
Categorización de consultas basada en resultados de imágenes
Publicado: 2022-04-27Google obtuvo recientemente una patente sobre la categorización de consultas basada en resultados de imágenes.
La patente nos dice que: “los motores de búsqueda de Internet brindan información sobre recursos accesibles en Internet (como páginas web, imágenes, documentos de texto, contenido multimedia) en respuesta a la consulta de búsqueda de un usuario al devolver, cuando busca imágenes, un conjunto de resultados de búsqueda de imágenes en respuesta a la consulta.”
Un resultado de búsqueda incluye, por ejemplo, un localizador uniforme de recursos (URL) de una imagen o un documento que contiene la imagen y un fragmento de información.
Clasificación de SERPs utilizando una función de puntuación
Los resultados de la búsqueda se pueden clasificar (por ejemplo, en orden) según las puntuaciones asignadas por una función de puntuación.
La función de puntuación clasifica los resultados de búsqueda según varias señales:
- Dónde (y con qué frecuencia) aparece el texto de consulta en el texto del documento que rodea una imagen
- Una leyenda de imagen o texto alternativo para la idea.
- Cuán estándar son los términos de consulta en los resultados de búsqueda indexados por el motor de búsqueda.
En general, el objeto descrito en esta patente está en un método que incluye:
- La obtención de imágenes a partir de los resultados de la primera imagen para una primera consulta, donde una serie de imágenes adquiridas se asocian con puntajes y datos de comportamiento del usuario que indican la interacción del usuario con las imágenes obtenidas cuando las imágenes obtenidas son resultados de búsqueda para la consulta.
- Seleccionar un número de las imágenes adquiridas, cada una de las cuales tiene datos de comportamiento respectivos que satisfacen un umbral
- Asociar las primeras imágenes elegidas con varias anotaciones basadas en el análisis del contenido de las imágenes seleccionadas
Estos pueden incluir opcionalmente las siguientes características.
La primera consulta se puede asociar con categorías basadas en las anotaciones. Las asociaciones de categorización y anotación de consultas se pueden almacenar para uso futuro. Los resultados de la segunda imagen responden a una segunda consulta que es igual o similar a la primera consulta que se puede recibir.
Cada una de las segundas imágenes se asocia con una puntuación, y la segunda imagen se puede modificar en función de las categorías relacionadas con la primera consulta.
Una de las categorizaciones de consulta puede establecer que la primera consulta es una consulta de una sola persona y aumenta los puntajes de la segunda imagen, cuyas anotaciones dicen que el conjunto de segundas imágenes contiene una sola cara.
Una categorización de consulta puede afirmar que la primera consulta es diversa y aumentar las puntuaciones de las segundas imágenes, cuyas anotaciones dicen que el conjunto de segundas imágenes es diverso.
Una de las categorías puede establecer que la primera consulta es una consulta de texto y aumentar las puntuaciones de la segunda imagen, cuyas anotaciones dicen que el conjunto de segundas imágenes contiene el texto.
La primera consulta se puede proporcionar a un clasificador capacitado para determinar una categorización de consulta en las categorías.
El análisis del contenido de las primeras imágenes seleccionadas puede incluir agrupar los resultados de la primera imagen para determinar una anotación en las anotaciones. Los datos de comportamiento del usuario pueden ser la cantidad de veces que los usuarios seleccionan la imagen en los resultados de búsqueda para la primera consulta.
El tema descrito en esta patente se puede implementar para obtener las siguientes ventajas:
El conjunto de resultados de imágenes se analiza para derivar anotaciones de imágenes y una categorización de consultas, y la interacción del usuario con los resultados de búsqueda de imágenes se puede usar para derivar tipos de consultas.
Categorización de consultas
Las categorías de consulta pueden, a su vez, mejorar la relevancia, la calidad y la diversidad de los resultados de búsqueda de imágenes.
La categorización de consultas también se puede utilizar como parte del procesamiento de consultas o en un proceso fuera de línea.
Las categorías de consulta se pueden utilizar para proporcionar sugerencias de consulta automatizadas, como "mostrar solo imágenes con caras" o "mostrar solo imágenes prediseñadas".
