
画像結果に基づくクエリ分類
公開: 2022-04-27Googleは最近、画像結果に基づくクエリ分類に関する特許を取得しました。
この特許は次のように述べています。「インターネット検索エンジンは、画像検索時に一連の画像検索結果を返すことにより、ユーザーの検索クエリに応答するインターネットアクセス可能なリソース(Webページ、画像、テキストドキュメント、マルチメディアコンテンツなど)に関する情報を提供します。クエリに応答して。」
検索結果には、たとえば、画像または画像と情報のスニペットを含むドキュメントのURL(Uniform Resource Locator)が含まれます。
スコアリング関数を使用したSERPのランク付け
検索結果は、スコアリング関数によって割り当てられたスコアに従って(順番などに)ランク付けできます。
スコアリング関数は、さまざまな信号に従って検索結果をランク付けします。
- 画像を囲むドキュメントテキストのどこに(そしてどのくらいの頻度で)クエリテキストが表示されるか
- アイデアの画像キャプションまたは代替テキスト
- 検索エンジンによって索引付けされた検索結果でのクエリ用語の標準性。
一般に、この特許に記載されている主題は、以下を含む方法である。
- 最初のクエリの最初の画像結果から画像を取得します。ここで、取得した画像がクエリの検索結果である場合に、取得した画像とのユーザーの相互作用を示すスコアおよびユーザー行動データに関連付けられた取得画像の数
- それぞれがしきい値を満たすそれぞれの行動データを有する取得された画像の数を選択する
- 選択した画像のコンテンツの分析に基づいて、選択した最初の画像をいくつかの注釈に関連付けます
これらには、オプションで次の機能を含めることができます。
最初のクエリは、注釈に基づいてカテゴリに関連付けることができます。 クエリの分類と注釈の関連付けは、将来の使用のために保存できます。 2番目の画像の結果は、最初のクエリと同じまたは類似した2番目のクエリに応答して受信できます。
2番目の画像はそれぞれスコアに関連付けられ、2番目の画像は最初のクエリに関連するカテゴリに基づいて変更できます。
クエリの分類の1つは、最初のクエリが1人のクエリであり、2番目の画像のスコアを上げることを示すことができます。その注釈は、2番目の画像のセットに単一の顔が含まれていることを示しています。
1つのクエリ分類は、最初のクエリが多様であると述べ、2番目の画像のスコアを上げることができます。その注釈は、2番目の画像のセットが多様であることを示しています。
カテゴリの1つは、最初のクエリがテキストクエリであると述べ、2番目の画像のスコアを上げることができます。その注釈は、2番目の画像のセットにテキストが含まれていることを示しています。
最初のクエリは、トレーニングを受けた分類子に提供され、カテゴリ内のクエリの分類を決定できます。
選択された最初の画像のコンテンツの分析には、最初の画像の結果をクラスタリングして、注釈内の注釈を決定することが含まれます。 ユーザー行動データは、ユーザーが最初のクエリの検索結果で画像を選択した回数です。
この特許に記載されている主題は、以下の利点を実現するために実施することができる。
画像結果セットは、画像注釈とクエリ分類を導出するために分析され、画像検索結果とのユーザーインタラクションを使用して、クエリのタイプを導出できます。
クエリの分類
クエリカテゴリは、画像検索結果の関連性、品質、多様性を向上させることができます。
クエリの分類は、クエリ処理の一部として、またはオフラインプロセスで使用することもできます。
クエリカテゴリを使用して、「顔のある画像のみを表示する」や「クリップアートのみを表示する」などの自動クエリ提案を提供できます。
画像の結果に基づくクエリの分類
発明者:AnnaMajkowskaとCristianTapus
譲受人:GOOGLE LLC
米国特許:11,308,149
付与:2022年4月19日
提出日:2017年11月3日
概要
画像結果に基づくクエリ分類のための、コンピュータ記憶媒体上にエンコードされたコンピュータプログラムを含む方法、システム、および装置。
一態様では、方法は、クエリに応答する画像結果から画像を受信することを含み、各写真は、最初のクエリの検索結果として画像結果の順序および画像のそれぞれのユーザ行動データに関連付けられ、選択された最初の画像のコンテンツの分析に基づいて、複数の注釈が付けられた最初の画像。
