
Catégorisation des requêtes basée sur les résultats d'image
Publié: 2022-04-27Google a récemment obtenu un brevet sur la catégorisation des requêtes basée sur les résultats d'image.
Le brevet nous dit que : "les moteurs de recherche Internet fournissent des informations sur les ressources accessibles sur Internet (telles que les pages Web, les images, les documents texte, le contenu multimédia) en réponse à la requête de recherche d'un utilisateur en renvoyant, lors de la recherche d'images, un ensemble de résultats de recherche d'images en réponse à la requête.
Un résultat de recherche inclut, par exemple, une URL (Uniform Resource Locator) d'une image ou d'un document contenant l'image et un extrait d'informations.
Classement des SERP à l'aide d'une fonction de notation
Les résultats de la recherche peuvent être classés (par exemple dans l'ordre) selon des notes attribuées par une fonction de notation.
La fonction de scoring classe les résultats de la recherche selon différents signaux :
- Où (et à quelle fréquence) le texte de la requête apparaît dans le texte du document entourant une image
- Une légende d'image ou un texte alternatif pour l'idée
- Niveau de standardisation des termes de la requête dans les résultats de recherche indexés par le moteur de recherche.
En général, le sujet décrit dans ce brevet est dans un procédé qui comprend :
- Obtention d'images à partir des premiers résultats d'image pour une première requête, un certain nombre des images acquises étant associées à des scores et à des données de comportement d'utilisateur indiquant l'interaction de l'utilisateur avec les images obtenues lorsque les images obtenues sont des résultats de recherche pour la requête
- Sélection d'un certain nombre d'images acquises ayant chacune des données de comportement respectives qui satisfont un seuil
- Associer les premières images choisies à plusieurs annotations basées sur l'analyse du contenu des images sélectionnées
Ceux-ci peuvent éventuellement inclure les fonctionnalités suivantes.
La première requête peut être associée à des catégories basées sur les annotations. La catégorisation des requêtes et les associations d'annotations peuvent être stockées pour une utilisation future. Les résultats de la seconde image en réponse à une seconde requête identique ou similaire à la première requête peuvent être reçus.
Chacune des secondes images est associée à un score, et la seconde image peut être modifiée en fonction des catégories liées à la première requête.
L'une des catégorisations de requête peut indiquer que la première requête est une requête à une seule personne et augmente les scores de la seconde image, dont les annotations indiquent que l'ensemble de secondes images contient un seul visage.
Une catégorisation de requête peut indiquer que la première requête est diversifiée et augmenter les scores des secondes images, dont les annotations indiquent que l'ensemble de secondes images est diversifié.
L'une des catégories peut indiquer que la première requête est une requête textuelle et augmenter les scores de la deuxième image, dont les annotations disent que l'ensemble des deuxièmes images contient le texte.
La première requête peut être fournie à un classificateur formé pour déterminer une catégorisation de requête dans les catégories.
L'analyse du contenu des premières images sélectionnées peut comprendre le regroupement des premiers résultats d'image pour déterminer une annotation dans les annotations. Les données sur le comportement des utilisateurs peuvent correspondre au nombre de fois où les utilisateurs sélectionnent l'image dans les résultats de recherche pour la première requête.
L'objet décrit dans ce brevet peut être mis en œuvre de manière à réaliser les avantages suivants :
L'ensemble de résultats d'image est analysé pour dériver des annotations d'image et une catégorisation de requête, et l'interaction de l'utilisateur avec les résultats de recherche d'image peut être utilisée pour dériver des types de requêtes.
Catégorisation des requêtes
Les catégories de requête peuvent, à leur tour, améliorer la pertinence, la qualité et la diversité des résultats de recherche d'images.
La catégorisation des requêtes peut également être utilisée dans le cadre du traitement des requêtes ou dans un processus hors ligne.
Les catégories de requête peuvent être utilisées pour fournir des suggestions de requête automatisées telles que "afficher uniquement les images avec des visages" ou "afficher uniquement les images clipart".