Categorización de consultas basada en resultados de imágenes
Inventores: Anna Majkowska y Cristian Tapus
Cesionario: GOOGLE LLC
Patente de EE. UU.: 11,308,149
Concedido: 19 de abril de 2022
Archivado: 3 de noviembre de 2017
Resumen
Métodos, sistemas y aparatos, incluidos los programas informáticos codificados en un medio de almacenamiento informático, para la categorización de consultas en función de los resultados de las imágenes.
En un aspecto, un método incluye recibir imágenes de resultados de imágenes en respuesta a una consulta, en el que cada una de las fotos se asocia con un orden en los resultados de imágenes y los respectivos datos de comportamiento del usuario para la imagen como resultado de búsqueda para la primera consulta y asociación de las primeras imágenes con una pluralidad de anotaciones basadas en el análisis del contenido de las primeras imágenes seleccionadas.
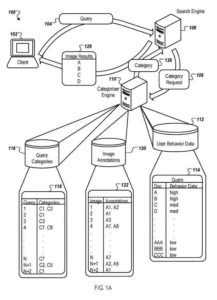
Un sistema que utiliza la categorización de consultas para mejorar el conjunto de resultados devueltos para una consulta
Un cliente, como un navegador web u otro proceso que se ejecuta en un dispositivo informático, envía una consulta de entrada a un motor de búsqueda, y el motor de búsqueda devuelve los resultados de la búsqueda de imágenes al cliente. En algunas implementaciones, una consulta comprende texto como caracteres en un conjunto de caracteres (p. ej., "tomate rojo").
Una consulta comprende imágenes, sonidos, videos o combinaciones de estos. Son posibles otros tipos de consultas. El motor de búsqueda buscará resultados basados en versiones de consulta alternativas iguales, más amplias o más específicas que la consulta de entrada.
Los resultados de la búsqueda de imágenes son una lista ordenada o clasificada de documentos o enlaces a los mismos, que se determina que responden a la consulta de entrada, y los documentos que se determina que son los más relevantes tienen la clasificación más alta. Una copia es una página web, una imagen u otro archivo electrónico.
En el caso de la búsqueda de imágenes, el motor de búsqueda determina la relevancia de una imagen basándose, al menos en parte, en lo siguiente:
- contenido de la imagen
- El texto que rodea la imagen.
- Captura de imagen
- Texto alternativo para la imagen
Categorías asociadas a una consulta
Al producir los resultados de la búsqueda de imágenes, el motor de búsqueda en algunas implementaciones envía una solicitud de categorías asociadas con la consulta. El motor de búsqueda puede usar las categorías asociadas para reordenar los resultados de la búsqueda de imágenes aumentando el rango de los resultados de imágenes que se determina que pertenecen a las categorías relacionadas.
En algunos casos, puede disminuir los resultados de imágenes que no pertenecen a las categorías asociadas o ambas.
El motor de búsqueda también puede usar las categorías de los resultados para determinar cómo deben clasificarse en el conjunto final de resultados en combinación con o de la categoría de consulta.
Un motor de categorización u otro proceso emplea resultados de imágenes obtenidos para la consulta y un depósito de datos de comportamiento del usuario para derivar categorías para la consulta. El repositorio contiene datos de comportamiento del usuario. El almacenamiento indica la cantidad de veces que las poblaciones de usuarios seleccionaron un resultado de imagen para una consulta determinada.
La selección de imágenes se puede lograr de varias maneras, incluido el uso del teclado, el mouse de una computadora o un gesto con el dedo, un comando de voz u otros métodos. Los datos de comportamiento del usuario incluyen "datos de clic".
Los datos de clic indican cuánto tiempo ve un usuario o "permanece" en un resultado de imagen
Los datos de clic indican cuánto tiempo un usuario ve o "permanece" en un resultado de imagen después de seleccionarlo en una lista de resultados para la consulta. Por ejemplo, permanecer mucho tiempo en una imagen (como más de 1 minuto), denominado "clic prolongado", puede indicar que un usuario encontró la imagen relevante para la consulta del usuario.
