
Abfragekategorisierung basierend auf Bildergebnissen
Veröffentlicht: 2022-04-27Google wurde kürzlich ein Patent zur Kategorisierung von Suchanfragen basierend auf Bildergebnissen erteilt.
Das Patent sagt uns: „Internet-Suchmaschinen stellen Informationen über im Internet zugängliche Ressourcen (wie Webseiten, Bilder, Textdokumente, Multimedia-Inhalte) bereit, die auf die Suchanfrage eines Benutzers reagieren, indem sie bei der Bildsuche eine Reihe von Bildsuchergebnissen zurückgeben als Antwort auf die Anfrage.“
Ein Suchergebnis enthält beispielsweise einen Uniform Resource Locator (URL) eines Bildes oder eines Dokuments, das das Bild und einen Informationsausschnitt enthält.
Ranking von SERPs mit einer Scoring-Funktion
Die Suchergebnisse können (z. B. in der Reihenfolge) gemäß den von einer Bewertungsfunktion zugewiesenen Bewertungen geordnet werden.
Die Scoring-Funktion ordnet die Suchergebnisse nach verschiedenen Signalen:
- Wo (und wie oft) Abfragetext im Dokumenttext erscheint, der ein Bild umgibt
- Eine Bildunterschrift oder Alternativtext für die Idee
- Wie üblich die Suchbegriffe in den von der Suchmaschine indexierten Suchergebnissen sind.
Im Allgemeinen handelt es sich bei dem in diesem Patent beschriebenen Gegenstand um ein Verfahren, das Folgendes umfasst:
- Erhalten von Bildern aus den ersten Bildergebnissen für eine erste Abfrage, wobei einer Anzahl der erhaltenen Bilder Bewertungen und Benutzerverhaltensdaten zugeordnet sind, die eine Benutzerinteraktion mit den erhaltenen Bildern angeben, wenn die erhaltenen Bilder Suchergebnisse für die Abfrage sind
- Auswählen einer Anzahl der erfassten Bilder, die jeweils entsprechende Verhaltensdaten aufweisen, die einen Schwellenwert erfüllen
- Zuordnen der ausgewählten ersten Bilder zu mehreren Anmerkungen basierend auf einer Analyse des Inhalts der ausgewählten Bilder
Diese können optional die folgenden Merkmale umfassen.
Die erste Abfrage kann basierend auf den Anmerkungen Kategorien zugeordnet werden. Die Abfragekategorisierung und Anmerkungszuordnungen können für die zukünftige Verwendung gespeichert werden. Die zweiten Bildergebnisse, die auf eine zweite Abfrage reagieren, die gleich oder ähnlich der ersten Abfrage ist, können empfangen werden.
Jedes der zweiten Bilder wird mit einer Punktzahl verknüpft, und das zweite Bild kann basierend auf den Kategorien in Bezug auf die erste Abfrage modifiziert werden.
Eine der Abfragekategorisierungen kann angeben, dass die erste Abfrage eine Einzelperson-Abfrage ist, und die Punktzahlen des zweiten Bilds erhöhen, dessen Anmerkungen besagen, dass der Satz von zweiten Bildern ein einzelnes Gesicht enthält.
Eine Abfragekategorisierung kann angeben, dass die erste Abfrage vielfältig ist, und die Punktzahlen der zweiten Bilder erhöhen, deren Anmerkungen besagen, dass der Satz von zweiten Bildern vielfältig ist.
Eine der Kategorien kann angeben, dass die erste Abfrage eine Textabfrage ist, und die Punktzahl des zweiten Bildes erhöhen, dessen Anmerkungen besagen, dass der Satz von zweiten Bildern den Text enthält.
Die erste Abfrage kann einem trainierten Klassifizierer bereitgestellt werden, um eine Abfragekategorisierung in den Kategorien zu bestimmen.
Die Analyse des Inhalts der ausgewählten ersten Bilder kann das Gruppieren der Ergebnisse der ersten Bilder umfassen, um eine Anmerkung in den Anmerkungen zu bestimmen. Benutzerverhaltensdaten können die Häufigkeit sein, mit der Benutzer das Bild in den Suchergebnissen für die erste Abfrage auswählen.
