
基於圖像結果的查詢分類
已發表: 2022-04-27谷歌最近獲得了一項基於圖像結果的查詢分類的專利。
該專利告訴我們:“互聯網搜索引擎通過在圖像搜索時返回一組圖像搜索結果來響應用戶的搜索查詢,從而提供有關互聯網可訪問資源(例如網頁、圖像、文本文檔、多媒體內容)的信息。回應詢問。”
搜索結果包括例如圖像或包含圖像的文檔的統一資源定位符(URL)和信息片段。
使用評分函數對 SERP 進行排名
可以根據評分函數分配的分數對搜索結果進行排名(例如按順序)。
評分功能根據各種信號對搜索結果進行排名:
- 查詢文本出現在圖像周圍的文檔文本中的位置(以及頻率)
- 想法的圖像標題或替代文本
- 查詢詞在搜索引擎索引的搜索結果中的標準程度。
通常,本專利中描述的主題是一種方法,包括:
- 從第一圖像獲取圖像結果用於第一查詢,其中獲取的圖像的數量與分數和用戶行為數據相關聯,當獲取的圖像是查詢的搜索結果時,用戶行為數據說明用戶與獲取的圖像的交互
- 選擇多個獲取的圖像,每個圖像具有滿足閾值的相應行為數據
- 基於對所選圖像內容的分析,將所選第一張圖像與多個註釋相關聯
這些可以選擇包括以下功能。
第一個查詢可以與基於註釋的類別相關聯。 可以存儲查詢分類和註釋關聯以供將來使用。 響應於與第一查詢相同或相似的第二查詢的第二圖像結果可以被接收。
第二個圖像中的每一個都與一個分數相關聯,並且可以根據與第一個查詢相關的類別來修改第二個圖像。
其中一個查詢分類可以說明第一個查詢是單人查詢並增加第二個圖像的分數,第二個圖像的註釋說第二個圖像的集合包含一個人臉。
一個查詢分類可以說明第一個查詢是多樣化的,並增加第二個圖像的分數,其註釋表明第二個圖像的集合是多樣化的。
其中一個類別可以說明第一個查詢是文本查詢並增加第二個圖像的分數,其註釋說第二個圖像的集合包含文本。
可以將第一個查詢提供給經過訓練的分類器以確定類別中的查詢分類。
對所選第一圖像的內容的分析可以包括對第一圖像結果進行聚類以確定註釋中的註釋。 用戶行為數據可以是用戶在第一次查詢的搜索結果中選擇圖像的次數。
本專利所描述的主題可以得到實施,從而實現以下優點:
分析圖像結果集以導出圖像註釋和查詢分類,並且用戶與圖像搜索結果的交互可用於導出查詢類型。
查詢分類
反過來,查詢類別可以提高圖像搜索結果的相關性、質量和多樣性。
查詢分類也可以用作查詢處理的一部分或用於離線過程。
查詢類別可用於提供自動查詢建議,例如“僅顯示帶面孔的圖像”或“僅顯示剪貼畫”。
基於圖像結果的查詢分類
發明人:Anna Majkowska 和 Cristian Tapus
受讓人:谷歌有限責任公司
美國專利:11,308,149
授予:2022 年 4 月 19 日
提交日期:2017 年 11 月 3 日
抽象的
用於基於圖像結果進行查詢分類的方法、系統和裝置,包括編碼在計算機存儲介質上的計算機程序。
在一個方面,一種方法包括從響應於查詢的圖像結果接收圖像,其中每張照片與圖像結果中的順序和圖像的相應用戶行為數據相關聯,作為第一查詢的搜索結果,並且關聯基於對所選第一圖像的內容的分析,具有多個註釋的第一圖像。
使用查詢分類改進查詢返回的結果集的系統
諸如網絡瀏覽器或在計算設備上執行的其他進程的客戶端向搜索引擎提交輸入查詢,並且搜索引擎將圖像搜索結果返回給客戶端。 在一些實施方式中,查詢包括文本,例如字符集中的字符(例如,“紅番茄”)。