Un breve período de visualización de una imagen (por ejemplo, menos de 30 segundos), denominado "clic breve", puede interpretarse como una falta de relevancia de la imagen. Son posibles otros tipos de datos de comportamiento del usuario.
A modo de ilustración, los datos de comportamiento del usuario pueden generarse mediante un proceso que crea un registro para los documentos de resultados seleccionados por los usuarios en respuesta a una consulta específica. Cada formulario se puede representar como una tupla: <documento, consulta, datos>) que incluye:
- Una pregunta enviada por los usuarios.
- Una referencia de consulta que indica la consulta.
- Un documento hace referencia a un artículo seleccionado por los usuarios en respuesta a la consulta.
- Agregación de datos de clics (como un recuento de cada tipo de clic) para todos los usuarios o un subconjunto de todos los usuarios que seleccionaron la referencia del documento en respuesta a la consulta.
Las extensiones de este enfoque basado en tuplas a los datos de comportamiento del usuario son posibles. Por ejemplo, los datos de comportamiento del usuario pueden ampliarse para incluir identificadores específicos de ubicación (como país o estado) o específicos de idioma.
Con tales identificadores incluidos, una tupla específica del país consistiría en el país desde donde se originó la consulta del usuario, y una tupla específica del idioma consistiría en el idioma de la consulta del usuario.
Para simplificar la presentación, los datos de comportamiento del usuario asociados con los documentos A-CCC para la consulta se representan en la tabla como una cantidad "alta", "media" o "baja" de datos de comportamiento del usuario favorables (como el comportamiento del usuario). datos que indiquen relevancia entre el documento y la consulta).
Datos de comportamiento del usuario para un documento
Los datos de comportamiento de usuario favorables para un documento pueden indicar que los usuarios seleccionan el documento cuando se ve en los resultados de la consulta, o cuando un usuario ve el documento después de elegirlo de los resultados de la consulta, los usuarios ven el documento para un período prolongado (como cuando el usuario considera que el documento es relevante para la pregunta).
El motor de categorización funciona junto con el motor de búsqueda utilizando los resultados devueltos y los datos de comportamiento del usuario para determinar las categorías de consulta y luego volver a clasificar los resultados antes de devolverlos al usuario.
En general, para la consulta (como una consulta o una forma alternativa de la consulta) especificada en la solicitud de categoría de consulta, el motor categorizador analiza los resultados de la imagen de la consulta para determinar si la consulta pertenece a categorías. Los resultados de imágenes analizados en algunas implementaciones han sido seleccionados por los usuarios como resultado de búsqueda para la consulta un número total de veces por encima de un umbral (como el establecido al menos diez veces).
El motor de categorización analiza todos los resultados de imágenes recuperados por el motor de búsqueda para una consulta determinada. en otras implementaciones
El motor de categorización analiza los resultados de las imágenes para la consulta en la que una métrica (p. ej., el número total de selecciones u otra medida) para los datos de clic está por encima de un umbral.
Los resultados de la imagen se pueden analizar en línea utilizando técnicas de visión por computadora de varias maneras, ya sea fuera de línea o en línea, durante el proceso de puntuación. Las imágenes se anotan con información extraída de su contenido visual.
Anotaciones de imagen
Por ejemplo, las anotaciones de imágenes se pueden almacenar en el almacén de anotaciones. Cada imagen analizada (p. ej., imagen 1, imagen 2, etc.) se asocia con anotaciones (p. ej., A1, A2, etc.) en una asociación de foto a anotación.
Las anotaciones pueden incluir:
- El número de caras en la imagen.
- El tamaño de cada cara.
- Los colores dominantes de la imagen.
- Si una imagen contiene texto o un gráfico
- Si una imagen es una captura de pantalla
Además, cada imagen puede anotarse con una huella digital que luego puede determinar si dos imágenes son idénticas o idénticas.