クエリの分類を使用して、クエリに対して返される一連の結果を改善するシステム
コンピューティングデバイス上で実行されているWebブラウザやその他のプロセスなどのクライアントは、入力クエリを検索エンジンに送信し、検索エンジンは画像検索結果をクライアントに返します。 一部の実装では、クエリは文字セット内の文字などのテキスト(「赤いトマト」など)で構成されます。
クエリは、画像、音声、動画、またはこれらの組み合わせで構成されます。 他のクエリタイプも可能です。 検索エンジンは、入力クエリと等しいか、それよりも広い、またはより具体的な代替クエリバージョンに基づいて結果を検索します。
画像検索結果は、入力クエリに応答すると判断されたドキュメントまたはそのリンクの順序付きまたはランク付けされたリストであり、最も関連性が高いと判断されたドキュメントが最高ランクになります。 コピーとは、Webページ、画像、または別の電子ファイルです。
画像検索の場合、検索エンジンは、少なくとも部分的に、以下に基づいて画像の関連性を判断します。
- 画像のコンテンツ
- 画像を囲むテキスト
- 画像キャプション
- 画像の代替テキスト
クエリに関連付けられたカテゴリ
画像検索結果を生成する際に、一部の実装の検索エンジンは、クエリに関連付けられたカテゴリのリクエストを送信します。 検索エンジンは、関連するカテゴリを使用して、関連するカテゴリに属すると判断された画像結果のランクを上げることにより、画像検索結果を並べ替えることができます。
場合によっては、関連するカテゴリまたはその両方に属していない画像結果が減少することがあります。
検索エンジンは、結果のカテゴリを使用して、クエリカテゴリと組み合わせて、またはクエリカテゴリの最終的な結果セットでどのようにランク付けするかを決定することもできます。
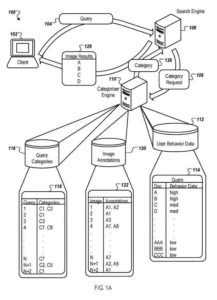
カテゴライザーエンジンまたはその他のプロセスは、クエリ用に取得された画像結果とユーザー行動データリポジトリを使用して、クエリのカテゴリを導き出します。 リポジトリには、ユーザーの行動データが含まれています。 ストレージは、ユーザーの母集団が特定のクエリの画像結果を選択した回数を示します。
画像の選択は、キーボード、コンピューターのマウスまたは指のジェスチャー、音声コマンド、またはその他の方法を使用するなど、さまざまな方法で実行できます。 ユーザー行動データには「クリックデータ」が含まれます。
クリックデータは、ユーザーが画像の結果を表示または「滞留」する時間を示します
クリックデータは、ユーザーがクエリの結果リストで画像を選択した後、画像の結果を表示または「滞留」する時間を示します。 たとえば、「ロングクリック」と呼ばれる画像を長時間(1分以上など)滞在すると、ユーザーがユーザーのクエリに関連する画像を見つけたと言えます。
「ショートクリック」と呼ばれる、画像を短時間(たとえば、30秒未満)表示すると、画像の関連性が欠如していると解釈される可能性があります。 他のタイプのユーザー行動データも可能です。
例として、ユーザーの行動データは、特定のクエリに応答してユーザーが選択した結果ドキュメントのレコードを作成するプロセスによって生成できます。 各フォームはタプルとして表すことができます:<ドキュメント、クエリ、データ>):以下を含みます:
- ユーザーから送信された質問
- クエリを示すクエリリファレンス
- ドキュメントは、クエリに応答してユーザーが選択した論文を参照します
- クエリに応答してドキュメント参照を選択したすべてのユーザーまたはすべてのユーザーのサブセットのクリックデータ(各クリックタイプの数など)の集計。
このタプルベースのアプローチをユーザー行動データに拡張することが可能です。 たとえば、ユーザーの行動データを拡張して、場所固有(国や州など)または言語固有の識別子を含めることができます。
このような識別子が含まれている場合、国固有のタプルはユーザークエリが発生した国で構成され、言語固有のタプルはユーザークエリの言語で構成されます。
表示を簡単にするために、クエリのドキュメントA〜CCCに関連付けられたユーザー行動データは、「高」、「中」、または「低」の量の好ましいユーザー行動データ(ユーザー行動など)として表に示されます。ドキュメントとクエリの関連性を示すデータ)。