Der in diesem Patent beschriebene Gegenstand kann so implementiert werden, dass die folgenden Vorteile realisiert werden:
Der Bildergebnissatz wird analysiert, um Bildanmerkungen und eine Abfragekategorisierung abzuleiten, und die Benutzerinteraktion mit Bildsuchergebnissen kann verwendet werden, um Typen für Abfragen abzuleiten.
Abfragekategorisierung
Abfragekategorien können wiederum die Relevanz, Qualität und Vielfalt der Bildersuchergebnisse verbessern.
Die Abfragekategorisierung kann auch als Teil der Abfrageverarbeitung oder in einem Offline-Prozess verwendet werden.
Abfragekategorien können verwendet werden, um automatisierte Abfragevorschläge wie „nur Bilder mit Gesichtern anzeigen“ oder „nur Cliparts anzeigen“ bereitzustellen.
Abfragekategorisierung basierend auf Bildergebnissen
Erfinder: Anna Majkowska und Cristian Tapus
Zessionar: GOOGLE LLC
US-Patent: 11.308.149
Gewährt: 19. April 2022
Eingereicht: 3. November 2017
Abstrakt
Verfahren, Systeme und Geräte, einschließlich auf einem Computerspeichermedium codierte Computerprogramme zur Kategorisierung von Abfragen auf der Grundlage von Bildergebnissen.
In einem Aspekt umfasst ein Verfahren das Empfangen von Bildern aus Bildergebnissen als Reaktion auf eine Abfrage, wobei jedes der Fotos mit einer Reihenfolge in den Bildergebnissen und jeweiligen Benutzerverhaltensdaten für das Bild als Suchergebnis für die erste Abfrage und deren Zuordnung verknüpft wird die ersten Bilder mit mehreren Anmerkungen basierend auf einer Analyse des Inhalts der ausgewählten ersten Bilder.
Ein System, das die Abfragekategorisierung verwendet, um die für eine Abfrage zurückgegebene Ergebnismenge zu verbessern
Ein Client, wie etwa ein Webbrowser oder ein anderer Prozess, der auf einem Computergerät ausgeführt wird, sendet eine Eingabeabfrage an eine Suchmaschine, und die Suchmaschine gibt Bildsuchergebnisse an den Client zurück. In manchen Implementierungen umfasst eine Abfrage Text wie etwa Zeichen in einem Zeichensatz (z. B. „rote Tomate“).
Eine Abfrage umfasst Bilder, Töne, Videos oder Kombinationen davon. Andere Abfragetypen sind möglich. Die Suchmaschine sucht nach Ergebnissen basierend auf alternativen Abfrageversionen, die gleich, umfassender oder spezifischer als die Eingabeabfrage sind.
Die Bildsuchergebnisse sind eine geordnete oder geordnete Liste von Dokumenten oder Links zu solchen, die als auf die Eingabeabfrage ansprechend bestimmt werden, wobei die als am relevantesten bestimmten Dokumente den höchsten Rang haben. Eine Kopie ist eine Webseite, ein Bild oder eine andere elektronische Datei.
Bei der Bildersuche bestimmt die Suchmaschine die Relevanz eines Bildes zumindest teilweise auf der Grundlage der folgenden Punkte:
- Inhalt des Bildes
- Der Text, der das Bild umgibt
- Bildbeschreibung
- Alternativer Text für das Bild
Einer Abfrage zugeordnete Kategorien
Beim Erzeugen der Bildsuchergebnisse sendet die Suchmaschine in einigen Implementierungen eine Anfrage nach Kategorien, die der Anfrage zugeordnet sind. Die Suchmaschine kann die zugeordneten Kategorien verwenden, um die Bildsuchergebnisse neu zu ordnen, indem sie den Rang von Bildergebnissen erhöht, von denen festgestellt wurde, dass sie zu den zugehörigen Kategorien gehören.
In einigen Fällen kann es Bildergebnisse verringern, die nicht zu den zugeordneten Kategorien oder zu beiden gehören.
Die Suchmaschine kann auch die Kategorien der Ergebnisse verwenden, um zu bestimmen, wie sie in der endgültigen Ergebnismenge in Kombination mit oder von der Abfragekategorie eingestuft werden sollen.
