
Категоризация запросов на основе результатов изображения
Опубликовано: 2022-04-27Google недавно получил патент на категоризацию запросов на основе результатов изображений.
Патент сообщает нам, что: «интернет-поисковые системы предоставляют информацию о доступных в Интернете ресурсах (таких как веб-страницы, изображения, текстовые документы, мультимедийный контент) в ответ на поисковый запрос пользователя, возвращая при поиске изображения набор результатов поиска изображения. в ответ на запрос».
Результат поиска включает, например, унифицированный указатель ресурсов (URL) изображения или документа, содержащего изображение и фрагмент информации.
Ранжирование поисковой выдачи с использованием функции подсчета очков
Результаты поиска можно ранжировать (например, по порядку) в соответствии с оценками, присвоенными функцией оценки.
Функция подсчета очков ранжирует результаты поиска по различным сигналам:
- Где (и как часто) текст запроса появляется в тексте документа, окружающем изображение
- Подпись к изображению или альтернативный текст для идеи
- Насколько стандартны условия запроса в результатах поиска, индексируемых поисковой системой.
В общем, предметом, описанным в этом патенте, является способ, который включает:
- Получение изображений из результатов первого изображения для первого запроса, где количество полученных изображений связано с оценками и данными о поведении пользователя, которые определяют взаимодействие пользователя с полученными изображениями, когда полученные изображения являются результатами поиска для запроса.
- Выбор количества полученных изображений, каждое из которых имеет соответствующие данные о поведении, которые удовлетворяют пороговому значению
- Связывание выбранных первых изображений с несколькими аннотациями на основе анализа содержимого выбранных изображений
Они могут дополнительно включать следующие функции.
Первый запрос может быть связан с категориями на основе аннотаций. Категоризация запросов и ассоциации аннотаций могут быть сохранены для использования в будущем. Результаты второго изображения реагируют на второй запрос, который является таким же или подобным первому запросу.
Каждое из вторых изображений связано с оценкой, а второе изображение может быть изменено на основе категорий, связанных с первым запросом.
Одна из категорий запросов может указывать, что первый запрос является запросом для одного человека и увеличивает баллы второго изображения, аннотации которого говорят, что набор вторых изображений содержит одно лицо.
Одна категоризация запроса может указать, что первый запрос разнообразен, и увеличить оценки вторых изображений, аннотации которых говорят, что набор вторых изображений разнообразен.
Одна из категорий может указать, что первый запрос является текстовым запросом, и повысить баллы второго изображения, чьи аннотации говорят, что набор вторых изображений содержит текст.
Первый запрос может быть предоставлен обученному классификатору для определения категоризации запроса по категориям.
Анализ содержимого выбранного первого изображения может включать кластеризацию результатов первого изображения для определения аннотации в аннотациях. Данные о поведении пользователей могут представлять собой количество раз, когда пользователи выбирают изображение в результатах поиска по первому запросу.
Предмет, описанный в этом патенте, может быть реализован таким образом, чтобы реализовать следующие преимущества:
Набор результатов изображения анализируется для получения аннотаций изображения и категоризации запроса, а взаимодействие пользователя с результатами поиска изображения может использоваться для получения типов запросов.
Категоризация запросов
Категории запросов, в свою очередь, могут повысить релевантность, качество и разнообразие результатов поиска изображений.
Категоризация запросов также может использоваться как часть обработки запросов или в автономном процессе.
Категории запросов можно использовать для предоставления автоматических предложений запросов, таких как «показывать только изображения с лицами» или «показывать только картинки».
Категоризация запросов на основе результатов изображений
Изобретатели: Анна Майковска и Кристиан Тапус
Правопреемник: GOOGLE LLC
Патент США: 11 308 149
Выдано: 19 апреля 2022 г.
Подано: 3 ноября 2017 г.
Абстрактный
Способы, системы и устройства, включая компьютерные программы, закодированные на компьютерном носителе данных, для категоризации запросов на основе результатов изображения.
В одном аспекте способ включает в себя получение изображений из результатов изображения в ответ на запрос, при этом каждая из фотографий связывается с порядком в результатах изображения и соответствующими данными о поведении пользователя для изображения в качестве результата поиска для первого запроса и ассоциирования первые изображения с множеством аннотаций на основе анализа содержимого выбранного первого изображения.
