
Categorização da consulta com base nos resultados da imagem
Publicados: 2022-04-27Recentemente, o Google recebeu uma patente sobre a categorização de consultas com base em resultados de imagens.
A patente nos diz que: “os mecanismos de busca da Internet fornecem informações sobre recursos acessíveis pela Internet (como páginas da Web, imagens, documentos de texto, conteúdo multimídia) que respondem à consulta de pesquisa de um usuário retornando, ao pesquisar imagens, um conjunto de resultados de pesquisa de imagens em resposta à consulta.”
Um resultado de pesquisa inclui, por exemplo, um Uniform Resource Locator (URL) de uma imagem ou um documento que contém a imagem e um fragmento de informação.
Classificando SERPs usando uma função de pontuação
Os resultados da pesquisa podem ser classificados (como em ordem) de acordo com as pontuações atribuídas por uma função de pontuação.
A função de pontuação classifica os resultados da pesquisa de acordo com vários sinais:
- Onde (e com que frequência) o texto da consulta aparece no texto do documento ao redor de uma imagem
- Uma legenda de imagem ou texto alternativo para a ideia
- Quão padrão são os termos de consulta nos resultados de pesquisa indexados pelo mecanismo de pesquisa.
Em geral, o assunto descrito nesta patente está em um método que inclui:
- A obtenção de imagens dos resultados da primeira imagem para uma primeira consulta, em que várias imagens adquiridas associadas a pontuações e dados de comportamento do usuário que indicam a interação do usuário com as imagens obtidas quando as imagens obtidas são resultados de pesquisa para a consulta
- Selecionando um número de imagens adquiridas, cada uma tendo os respectivos dados de comportamento que satisfazem um limite
- Associar as primeiras imagens escolhidas a várias anotações com base na análise do conteúdo das imagens selecionadas
Estes podem incluir opcionalmente os seguintes recursos.
A primeira consulta pode ser associada a categorias com base nas anotações. A categorização de consulta e as associações de anotação podem ser armazenadas para uso futuro. Os resultados da segunda imagem respondem a uma segunda consulta que é a mesma ou como a primeira consulta pode ser recebida.
Cada uma das segundas imagens é associada a uma pontuação e a segunda imagem pode ser modificada com base nas categorias relacionadas à primeira consulta.
Uma das categorizações de consulta pode afirmar que a primeira consulta é uma consulta individual e aumenta as pontuações da segunda imagem, cujas anotações dizem que o conjunto de segundas imagens contém uma única face.
Uma categorização de consulta pode afirmar que a primeira consulta é diversa e aumentar as pontuações das segundas imagens, cujas anotações dizem que o conjunto das segundas imagens é diverso.
Uma das categorias pode afirmar que a primeira consulta é uma consulta de texto e aumentar as pontuações da segunda imagem, cujas anotações dizem que o conjunto de segundas imagens contém o texto.
A primeira consulta pode ser fornecida a um classificador treinado para determinar uma categorização de consulta nas categorias.
A análise do conteúdo das primeiras imagens selecionadas pode incluir o agrupamento dos resultados da primeira imagem para determinar uma anotação nas anotações. Os dados de comportamento do usuário podem ser o número de vezes que os usuários selecionam a imagem nos resultados da pesquisa para a primeira consulta.
O assunto descrito nesta patente pode ser implementado para obter as seguintes vantagens:
O conjunto de resultados de imagem é analisado para derivar anotações de imagem e uma categorização de consulta, e a interação do usuário com os resultados da pesquisa de imagem pode ser usada para derivar tipos de consultas.
Categorização da consulta
As categorias de consulta podem, por sua vez, melhorar a relevância, a qualidade e a diversidade dos resultados da pesquisa de imagens.
A categorização de consultas também pode ser usada como parte do processamento de consultas ou em um processo off-line.
As categorias de consulta podem ser usadas para fornecer sugestões de consulta automatizadas, como “mostrar apenas imagens com rostos” ou “mostrar apenas clip-arts”.