ドキュメントのユーザー行動データ
ドキュメントの好ましいユーザー行動データは、クエリの結果で表示されたときにユーザーが紙を選択したこと、またはユーザーがクエリの結果からドキュメントを選択した後にドキュメントを表示したときに、ユーザーがドキュメントを表示したことを示すことができます。長期間(ユーザーがドキュメントが質問に関連していると感じるなど)。
カテゴライザーエンジンは、返された結果とユーザーの行動データを使用して検索エンジンと連携し、クエリカテゴリを決定し、ユーザーに返される前に結果を再ランク付けします。
一般に、クエリカテゴリリクエストで指定されたクエリ(クエリやクエリの代替形式など)の場合、カテゴライザエンジンはクエリの画像結果を分析して、クエリがカテゴリに属しているかどうかを判断します。 一部の実装で分析された画像結果は、しきい値を超えた合計回数(少なくとも10回設定など)のクエリの検索結果としてユーザーによって選択されています。
カテゴライザーエンジンは、特定のクエリに対して検索エンジンによって取得されたすべての画像結果を分析します。 他の実装では
カテゴライザーエンジンは、クリックデータのメトリック(たとえば、選択の総数または別のメジャー)がしきい値を超えているクエリの画像結果を分析します。
画像の結果は、スコアリングプロセス中に、オフラインまたはオンラインのさまざまな方法でコンピュータビジョン技術を使用してオンラインで分析できます。 画像には、視覚的なコンテンツから抽出された情報が注釈として付けられます。
画像の注釈
たとえば、画像の注釈を注釈ストアに保存できます。 分析された各画像(たとえば、画像1、画像2など)は、写真と注釈の関連付けの注釈(たとえば、A1、A2など)に関連付けられます。
注釈には次のものを含めることができます。
- 画像内の顔の数
- 各面のサイズ
- 画像の主な色
- 画像にテキストまたはグラフが含まれているかどうか
- 画像がスクリーンショットかどうか
さらに、各画像に指紋の注釈を付けることができます。指紋により、2つの画像が同一であるか同一であるかを判断できます。
次に、カテゴライザエンジンは、特定のクエリの画像結果とその注釈を分析して、クエリカテゴリを決定します。 特定のクエリ(クエリ1、クエリ2など)に対するクエリカテゴリ(C1、C2など)の関連付けは、単純なヒューリスティックや自動分類器を使用するなど、さまざまな方法で決定できます。
ヒューリスティックに基づく単純なクエリカテゴリ
例として、ヒューリスティックに基づく単純なクエリカテゴライザーを使用して、クエリに必要な主要な色(および存在するかどうか)を決定できます。
ヒューリスティックは、たとえば、クエリで最も頻繁にクリックされる上位20の画像のうち、少なくとも70%が主な色が赤である場合、クエリは「赤のクエリ」として分類される可能性があります。 このようなクエリの場合、検索エンジンは取得した結果を並べ替えて、主な色として赤で注釈が付けられたすべての画像のランクを上げることができます。
同じ分類を他のすべての標準色で使用できます。 クエリのテキストを過剰に分析するこのアプローチの利点は、翻訳を必要とせずにすべての言語で機能することです(たとえば、どの言語でも「赤いリンゴ」という質問に対して赤い色が支配的な画像を宣伝します)。 より堅牢です(「赤い海」というクエリの赤い画像のランクが上がることはありません)。
カテゴライザーエンジンの例
カテゴライザエンジンは、オンラインモードまたはオフラインモードで動作できます。このモードでは、クエリカテゴリの関連付けが事前に(たとえば、テーブルに)保存され、クエリ処理中に検索エンジンで使用されます。
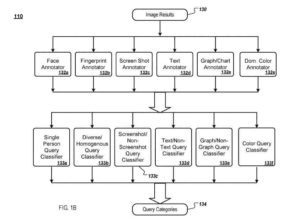
エンジンは、特定のクエリのクエリ画像結果を受け取り、画像アノテーターに画像結果を提供します。 各画像アノテーターは、画像の結果を分析し、画像の視覚的コンテンツに関する情報を抽出します。この情報は、アイデアの画像注釈(画像注釈など)として保存されます。
顔画像アノテーター
実例として、顔画像アノテーター:
- 画像に含まれる顔の数と各顔のサイズを決定します
- 指紋画像アノテーターは、視覚的な画像の特徴を凝縮された形式(指紋)で抽出します。これを別の画像の指紋と比較して、2つの画像が類似しているかどうかを判断できます。