A continuación, el motor de categorización analiza los resultados de las imágenes para una consulta determinada y sus anotaciones para determinar las categorías de consulta. Las asociaciones de categorías de consulta (p. ej., C1, C2, etc.) para una consulta determinada (como consulta 1, consulta 2, etc.) se pueden determinar de muchas maneras, como mediante una heurística simple o mediante un clasificador automático.
Un categorizador de consulta simple basado en una heurística
Como ejemplo, se puede usar un categorizador de consulta simple basado en una heurística para determinar el color dominante deseado para la consulta (y si hay uno).
La heurística puede ser, por ejemplo, que si de las 20 imágenes principales en las que se hace clic con más frecuencia para la consulta, al menos el 70 % tiene un color rojo dominante, entonces la consulta puede clasificarse como "consulta roja". Para tales consultas, el motor de búsqueda puede reordenar los resultados recuperados para aumentar el rango de todas las imágenes anotadas con rojo como color dominante.
La misma categorización se puede utilizar con todos los demás colores estándar. Una ventaja de este enfoque para analizar en exceso el texto de la consulta es que funciona para todos los idiomas sin necesidad de traducción (por ejemplo, promoverá imágenes con el color rojo dominante para la pregunta "manzana roja" en cualquier idioma). Es más robusto (por ejemplo, no aumentará el rango de las imágenes rojas para la consulta "mar rojo").
Un motor de categorización de ejemplo
El motor de categorización puede funcionar en un modo en línea o fuera de línea en el que las asociaciones de categorías de consultas se almacenan con anticipación (por ejemplo, en la tabla) para que las utilice el motor de búsqueda durante el procesamiento de consultas.
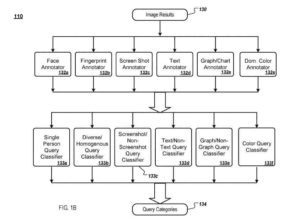
El motor recibe los resultados de la imagen de consulta para una consulta determinada y proporciona los resultados de la imagen a los anotadores de imágenes. Cada anotador de imagen analiza los resultados de la imagen y extrae información sobre el contenido visual de la imagen, que se almacena como una anotación de imagen (p. ej., anotaciones de imagen) para la idea.
Un anotador de imagen de rostro
A modo de ilustración, un anotador de imagen de cara:
- Determina cuántas caras hay en una imagen y el tamaño de cada cara
- un anotador de imágenes de huellas dactilares extrae las características visuales de la imagen en una forma condensada (huella dactilar) que luego se puede comparar con la huella dactilar de otra imagen para determinar si las dos imágenes son similares
- Un anotador de imagen de captura de pantalla determina si una imagen es una captura de pantalla
- Un anotador de imagen de texto determina si una imagen contiene texto
- Una consulta de imagen de gráfico/tabla determina si una imagen incluye gráficos o tablas (p. ej., gráficos de barras)
- Un anotador de color dominante determina si una imagen contiene un color dominante
También se pueden utilizar otros anotadores de imágenes. Por ejemplo, varios anotadores de imágenes se describen en un artículo titulado "Detección rápida de objetos usando una cascada potenciada de funciones simples", por Viola, P.; Jones, M., Mitsubishi Electric Research Laboratories, TR2004-043 (mayo de 2004).
A continuación, el motor del categorizador analiza los resultados de las imágenes para una consulta dada y sus anotaciones para determinar las categorías de consulta (por ejemplo, categorías de consulta). Las categorías de consultas se determinan mediante un clasificador, y un clasificador de consultas se puede realizar mediante un sistema de aprendizaje automático.
Uso de refuerzo adaptativo
A modo de ilustración, AdaBoost, abreviatura de Adaptive Boosting, es un sistema de aprendizaje automático que se puede utilizar con otros algoritmos de aprendizaje para mejorar su rendimiento. AdaBoost se utiliza para generar una categorización de consultas. (Más algoritmos de aprendizaje son posibles)
AdaBoost invoca un anotador de imagen "débil" en una serie de rondas. A modo de ilustración, el clasificador de consultas de una sola persona puede basarse en un algoritmo de máquina de aprendizaje entrenado para determinar si una consulta requiere imágenes de una sola persona.
