell'utente (come i dati sui clic).
Viene selezionato un certo numero delle prime immagini in cui una metrica per i rispettivi dati di comportamento per ciascuna immagine selezionata soddisfa una soglia.
Le prime immagini selezionate vengono associate a diverse annotazioni in base all'analisi del contenuto delle prime immagini scelte. Le annotazioni dell'immagine possono essere mantenute nelle annotazioni dell'immagine.
Le categorie vengono quindi associate alla prima query in base alle annotazioni.
Le associazioni di categorizzazione delle query possono durare nelle categorie di query.
I risultati della seconda immagine rispondono a una seconda query che è la stessa o viene quindi ricevuta la prima query.
(Se la seconda query non viene trovata nella categorizzazione della query, la seconda query può essere trasformata o "riscritta" per determinare se un modulo alternativo corrisponde a una query nella categorizzazione della query.)
In questo esempio, la seconda query è la stessa o può essere riscritta come la prima query.
I risultati della seconda immagine vengono riordinati in base alla categorizzazione della query prima di essere associati alla prima query.
Cerca notizie direttamente nella tua casella di posta
*Necessario