Catégorisation des requêtes basée sur les résultats d'image
Inventeurs : Anna Majkowska et Cristian Tapus
Cessionnaire : GOOGLE LLC
Brevet américain : 11 308 149
Attribué : 19 avril 2022
Date de dépôt : 3 novembre 2017
Abstrait
L'invention concerne des procédés, des systèmes et un appareil, comprenant des programmes informatiques codés sur un support de stockage informatique, pour une catégorisation d'interrogation basée sur des résultats d'image.
Dans un aspect, un procédé comprend la réception d'images à partir de résultats d'image en réponse à une requête, chacune des photos étant associée à un ordre dans les résultats d'image et des données de comportement d'utilisateur respectives pour l'image en tant que résultat de recherche pour la première requête et l'association de les premières images avec une pluralité d'annotations basées sur l'analyse du contenu des premières images sélectionnées.
Un système qui utilise la catégorisation des requêtes pour améliorer l'ensemble des résultats renvoyés pour une requête
Un client, tel qu'un navigateur Web ou un autre processus s'exécutant sur un dispositif informatique, soumet une requête d'entrée à un moteur de recherche, et le moteur de recherche renvoie des résultats de recherche d'images au client. Dans certaines mises en œuvre, une requête comprend du texte tel que des caractères dans un jeu de caractères (par exemple, "tomate rouge").
Une requête comprend des images, des sons, des vidéos ou des combinaisons de ceux-ci. D'autres types de requêtes sont possibles. Le moteur de recherche recherchera des résultats basés sur des versions de requête alternatives égales, plus larges ou plus spécifiques que la requête d'entrée.
Les résultats de la recherche d'images sont une liste ordonnée ou classée de documents ou de liens vers ceux-ci, qui sont déterminés comme répondant à la requête d'entrée, les documents déterminés comme étant les plus pertinents ayant le rang le plus élevé. Une copie est une page Web, une image ou un autre fichier électronique.
Dans le cas de la recherche d'images, le moteur de recherche détermine la pertinence d'une image en fonction, au moins en partie, des éléments suivants :
- Contenu de l'image
- Le texte entourant l'image
- Légende
- Texte alternatif pour l'image
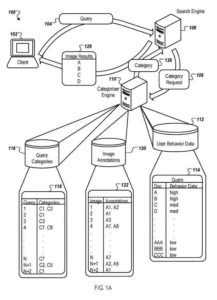
Catégories associées à une requête
Lors de la production des résultats de la recherche d'images, le moteur de recherche dans certaines mises en œuvre soumet une demande de catégories associées à la requête. Le moteur de recherche peut utiliser les catégories associées pour réorganiser les résultats de recherche d'images en augmentant le rang des résultats d'images déterminés comme appartenant aux catégories associées.
Dans certains cas, cela peut diminuer les résultats d'image qui n'appartiennent pas aux catégories associées ou aux deux.
Le moteur de recherche peut également utiliser les catégories des résultats pour déterminer comment ils doivent être classés dans l'ensemble finalisé de résultats en combinaison avec ou de la catégorie de requête.
Un moteur de catégorisation ou un autre processus utilise des résultats d'image récupérés pour la requête et un référentiel de données de comportement d'utilisateur pour dériver des catégories pour la requête. Le référentiel contient des données sur le comportement des utilisateurs. Le stockage indique le nombre de fois que des populations d'utilisateurs ont sélectionné un résultat d'image pour une requête donnée.
La sélection d'images peut être effectuée de différentes manières, notamment à l'aide du clavier, d'une souris d'ordinateur ou d'un geste du doigt, d'une commande vocale ou d'autres méthodes. Les données sur le comportement des utilisateurs incluent les "données sur les clics".
Les données de clic indiquent combien de temps un utilisateur visualise ou "s'attarde" sur un résultat d'image
Les données de clic indiquent combien de temps un utilisateur visualise ou « s'attarde » sur un résultat d'image après l'avoir sélectionné dans une liste de résultats pour la requête. Par exemple, un long temps passé sur une image (par exemple plus d'une minute), appelé "clic long", peut indiquer qu'un utilisateur a trouvé l'image pertinente pour la requête de l'utilisateur.