- スクリーンショット画像アノテーターは、画像がスクリーンショットであるかどうかを判断します
- テキスト画像アノテーターは、画像にテキストが含まれているかどうかを判断します
- グラフ/チャート画像クエリは、画像にグラフまたはチャート(棒グラフなど)が含まれるかどうかを判断します
- ドミナントカラーアノテーターは、画像にドミナントカラーが含まれているかどうかを判断します
他の画像アノテーターも使用できます。 たとえば、いくつかの画像アノテーターは、Viola、P.による「ブーストされた単純な機能のカスケードを使用した高速オブジェクト検出」というタイトルの論文で説明されています。 ジョーンズ、M。、三菱電機研究所、TR2004-043(2004年5月)。
次に、カテゴライザエンジンは、特定のクエリの画像結果とその注釈を分析して、クエリカテゴリ(クエリカテゴリなど)を決定します。 クエリカテゴリは分類器を使用して決定され、クエリ分類器は機械学習システムを使用して実現できます。
アダプティブブースティングの使用
例として、Adaptive Boostingの略であるAdaBoostは、他の学習アルゴリズムと併用してパフォーマンスを向上させることができる機械学習システムです。 AdaBoostは、クエリの分類を生成するために使用されます。 (より多くの学習アルゴリズムが可能です)
AdaBoostは、一連のラウンドで「弱い」画像アノテーターを呼び出します。 実例として、一人のクエリ分類器は、クエリが一人の人の画像を要求するかどうかを決定するように訓練された学習機械アルゴリズムに基づいて取得することができる。
例として、そのようなクエリ分類器は、クエリ、0個以上の顔を持つ質問の結果画像を表す特徴ベクトルのセット、およびクエリの正しい分類(つまり、顔かどうか)を含むデータセットでトレーニングすることができます。 。 クエリ分類器は、呼び出しごとに、分類のトレーニングデータセット内の例の重要性を示す重みの分布を更新します。
各ラウンドで、分類された各トレーニング例の重みが増加する(または分類された各トレーニング例の結果が減少する)ため、新しいクエリ分類はこれらの例に焦点を当てます。 結果として得られるトレーニング済みのクエリ分類では、クエリを入力として受け取り、クエリが1人の人物を含む画像を要求する確率を出力できます。
多様で均質なクエリ分類器は、入力としてクエリを受け取り、クエリがさまざまな画像に対するものである確率を出力します。 分類子は、クラスタリングアルゴリズムを使用して、相互の距離の測定値に基づくフィンガープリントに従って画像結果をクラスタリングします。 各イメージはクラスター識別子に関連付けられます。
画像クラスター識別子は、クラスターの数、グループのサイズ、および結果セット内の画像によって形成されたクラスター間の類似性を判別するために使用されます。 たとえば、この情報は、クエリが特定である(または重複を招く)かどうかの確率を関連付けるために使用されます。
クエリを正規の意味および表現に関連付ける
クエリの分類は、クエリを正規の意味や表現に関連付けるためにも使用できます。 たとえば、単一の大きなクラスターまたは複数の大きなクラスターがある場合、質問が重複した画像の結果に関連する可能性が高くなります。 小さなクラスターが多数ある場合、クエリが同じ画像結果に関連付けられる可能性は低くなります。
画像の複製は、それ以上の情報を提供しないため、通常はあまり役に立ちません。したがって、クエリ結果として降格する必要があります。 ただし、例外があります。 たとえば、初期結果に重複が多数ある場合(少数の大きなクラスター)、クエリは特定のものであり、重複は降格されません。
スクリーンショット/非スクリーンショットクエリの分類は、入力としてクエリを受け取り、クエリがスクリーンショットである画像を要求する確率を出力します。 テキスト/非テキストクエリ分類子は、入力としてクエリを受け入れ、クエリがテキストを含む画像を呼び出す可能性を出力します。
グラフ/非グラフクエリの分類は、クエリの入力を受け取り、クエリがグラフまたはチャートを含む画像を要求する確率を出力します。 カラークエリ分類器133fは、情報クエリを受け取り、クエリが単一の色によって支配されるショットを呼び出すチャンスを出力する。 他のクエリ分類子も可能です。
クエリ分類に基づく画像結果の関連性の改善