查詢包括圖像、聲音、視頻或這些的組合。 其他查詢類型也是可能的。 搜索引擎將根據與輸入查詢相同、更廣泛或更具體的替代查詢版本來搜索結果。
圖像搜索結果是被確定為響應輸入查詢的文檔或鏈接的有序或排序列表,其中被確定為最相關的文檔具有最高排序。 副本是網頁、圖像或其他電子文件。
在圖像搜索的情況下,搜索引擎至少部分基於以下內容來確定圖像的相關性:
- 圖片內容
- 圖片周圍的文字
- 圖片說明
- 圖像的替代文本
與查詢相關的類別
在產生圖像搜索結果時,搜索引擎在一些實施方式中提交對與查詢相關聯的類別的請求。 搜索引擎可以使用相關類別通過增加確定屬於相關類別的圖像結果的排名來重新排序圖像搜索結果。
在某些情況下,它可能會減少不屬於相關類別或兩者的圖像結果。
搜索引擎還可以使用結果的類別來確定它們應該如何在最終確定的結果集中與查詢類別或查詢類別相結合。
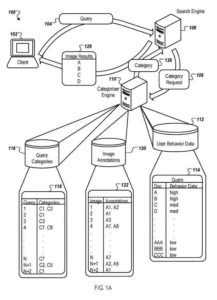
分類器引擎或其他過程使用為查詢檢索的圖像結果和用戶行為數據存儲庫來導出查詢的類別。 存儲庫包含用戶行為數據。 存儲指示用戶群體為給定查詢選擇圖像結果的次數。
圖像選擇可以以各種方式完成,包括使用鍵盤、計算機鼠標或手指手勢、語音命令或其他方法。 用戶行為數據包括“點擊數據”。
單擊數據指示用戶查看或“停留”圖像結果的時間
點擊數據表示用戶在查詢的結果列表中選擇圖像結果後查看或“停留”多長時間。 例如,長時間停留在圖像上(例如超過 1 分鐘),稱為“長點擊”,可以說明用戶找到了與用戶查詢相關的圖像。
查看圖像的短暫時間(例如,少於 30 秒),稱為“短點擊”,可被解釋為缺乏圖像相關性。 其他類型的用戶行為數據是可能的。
舉例來說,用戶行為數據可以由為用戶響應特定查詢而選擇的結果文檔創建記錄的過程生成。 每個表單都可以表示為一個元組:<document, query, data>),其中包括:
- 用戶提交的問題
- 指示查詢的查詢引用
- 文檔引用用戶響應查詢選擇的論文
- 為響應查詢選擇文檔引用的所有用戶或所有用戶子集的點擊數據聚合(例如每種點擊類型的計數)。
將這種基於元組的方法擴展到用戶行為數據是可能的。 例如,用戶行為數據可以擴展為包括特定位置(例如國家或州)或特定語言的標識符。
包含此類標識符後,特定於國家/地區的元組將由用戶查詢起源的國家/地區組成,而特定於語言的元組將由用戶查詢的語言組成。
為簡單起見,與查詢的文檔 A-CCC 關聯的用戶行為數據在表中被描述為“高”、“中”或“低”量的有利用戶行為數據(例如用戶行為指示文檔和查詢之間相關性的數據)。
文檔的用戶行為數據
文檔的有利用戶行為數據可以表明,當在查詢結果中查看該論文時,用戶選擇了該論文,或者當用戶從查詢結果中選擇該文檔後查看該文檔時,用戶查看該文檔的目的是延長時間(例如用戶發現文檔與問題相關)。
分類器引擎與搜索引擎一起使用返回的結果和用戶行為數據來確定查詢類別,然後在結果返回給用戶之前對其進行重新排序。
通常,對於查詢類別請求中指定的查詢(例如查詢或查詢的替代形式),分類器引擎分析查詢的圖像結果以確定查詢是否屬於類別。 在某些實施方式中分析的圖像結果已被用戶選擇作為查詢的搜索結果,總次數超過閾值(例如設置至少十次)。
分類器引擎分析搜索引擎針對給定查詢檢索到的所有圖像結果。 在其他實現中