Une brève période de visualisation d'une image (par exemple, moins de 30 secondes), appelée « clic court », peut être interprétée comme un manque de pertinence de l'image. D'autres types de données sur le comportement des utilisateurs sont possibles.
À titre d'illustration, les données de comportement des utilisateurs peuvent être générées par un processus qui crée un enregistrement pour les documents de résultats sélectionnés par les utilisateurs en réponse à une requête spécifique. Chaque formulaire peut être représenté sous la forme d'un tuple : <document, query, data>) qui inclut :
- Une question soumise par les utilisateurs
- Une référence de requête indiquant la requête
- Un document référence un article sélectionné par les utilisateurs en réponse à la requête
- Agrégation des données de clic (telles que le nombre de chaque type de clic) pour tous les utilisateurs ou un sous-ensemble de tous les utilisateurs qui ont sélectionné la référence de document en réponse à la requête.
Des extensions de cette approche basée sur les tuples aux données sur le comportement des utilisateurs sont possibles. Par exemple, les données sur le comportement de l'utilisateur peuvent être étendues pour inclure des identifiants spécifiques à l'emplacement (tels que le pays ou l'état) ou spécifiques à la langue.
Avec de tels identifiants inclus, un tuple spécifique au pays serait constitué du pays d'où provient la requête de l'utilisateur, et un tuple spécifique à la langue serait constitué de la langue de la requête de l'utilisateur.
Pour simplifier la présentation, les données de comportement de l'utilisateur associées aux documents A-CCC pour la requête sont représentées dans le tableau comme étant une quantité "élevée", "moyenne" ou "faible" de données de comportement de l'utilisateur favorables (telles que le comportement de l'utilisateur données indiquant la pertinence entre le document et la requête).
Données de comportement de l'utilisateur pour un document
Les données de comportement utilisateur favorables pour un document peuvent indiquer que le papier est sélectionné par les utilisateurs lorsqu'il est affiché dans les résultats de la requête, ou lorsqu'un utilisateur affiche le document après l'avoir choisi dans les résultats de la requête, les utilisateurs affichent le document pour une période prolongée (telle que l'utilisateur trouve que le document est pertinent pour la question).
Le moteur de catégorisation fonctionne en conjonction avec le moteur de recherche en utilisant les résultats renvoyés et les données de comportement de l'utilisateur pour déterminer les catégories de requête, puis reclasser les résultats avant qu'ils ne soient renvoyés à l'utilisateur.
En général, pour la requête (telle qu'une requête ou une autre forme de requête) spécifiée dans la demande de catégorie de requête, le moteur de catégorisation analyse les résultats d'image pour la requête afin de déterminer si la requête appartient à des catégories. Les résultats d'image analysés dans certaines implémentations ont été sélectionnés par les utilisateurs comme résultat de recherche pour la requête un nombre total de fois au-dessus d'un seuil (par exemple, défini au moins dix fois).
Le moteur de catégorisation analyse tous les résultats d'image récupérés par le moteur de recherche pour une requête donnée. dans d'autres implémentations
Le moteur de catégorisation analyse les résultats d'image pour la requête lorsqu'une métrique (par exemple, le nombre total de sélections ou une autre mesure) pour les données de clic est supérieure à un seuil.
Les résultats d'image peuvent être analysés en ligne à l'aide de techniques de vision par ordinateur de différentes manières, hors ligne ou en ligne, pendant le processus de notation. Les images sont annotées avec des informations extraites de leur contenu visuel.
Annotations d'images
Par exemple, les annotations d'image peuvent être stockées dans le magasin d'annotations. Chaque image analysée (par exemple, image 1, image 2, etc.) est associée à des annotations (par exemple, A1, A2, etc.) dans une association photo à annotation.
Les annotations peuvent inclure :
- Le nombre de visages dans l'image
- La taille de chaque visage
- Les couleurs dominantes de l'image
- Si une image contient du texte ou un graphique
- Si une image est une capture d'écran
De plus, chaque image peut être annotée avec une empreinte digitale qui peut alors déterminer si deux images sont identiques ou identiques.