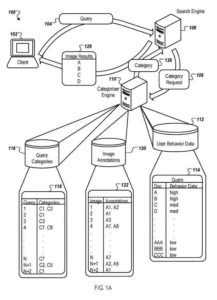
Eine Kategorisierungsmaschine oder ein anderer Prozess verwendet Bildergebnisse, die für die Abfrage abgerufen wurden, und einen Speicher für Benutzerverhaltensdaten, um Kategorien für die Abfrage abzuleiten. Das Repository enthält Daten zum Benutzerverhalten. Der Speicher gibt an, wie oft Populationen von Benutzern ein Bildergebnis für eine gegebene Abfrage ausgewählt haben.
Die Bildauswahl kann auf verschiedene Weise erreicht werden, einschließlich der Verwendung der Tastatur, einer Computermaus oder einer Fingergeste, eines Sprachbefehls oder anderer Verfahren. Zu den Daten zum Nutzerverhalten gehören „Klickdaten“.
Klickdaten zeigen an, wie lange ein Benutzer ein Bildergebnis betrachtet oder „verweilt“.
Klickdaten geben an, wie lange ein Benutzer ein Bildergebnis betrachtet oder „verweilt“, nachdem er es in einer Ergebnisliste für die Abfrage ausgewählt hat. Beispielsweise kann ein langes Verweilen auf einem Bild (z. B. länger als 1 Minute), das als „langer Klick“ bezeichnet wird, angeben, dass ein Benutzer das Bild für die Suchanfrage des Benutzers relevant gefunden hat.
Ein kurzer Betrachtungszeitraum eines Bildes (z. B. weniger als 30 Sekunden), der als „kurzer Klick“ bezeichnet wird, kann als fehlende Bildrelevanz interpretiert werden. Andere Arten von Benutzerverhaltensdaten sind möglich.
Zur Veranschaulichung können Benutzerverhaltensdaten durch einen Prozess generiert werden, der einen Datensatz für Ergebnisdokumente erstellt, die von Benutzern als Antwort auf eine bestimmte Abfrage ausgewählt werden. Jedes Formular kann als Tupel dargestellt werden: <Dokument, Abfrage, Daten>), das Folgendes enthält:
- Eine von Benutzern eingereichte Frage
- Eine Abfragereferenz, die die Abfrage angibt
- Ein Dokument verweist auf ein Papier, das von Benutzern als Antwort auf die Anfrage ausgewählt wurde
- Aggregation von Klickdaten (z. B. Anzahl der einzelnen Klicktypen) für alle Benutzer oder eine Teilmenge aller Benutzer, die den Dokumentverweis als Antwort auf die Abfrage ausgewählt haben.
Erweiterungen dieses tupelbasierten Ansatzes für Benutzerverhaltensdaten sind möglich. Beispielsweise können die Nutzerverhaltensdaten um standortspezifische (wie Land oder Staat) oder sprachspezifische Kennungen erweitert werden.
Mit solchen Identifikatoren würde ein landesspezifisches Tupel aus dem Land bestehen, aus dem die Benutzeranfrage stammt, und ein sprachspezifisches Tupel würde aus der Sprache der Benutzeranfrage bestehen.
Zur Vereinfachung der Darstellung werden die Benutzerverhaltensdaten, die den Dokumenten A-CCC für die Abfrage zugeordnet sind, in der Tabelle entweder als „hohe“, „mittlere“ oder „niedrige“ Menge günstiger Benutzerverhaltensdaten (z. B. Benutzerverhalten) dargestellt Daten, die die Relevanz zwischen dem Dokument und der Anfrage angeben).
Benutzerverhaltensdaten für ein Dokument
Günstige Benutzerverhaltensdaten für ein Dokument können angeben, dass das Papier von Benutzern ausgewählt wird, wenn es in den Ergebnissen für die Abfrage angezeigt wird, oder wenn ein Benutzer das Dokument anzeigt, nachdem er es aus den Ergebnissen für die Abfrage ausgewählt hat, sehen die Benutzer das Dokument für einen längeren Zeitraum (z. B. wenn der Benutzer das Dokument für die Frage relevant findet).
Die Kategorisierungs-Engine arbeitet mit der Suchmaschine zusammen und verwendet zurückgegebene Ergebnisse und Benutzerverhaltensdaten, um Abfragekategorien zu bestimmen und die Ergebnisse dann neu zu ordnen, bevor sie an den Benutzer zurückgegeben werden.