検索者は、クライアントまたは他のデバイスを介してシステムと対話できます。 たとえば、クライアントデバイスは、ローカルエリアネットワーク(LAN)または広大なエリアネットワーク(WAN)内のコンピューター端末にすることができます。 クライアントデバイスは、LAN、WAN、またはその他のネットワーク(たとえば、携帯電話ネットワーク)を介して通信できるモバイルデバイス(たとえば、携帯電話、モバイルコンピュータ、パーソナルデスクトップアシスタントなど)にすることができます。
クライアントデバイスには、ランダムアクセスメモリ(RAM)(または他のメモリとストレージデバイス)とプロセッサを含めることができます。
プロセッサは、システム内の命令とデータを処理するように構造化されます。 プロセッサは、処理コアを備えたシングルスレッドまたはマルチスレッドのマイクロプロセッサです。 プロセッサは、RAM(または他のメモリとクライアントデバイスに含まれるストレージデバイス)に格納された命令を実行するように構造化されて受信し、ユーザーインターフェイスのグラフィック情報をレンダリングします。

検索者は、サーバーシステム内の検索エンジンに接続して、入力クエリを送信できます。 検索エンジンは、画像やドキュメント(HTMLページなど)などの他の種類のコンテンツを取得できる画像検索エンジンまたは汎用検索エンジンです。
ユーザーがクライアントデバイスに接続された入力デバイスを介して入力クエリを送信すると、クライアント側の質問がネットワークに送信され、サーバー側のクエリとしてサーバーシステムに転送されます。 サーバーシステムは、場所にあるサーバーデバイスにすることができます。 サーバーデバイスは、そこにロードされた検索エンジンからなるメモリデバイスを含む。
プロセッサは、デバイス内の命令を処理するように構造化されます。 これらの手順では、検索エンジンのコンポーネントをインストールできます。 プロセッサはシングルスレッドまたはマルチスレッドであり、多くの処理コアを含みます。 プロセッサは、検索エンジンに関連するメモリに格納された命令を処理し、ネットワークを介してクライアントデバイスに情報を送信して、クライアントデバイスのユーザーインターフェイスにグラフィカルなプレゼンテーションを作成できます(たとえば、Webに表示されるWebページの検索結果)。ブラウザ)。
サーバー側のクエリは検索エンジンによって受信されます。 検索エンジンは、入力クエリ内の情報(クエリ用語など)を使用して、関連するドキュメントを検索します。 検索エンジンには、コーパス(たとえば、インターネット上のWebページ)を検索して、そのコーパスで見つかったドキュメントにインデックスを付けるインデックスエンジンを含めることができます。 コーパスドキュメントのインデックス情報は、インデックスデータベースに保存できます。
このインデックスデータベースにアクセスして、ユーザーに関連するドキュメントを特定できます。 電子コピー(ドキュメントと呼ばれる)はファイルに対応していないことに注意してください。 レコードは、他のドキュメントを保持するファイルの一部、問題のドキュメント専用の単一のファイル、または多くの調整されたファイルに保存できます。 さらに、コピーはファイルに保存せずにメモリに保存できます。
検索エンジンには、入力クエリに関連するドキュメントをランク付けするためのランク付けエンジンを含めることができます。 ドキュメントのランク付けは、従来の手法を使用して実行し、特定のクエリでインデックス付けされたレコードの情報検索(IR)スコアを決定できます。
任意の適切な方法で、特定の検索用語内の特定のドキュメントまたは他の提供された情報との関連性を判断できます。 たとえば、検索語の一致を含むドキュメントへのバックリンクの一般的なレベルは、ドキュメントの関連性を推測するために使用される場合があります。
特に、ドキュメントが他の多くの関連ドキュメント(検索語に一致するドキュメントなど)によってリンクされている場合(たとえば、ハイパーリンクのターゲットである場合)、ターゲットドキュメントが特に関連していると推測できます。 この推論は、ポインティングペーパーの作成者が、ほとんどの場合、対象者に関連する他のドキュメントを指していると考えられるために行うことができます。
ポインティングドキュメントは、より関連性が高いと見なすことができる他の関連ドキュメントからのリンクを対象としています。 最初のドキュメントは、該当する(または関連性の高い)ドキュメントを対象としているため、特に適切です。