Ensuite, le moteur de catégorisation analyse les résultats d'image pour une requête donnée et leurs annotations pour déterminer les catégories de requête. Les associations de catégories de requêtes (par exemple, C1, C2, etc.) pour une requête donnée (telle que la requête 1, la requête 2, etc.) peuvent être déterminées de plusieurs façons, par exemple en utilisant une simple heuristique ou en utilisant un classificateur automatisé.
Un catégoriseur de requête simple basé sur une heuristique
Par exemple, un simple catégoriseur de requête basé sur une heuristique peut être utilisé pour déterminer la couleur dominante souhaitée pour la requête (et s'il y en a une).
L'heuristique peut être, par exemple, que si sur les 20 images les plus cliquées pour la requête, au moins 70 % ont une couleur dominante rouge, la requête peut être classée comme "requête rouge". Pour de telles requêtes, le moteur de recherche peut réorganiser les résultats récupérés pour augmenter le rang de toutes les images annotées avec le rouge comme couleur dominante.
La même catégorisation peut être utilisée avec toutes les autres couleurs standard. Un avantage de cette approche de sur-analyse du texte de la requête est qu'elle fonctionne pour toutes les langues sans avoir besoin de traduction (par exemple, elle favorisera les images avec une couleur rouge dominante pour la question "pomme rouge" dans n'importe quelle langue). Il est plus robuste (tel qu'il n'augmentera pas le rang des images rouges pour la requête "mer rouge").
Un exemple de moteur de catégorisation
Le moteur de catégorisation peut fonctionner en mode en ligne ou en mode hors ligne dans lequel les associations de catégories de requête sont stockées à l'avance (par exemple, dans la table) pour être utilisées par le moteur de recherche pendant le traitement de la requête.
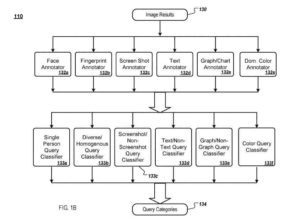
Le moteur reçoit des résultats d'image de requête pour une requête donnée et fournit les résultats d'image à des annotateurs d'image. Chaque annotateur d'image analyse les résultats d'image et extrait des informations sur le contenu visuel de l'image, qui sont stockées sous la forme d'une annotation d'image (par exemple, des annotations d'image) pour l'idée.
Un annotateur d'image de visage
A titre d'illustration, un annotateur d'image de visage :
- Détermine le nombre de visages dans une image et la taille de chaque visage
- un annotateur d'image d'empreintes digitales extrait les caractéristiques visuelles de l'image sous une forme condensée (empreinte digitale) qui peut ensuite être comparée à l'empreinte digitale d'une autre image pour déterminer si les deux images sont similaires
- Un annotateur d'image de capture d'écran détermine si une image est une capture d'écran
- Un annotateur d'image de texte détermine si une image contient du texte
- Une requête d'image graphique/graphique détermine si une image comprend des graphiques ou des graphiques (par exemple, des graphiques à barres)
- Un annotateur de couleur dominante détermine si une image contient une couleur dominante
D'autres annotateurs d'images peuvent également être utilisés. Par exemple, plusieurs annotateurs d'images sont décrits dans un article intitulé "Rapid Object Detection Using a Boosted Cascade of Simple Features", par Viola, P. ; Jones, M., Laboratoires de recherche Mitsubishi Electric, TR2004-043 (mai 2004).
Ensuite, le moteur de catégorisation analyse les résultats d'image pour une requête donnée et leurs annotations pour déterminer des catégories de requête (par exemple, des catégories de requête). Les catégories de requête sont déterminées à l'aide d'un classificateur, et un classificateur de requête peut être réalisé à l'aide d'un système d'apprentissage automatique.
Utilisation du boosting adaptatif
A titre d'illustration, AdaBoost, abréviation de Adaptive Boosting, est un système d'apprentissage automatique qui peut être utilisé avec d'autres algorithmes d'apprentissage pour améliorer leurs performances. AdaBoost s'habitue à générer une catégorisation de requête. (Plus d'algorithmes d'apprentissage sont possibles)
AdaBoost invoque un annotateur d'image "faible" dans une série de tours. À titre d'illustration, le classificateur de requête d'une seule personne peut se baser sur un algorithme de machine d'apprentissage formé pour déterminer si une requête appelle des images d'une seule personne.