Categorização de consultas com base nos resultados da imagem
Inventores: Anna Majkowska e Cristian Tapus
Cessionário: GOOGLE LLC
Patente dos EUA: 11.308.149
Concedido: 19 de abril de 2022
Arquivado: 3 de novembro de 2017
Resumo
Métodos, sistemas e aparelhos, incluindo programas de computador codificados em um meio de armazenamento de computador, para categorização de consulta com base em resultados de imagem.
Em um aspecto, um método inclui receber imagens de resultados de imagem responsivos a uma consulta, em que cada uma das fotos é associada a um pedido nos resultados de imagem e respectivos dados de comportamento do usuário para a imagem como resultado de pesquisa para a primeira consulta e associação de as primeiras imagens com uma pluralidade de anotações com base na análise do conteúdo das primeiras imagens selecionadas.
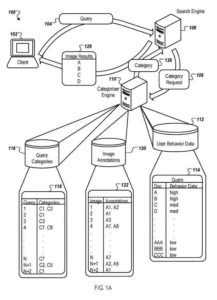
Um sistema que usa categorização de consulta para melhorar o conjunto de resultados retornados para uma consulta
Um cliente, como um navegador da Web ou outro processo executado em um dispositivo de computação, envia uma consulta de entrada para um mecanismo de pesquisa e o mecanismo de pesquisa retorna os resultados da pesquisa de imagens ao cliente. Em algumas implementações, uma consulta compreende texto como caracteres em um conjunto de caracteres (por exemplo, “tomate vermelho”).
Uma consulta inclui imagens, sons, vídeos ou combinações destes. Outros tipos de consulta são possíveis. O mecanismo de pesquisa pesquisará resultados com base em versões de consulta alternativas iguais, mais amplas ou mais específicas que a consulta de entrada.
Os resultados da pesquisa de imagens são uma lista ordenada ou classificada de documentos ou links para tais, que são determinados como responsivos à consulta de entrada, com os documentos determinados como mais relevantes tendo a classificação mais alta. Uma cópia é uma página da web, uma imagem ou outro arquivo eletrônico.
No caso da pesquisa de imagens, o mecanismo de pesquisa determina a relevância de uma imagem com base, pelo menos em parte, no seguinte:
- Conteúdo da imagem
- O texto ao redor da imagem
- Legenda da imagem
- Texto alternativo para a imagem
Categorias associadas a uma consulta
Ao produzir os resultados da pesquisa de imagens, o mecanismo de pesquisa em algumas implementações envia uma solicitação de categorias associadas à consulta. O mecanismo de pesquisa pode usar as categorias associadas para reordenar os resultados da pesquisa de imagens aumentando a classificação dos resultados de imagens determinados como pertencentes às categorias relacionadas.
Em alguns casos, pode diminuir os resultados de imagem que não pertencem às categorias associadas ou a ambas.
O mecanismo de pesquisa também pode usar as categorias dos resultados para determinar como eles devem ser classificados no conjunto finalizado de resultados em combinação com ou da categoria de consulta.
Um mecanismo de categorização ou outro processo emprega resultados de imagem recuperados para a consulta e um repositório de dados de comportamento do usuário para derivar categorias para a consulta. O repositório contém dados de comportamento do usuário. O armazenamento indica o número de vezes que populações de usuários selecionaram um resultado de imagem para uma determinada consulta.
A seleção de imagens pode ser realizada de várias maneiras, inclusive usando o teclado, o mouse do computador ou um gesto com o dedo, um comando de voz ou outros métodos. Os dados de comportamento do usuário incluem “dados de clique”.
Os dados de clique indicam por quanto tempo um usuário visualiza ou “permanece” em um resultado de imagem
Os dados de clique indicam por quanto tempo um usuário visualiza ou “permanece” em um resultado de imagem após selecioná-lo em uma lista de resultados para a consulta. Por exemplo, um longo tempo de permanência em uma imagem (como mais de 1 minuto), denominado "clique longo", pode indicar que um usuário achou a imagem relevante para a consulta do usuário.