A modo de ilustración, dicho clasificador de consultas puede entrenarse con conjuntos de datos que comprenden una consulta, un conjunto de vectores de características que representan imágenes de resultados para la pregunta con cero o más caras, y la categorización correcta para la consulta (es decir, caras o no) . Para cada llamada, el clasificador de consultas actualiza una distribución de pesos que indica la importancia de los ejemplos en el conjunto de datos de entrenamiento para la clasificación.
En cada ronda, los pesos de cada ejemplo de entrenamiento clasificado aumentan (o las consecuencias de cada ejemplo de entrenamiento clasificado disminuyen), por lo que la nueva categorización de consultas se enfoca más en esos ejemplos. La categorización de consulta entrenada resultante puede tomar como entrada una consulta y generar una probabilidad de que la consulta solicite imágenes que contengan personas individuales.
Un clasificador de consultas diversas/homogéneas toma como entrada una consulta y genera una probabilidad de que la consulta sea para varias imágenes. El clasificador utiliza un algoritmo de agrupamiento para agrupar los resultados de las imágenes de acuerdo con sus huellas dactilares en función de una medida de distancia entre sí. Cada imagen se asocia con un identificador de clúster.
El identificador de clúster de imágenes se utiliza para determinar la cantidad de clústeres, el tamaño de los grupos y la similitud entre los clústeres formados por imágenes en el conjunto de resultados. Por ejemplo, esta información se utiliza para asociar una probabilidad de que la consulta sea específica (o invite a duplicados) o no,
Asociación de consultas con representaciones y significados canónicos
La categorización de consultas también se puede usar para asociar consultas con representaciones y significados canónicos. Por ejemplo, si hay un solo grupo grande o varios grupos grandes, la probabilidad de que la pregunta se relacione con resultados de imágenes duplicadas es alta. Si hay muchos clústeres más pequeños, la probabilidad de que la consulta se asocie con los mismos resultados de imagen es baja.

Los duplicados de imágenes generalmente no son muy útiles ya que no brindan más información, por lo que deben ser degradados como resultados de la consulta. Pero, hay excepciones. Por ejemplo, si hay muchos duplicados en los resultados iniciales (algunos grupos grandes), la consulta es particular y los duplicados no deben degradarse.
Una categorización de consulta de captura de pantalla/no captura de pantalla toma como entrada una consulta y genera una probabilidad de que la consulta solicite imágenes que sean capturas de pantalla. Un clasificador de consulta de texto/no texto acepta como entrada una consulta y genera la posibilidad de que la consulta solicite imágenes que contengan texto.
Una categorización de consulta de gráfico/no gráfico toma una entrada de una consulta y genera una probabilidad de que la consulta solicite imágenes que contengan un gráfico o un gráfico. Un clasificador de consulta de color 133f toma una consulta de información y genera la posibilidad de que la consulta llame a tiros que sean dominados por un solo color. Son posibles otros clasificadores de consultas.
Mejora de la relevancia de los resultados de imágenes en función de la categorización de consultas
Un buscador puede interactuar con el sistema a través de un cliente u otro dispositivo. Por ejemplo, el dispositivo cliente puede ser un terminal de computadora dentro de una red de área local (LAN) o una red de área extensa (WAN). El dispositivo cliente puede ser un dispositivo móvil (por ejemplo, un teléfono móvil, una computadora móvil, un asistente de escritorio personal, etc.) capaz de comunicarse a través de una LAN, una WAN o alguna otra red (por ejemplo, una red de telefonía celular).
El dispositivo cliente puede incluir una memoria de acceso aleatorio (RAM) (u otra memoria y un dispositivo de almacenamiento) y un procesador.
El procesador se estructura para procesar instrucciones y datos dentro del sistema. El procesador es un microprocesador de subproceso único o de subprocesos múltiples que tiene núcleos de procesamiento. El procesador recibe instrucciones estructuradas para ejecutar almacenadas en la RAM (u otra memoria y un dispositivo de almacenamiento incluido con el dispositivo del cliente) para generar información gráfica para una interfaz de usuario.