À titre d'illustration, un tel classificateur de requête peut être formé avec des ensembles de données comprenant une requête, un ensemble de vecteurs de caractéristiques représentant des images de résultat pour la question avec zéro ou plusieurs visages, et la catégorisation correcte pour la requête (c'est-à-dire, visages ou non) . Pour chaque appel, le classificateur de requête met à jour une distribution de pondérations qui indique l'importance des exemples dans l'ensemble de données d'apprentissage pour la classification.
À chaque tour, les poids de chaque exemple de formation classifié augmentent (ou les conséquences de chaque exemple de formation classifié diminuent), de sorte que la nouvelle catégorisation des requêtes se concentre davantage sur ces exemples. La catégorisation de requête entraînée résultante peut prendre en entrée une requête et produire une probabilité que la requête appelle des images contenant des personnes seules.
Un classificateur de requêtes diverses/homogènes prend en entrée une requête et génère une probabilité que la requête concerne diverses images. Le classificateur utilise un algorithme de regroupement pour regrouper les résultats d'image en fonction de leurs empreintes digitales en fonction d'une mesure de distance les uns des autres. Chaque image est associée à un identifiant de cluster.
L'identifiant de cluster d'image est utilisé pour déterminer le nombre de clusters, la taille des groupes et la similarité entre les clusters formés par les images dans le jeu de résultats. Par exemple, cette information sert à associer une probabilité que la requête soit spécifique (ou invitant les doublons) ou non,

Associer des requêtes à des significations et des représentations canoniques
La catégorisation des requêtes peut également être utilisée pour associer des requêtes à des significations et des représentations canoniques. Par exemple, s'il existe un seul grand cluster ou plusieurs grands clusters, la probabilité que la question soit liée à des résultats d'image en double est élevée. S'il existe de nombreux clusters plus petits, la probabilité que la requête soit associée aux mêmes résultats d'image est faible.
Les doublons d'images ne sont généralement pas très utiles car ils ne fournissent plus d'informations, ils doivent donc être rétrogradés en tant que résultats de requête. Mais, il y a des exceptions. Par exemple, s'il existe de nombreux doublons dans les résultats initiaux (quelques gros clusters), la requête est particulière et les doublons ne doivent pas être rétrogradés.
Une catégorisation de requête capture d'écran/non-capture d'écran prend comme entrée une requête et génère une probabilité que la requête appelle des images qui sont des captures d'écran. Un classificateur de requête texte/non-texte accepte en entrée une requête et génère une chance que la requête appelle des images contenant du texte.
Une catégorisation de requête graphique/non graphique prend une entrée d'une requête et génère une probabilité que la requête appelle des images qui contiennent un graphique ou un diagramme. Un classificateur de requête de couleur 133f prend une requête d'informations et délivre une chance que la requête appelle des plans qui sont dominés par une seule couleur. D'autres classificateurs de requêtes sont possibles.
Améliorer la pertinence des résultats d'image en fonction de la catégorisation des requêtes
Un chercheur peut interagir avec le système par l'intermédiaire d'un client ou d'un autre dispositif. Par exemple, le dispositif client peut être un terminal informatique au sein d'un réseau local (LAN) ou d'un réseau étendu (WAN). Le dispositif client peut être un dispositif mobile (par exemple, un téléphone portable, un ordinateur portable, un assistant de bureau personnel, etc.) capable de communiquer sur un LAN, un WAN ou un autre réseau (par exemple, un réseau de téléphonie cellulaire).
Le dispositif client peut comprendre une mémoire vive (RAM) (ou une autre mémoire et un dispositif de stockage) et un processeur.
Le processeur est structuré pour traiter les instructions et les données au sein du système. Le processeur est un microprocesseur monothread ou multithread ayant des cœurs de traitement. Le processeur reçoit des instructions structurées pour exécuter stockées dans la RAM (ou une autre mémoire et un dispositif de stockage compris avec le dispositif client) pour restituer des informations graphiques pour une interface utilisateur.