Um breve período de visualização de uma imagem (por exemplo, menos de 30 segundos), denominado “clique curto”, pode ser interpretado como falta de relevância da imagem. Outros tipos de dados de comportamento do usuário são possíveis.
A título de ilustração, os dados de comportamento do usuário podem ser gerados por um processo que cria um registro para documentos de resultados selecionados pelos usuários em resposta a uma consulta específica. Cada formulário pode ser representado como uma tupla: <document, query, data>) que inclui:
- Uma pergunta enviada por usuários
- Uma referência de consulta indicando a consulta
- Um documento faz referência a um artigo selecionado pelos usuários em resposta à consulta
- Agregação de dados de clique (como uma contagem de cada tipo de clique) para todos os usuários ou um subconjunto de todos os usuários que selecionaram a referência do documento em resposta à consulta.
Extensões dessa abordagem baseada em tupla para dados de comportamento do usuário são possíveis. Por exemplo, os dados de comportamento do usuário podem ser estendidos para incluir identificadores específicos do local (como país ou estado) ou específicos do idioma.
Com esses identificadores incluídos, uma tupla específica do país consistiria no país de onde a consulta do usuário se originou e uma tupla específica do idioma consistiria no idioma da consulta do usuário.
Para simplificar a apresentação, os dados de comportamento do usuário associados aos documentos A-CCC para a consulta são descritos na tabela como sendo uma quantidade "alta", "média" ou "baixa" de dados favoráveis de comportamento do usuário (como comportamento do usuário dados que indicam relevância entre o documento e a consulta).
Dados de comportamento do usuário para um documento
Dados de comportamento do usuário favoráveis para um documento podem indicar que o documento é selecionado pelos usuários quando é visualizado nos resultados da consulta, ou quando um usuário visualiza o documento após escolhê-lo nos resultados da consulta, os usuários visualizam o documento por um período prolongado (como o usuário acha que o documento é relevante para a questão).
O mecanismo de categorização funciona em conjunto com o mecanismo de pesquisa usando resultados retornados e dados de comportamento do usuário para determinar as categorias de consulta e, em seguida, reclassificar os resultados antes de serem devolvidos ao usuário.
Em geral, para a consulta (como uma consulta ou uma forma alternativa da consulta) especificada na solicitação de categoria de consulta, o mecanismo do categorizador analisa os resultados da imagem da consulta para determinar se ela pertence a categorias. Os resultados de imagem analisados em algumas implementações foram selecionados pelos usuários como resultado da pesquisa para a consulta um número total de vezes acima de um limite (como definir pelo menos dez vezes).
O mecanismo categorizador analisa todos os resultados de imagem recuperados pelo mecanismo de pesquisa para uma determinada consulta. em outras implementações
O mecanismo do categorizador analisa os resultados da imagem para a consulta em que uma métrica (por exemplo, o número total de seleções ou outra medida) para os dados de clique está acima de um limite.
Os resultados da imagem podem ser analisados online usando técnicas de visão computacional de várias maneiras, seja offline ou online, durante o processo de pontuação. As imagens são anotadas com informações extraídas de seu conteúdo visual.
Anotações de imagem
Por exemplo, as anotações de imagem podem ser armazenadas no armazenamento de anotações. Cada imagem analisada (por exemplo, imagem 1, imagem 2, etc.) é associada a anotações (por exemplo, A1, A2 e assim por diante) em uma associação de foto para anotação.
As anotações podem incluir:
- O número de rostos na imagem
- O tamanho de cada rosto
- As cores dominantes da imagem
- Se uma imagem contém texto ou um gráfico
- Se uma imagem é uma captura de tela
Além disso, cada imagem pode ser anotada com uma impressão digital que pode determinar se duas imagens são idênticas ou idênticas.
Em seguida, o mecanismo do categorizador analisa os resultados da imagem para uma determinada consulta e suas anotações para determinar as categorias de consulta. As associações de categorias de consulta (por exemplo, C1, C2 e assim por diante) para uma determinada consulta (como consulta 1, consulta 2 etc.) podem ser determinadas de várias maneiras, como usando uma heurística simples ou um classificador automatizado.