このような手法は、ドキュメントの関連性または多くの決定要因の1つを決定する場合があります。 ページの関連性を高めるために不正な票を投じる試みを特定して削減するために、適切な方法をとることもできます。
このような従来のドキュメントランキング手法をさらに改善するために、ランキングエンジンは、ランク修飾子エンジンからより多くの信号を受信して、ドキュメントの適切なランキングを決定するのに役立てることができます。
上記の画像アノテーターおよびクエリ分類と組み合わせて、ランク修飾子エンジンは、論文の関連性の尺度を提供します。 ランキングエンジンは、ユーザーに提供される検索結果のランキングを向上させるために使用できます。
ランク修飾子エンジンは、関連性の測定値を生成するための操作を実行できます。
画像結果のスコアが増加するか減少するかは、画像の視覚的コンテンツ(画像注釈で表される)がクエリの分類と一致するかどうかによって異なり、各画像カテゴリが考慮されます。
たとえば、クエリの分類が「単一の人物」である場合、「スクリーンショット」と「単一の顔」の両方に分類される画像結果は、「スクリーンショット」カテゴリのために最初にスコアが減少します。 その後、「シングルフェイス」カテゴリのためにスコアを上げることができます。
検索エンジンは、ネットワークを介してサーバー側の検索結果内の最終的なランク付けされた結果リストを転送できます。 ネットワークを終了すると、クライアント側の検索結果をクライアントデバイスで受信できます。この結果は、RAM内に保存され、プロセッサがユーザーの出力デバイスに結果を表示するために使用できます。
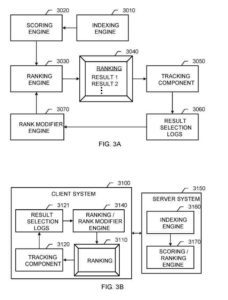
情報検索システム
これらのコンポーネントには、次のものが含まれます。
- インデックスエンジン
- スコアリングエンジン
- ランキングエンジン
- ランク修飾子エンジン
インデックスエンジンは、インデックスエンジンについて前述したように機能します。 スコアリングエンジンは、クエリをドキュメント結果にリンクするコンテンツベースの機能や、ドキュメント結果の品質を一般的に示すクエリに依存しない部分など、多くの機能に基づいてドキュメント結果のスコアを生成します。
画像のコンテンツベースの機能には、ドキュメントのタイトルや画像のキャプションとのクエリの一致など、画像を含むドキュメントの側面が含まれます。
クエリに依存しない機能には、たとえば、紙やドメインまたは画像の寸法のドキュメント相互参照の側面が含まれます。
さらに、スコアリングエンジンで使用される特定の機能は、自動または半自動プロセスを使用して、最終的なIRスコアへのさまざまな機能の寄与を調整するように調整できます。
ランク付けエンジンは、スコアリングマシンから受信したIRスコアとランク修飾子エンジンからの信号に基づいて、ユーザーに表示するためにドキュメントの結果をランク付けします。
ランク修飾子エンジンは、ドキュメントの関連性の測定値を提供します。これを使用して、ランク付けエンジンを使用して、ユーザーに提供される検索結果のランク付けを向上させることができます。 追跡コンポーネントは、注文で提示された結果の個々のユーザー選択など、ユーザーの行動情報を記録します。
追跡コンポーネントは、個々のドキュメント結果のユーザー選択を識別し、ユーザーが結果ページに戻ったときを識別するWebページランキングに含まれる埋め込みJavaScriptコードを取得します。これにより、ユーザーが選択したドキュメント結果の表示に費やした時間を示します。
追跡コンポーネントは、ドキュメント結果のユーザー選択がルーティングされるプロキシシステムです。 追跡コンポーネントには、クライアント用にプリインストールされたソフトウェア(クライアントのオペレーティングシステムへのツールバープラグインなど)を含めることもできます。
他の実装も可能です。たとえば、タグ/ディレクティブをページに含めることができるWebブラウザーの機能を使用して、ユーザーがクリックしたリンクに関するメッセージをブラウザーにサーバーに接続するように要求します。
記録された情報は、結果選択ログに保存されます。 記録された情報には、送信されたクエリごとに提示された各結果ドキュメントとのユーザーの相互作用を示すログエントリが含まれます。