Un chercheur peut se connecter au moteur de recherche dans un système de serveur pour soumettre une requête d'entrée. Le moteur de recherche est un moteur de recherche d'images ou un moteur de recherche générique qui peut récupérer des images et d'autres types de contenus tels que des documents (par exemple, des pages HTML).
Lorsque l'utilisateur soumet la requête d'entrée via un dispositif d'entrée relié à un dispositif client, une question côté client est envoyée dans un réseau et transmise au système serveur en tant que requête côté serveur. Le système de serveur peut être constitué de dispositifs de serveur dans des emplacements. Un dispositif serveur comprend un dispositif de mémoire constitué du moteur de recherche qui y est chargé.
Un processeur est structuré pour traiter les instructions au sein de l'appareil. Ces instructions peuvent installer des composants du moteur de recherche. Le processeur peut être monothread ou multithread et inclure de nombreux cœurs de traitement. Le processeur peut traiter des instructions stockées dans la mémoire relatives au moteur de recherche et envoyer des informations au dispositif client via le réseau pour créer une présentation graphique dans l'interface utilisateur du dispositif client (par exemple, des résultats de recherche sur une page Web affichée dans un navigateur).
La requête côté serveur est reçue par le moteur de recherche. Le moteur de recherche utilise les informations contenues dans la requête d'entrée (telles que les termes de la requête) pour trouver les documents pertinents. Le moteur de recherche peut comprendre un moteur d'indexation qui recherche un corpus (par exemple, des pages Web sur Internet) pour indexer les documents trouvés dans ce corpus. Les informations d'index pour les documents de corpus peuvent être stockées dans une base de données d'index.
Cette base de données d'index peut être consultée pour identifier les documents liés à l'utilisateur. Notez qu'une copie électronique (que l'on appellera un document) ne correspond pas à un dossier. Un enregistrement peut être stocké dans une partie d'un dossier qui contient d'autres documents, dans un seul dossier dédié au document en question, ou dans plusieurs dossiers coordonnés. De plus, une copie peut être stockée dans une mémoire sans être stockée dans un fichier.
Le moteur de recherche peut comprendre un moteur de classement pour classer les documents liés à la requête d'entrée. Le classement des documents peut être effectué à l'aide de techniques traditionnelles pour déterminer un score de récupération d'informations (IR) pour les enregistrements indexés en fonction d'une requête donnée.
Toute méthode appropriée peut déterminer la pertinence d'un document particulier dans un terme de recherche spécifique ou par rapport à d'autres informations fournies. Par exemple, le niveau général de back-links vers un document contenant des correspondances pour un terme de recherche peut être utilisé pour déduire la pertinence d'un document.
En particulier, si un document est lié (par exemple, est la cible d'un lien hypertexte) par de nombreux autres documents pertinents (tels que des documents contenant des correspondances pour les termes de recherche), il peut en être déduit que le document cible est particulièrement pertinent. Cette inférence peut être faite parce que les auteurs des articles de pointage pointent vraisemblablement, pour la plupart, vers d'autres documents qui sont pertinents pour leur public.
Les documents de pointage ciblent des liens provenant d'autres documents pertinents, qui peuvent être considérés comme plus pertinents. Le premier document est particulièrement adapté car il cible des documents applicables (voire très pertinents).
Une telle technique peut déterminer la pertinence d'un document ou l'un des nombreux déterminants. Des méthodes appropriées peuvent également être utilisées pour identifier et réduire les tentatives de vote frauduleux afin d'augmenter la pertinence d'une page.
Pour améliorer davantage ces techniques traditionnelles de classement de documents, le moteur de classement peut recevoir davantage de signaux d'un moteur de modification de classement pour aider à déterminer un classement approprié pour les documents.
En conjonction avec les annotateurs d'images et la catégorisation des requêtes décrits ci-dessus, le moteur de modification de classement fournit des mesures de pertinence pour les articles. Le moteur de classement peut utiliser pour améliorer le classement des résultats de recherche fourni à l'utilisateur.
Le moteur de modificateur de classement peut effectuer des opérations pour générer les mesures de pertinence.