Um categorizador de consulta simples baseado em uma heurística
Como exemplo, um categorizador de consulta simples baseado em uma heurística pode ser usado para determinar a cor dominante desejada para a consulta (e se existe uma).
A heurística pode ser, por exemplo, que se das 20 imagens mais clicadas para a consulta, pelo menos 70% têm uma cor dominante vermelha, a consulta pode ser categorizada como “consulta vermelha”. Para essas consultas, o mecanismo de pesquisa pode reordenar os resultados recuperados para aumentar a classificação de todas as imagens anotadas com vermelho como cor dominante.
A mesma categorização pode ser usada com todas as outras cores padrão. Uma vantagem dessa abordagem de superanálise do texto da consulta é que ela funciona para todos os idiomas sem a necessidade de tradução (como promover imagens com cor vermelha dominante para a pergunta “maçã vermelha” em qualquer idioma). É mais robusto (por exemplo, não aumentará a classificação das imagens vermelhas para a consulta “mar vermelho”).
Um Motor Categorizador de Exemplo
O mecanismo categorizador pode funcionar em modo online ou offline, no qual as associações de categorias de consulta são armazenadas antecipadamente (por exemplo, na tabela) para uso pelo mecanismo de pesquisa durante o processamento da consulta.
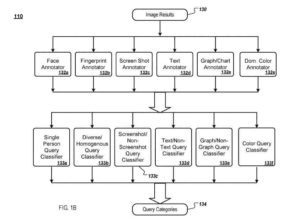
O mecanismo recebe os resultados da imagem de consulta para uma determinada consulta e fornece os resultados da imagem aos anotadores de imagem. Cada anotador de imagem analisa os resultados da imagem e extrai informações sobre o conteúdo visual da imagem, que é armazenada como uma anotação de imagem (por exemplo, anotações de imagem) para a ideia.
Um Anotador de Imagem de Rosto
A título de ilustração, um anotador de imagem de rosto:
- Determina quantos rostos estão em uma imagem e o tamanho de cada rosto
- um anotador de imagem de impressão digital extrai recursos de imagem visual em uma forma condensada (impressão digital) que pode ser comparada com a impressão digital de outra imagem para determinar se as duas imagens são semelhantes
- Um anotador de imagem de captura de tela determina se uma imagem é uma captura de tela
- Um anotador de imagem de texto determina se uma imagem contém texto
- Uma consulta de imagem de gráfico/gráfico determina se uma imagem inclui gráficos ou tabelas (por exemplo, gráficos de barras)
- Um anotador de cor dominante determina se uma imagem contém uma cor dominante
Outros anotadores de imagem também podem ser usados. Por exemplo, vários anotadores de imagem são descritos em um artigo intitulado “Detecção Rápida de Objetos Usando uma Cascata Impulsionada de Recursos Simples”, de Viola, P.; Jones, M., Mitsubishi Electric Research Laboratories, TR2004-043 (maio de 2004).
Em seguida, o mecanismo do categorizador analisa os resultados da imagem para uma determinada consulta e suas anotações para determinar as categorias de consulta (por exemplo, categorias de consulta). As categorias de consulta são determinadas usando um classificador, e um classificador de consulta pode ser realizado usando um sistema de aprendizado de máquina.
Uso de reforço adaptativo
A título de ilustração, AdaBoost, abreviação de Adaptive Boosting, é um sistema de aprendizado de máquina que pode ser usado com outros algoritmos de aprendizado para melhorar seu desempenho. O AdaBoost é usado para gerar uma categorização de consulta. (Mais algoritmos de aprendizado são possíveis)
AdaBoost invoca um anotador de imagem “fraco” em uma série de rodadas. A título de ilustração, o classificador de consulta de uma única pessoa pode ser baseado em um algoritmo de máquina de aprendizado treinado para determinar se uma consulta exige imagens de uma única pessoa.