分類器引擎分析查詢的圖像結果,其中點擊數據的度量(例如,選擇的總數或其他度量)高於閾值。
在評分過程中,可以使用計算機視覺技術以各種方式(離線或在線)在線分析圖像結果。 圖像使用從其視覺內容中提取的信息進行註釋。
圖像註釋
例如,圖像註釋可以存儲在註釋存儲中。 每個分析的圖像(例如,圖像 1、圖像 2 等)都與照片中的註釋(例如,A1、A2 等)關聯到註釋關聯。
註釋可以包括:
- 圖像中的人臉數量
- 每張臉的大小
- 圖像的主要顏色
- 圖片是否包含文字或圖表
- 圖片是否為截圖
此外,每個圖像都可以使用指紋進行註釋,然後可以確定兩個圖像是否相同或相同。
接下來,分類器引擎分析給定查詢的圖像結果及其註釋以確定查詢類別。 可以以多種方式確定給定查詢(例如查詢1、查詢2等)的查詢類別(例如C1、C2等)的關聯,例如使用簡單的啟發式或使用自動分類器。
基於啟發式的簡單查詢分類器
例如,可以使用基於啟發式的簡單查詢分類器來確定查詢所需的主色(以及是否存在主色)。
例如,啟發式方法可以是,如果在查詢的前 20 個最常點擊的圖像中,至少 70% 的主色為紅色,則查詢可以被歸類為“紅色查詢”。 對於這樣的查詢,搜索引擎可以對檢索到的結果重新排序,以增加所有以紅色作為主色註釋的圖像的排名。
相同的分類可以用於所有其他標準顏色。 這種過度分析查詢文本的方法的一個優點是它適用於所有語言而無需翻譯(例如,它會為任何語言的問題“紅蘋果”推廣具有主要紅色的圖像)。 它更健壯(例如它不會增加查詢“紅海”的紅色圖像的排名)。
一個示例分類引擎
分類器引擎可以在線模式或離線模式下工作,其中查詢類別關聯被提前存儲(例如,在表中)以供搜索引擎在查詢處理期間使用。
引擎接收給定查詢的查詢圖像結果,並將圖像結果提供給圖像註釋器。 每個圖像註釋器分析圖像結果並提取有關圖像視覺內容的信息,這些信息被存儲為想法的圖像註釋(例如,圖像註釋)。
人臉圖像註釋器
舉例來說,一個人臉圖像註釋器:
- 確定圖像中有多少張臉以及每張臉的大小
- 指紋圖像註釋器以壓縮形式(指紋)提取視覺圖像特徵,然後可以將其與另一幅圖像的指紋進行比較,以確定兩幅圖像是否相似
- 屏幕截圖圖像註釋器確定圖像是否為屏幕截圖
- 文本圖像註釋器確定圖片是否包含文本
- 圖形/圖表圖像查詢確定圖像是否包括圖形或圖表(例如,條形圖)
- 主色註釋器確定圖片是否包含主色
也可以使用其他圖像註釋器。 例如,Viola, P. 的一篇題為“Rapid Object Detection Using a Boosted Cascade of Simple Features”的論文中描述了幾個圖像註釋器; Jones, M.,三菱電機研究實驗室,TR2004-043(2004 年 5 月)。
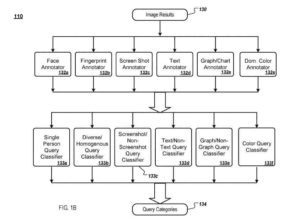
接下來,分類器引擎分析給定查詢的圖像結果及其註釋以確定查詢類別(例如,查詢類別)。 查詢類別是通過分類器確定的,查詢分類器可以通過機器學習系統來實現。
使用自適應提升
舉例來說,AdaBoost 是 Adaptive Boosting 的縮寫,是一種機器學習系統,可與其他學習算法一起使用以提高其性能。 AdaBoost 用於生成查詢分類。 (更多的學習算法是可能的)
AdaBoost 在一系列輪次中調用“弱”圖像註釋器。 舉例來說,單人查詢分類器可以基於經過訓練以確定查詢是否需要單人圖像的學習機算法。