Un buscador puede conectarse al motor de búsqueda dentro de un sistema de servidor para enviar una consulta de entrada. El motor de búsqueda es un motor de búsqueda de imágenes o un motor de búsqueda genérico que puede recuperar imágenes y otros tipos de contenido, como documentos (por ejemplo, páginas HTML).
Cuando el usuario envía la consulta de entrada a través de un dispositivo de entrada conectado a un dispositivo cliente, se envía una pregunta del lado del cliente a una red y se reenvía al sistema del servidor como una consulta del lado del servidor. El sistema de servidor puede ser dispositivos de servidor en ubicaciones. Un dispositivo de servidor incluye un dispositivo de memoria que consta del motor de búsqueda cargado en el mismo.
Un procesador se estructura para procesar instrucciones dentro del dispositivo. Estas instrucciones pueden instalar componentes del motor de búsqueda. El procesador puede ser de subproceso único o multiproceso e incluir muchos núcleos de procesamiento. El procesador puede procesar instrucciones almacenadas en la memoria relacionadas con el motor de búsqueda y enviar información al dispositivo cliente a través de la red para crear una presentación gráfica en la interfaz de usuario del dispositivo cliente (p. ej., resultados de búsqueda en una página web mostrada en un sitio web). navegador).
La consulta del lado del servidor es recibida por el motor de búsqueda. El motor de búsqueda utiliza la información dentro de la consulta de entrada (como los términos de consulta) para encontrar documentos relevantes. El motor de búsqueda puede incluir un motor de indexación que busca en un corpus (por ejemplo, páginas web en Internet) para indexar los documentos encontrados en ese corpus. La información de índice para los documentos del corpus se puede almacenar en una base de datos de índice.
Se puede acceder a esta base de datos de índice para identificar documentos relacionados con el usuario. Tenga en cuenta que una copia electrónica (que se denominará documento) no corresponde a un archivo. Un registro puede almacenarse en una parte de un archivo que contiene otros documentos, en un solo archivo dedicado al documento en cuestión o en muchos archivos coordinados. Además, una copia puede almacenarse en una memoria sin almacenarse en un archivo.
El motor de búsqueda puede incluir un motor de clasificación para clasificar los documentos relacionados con la consulta de entrada. La clasificación de los documentos se puede realizar utilizando técnicas tradicionales para determinar una puntuación de recuperación de información (IR) para registros indexados dada una consulta determinada.
Cualquier método apropiado puede determinar la relevancia de un documento en particular en un término de búsqueda específico o para otra información proporcionada. Por ejemplo, el nivel general de vínculos de retroceso a un documento que contiene coincidencias para un término de búsqueda puede usarse para inferir la relevancia de un documento.
En particular, si un documento se vincula (por ejemplo, es el destino de un hipervínculo) por muchos otros documentos relevantes (como documentos que contienen coincidencias para los términos de búsqueda), se puede inferir que el documento de destino es particularmente relevante. Esta inferencia se puede hacer porque los autores de los documentos señalados presumiblemente apuntan, en su mayor parte, a otros documentos que son relevantes para su audiencia.
Los documentos de referencia apuntan a enlaces de otros documentos relevantes, que pueden considerarse más relevantes. El primer documento es particularmente apropiado porque se dirige a documentos aplicables (o incluso muy relevantes).
Tal técnica puede determinar la relevancia de un documento o uno de muchos determinantes. También se pueden tomar métodos apropiados para identificar y eliminar los intentos de emitir votos fraudulentos para aumentar la relevancia de una página.
Para mejorar aún más dichas técnicas tradicionales de clasificación de documentos, el motor de clasificación puede recibir más señales de un motor modificador de clasificación para ayudar a determinar una clasificación adecuada para los documentos.
Junto con los anotadores de imágenes y la categorización de consultas descritas anteriormente, el motor de modificación de clasificación proporciona medidas de relevancia para los documentos. El motor de clasificación puede usarse para mejorar la clasificación de los resultados de búsqueda proporcionados al usuario.