A título de ilustração, tal classificador de consulta pode ser treinado com conjuntos de dados que compreendem uma consulta, um conjunto de vetores de recursos representando imagens de resultado para a questão com zero ou mais faces e a categorização correta para a consulta (ou seja, faces ou não) . Para cada chamada, o classificador de consulta atualiza uma distribuição de pesos que indica a importância dos exemplos no conjunto de dados de treinamento para a classificação.
Em cada rodada, os pesos de cada exemplo de treinamento classificado aumentam (ou as consequências de cada exemplo de treinamento classificado diminuem), de modo que a nova categorização de consulta se concentra mais nesses exemplos. A categorização de consulta treinada resultante pode receber como entrada uma consulta e produzir uma probabilidade de que a consulta solicite imagens contendo pessoas únicas.
Um classificador de consulta diverso/homogêneo recebe como entrada uma consulta e gera uma probabilidade de que a consulta seja para várias imagens. O classificador usa um algoritmo de agrupamento para agrupar os resultados das imagens de acordo com suas impressões digitais com base em uma medida de distância entre si. Cada imagem é associada a um identificador de cluster.
O identificador de cluster de imagem é usado para determinar o número de clusters, o tamanho dos grupos e a similaridade entre os clusters formados por imagens no conjunto de resultados. Por exemplo, essa informação é usada para associar uma probabilidade de que a consulta seja específica (ou convidando duplicatas) ou não,
Associando consultas com significados e representações canônicas
A categorização de consultas também pode ser usada para associar consultas com significados e representações canônicas. Por exemplo, se houver um único cluster grande ou vários clusters grandes, a probabilidade de a pergunta ser relacionada a resultados de imagem duplicados é alta. Se houver muitos clusters menores, a probabilidade de a consulta ser associada aos mesmos resultados de imagem é baixa.

Duplicatas de imagens geralmente não são muito úteis, pois não fornecem mais informações, portanto, devem ser rebaixadas como resultados da consulta. Mas, há exceções. Por exemplo, se houver muitas duplicatas nos resultados iniciais (alguns clusters grandes), a consulta é específica e as duplicatas não devem ser rebaixadas.
Uma categorização de consulta de captura de tela/não captura de tela recebe como entrada uma consulta e gera uma probabilidade de que a consulta solicite imagens que são capturas de tela. Um classificador de consulta de texto/não-texto aceita como entrada uma consulta e gera uma chance de que a consulta chame imagens que contenham texto.
Uma categorização de consulta de gráfico/não gráfico recebe uma entrada de uma consulta e gera uma probabilidade de que a consulta solicite imagens que contenham um gráfico ou um gráfico. Um classificador de consulta de cores 133f recebe uma consulta de informações e gera uma chance de que a consulta chame tiros que são dominados por uma única cor. Outros classificadores de consulta são possíveis.
Melhorar a relevância dos resultados de imagem com base na categorização da consulta
Um pesquisador pode interagir com o sistema por meio de um cliente ou outro dispositivo. Por exemplo, o dispositivo cliente pode ser um terminal de computador dentro de uma rede de área local (LAN) ou de uma vasta rede de área (WAN). O dispositivo cliente pode ser um dispositivo móvel (por exemplo, um telefone celular, um computador móvel, um assistente de desktop pessoal, etc.) capaz de se comunicar por uma LAN, WAN ou alguma outra rede (por exemplo, uma rede de telefonia celular).
O dispositivo cliente pode incluir uma memória de acesso aleatório (RAM) (ou outra memória e um dispositivo de armazenamento) e um processador.
O processador é estruturado para processar instruções e dados dentro do sistema. O processador é um microprocessador single-thread ou multi-thread com núcleos de processamento. O processador recebe instruções estruturadas para executar armazenadas na RAM (ou outra memória e um dispositivo de armazenamento incluído no dispositivo cliente) para renderizar informações gráficas para uma interface de usuário.