舉例來說,這樣的查詢分類器可以使用包括查詢的數據集、表示具有零個或多個面孔的問題的結果圖像的一組特徵向量以及查詢的正確分類(即,面孔與否)進行訓練. 對於每次調用,查詢分類器都會更新一個權重分佈,該分佈指示訓練數據集中示例對分類的重要性。
在每一輪中,每個分類訓練示例的權重都會增加(或每個分類訓練示例的結果會減少),因此新的查詢分類更多地關注這些示例。 生成的經過訓練的查詢分類可以將查詢作為輸入,並輸出查詢要求包含單個人的圖像的概率。
多樣化/同質查詢分類器將查詢作為輸入,並輸出查詢針對各種圖像的概率。 分類器使用聚類算法根據彼此之間的距離度量根據指紋對圖像結果進行聚類。 每個圖像都與一個集群標識符相關聯。
圖像聚類標識符用於確定聚類的數量、組的大小以及結果集中圖像形成的聚類之間的相似性。 例如,此信息用於關聯查詢是否特定(或邀請重複)的概率,
將查詢與規範含義和表示相關聯
查詢分類也可以用來將查詢與規範含義和表示相關聯。 例如,如果有單個大簇或幾個大簇,則問題與重複圖像結果相關的概率很高。 如果有許多較小的集群,則查詢與相同圖像結果相關聯的可能性很低。
圖像的副本通常不是很有用,因為它們沒有提供更多信息,因此它們應該被降級為查詢結果。 但是,也有例外。 例如,如果初始結果中有很多重複項(少數,大型集群),則查詢是特定的,重複項不應被降級。
屏幕截圖/非屏幕截圖查詢分類將查詢作為輸入,並輸出查詢調用屏幕截圖圖像的概率。 文本/非文本查詢分類器接受查詢作為輸入,並輸出查詢調用包含文本的圖像的機會。
圖形/非圖形查詢分類接受查詢的輸入並輸出查詢調用包含圖形或圖表的圖像的概率。 顏色查詢分類器133f接受信息查詢並輸出查詢調用由單一顏色支配的鏡頭的機會。 其他查詢分類器是可能的。
基於查詢分類提高圖像結果的相關性
搜索者可以通過客戶端或其他設備與系統交互。 例如,客戶端設備可以是局域網(LAN)或廣域網(WAN)內的計算機終端。 客戶端設備可以是能夠通過LAN、WAN或一些其他網絡(例如,蜂窩電話網絡)進行通信的移動設備(例如,移動電話、移動計算機、個人桌面助理等)。
客戶端設備可以包括隨機存取存儲器(RAM)(或其他存儲器和存儲設備)和處理器。
處理器被結構化以處理系統內的指令和數據。 處理器是具有處理核心的單線程或多線程微處理器。 處理器接收結構化以執行存儲在RAM(或客戶端設備所包括的其他存儲器和存儲設備)中的指令,以呈現用於用戶界面的圖形信息。
搜索者可以連接到服務器系統內的搜索引擎以提交輸入查詢。 搜索引擎是可以檢索圖像和其他類型的內容(例如文檔(例如,HTML頁面))的圖像搜索引擎或通用搜索引擎。
當用戶通過連接到客戶端設備的輸入設備提交輸入查詢時,客戶端問題被發送到網絡並作為服務器端查詢轉發到服務器系統。 服務器系統可以是位置中的服務器設備。 服務器設備包括由加載在其中的搜索引擎組成的存儲設備。
處理器被結構化以處理設備內的指令。 這些說明可以安裝搜索引擎的組件。 處理器可以是單線程或多線程的,並且包括許多處理核心。 處理器可以處理存儲在存儲器中的與搜索引擎相關的指令,並通過網絡向客戶端設備發送信息,以在客戶端設備的用戶界面中創建圖形表示(例如,在網頁中顯示的網頁上的搜索結果)瀏覽器)。