クエリに対して提示された結果ドキュメントのユーザー選択ごとに、ログエントリには、クエリ(Q)、論文(D)、ドキュメントでのユーザーの滞留時間(T)、ユーザーが使用する言語(L)、また、ユーザーがいる可能性が高い国(C)(たとえば、IRシステムへのアクセスに使用されるサーバーに基づく)と、ユーザーの大都市圏を識別する地域コード(R)。
ログエントリには、ドキュメントの結果がユーザーに表示されても選択されなかったなどの否定的な情報も記録されます。
次のようなその他の情報:
- クリックの位置(つまり、ユーザーインターフェイスでのユーザー選択)
- セッションに関する情報(前のクリックの存在とタイプ(クリック後のセッションアクティビティ)など)
- クリックした結果のRスコア
- クリックする前に表示されたすべての結果のIRスコア
- クリックする前に、タイトルとスニペットがユーザーに表示されます
- ユーザーのCookie
- クッキーの時代
- IP(インターネットプロトコル)アドレス
- ブラウザのユーザーエージェント
- 後で
ドキュメント結果への最初のクリックスルーから、ユーザーがメインページに戻って別のドキュメント結果をクリックする(または新しい検索クエリを送信する)までの時間(T)も記録されます。
時間(T)について評価が行われるのは、この時間がドキュメントのより長いビューを示しているのか、より短いビューを示しているのかについてです。 今回の評価(T)は、さまざまな重み付け手法と組み合わせて行うことができます。
示されているコンポーネントは、さまざまな方法および複数のシステム構成で組み合わせることができます。 スコアリングエンドタンキングエンジンは、ランキングエンジンなどの単一のランキングエンジンに統合されます。 ランク修飾子エンジンとランキングエンジンもマージできます。 一般に、ランキングエンジンには、クエリ後にドキュメント結果のランキングを生成するソフトウェアコンポーネントが含まれます。 さらに、ランキングエンジンは、サーバーシステムにも(またはではなく)クライアントシステムに適合させることができます。
もう1つの例は、情報検索システムです。 サーバーシステムには、インデックス作成エンジンとスコアリング/ランク付けエンジンが含まれています。
このシステムでは、クライアントシステムには次のものが含まれます。
- ランキングを表示するためのユーザーインターフェイス
- 追跡コンポーネント
- 結果選択ログ
- ランキング/ランク修飾子エンジン。
たとえば、クライアントシステムには、企業のエンタープライズネットワークとパーソナルコンピュータを含めることができます。この場合、ブラウザプラグインにランキング/ランクモディファイアエンジンが組み込まれています。
会社の従業員がサーバーシステムで検索を開始すると、スコアリング/ランク付けエンジンが検索結果を返すことができます。 結果の初期ランキングまたは実際のIRスコア。 次に、ブラウザプラグインは、企業固有のユーザーベースの追跡されたページ選択に基づいて結果を再ランク付けします。
クエリ分類の手法
この手法は、オンライン(クエリ処理の一部として)またはオフラインで実行できます。
最初のクエリに応答する最初の画像結果が受信されます。 最初の各画像は、注文(IRスコアなど)とそれぞれのユーザー行動データ(クリックデータなど)に関連付けられます。
選択された各画像のそれぞれの動作データのメトリックがしきい値を満たす場合、最初の画像の数が選択されます。
選択された最初の画像は、選択された最初の画像のコンテンツ分析に基づいて、いくつかの注釈に関連付けられます。 画像の注釈は、画像の注釈に保持される可能性があります。
次に、注釈に基づいて、カテゴリが最初のクエリに関連付けられます。
クエリ分類の関連付けは、クエリカテゴリで継続できます。
同じである2番目のクエリに応答する2番目の画像結果、または最初のクエリが受信されます。
(2番目のクエリがクエリ分類で見つからない場合、2番目のクエリを変換または「書き換え」て、代替フォームがクエリ分類のクエリと一致するかどうかを判断できます。)
この例では、2番目のクエリは最初のクエリと同じであるか、最初のクエリと同じように書き換えることができます。
2番目の画像の結果は、最初のクエリに関連付けられる前に、クエリの分類に基づいて並べ替えられます。
受信トレイに直接ニュースを検索
*必須