Система, использующая категоризацию запросов для улучшения набора результатов, возвращаемых запросом
Клиент, такой как веб-браузер или другой процесс, выполняемый на вычислительном устройстве, отправляет входной запрос поисковой системе, и поисковая система возвращает клиенту результаты поиска изображения. В некоторых реализациях запрос содержит текст, такой как символы из набора символов (например, «красный помидор»).
Запрос включает изображения, звуки, видео или их комбинации. Возможны другие типы запросов. Поисковая система будет искать результаты на основе альтернативных версий запроса, равных, более широких или более конкретных, чем входной запрос.
Результаты поиска изображений представляют собой упорядоченный или ранжированный список документов или ссылок на них, которые определены как отвечающие на входной запрос, причем документы, определенные как наиболее релевантные, имеют наивысший ранг. Копия — это веб-страница, изображение или другой электронный файл.
В случае поиска изображений поисковая система определяет релевантность изображения, по крайней мере частично, на основе следующего:
- Содержание изображения
- Текст вокруг изображения
- Подпись к изображению
- Альтернативный текст для изображения
Категории, связанные с запросом
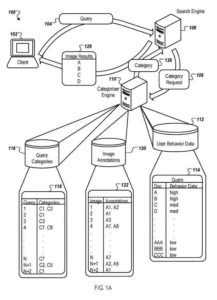
При создании результатов поиска изображений поисковая машина в некоторых реализациях отправляет запрос на категории, связанные с запросом. Поисковая система может использовать связанные категории для изменения порядка результатов поиска изображений путем повышения ранга результатов изображений, определенных как принадлежащие связанным категориям.
В некоторых случаях это может уменьшить результаты изображений, которые не относятся к связанным категориям или к обеим категориям.
Поисковая система также может использовать категории результатов, чтобы определить, как они должны ранжироваться в окончательном наборе результатов в сочетании с категорией запроса или .
Механизм классификатора или другой процесс использует результаты изображений, полученные для запроса, и репозиторий данных о поведении пользователя для получения категорий для запроса. Репозиторий содержит данные о поведении пользователей. Хранилище показывает, сколько раз группы пользователей выбирали результат изображения для данного запроса.
Выбор изображения может осуществляться различными способами, в том числе с помощью клавиатуры, компьютерной мыши или жеста пальца, голосовой команды или другими способами. Данные о поведении пользователей включают «данные о кликах».
Данные о кликах показывают, как долго пользователь просматривает или «останавливается» на результате изображения.
Данные о кликах показывают, как долго пользователь просматривает или «останавливается» на результате изображения после выбора его в списке результатов для запроса. Например, длительное нахождение изображения (например, более 1 минуты), называемое «долгим кликом», может указывать на то, что пользователь нашел изображение, имеющее отношение к запросу пользователя.
Короткий период просмотра изображения (например, менее 30 секунд), называемый «коротким кликом», может быть истолкован как отсутствие релевантности изображения. Возможны и другие типы данных о поведении пользователя.
Например, данные о поведении пользователя могут быть сгенерированы процессом, создающим запись для результирующих документов, выбранных пользователями в ответ на конкретный запрос. Каждая форма может быть представлена в виде кортежа: <document, query, data>), который включает:
- Вопрос, заданный пользователями
- Ссылка на запрос, указывающая запрос
- Ссылка на документ, выбранный пользователями в ответ на запрос.
- Агрегация данных о кликах (например, количество кликов каждого типа) для всех пользователей или подмножества всех пользователей, выбравших ссылку на документ в ответ на запрос.
Возможны расширения этого подхода на основе кортежей к данным о поведении пользователей. Например, данные о поведении пользователя могут быть расширены за счет включения идентификаторов, зависящих от местоположения (например, страны или штата), или идентификаторов, зависящих от языка.
С включенными такими идентификаторами кортеж для конкретной страны будет состоять из страны, из которой исходит пользовательский запрос, а кортеж для конкретного языка будет состоять из языка пользовательского запроса.