Que le score d'un résultat d'image augmente ou diminue selon que le contenu visuel de l'image (tel que représenté dans les annotations d'image) correspond à la catégorisation de la requête, chaque catégorie d'image est prise en compte.
Par exemple, si la catégorisation de la requête est « personne seule », un résultat d'image classé à la fois comme « capture d'écran » et « visage unique » verrait d'abord son score diminuer en raison de la catégorie « capture d'écran ». Il peut alors augmenter son score du fait de la catégorie « simple face ».
Le moteur de recherche peut transmettre la liste finale des résultats classés dans les résultats de recherche côté serveur via le réseau. En quittant le réseau, les résultats de la recherche côté client peuvent être reçus par le périphérique client, où les résultats peuvent être stockés dans la RAM et utilisés par le processeur pour afficher les résultats sur un périphérique de sortie pour l'utilisateur.
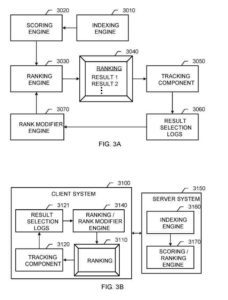
Un système de recherche d'informations
Ces composants comprennent un :
- Moteur d'indexation
- Moteur de notation
- Moteur de classement
- Moteur de modificateur de classement
Le moteur d'indexation fonctionne comme décrit ci-dessus pour le moteur d'indexation. Le moteur de notation génère des scores pour les résultats du document en fonction de nombreuses fonctionnalités, y compris les fonctionnalités basées sur le contenu qui lient une requête aux résultats du document et les parties indépendantes de la requête qui indiquent généralement la qualité des résultats des documents.
Les fonctionnalités basées sur le contenu pour les images incluent des aspects du document qui contient l'image, tels que les correspondances de requête avec le titre du document ou la légende de l'image.
Les fonctionnalités indépendantes de la requête comprennent, par exemple, des aspects de référencement croisé de document du papier ou des dimensions de domaine ou d'image.
De plus, les fonctions particulières utilisées par le moteur de notation peuvent être ajustées pour ajuster les différentes contributions des caractéristiques au score IR final, en utilisant des processus automatiques ou semi-automatiques.
Le moteur de classement classe les résultats de document à afficher pour un utilisateur sur la base des scores IR reçus de la machine de notation et des signaux provenant du moteur de modification de classement.
Le moteur de modification de classement fournit des mesures de pertinence pour les documents, que le moteur de classement peut utiliser pour améliorer le classement des résultats de recherche fourni à l'utilisateur. Un composant de suivi enregistre des informations sur le comportement de l'utilisateur, telles que des sélections d'utilisateurs individuels des résultats présentés dans la commande.
Le composant de suivi obtient un code JavaScript intégré inclus dans un classement de page Web qui identifie les sélections de l'utilisateur de résultats de document individuels et identifie le moment où l'utilisateur revient à la page de résultats, indiquant ainsi le temps passé par l'utilisateur à visualiser le résultat de document sélectionné.
Le composant de suivi est un système proxy par lequel les sélections de l'utilisateur des résultats du document sont acheminées. Le composant de suivi peut également inclure un logiciel préinstallé pour le client (tel qu'un plug-in de barre d'outils pour le système d'exploitation du client).
D'autres implémentations sont également possibles, par exemple, celle qui utilise une fonctionnalité d'un navigateur Web qui permet à une balise/directive d'être incluse dans une page, qui demande au navigateur de se reconnecter au serveur avec des messages sur les liens cliqués par l'utilisateur.
Les informations enregistrées sont stockées dans les journaux de sélection des résultats. Les informations enregistrées comprennent des entrées de journal qui indiquent l'interaction de l'utilisateur avec chaque document de résultat présenté pour chaque requête soumise.
Pour chaque sélection par l'utilisateur d'un document de résultat présenté pour une requête, les entrées du journal indiquent la requête (Q), le papier (D), le temps de passage de l'utilisateur (T) sur le document, la langue (L) employée par l'utilisateur, et le pays (C) où l'utilisateur est probablement situé (par exemple, sur la base du serveur utilisé pour accéder au système IR) et un code de région (R) identifiant la zone métropolitaine de l'utilisateur.