El motor de modificación de rango puede realizar operaciones para generar las medidas de relevancia.
Si la puntuación del resultado de una imagen aumenta o disminuye depende de si el contenido visual de la imagen (tal como se representa en las anotaciones de la imagen) coincide con la categorización de la consulta, se considera cada categoría de imagen.
Por ejemplo, si la categorización de la consulta es "una sola persona", el resultado de una imagen que se clasifique como "captura de pantalla" y "cara única" primero vería reducido su puntaje debido a la categoría "captura de pantalla". Luego puede aumentar su puntaje debido a la categoría de "cara única".
El motor de búsqueda puede reenviar la lista final de resultados clasificados dentro de los resultados de búsqueda del lado del servidor a través de la red. Al salir de la red, el dispositivo cliente puede recibir los resultados de la búsqueda del lado del cliente, donde los resultados pueden almacenarse en la RAM y ser utilizados por el procesador para mostrar los resultados en un dispositivo de salida para el usuario.
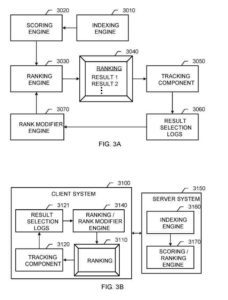
Un sistema de recuperación de información
Estos componentes incluyen:
- Motor de indexación
- motor de puntuación
- Motor de clasificación
- Motor modificador de rango
El motor de indexación funciona como se describe anteriormente para el motor de indexación. El motor de puntuación genera puntuaciones para los resultados de los documentos en función de muchas características, incluidas las características basadas en el contenido que vinculan una consulta a los resultados del documento y partes independientes de la consulta que generalmente indican la calidad de los resultados de los documentos.
Las funciones basadas en contenido para imágenes incluyen aspectos del documento que contiene la imagen, como coincidencias de consulta con el título del documento o el título de la imagen.
Las características independientes de la consulta incluyen, por ejemplo, aspectos de referencias cruzadas de documentos del papel o el dominio o las dimensiones de la imagen.
Además, las funciones particulares utilizadas por el motor de puntuación pueden ajustarse para ajustar las distintas contribuciones de características a la puntuación IR final, utilizando procesos automáticos o semiautomáticos.
El motor de clasificación clasifica los resultados de los documentos para mostrarlos a un usuario en función de las puntuaciones de IR recibidas de la máquina de puntuación y las señales del motor modificador de clasificación.
El motor de modificación de clasificación proporciona medidas de relevancia para los documentos, que el motor de clasificación puede utilizar para mejorar la clasificación de los resultados de búsqueda proporcionados al usuario. Un componente de seguimiento registra la información del comportamiento del usuario, como selecciones de usuarios individuales de los resultados presentados en el pedido.
El componente de seguimiento obtiene un código JavaScript incrustado incluido en una clasificación de página web que identifica las selecciones de usuario de resultados de documentos individuales e identifica cuándo el usuario regresa a la página de resultados, lo que indica la cantidad de tiempo que el usuario pasó viendo el resultado del documento seleccionado.
El componente de seguimiento es un sistema proxy a través del cual se enrutan las selecciones del usuario de los resultados del documento. El componente de seguimiento también puede incluir software preinstalado para el cliente (como un complemento de barra de herramientas para el sistema operativo del cliente).
También son posibles otras implementaciones, por ejemplo, una que utiliza una función de un navegador web que permite incluir una etiqueta/directiva en una página, que solicita al navegador que se conecte de nuevo al servidor con mensajes sobre enlaces en los que el usuario hizo clic.
La información registrada se almacena en registros de selección de resultados. La información registrada incluye entradas de registro que indican la interacción del usuario con cada documento de resultado presentado para cada consulta enviada.
Para cada selección de usuario de un documento de resultado presentado para una consulta, las entradas de registro indican la consulta (Q), el papel (D), el tiempo de permanencia del usuario (T) en el documento, el idioma (L) empleado por el usuario, y el país (C) donde probablemente se encuentra el usuario (p. ej., según el servidor utilizado para acceder al sistema IR) y un código de región (R) que identifica el área metropolitana del usuario.