Для простоты представления данные о поведении пользователя, связанные с документами A-CCC для запроса, отображаются в таблице как «высокий», «средний» или «низкий» объем данных о благоприятном поведении пользователя (например, о поведении пользователя). данные, указывающие на соответствие между документом и запросом).
Данные о поведении пользователя для документа
Данные о благоприятном поведении пользователей для документа могут указывать, что документ выбирается пользователями, когда он просматривается в результатах запроса, или когда пользователи просматривают документ после выбора его из результатов запроса, пользователи просматривают документ в течение длительный период (например, пользователь считает, что документ имеет отношение к вопросу).
Механизм классификатора работает совместно с поисковой системой, используя возвращенные результаты и данные о поведении пользователя, чтобы определить категории запросов, а затем повторно ранжировать результаты, прежде чем они будут возвращены пользователю.
Как правило, для запроса (такого как запрос или альтернативная форма запроса), указанного в запросе категории запроса, механизм классификатора анализирует результаты изображения для запроса, чтобы определить, принадлежит ли запрос к категориям. Результаты анализа изображений в некоторых реализациях были выбраны пользователями в качестве результата поиска для запроса в общее количество раз выше порогового значения (например, установленного не менее десяти раз).
Механизм классификатора анализирует все результаты изображений, полученные поисковой системой по заданному запросу. в других реализациях
Механизм классификатора анализирует результаты изображения для запроса, в котором метрика (например, общее количество выборов или другая мера) для данных кликов превышает пороговое значение.
Результаты изображения могут быть проанализированы в режиме онлайн с использованием методов компьютерного зрения различными способами, как в автономном режиме, так и в режиме онлайн, в процессе подсчета очков. Изображения аннотируются информацией, извлеченной из их визуального содержимого.
Аннотации изображений
Например, аннотации к изображениям могут храниться в хранилище аннотаций. Каждое проанализированное изображение (например, изображение 1, изображение 2 и т. д.) связывается с аннотациями (например, A1, A2 и т. д.) в связи фотографии с аннотацией.
Аннотации могут включать:
- Количество лиц на изображении
- Размер каждого лица
- Доминирующие цвета изображения
- Содержит ли изображение текст или график
- Является ли изображение скриншотом
Кроме того, каждое изображение может быть аннотировано отпечатком пальца, который затем может определить, являются ли два изображения идентичными или идентичными.
Затем механизм классификатора анализирует результаты изображений по заданному запросу и их аннотации, чтобы определить категории запроса. Связи категорий запросов (например, C1, C2 и т. д.) для заданного запроса (например, запроса 1, запроса 2 и т. д.) можно определить разными способами, например, с помощью простой эвристики или с помощью автоматического классификатора.
Простой классификатор запросов на основе эвристики
Например, простой классификатор запросов, основанный на эвристике, может использоваться для определения желаемого доминирующего цвета для запроса (и есть ли он).
Например, эвристика может заключаться в том, что если из 20 наиболее часто нажимаемых изображений по запросу не менее 70% имеют доминирующий красный цвет, то запрос может быть отнесен к категории «красный запрос». Для таких запросов поисковая система может изменить порядок полученных результатов, чтобы повысить рейтинг всех изображений, аннотированных красным цветом как доминирующим.
Та же самая категоризация может использоваться со всеми другими стандартными цветами. Преимущество такого подхода к чрезмерному анализу текста запроса заключается в том, что он работает для всех языков без необходимости перевода (например, он будет продвигать изображения с доминирующим красным цветом для вопроса «красное яблоко» на любом языке). Он более надежен (например, не повышает рейтинг красных изображений по запросу «красное море»).
Пример механизма классификации
Механизм классификатора может работать в интерактивном режиме или в автономном режиме, в котором ассоциации категорий запроса сохраняются заранее (например, в таблице) для использования поисковой машиной во время обработки запроса.
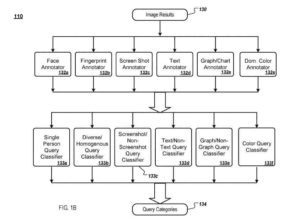
Механизм получает результаты запроса изображения для данного запроса и предоставляет результаты изображения аннотаторам изображений. Каждый аннотатор изображения анализирует результаты изображения и извлекает информацию о визуальном содержании изображения, которая сохраняется как аннотация изображения (например, аннотации изображения) для идеи.