Um pesquisador pode se conectar ao mecanismo de pesquisa em um sistema de servidor para enviar uma consulta de entrada. O mecanismo de pesquisa é um mecanismo de pesquisa de imagens ou um mecanismo de pesquisa genérico que pode recuperar imagens e outros tipos de conteúdo, como documentos (por exemplo, páginas HTML).
Quando o usuário envia a consulta de entrada por meio de um dispositivo de entrada conectado a um dispositivo cliente, uma pergunta do lado do cliente é enviada para uma rede e encaminhada ao sistema do servidor como uma consulta do lado do servidor. O sistema de servidor pode ser dispositivos de servidor em locais. Um dispositivo servidor inclui um dispositivo de memória que consiste no mecanismo de pesquisa nele carregado.
Um processador é estruturado para processar instruções dentro do dispositivo. Essas instruções podem instalar componentes do mecanismo de pesquisa. O processador pode ser single-thread ou multi-thread e incluir muitos núcleos de processamento. O processador pode processar instruções armazenadas na memória relacionadas ao mecanismo de pesquisa e enviar informações para o dispositivo cliente através da rede para criar uma apresentação gráfica na interface do usuário do dispositivo cliente (por exemplo, resultados de pesquisa em uma página da Web exibida em um navegador).
A consulta do lado do servidor é recebida pelo mecanismo de pesquisa. O mecanismo de pesquisa usa as informações da consulta de entrada (como termos de consulta) para localizar documentos relevantes. O mecanismo de pesquisa pode incluir um mecanismo de indexação que pesquisa um corpus (por exemplo, páginas da Web na Internet) para indexar os documentos encontrados nesse corpus. As informações de índice para os documentos de corpus podem ser armazenadas em um banco de dados de índice.
Este banco de dados de índice pode ser acessado para identificar documentos relacionados ao usuário. Observe que uma cópia eletrônica (que será chamada de documento) não corresponde a um arquivo. Um registro pode ficar armazenado em uma parte de um arquivo que contém outros documentos, em um único arquivo dedicado ao documento em questão ou em vários arquivos coordenados. Além disso, uma cópia pode ser armazenada em uma memória sem ser armazenada em um arquivo.
O mecanismo de pesquisa pode incluir um mecanismo de classificação para classificar os documentos relacionados à consulta de entrada. A classificação dos documentos pode ser realizada usando técnicas tradicionais para determinar uma pontuação de Recuperação de Informações (IR) para registros indexados em uma determinada consulta.
Qualquer método apropriado pode determinar a relevância de um determinado documento em um termo de pesquisa específico ou em outras informações fornecidas. Por exemplo, o nível geral de backlinks para um documento que contém correspondências para um termo de pesquisa pode ser usado para inferir a relevância de um documento.
Em particular, se um documento for vinculado (por exemplo, é o destino de um hiperlink) por muitos outros documentos relevantes (como documentos que contenham correspondências para os termos de pesquisa), pode-se inferir que o documento de destino é particularmente relevante. Essa inferência pode ser feita porque os autores dos artigos de indicação presumivelmente apontam, na maioria das vezes, para outros documentos relevantes para seu público.
Os documentos apontadores têm como alvo links de outros documentos relevantes, que podem ser considerados mais relevantes. O primeiro documento é particularmente apropriado porque visa documentos aplicáveis (ou mesmo altamente relevantes).
Tal técnica pode determinar a relevância de um documento ou um dos muitos determinantes. Métodos apropriados também podem ser usados para identificar e cortar tentativas de lançar votos fraudulentos para aumentar a relevância de uma página.
Para melhorar ainda mais essas técnicas tradicionais de classificação de documentos, o mecanismo de classificação pode receber mais sinais de um mecanismo modificador de classificação para auxiliar na determinação de uma classificação apropriada para os documentos.
Em conjunto com anotadores de imagem e categorização de consulta descritos acima, o mecanismo do modificador de classificação fornece medidas de relevância para os artigos. O mecanismo de classificação pode ser usado para melhorar a classificação dos resultados de pesquisa fornecidos ao usuário.
O mecanismo do modificador de classificação pode realizar operações para gerar as medidas de relevância.