服務器端查詢被搜索引擎接收。 搜索引擎使用輸入查詢中的信息(例如查詢詞)來查找相關文檔。 搜索引擎可以包括搜索語料庫(例如,因特網上的網頁)以索引在該語料庫中找到的文檔的索引引擎。 語料庫文檔的索引信息可以存儲在索引數據庫中。
可以訪問該索引數據庫以識別與用戶相關的文檔。 請注意,電子副本(將被稱為文檔)與文件不對應。 記錄可以存儲在包含其他文檔的文件的一部分中,也可以存儲在專用於相關文檔的單個文件中,或者存儲在許多協調的文件中。 此外,副本可以存儲在內存中,而無需存儲在文件中。
搜索引擎可以包括對與輸入查詢相關的文檔進行排名的排名引擎。 可以使用傳統技術執行文檔的排名,以確定給定查詢的索引記錄的信息檢索 (IR) 分數。
任何適當的方法都可以確定特定文檔在特定搜索項中的相關性或與其他提供的信息的相關性。 例如,包含與搜索詞匹配的文檔的反向鏈接的一般級別可以用來推斷文檔的相關性。
特別是,如果一個文檔被許多其他相關文檔(例如包含與搜索詞匹配的文檔)鏈接到(例如,是超鏈接的目標),則可以推斷出目標文檔特別相關。 之所以可以做出這種推論,是因為指向論文的作者大概會在大多數情況下指向與他們的受眾相關的其他文檔。
指向文檔的目標是來自其他相關文檔的鏈接,這可以被認為是更相關的。 第一個文件特別合適,因為它針對適用(甚至高度相關)的文件。
這種技術可以確定文檔的相關性或許多決定因素之一。 還可以採取適當的方法來識別和減少進行欺詐性投票以提高頁面相關性的嘗試。
為了進一步改進這種傳統的文檔排名技術,排名引擎可以從排名修改引擎接收更多信號,以幫助確定文檔的適當排名。
結合上述圖像註釋器和查詢分類,排名修改器引擎為論文提供相關性度量。 排名引擎可以用來提高提供給用戶的搜索結果的排名。
排名修改器引擎可以執行操作以生成相關性度量。
圖像結果的分數是增加還是減少取決於圖像的視覺內容(如圖像註釋中表示的)是否與查詢分類匹配,每個圖像類別都會被考慮。
例如,如果查詢的分類是“單人”,那麼被分類為“截圖”和“單人臉”的圖像結果首先會因為“截圖”類別而降低其分數。 然後,由於“單面”類別,它可以提高分數。
搜索引擎可以通過網絡轉發服務器端搜索結果中的最終排序結果列表。 退出網絡後,客戶端設備可以接收客戶端搜索結果,結果可以存儲在 RAM 中並由處理器用於在輸出設備上為用戶顯示結果。
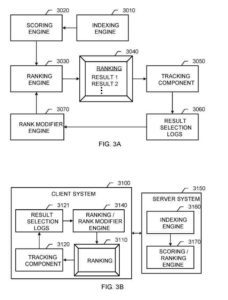
信息檢索系統
這些組件包括:
- 索引引擎
- 評分引擎
- 排名引擎
- 排名修改引擎
索引引擎的功能如上文針對索引引擎所述。 評分引擎根據許多特徵為文檔結果生成分數,包括將查詢鏈接到文檔結果的基於內容的特徵,以及通常說明文檔結果質量的與查詢無關的部分。
圖像的基於內容的特徵包括包含圖片的文檔的各個方面,例如與文檔標題或圖像標題的查詢匹配。
與查詢無關的特徵包括,例如,論文的文檔交叉引用或域或圖像維度的方面。
此外,評分引擎使用的特定功能可以使用自動或半自動過程進行調整,以調整對最終 IR 評分的各種特徵貢獻。
排名引擎根據從評分機接收的 IR 分數和來自排名修改器引擎的信號對文檔結果進行排名以顯示給用戶。
排名修改引擎為文檔提供相關性度量,排名引擎可以使用這些度量來提高提供給用戶的搜索結果的排名。 跟踪組件記錄用戶行為信息,例如單個用戶對按順序呈現的結果的選擇。
跟踪組件獲取包含在網頁排名中的嵌入 JavaScript 代碼,該代碼識別用戶對單個文檔結果的選擇並識別用戶何時返回結果頁面,從而指示用戶查看所選文檔結果所花費的時間。