Аннотатор изображения лица
В качестве иллюстрации аннотатор изображения лица:
- Определяет количество лиц на изображении и размер каждого лица.
- аннотатор изображения отпечатка пальца извлекает визуальные признаки изображения в сжатой форме (отпечаток пальца), которые затем можно сравнить с отпечатком пальца другого изображения, чтобы определить, похожи ли два изображения.
- Аннотатор изображения снимка экрана определяет, является ли изображение снимком экрана.
- Аннотатор текстового изображения определяет, содержит ли изображение текст
- Запрос изображения графика/диаграммы определяет, содержит ли изображение графики или диаграммы (например, гистограммы).
- Аннотатор доминирующего цвета определяет, содержит ли изображение доминирующий цвет.
Также можно использовать другие аннотаторы изображений. Например, несколько аннотаторов изображений описаны в статье под названием «Быстрое обнаружение объектов с использованием усиленного каскада простых функций» Виолы П.; Джонс, М., Mitsubishi Electric Research Laboratories, TR2004-043 (май 2004 г.).
Затем механизм классификатора анализирует результаты изображений для данного запроса и их аннотации, чтобы определить категории запроса (например, категории запроса). Категории запросов определяются с помощью классификатора, а классификатор запросов может быть реализован с помощью системы машинного обучения.
Использование адаптивного повышения
В качестве иллюстрации, AdaBoost, сокращение от Adaptive Boosting, представляет собой систему машинного обучения, которую можно использовать с другими алгоритмами обучения для повышения их производительности. AdaBoost используется для создания категоризации запросов. (Возможно больше алгоритмов обучения)
AdaBoost вызывает «слабый» аннотатор изображений в серии раундов. В качестве иллюстрации классификатор запроса одного человека может быть основан на алгоритме обучающей машины, обученном определять, требует ли запрос изображений одного человека.
В качестве иллюстрации такой классификатор запросов может обучаться с помощью наборов данных, содержащих запрос, набор векторов признаков, представляющих результирующие изображения для вопроса с нулем или более лицами, и правильную категоризацию для запроса (т. е. лица или нет). . Для каждого вызова классификатор запросов обновляет распределение весов, указывающее важность примеров в обучающем наборе данных для классификации.
В каждом раунде веса каждого классифицированного обучающего примера увеличиваются (или последствия каждого классифицированного обучающего примера уменьшаются), поэтому новая категоризация запросов больше фокусируется на этих примерах. Результирующая обученная категоризация запроса может принимать в качестве входных данных запрос и выводить вероятность того, что запрос требует изображений, содержащих отдельных людей.
Классификатор разнообразных/однородных запросов принимает в качестве входных данных запрос и выводит вероятность того, что запрос относится к различным изображениям. Классификатор использует алгоритм кластеризации для кластеризации результатов изображений в соответствии с их отпечатками пальцев на основе меры расстояния друг от друга. Каждое изображение связывается с идентификатором кластера.
Идентификатор кластера изображения используется для определения количества кластеров, размера групп и сходства между кластерами, образованными изображениями в результирующем наборе. Например, эта информация используется для сопоставления вероятности того, что запрос является конкретным (или приглашает дубликаты) или нет.
Связывание запросов с каноническими значениями и представлениями
Категоризация запросов также может использоваться для связывания запросов с каноническими значениями и представлениями. Например, если есть один большой кластер или несколько больших кластеров, высока вероятность того, что вопрос будет связан с повторяющимися результатами изображения. Если есть много более мелких кластеров, то вероятность того, что запрос будет связан с одними и теми же результатами изображения, низка.

Дубликаты изображений обычно не очень полезны, поскольку они не предоставляют больше информации, поэтому они должны быть понижены в качестве результатов запроса. Но есть исключения. Например, если в первоначальных результатах много дубликатов (несколько, большие кластеры), запрос является частным, и дубликаты не должны понижаться.