Les entrées de journal enregistrent également des informations négatives, telles qu'un résultat de document est présenté à un utilisateur mais n'a pas été sélectionné.
Autres informations telles que :
- Positions des clics (c'est-à-dire, les sélections de l'utilisateur dans l'interface utilisateur
- Informations sur la session (telles que l'existence et le type de clics précédents (activité de session post-clic))
- Scores R des résultats cliqués
- Scores IR de tous les résultats affichés avant le clic
- Les titres et les extraits sont affichés à l'utilisateur avant le clic
- Cookie de l'utilisateur
- Âge des cookies
- Adresse IP (protocole Internet)
- User-agent du navigateur
- Bientôt
Le temps (T) entre le clic initial sur le résultat du document et le retour des utilisateurs à la page principale et le clic sur un autre résultat de document (ou la soumission d'une nouvelle requête de recherche) est également enregistré.
Une évaluation est faite sur le temps (T) pour savoir si ce temps indique une vue plus longue ou plus courte du document puisque des arguments plus étendus montrent généralement la qualité ou la pertinence pour le résultat cliqué. Cette évaluation du temps (T) peut être faite en conjonction avec diverses techniques de pondération.
Les composants représentés peuvent être combinés de diverses manières et dans de multiples configurations de système. Les moteurs de notation et de tanking fusionnent en un seul moteur de classement, tel que le moteur de classement. Le moteur de modification de classement et le moteur de classement peuvent également être fusionnés. En général, un moteur de classement comprend tout composant logiciel qui génère un classement des résultats d'un document après une requête. De plus, un moteur de classement peut intégrer un système client également (ou plutôt que) dans un système serveur.
Un autre exemple est le système de recherche d'informations. Le système de serveur comprend un moteur d'indexation et un moteur de notation/classement.
Dans ce système, un système client comprend :
- Une interface utilisateur pour présenter un classement
- Un composant de suivi
- Journaux de sélection des résultats
- Un moteur de modification de classement/rang.
Par exemple, le système client peut comprendre le réseau d'entreprise et les ordinateurs personnels d'une entreprise, dans lesquels un module d'extension de navigateur incorpore le moteur de modification de classement/rang.
Lorsqu'un employé de l'entreprise lance une recherche sur le système serveur, le moteur de notation/classement peut renvoyer les résultats de la recherche. Un classement initial ou les scores IR réels pour les résultats. Le plug-in de navigateur reclasse ensuite les résultats en fonction des sélections de pages suivies pour la base d'utilisateurs spécifique à l'entreprise.
Une technique de catégorisation des requêtes
Cette technique peut être effectuée en ligne (dans le cadre du traitement des requêtes) ou hors ligne.
Les premiers résultats d'image répondant à la première requête sont reçus. Chacune des premières images est associée à une commande (telle qu'un score IR) et à des données de comportement d'utilisateur respectives (telles que des données de clic).
Un certain nombre des premières images sont sélectionnées lorsqu'une métrique pour les données de comportement respectives pour chaque image sélectionnée satisfait un seuil.
Les premières images sélectionnées sont associées à plusieurs annotations sur la base de l'analyse de contenu des premières images choisies. Les annotations d'image peuvent être conservées dans les annotations d'image.
Les catégories sont ensuite associées à la première requête basée sur les annotations.
Les associations de catégorisation des requêtes peuvent durer dans les catégories de requête.
Des résultats de seconde image répondant à une seconde requête qui est identique ou à la première requête sont ensuite reçus.
(Si la deuxième requête n'est pas trouvée dans la catégorisation de la requête, la deuxième requête peut être transformée ou "réécrite" pour déterminer si une autre forme correspond à une requête dans la catégorisation de la requête.)
Dans cet exemple, la deuxième requête est identique ou peut être réécrite comme la première requête.
Les résultats de la seconde image sont réordonnés sur la base de la catégorisation de la requête avant d'être associés à la première requête.
Rechercher des actualités directement dans votre boîte de réception
*Obligatoire