跟踪組件是一個代理系統,用戶對文檔結果的選擇通過該代理系統進行路由。 跟踪組件還可以包括客戶端的預安裝軟件(例如客戶端操作系統的工具欄插件)。
其他實現也是可能的,例如,使用允許標籤/指令被包含在頁面中的網絡瀏覽器的特性的實現,其請求瀏覽器連接回服務器並帶有關於用戶點擊的鏈接的消息。
記錄的信息存儲在結果選擇日誌中。 記錄的信息包括日誌條目,這些條目說明用戶與針對提交的每個查詢呈現的每個結果文檔的交互。
對於為查詢呈現的結果文檔的每個用戶選擇,日誌條目說明查詢 (Q)、論文 (D)、用戶在文檔上的停留時間 (T)、用戶使用的語言 (L)、和用戶可能位於的國家(C)(例如,基於用於訪問IR系統的服務器)和識別用戶的大都市區的地區代碼(R)。
日誌條目還記錄負面信息,例如文檔結果被呈現給用戶但未被選中。
其他信息,例如:
- 點擊位置(即用戶界面中的用戶選擇)
- 有關會話的信息(例如先前點擊的存在和類型(點擊後會話活動))
- 點擊結果的 R 分數
- 點擊前顯示的所有結果的 IR 分數
- 在點擊之前向用戶顯示標題和片段
- 用戶的 cookie
- 餅乾時代
- IP(互聯網協議)地址
- 瀏覽器的用戶代理
- 很快
初始點擊文檔結果與用戶返回主頁並點擊另一個文檔結果(或提交新的搜索查詢)之間的時間 (T) 也會被記錄下來。
對時間 (T) 進行評估,以確定該時間是否表示文檔的較長視圖或較短的視圖,因為更多擴展參數通常顯示點擊結果的質量或相關性。 該時間評估 (T) 可以結合各種加權技術進行。
所示組件可以以各種方式和多種系統配置進行組合。 評分結束坦克引擎合併成一個單一的排名引擎,例如排名引擎。 排名修改引擎和排名引擎也可以合併。 通常,排名引擎包括在查詢後生成文檔結果排名的任何軟件組件。 此外,排名引擎也可以(或不適合)服務器系統中的客戶端系統。
另一個例子是信息檢索系統。 服務器系統包括索引引擎和評分/排名引擎。
在該系統中,客戶端系統包括:
- 用於呈現排名的用戶界面
- 跟踪組件
- 結果選擇日誌
- 排名/排名修改引擎。
例如,客戶端系統可以包括公司的企業網絡和個人計算機,其中瀏覽器插件結合了排名/排名修改器引擎。
當公司員工在服務器系統上發起搜索時,評分/排名引擎可以返回搜索結果。 結果的初始排名或實際 IR 分數。 然後,瀏覽器插件根據公司特定用戶群的跟踪頁面選擇重新排列結果。
一種查詢分類技術
該技術可以在線(作為查詢處理的一部分)或離線方式執行。
接收到響應於第一個查詢的第一個圖像結果。 第一張圖像中的每一個都與訂單(例如 IR 分數)和相應的用戶行為數據(例如點擊數據)相關聯。
選擇多個第一圖像,其中每個選定圖像的相應行為數據的度量滿足閾值。
基於所選第一圖像的內容分析,所選第一圖像與若干註釋相關聯。 圖像註釋可以保留在圖像註釋中。
然後根據註釋將類別與第一個查詢相關聯。
查詢分類關聯可以在查詢類別中持續存在。
然後接收響應於相同的第二查詢或第一查詢的第二圖像結果。
(如果在查詢分類中未找到第二個查詢,則可以對第二個查詢進行轉換或“重寫”以確定替代形式是否與查詢分類中的查詢匹配。)
在此示例中,第二個查詢與第一個查詢相同或可以重寫為第一個查詢。
第二個圖像結果在與第一個查詢相關聯之前根據查詢分類重新排序。
直接在您的收件箱中搜索新聞
*必需的