Категоризация запросов со снимками экрана и без снимков экрана принимает в качестве входных данных запрос и выводит вероятность того, что запрос требует изображений, являющихся снимками экрана. Классификатор текстовых/нетекстовых запросов принимает в качестве входных данных запрос и выводит вероятность того, что запрос вызывает изображения, содержащие текст.
Категоризация графического/не графического запроса принимает входные данные запроса и выводит вероятность того, что запрос требует изображений, содержащих график или диаграмму. Классификатор 133f запроса цвета принимает информационный запрос и выводит вероятность того, что запрос вызывает снимки, в которых доминирует один цвет. Возможны другие классификаторы запросов.
Повышение релевантности результатов изображения на основе категоризации запроса
Поисковик может взаимодействовать с системой через клиент или другое устройство. Например, клиентское устройство может быть компьютерным терминалом в локальной сети (LAN) или обширной сети (WAN). Клиентское устройство может быть мобильным устройством (например, мобильным телефоном, мобильным компьютером, персональным настольным помощником и т. д.), способным обмениваться данными через локальную сеть, глобальную сеть или некоторую другую сеть (например, сеть сотовой связи).
Клиентское устройство может включать в себя оперативную память (RAM) (или другую память и запоминающее устройство) и процессор.
Процессор структурирован для обработки инструкций и данных в системе. Процессор представляет собой однопоточный или многопоточный микропроцессор, имеющий вычислительные ядра. Процессор получает структурированные для выполнения инструкции, хранящиеся в ОЗУ (или другой памяти и запоминающем устройстве, включенном в состав клиентского устройства), для воспроизведения графической информации для пользовательского интерфейса.
Поисковик может подключиться к поисковой системе в серверной системе, чтобы отправить входной запрос. Поисковая система представляет собой поисковую систему изображений или универсальную поисковую систему, которая может извлекать изображения и другие типы контента, такие как документы (например, HTML-страницы).
Когда пользователь отправляет входной запрос через устройство ввода, подключенное к клиентскому устройству, вопрос на стороне клиента отправляется в сеть и перенаправляется в серверную систему как запрос на стороне сервера. Серверная система может быть серверными устройствами в местах. Серверное устройство включает в себя запоминающее устройство, состоящее из загруженной в него поисковой системы.
Процессор структурируется для обработки инструкций внутри устройства. Эти инструкции могут установить компоненты поисковой системы. Процессор может быть однопоточным или многопоточным и включать множество вычислительных ядер. Процессор может обрабатывать хранящиеся в памяти инструкции, относящиеся к поисковой системе, и отправлять информацию клиентскому устройству по сети для создания графического представления в пользовательском интерфейсе клиентского устройства (например, результаты поиска на веб-странице, отображаемые в веб-интерфейсе). браузер).
Запрос на стороне сервера получает поисковая система. Поисковая система использует информацию во входном запросе (например, термины запроса) для поиска соответствующих документов. Механизм поиска может включать в себя механизм индексации, который выполняет поиск в корпусе (например, веб-страницах в Интернете) для индексации документов, найденных в этом корпусе. Индексная информация для корпусных документов может храниться в индексной базе данных.
Доступ к этой индексной базе данных можно получить для идентификации документов, связанных с пользователем. Обратите внимание, что электронная копия (которая будет называться документом) не соответствует файлу. Запись может храниться в части файла, содержащей другие документы, в одном файле, посвященном рассматриваемому документу, или во многих скоординированных файлах. Более того, копия может сохраняться в памяти, не сохраняясь в файле.
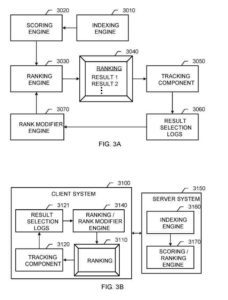
Механизм поиска может включать в себя механизм ранжирования для ранжирования документов, связанных с входным запросом. Ранжирование документов может выполняться с использованием традиционных методов для определения оценки информационного поиска (IR) для проиндексированных записей по заданному запросу.
Любой подходящий метод может определить релевантность конкретного документа конкретному поисковому запросу или другой предоставленной информации. Например, общий уровень обратных ссылок на документ, содержащий совпадения для поискового запроса, может использоваться для вывода о релевантности документа.