Se a pontuação de um resultado de imagem aumenta ou diminui depende se o conteúdo visual da imagem (conforme representado nas anotações da imagem) corresponde à categorização da consulta, cada categoria de imagem é considerada.
Por exemplo, se a categorização da consulta for "pessoa única", um resultado de imagem classificado como "captura de tela" e "rosto único" primeiro terá sua pontuação reduzida devido à categoria "captura de tela". Ele pode então aumentar sua pontuação por causa da categoria “rosto único”.
O mecanismo de pesquisa pode encaminhar a lista final de resultados classificados nos resultados de pesquisa do lado do servidor pela rede. Saindo da rede, os resultados da pesquisa do lado do cliente podem ser recebidos pelo dispositivo cliente, onde os resultados podem ser armazenados na RAM e usados pelo processador para exibir os resultados em um dispositivo de saída para o usuário.
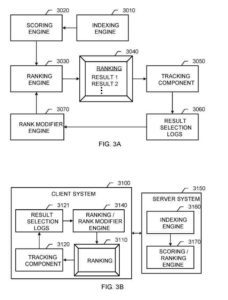
Um sistema de recuperação de informações
Esses componentes incluem um:
- Mecanismo de indexação
- Motor de pontuação
- Motor de classificação
- Mecanismo modificador de classificação
O mecanismo de indexação funciona conforme descrito acima para o mecanismo de indexação. O mecanismo de pontuação gera pontuações para resultados de documentos com base em muitos recursos, incluindo recursos baseados em conteúdo que vinculam uma consulta aos resultados do documento e partes independentes da consulta que geralmente indicam a qualidade dos resultados dos documentos.
Os recursos baseados em conteúdo para imagens incluem aspectos do documento que contém a imagem, como correspondências de consulta com o título do documento ou a legenda da imagem.
Os recursos independentes de consulta incluem, por exemplo, aspectos de referência cruzada de documentos do papel ou do domínio ou das dimensões da imagem.
Além disso, as funções específicas usadas pelo mecanismo de pontuação podem ser ajustadas para ajustar as várias contribuições de recursos para a pontuação final do IR, usando processos automáticos ou semiautomáticos.
O mecanismo de classificação classifica os resultados do documento para exibição a um usuário com base nas pontuações de IR recebidas da máquina de pontuação e nos sinais do mecanismo modificador de classificação.
O mecanismo modificador de classificação fornece medidas de relevância para os documentos, que o mecanismo de classificação pode usar para melhorar a classificação dos resultados de pesquisa fornecidos ao usuário. Um componente de rastreamento registra informações de comportamento do usuário, como seleções de usuários individuais dos resultados apresentados no pedido.
O componente de rastreamento obtém o código JavaScript incorporado incluído em uma classificação de página da Web que identifica as seleções do usuário de resultados de documentos individuais e identifica quando o usuário retorna à página de resultados, indicando assim a quantidade de tempo que o usuário gastou visualizando o resultado do documento selecionado.
O componente de rastreamento é um sistema proxy por meio do qual as seleções do usuário dos resultados do documento são roteadas. O componente de rastreamento também pode incluir software pré-instalado para o cliente (como um plug-in de barra de ferramentas para o sistema operacional do cliente).
Outras implementações também são possíveis, por exemplo, uma que usa um recurso de um navegador da web que permite que uma tag/diretiva seja incluída em uma página, que solicita que o navegador se conecte de volta ao servidor com mensagens sobre links clicados pelo usuário.
As informações registradas são armazenadas em logs de seleção de resultados. As informações registradas incluem entradas de log que informam a interação do usuário com cada documento de resultado apresentado para cada consulta enviada.
Para cada seleção de usuário de um documento de resultado apresentado para uma consulta, as entradas de log indicam a consulta (Q), o papel (D), o tempo de permanência do usuário (T) no documento, o idioma (L) empregado pelo usuário, e o país (C) onde o usuário provavelmente está localizado (por exemplo, com base no servidor usado para acessar o sistema de IR) e um código de região (R) identificando a área metropolitana do usuário.