Las entradas de registro también registran información negativa, como que el resultado de un documento se presenta a un usuario pero no se seleccionó.
Otra información como:
- Posiciones de clics (es decir, selecciones de usuario en la interfaz de usuario
- Información sobre la sesión (como la existencia y el tipo de clics anteriores (actividad de la sesión posterior al clic))
- Puntuaciones R de los resultados en los que se hizo clic
- Puntuaciones IR de todos los resultados mostrados antes de hacer clic
- Los títulos y fragmentos se muestran al usuario antes del clic.
- Cookie del usuario
- Antigüedad de las cookies
- Dirección IP (Protocolo de Internet)
- User-agent del navegador
- Pronto
También se registra el tiempo (T) entre el clic inicial en el resultado del documento y los usuarios que regresan a la página principal y hacen clic en otro resultado del documento (o envían una nueva consulta de búsqueda).
Se realiza una evaluación sobre el tiempo (T) sobre si este tiempo indica una vista más larga del documento o una más corta, ya que los argumentos más extensos generalmente muestran calidad o relevancia para el resultado del clic. Esta evaluación del tiempo (T) se puede realizar junto con varias técnicas de ponderación.
Los componentes que se muestran se pueden combinar de varias maneras y múltiples configuraciones de sistema. Los motores de tanques finales de puntuación se fusionan en un solo motor de clasificación, como el motor de clasificación. El motor de modificación de clasificación y el motor de clasificación también se pueden fusionar. En general, un motor de clasificación incluye cualquier componente de software que genera una clasificación de resultados de documentos después de una consulta. Además, un motor de clasificación también puede encajar en un sistema cliente (o en lugar de) en un sistema servidor.
Otro ejemplo es el sistema de recuperación de información. El sistema del servidor incluye un motor de indexación y un motor de puntuación/clasificación.
En este sistema, un sistema cliente incluye:
- Una interfaz de usuario para presentar una clasificación
- Un componente de seguimiento
- Registros de selección de resultados
- Un motor de clasificación/modificador de clasificación.
Por ejemplo, el sistema cliente puede incluir la red empresarial de una empresa y los ordenadores personales, en los que un complemento de navegador incorpora el motor de clasificación/modificador de clasificación.
Cuando un empleado de la empresa inicia una búsqueda en el sistema del servidor, el motor de puntuación/clasificación puede devolver los resultados de la búsqueda. Una clasificación inicial o las puntuaciones IR reales de los resultados. Luego, el complemento del navegador vuelve a clasificar los resultados en función de las selecciones de páginas rastreadas para la base de usuarios específica de la empresa.
Una técnica para la categorización de consultas
Esta técnica se puede realizar en línea (como parte del procesamiento de consultas) o fuera de línea.
Se reciben los primeros resultados de imagen que responden a la primera consulta. Cada una de las primeras imágenes se asocia con un pedido (como un puntaje IR) y los datos de comportamiento del usuario respectivo (como los datos de clic).
Se selecciona un número de las primeras imágenes donde una métrica para los datos de comportamiento respectivos para cada imagen seleccionada satisface un umbral.
Las primeras imágenes seleccionadas se asocian con varias anotaciones basadas en el análisis de contenido de las primeras imágenes elegidas. Las anotaciones de imagen pueden persistir en las anotaciones de imagen.
Luego, las categorías se asocian con la primera consulta en función de las anotaciones.
Las asociaciones de categorización de consulta pueden durar en categorías de consulta.
Luego se reciben los resultados de la segunda imagen que responden a una segunda consulta que es la misma o la primera consulta.
(Si la segunda consulta no se encuentra en la categorización de consultas, la segunda consulta puede transformarse o "reescribirse" para determinar si una forma alternativa coincide con una consulta en la categorización de consultas).
En este ejemplo, la segunda consulta es igual o se puede reescribir como la primera consulta.
Los resultados de la segunda imagen se reordenan en función de la categorización de la consulta antes de asociarse con la primera consulta.
Busque noticias directamente en su bandeja de entrada
*Requerido