В частности, если документ связан (например, является целью гиперссылки) со многими другими релевантными документами (такими как документы, содержащие совпадения для условий поиска), можно сделать вывод, что целевой документ является особенно релевантным. Такой вывод можно сделать, потому что авторы рекомендательных статей предположительно указывают, по большей части, на другие документы, имеющие отношение к их аудитории.
Указывающие документы нацелены на ссылки из других соответствующих документов, которые можно считать более релевантными. Первый документ особенно подходит, поскольку он нацелен на применимые (или даже очень важные) документы.
Такой метод может определять релевантность документа или один из многих определяющих факторов. Также можно использовать соответствующие методы для выявления и пресечения попыток мошеннического голосования, чтобы повысить релевантность страницы.
Для дальнейшего улучшения таких традиционных методов ранжирования документов механизм ранжирования может принимать больше сигналов от механизма модификатора ранга, чтобы помочь в определении соответствующего ранжирования для документов.
В сочетании с аннотаторами изображений и категоризацией запросов, описанными выше, механизм модификатора ранга обеспечивает меры релевантности для статей. Механизм ранжирования может использовать для улучшения рейтинга результатов поиска, предоставляемых пользователю.
Механизм модификатора ранга может выполнять операции для создания мер релевантности.
Увеличивается или уменьшается оценка результата изображения, зависит от того, соответствует ли визуальное содержимое изображения (представленное в аннотациях к изображению) категоризации запроса, при этом учитывается каждая категория изображения.
Например, если категоризация запроса — «один человек», то результат изображения, который классифицируется и как «снимок экрана», и как «одно лицо», сначала будет иметь пониженную оценку из-за категории «снимок экрана». Затем он может увеличить свой балл из-за категории «одно лицо».
Поисковая система может пересылать окончательный ранжированный список результатов в результатах поиска на стороне сервера по сети. При выходе из сети клиентское устройство может получить результаты поиска на стороне клиента, где результаты могут быть сохранены в ОЗУ и использованы процессором для отображения результатов на устройстве вывода для пользователя.
Информационно-поисковая система
Эти компоненты включают в себя:
- Механизм индексации
- Система подсчета очков
- Система ранжирования
- Механизм модификатора ранга
Механизм индексирования работает, как описано выше для механизма индексирования. Механизм оценки генерирует оценки для результатов документа на основе многих функций, включая функции на основе содержимого, которые связывают запрос с результатами документа, и независимые от запроса части, которые обычно определяют качество результатов документов.
Функции на основе содержимого для изображений включают в себя аспекты документа, содержащего изображение, такие как соответствие запроса заголовку документа или подписи к изображению.
К функциям, не зависящим от запроса, относятся, например, аспекты перекрестных ссылок документа на бумагу или размеры домена или изображения.
Кроме того, определенные функции, используемые механизмом подсчета, могут быть настроены для корректировки вклада различных функций в окончательную оценку IR с использованием автоматических или полуавтоматических процессов.
Механизм ранжирования ранжирует результаты документа для отображения пользователю на основе оценок IR, полученных от оценочной машины, и сигналов от механизма модификатора ранга.
Механизм модификатора ранга обеспечивает меры релевантности для документов, которые механизм ранжирования может использовать для улучшения ранжирования результатов поиска, предоставляемых пользователю. Компонент отслеживания записывает информацию о поведении пользователя, например выбор отдельных пользователей из результатов, представленных в заказе.
Компонент отслеживания получает встроенный код JavaScript, включенный в ранжирование веб-страницы, которое идентифицирует выбор пользователем отдельных результатов документа и определяет, когда пользователь возвращается на страницу результатов, таким образом указывая количество времени, которое пользователь потратил на просмотр выбранного результата документа.
Компонент отслеживания представляет собой прокси-систему, через которую перенаправляются пользовательские выборки результатов документа. Компонент отслеживания также может включать предустановленное программное обеспечение для клиента (например, подключаемый модуль панели инструментов для операционной системы клиента).
Возможны и другие реализации, например, та, которая использует функцию веб-браузера, позволяющую включать тег/директиву на страницу, которая запрашивает у браузера обратное подключение к серверу с сообщениями о ссылках, нажатых пользователем.