As entradas de log também registram informações negativas, como que um resultado de documento é apresentado a um usuário, mas não foi selecionado.
Outras informações como:
- Posições de cliques (ou seja, seleções do usuário na interface do usuário
- Informações sobre a sessão (como existência e tipo de cliques anteriores (atividade da sessão pós-clique))
- R pontuações de resultados clicados
- Pontuações de IR de todos os resultados mostrados antes do clique
- Títulos e snippets são exibidos para o usuário antes do clique
- Cookie do usuário
- Idade do cookie
- Endereço IP (Protocolo de Internet)
- User-agent do navegador
- Em breve
O tempo (T) entre o clique inicial no resultado do documento e o retorno dos usuários à página principal e o clique em outro resultado do documento (ou o envio de uma nova consulta de pesquisa) também é registrado.
É feita uma avaliação sobre o tempo (T) sobre se este tempo indica uma visão mais longa do documento ou uma mais curta, já que argumentos mais extensos geralmente mostram qualidade ou relevância para o resultado clicado. Esta avaliação do tempo (T) pode ser feita em conjunto com várias técnicas de ponderação.
Os componentes mostrados podem ser combinados de várias maneiras e várias configurações de sistema. Os mecanismos de tanque final de pontuação se fundem em um único mecanismo de classificação, como o mecanismo de classificação. O mecanismo modificador de classificação e o mecanismo de classificação também podem ser mesclados. Em geral, um mecanismo de classificação inclui qualquer componente de software que gere uma classificação dos resultados do documento após uma consulta. Além disso, um mecanismo de classificação pode encaixar um sistema cliente também (ou melhor) em um sistema servidor.
Outro exemplo é o sistema de recuperação de informações. O sistema do servidor inclui um mecanismo de indexação e um mecanismo de pontuação/classificação.
Neste sistema, um sistema cliente inclui:
- Uma interface de usuário para apresentar uma classificação
- Um componente de rastreamento
- Registros de seleção de resultados
- Um mecanismo modificador de classificação/classificação.
Por exemplo, o sistema cliente pode incluir a rede corporativa de uma empresa e computadores pessoais, nos quais um plug-in de navegador incorpora o mecanismo modificador de classificação/classificação.
Quando um funcionário da empresa inicia uma pesquisa no sistema do servidor, o mecanismo de pontuação/classificação pode retornar os resultados da pesquisa. Uma classificação inicial ou as pontuações reais de IR para os resultados. O plug-in do navegador reclassifica os resultados com base nas seleções de páginas rastreadas para a base de usuários específica da empresa.
Uma técnica para categorização de consultas
Essa técnica pode ser realizada online (como parte do processamento de consultas) ou offline.
Os primeiros resultados de imagem que respondem à primeira consulta são recebidos. Cada uma das primeiras imagens é associada a um pedido (como uma pontuação de IR) e a um respectivo dado de comportamento do usuário (como dados de clique).
Várias das primeiras imagens são selecionadas onde uma métrica para os respectivos dados de comportamento para cada imagem selecionada satisfaz um limite.
As primeiras imagens selecionadas são associadas a várias anotações com base na análise de conteúdo das primeiras imagens escolhidas. As anotações de imagem podem ser persistidas em anotações de imagem.
As categorias são então associadas à primeira consulta com base nas anotações.
As associações de categorização de consulta podem durar em categorias de consulta.
Os resultados da segunda imagem que respondem a uma segunda consulta que é a mesma ou a primeira consulta são recebidos.
(Se a segunda consulta não for encontrada na categorização da consulta, a segunda consulta poderá ser transformada ou “reescrita” para determinar se um formulário alternativo corresponde a uma consulta na categorização da consulta.)
Neste exemplo, a segunda consulta é igual ou pode ser reescrita como a primeira consulta.
Os resultados da segunda imagem são reordenados com base na categorização da consulta antes de serem associados à primeira consulta.
Pesquisar notícias diretamente na sua caixa de entrada
*Requerido