Записанная информация сохраняется в журналах выбора результатов. Записанная информация включает записи журнала, в которых указывается взаимодействие пользователя с каждым результирующим документом, представленным для каждого отправленного запроса.
Для каждого выбора пользователем результирующего документа, представленного для запроса, в записях журнала указывается запрос (Q), бумага (D), время пребывания пользователя (T) в документе, язык (L), используемый пользователем, и страна (C), в которой, вероятно, находится пользователь (например, на основе сервера, используемого для доступа к IR-системе), и код региона (R), идентифицирующий городской район пользователя.
Записи журнала также записывают отрицательную информацию, например, результат документа был представлен пользователю, но не был выбран.
Другая информация, такая как:
- Позиции кликов (т. е. выбор пользователя в пользовательском интерфейсе).
- Информация о сеансе (например, наличие и тип предыдущих кликов (активность сеанса после клика))
- R баллы результатов кликов
- IR-баллы всех результатов, показанных до клика
- Заголовки и сниппеты отображаются пользователю до клика
- Куки пользователя
- Возраст файлов cookie
- IP-адрес (интернет-протокол)
- User-agent браузера
- Скоро
Также записывается время (T) между первоначальным переходом к результату документа и возвратом пользователей на главную страницу и нажатием на другой результат документа (или отправкой нового поискового запроса).
Выполняется оценка времени (T) того, указывает ли это время на более продолжительный просмотр документа или на более короткий, поскольку более расширенные аргументы обычно показывают качество или релевантность результата клика. Эта оценка времени (T) может быть выполнена в сочетании с различными методами взвешивания.
Показанные компоненты можно комбинировать различными способами и формировать несколько системных конфигураций. Механизмы подсчета очков объединяются в единый механизм ранжирования, такой как механизм ранжирования. Механизм модификатора ранга и механизм ранжирования также могут быть объединены. Как правило, механизм ранжирования включает в себя любой программный компонент, который генерирует ранжирование результатов документа после запроса. Кроме того, механизм ранжирования может также (или лучше) вписаться в клиентскую систему в серверной системе.
Другой пример — информационно-поисковая система. Серверная система включает в себя механизм индексации и механизм оценки/ранжирования.
В этой системе клиентская система включает в себя:
- Пользовательский интерфейс для представления рейтинга
- Компонент отслеживания
- Журналы выбора результатов
- Механизм модификатора ранга/ранга.
Например, клиентская система может включать в себя корпоративную сеть компании и персональные компьютеры, в которых подключаемый модуль браузера включает механизм ранжирования/модификатора ранга.
Когда сотрудник компании инициирует поиск в серверной системе, система оценки/ранжирования может вернуть результаты поиска. Первоначальный рейтинг или фактические баллы IR для результатов. Затем подключаемый модуль браузера повторно ранжирует результаты на основе отслеживаемых вариантов выбора страниц для пользовательской базы конкретной компании.
Техника категоризации запросов
Этот метод может выполняться в режиме онлайн (как часть обработки запроса) или в автономном режиме.
Получены первые результаты изображения, отвечающие на первый запрос. Каждое из первых изображений связывается с заказом (например, с оценкой IR) и соответствующими данными о поведении пользователя (например, с данными о кликах).
Выбирается некоторое количество первых изображений, где метрика для соответствующих данных о поведении для каждого выбранного изображения удовлетворяет пороговому значению.
Выбранные первые изображения связываются с несколькими аннотациями на основе анализа содержимого выбранных первых изображений. Аннотации изображения могут сохраняться в аннотациях изображения.
Затем категории связываются с первым запросом на основе аннотаций.
Связи категоризации запросов могут длиться в категориях запросов.
Затем получаются результаты второго изображения в ответ на второй запрос, который совпадает с первым запросом.
(Если второй запрос не найден в категоризации запроса, второй запрос может быть преобразован или «переписан», чтобы определить, соответствует ли альтернативная форма запросу в категоризации запроса.)
В этом примере второй запрос совпадает с первым запросом или может быть переписан.
Результаты второго изображения переупорядочиваются на основе категоризации запроса, прежде чем они будут связаны с первым запросом.
Поиск новостей прямо в папку «Входящие»
*Необходимый