Im Allgemeinen analysiert die Kategorisierungsmaschine für die Abfrage (wie etwa eine Abfrage oder eine alternative Form der Abfrage), die in der Abfragekategorieanforderung spezifiziert ist, Bildergebnisse für die Abfrage, um zu bestimmen, ob die Abfrage zu Kategorien gehört. Bildergebnisse, die in einigen Implementierungen analysiert wurden, wurden von Benutzern als Suchergebnis für die Abfrage insgesamt so oft ausgewählt, dass sie einen Schwellenwert überschritten haben (z. B. mindestens zehnmal festgelegt).
Die Kategorisierungs-Engine analysiert alle Bildergebnisse, die von der Suchmaschine für eine bestimmte Anfrage abgerufen wurden. in anderen Implementierungen
Die Kategorisierungs-Engine analysiert Bildergebnisse für die Abfrage, wenn eine Metrik (z. B. die Gesamtzahl der Auswahlen oder ein anderes Maß) für die Klickdaten über einem Schwellenwert liegt.
Die Bildergebnisse können während des Scoring-Prozesses online mithilfe von Computer-Vision-Techniken auf verschiedene Weise analysiert werden, entweder offline oder online. Bilder werden mit Informationen kommentiert, die aus ihrem visuellen Inhalt extrahiert werden.
Bildanmerkungen
Beispielsweise können Bildanmerkungen im Anmerkungsspeicher gespeichert werden. Jedes analysierte Bild (z. B. Bild 1, Bild 2 usw.) wird mit Anmerkungen (z. B. A1, A2 usw.) in einer Foto-zu-Anmerkungs-Zuordnung verknüpft.
Die Anmerkungen können Folgendes umfassen:
- Die Anzahl der Gesichter im Bild
- Die Größe jedes Gesichts
- Die dominierenden Farben des Bildes
- Ob ein Bild Text oder eine Grafik enthält
- Ob ein Bild ein Screenshot ist
Zusätzlich kann jedes Bild mit einem Fingerabdruck kommentiert werden, der dann feststellen kann, ob zwei Bilder identisch oder identisch sind.
Als Nächstes analysiert die Kategorisierungs-Engine Bildergebnisse für eine bestimmte Abfrage und ihre Anmerkungen, um Abfragekategorien zu bestimmen. Zuordnungen von Abfragekategorien (z. B. C1, C2 usw.) für eine gegebene Abfrage (z. B. Abfrage 1, Abfrage 2 usw.) können auf viele Arten bestimmt werden, z. B. unter Verwendung einer einfachen Heuristik oder unter Verwendung eines automatisierten Klassifikators.
Ein einfacher Abfragekategorisierer basierend auf einer Heuristik
Als Beispiel kann ein einfacher, auf einer Heuristik basierender Abfragekategorisierer verwendet werden, um die gewünschte dominante Farbe für die Abfrage zu bestimmen (und ob es eine gibt).
Die Heuristik kann beispielsweise lauten, dass, wenn von den 20 am häufigsten angeklickten Bildern für die Suchanfrage mindestens 70 % eine dominante Farbe Rot aufweisen, die Suchanfrage als „rote Suchanfrage“ kategorisiert werden kann. Für solche Anfragen kann die Suchmaschine die abgerufenen Ergebnisse neu ordnen, um den Rang aller Bilder zu erhöhen, die mit Rot als dominanter Farbe kommentiert sind.
Die gleiche Kategorisierung kann mit allen anderen Standardfarben verwendet werden. Ein Vorteil dieses Ansatzes zur Überanalyse des Abfragetextes besteht darin, dass er für alle Sprachen funktioniert, ohne dass eine Übersetzung erforderlich ist (z. B. weil Bilder mit dominanter roter Farbe für die Frage „roter Apfel“ in jeder Sprache gefördert werden). Es ist robuster (z. B. erhöht es nicht den Rang von roten Bildern für die Suchanfrage „Rotes Meer“).
Ein Beispiel für eine Kategorisierungs-Engine
Die Kategorisierungsmaschine kann in einem Online-Modus oder Offline-Modus arbeiten, in dem Zuordnungen von Abfragekategorien im Voraus (z. B. in der Tabelle) zur Verwendung durch die Suchmaschine während der Abfrageverarbeitung gespeichert werden.
Die Engine empfängt Abfragebildergebnisse für eine bestimmte Abfrage und stellt die Bildergebnisse Bildannotatoren bereit. Jeder Bildkommentator analysiert Bildergebnisse und extrahiert Informationen über den visuellen Inhalt des Bildes, die als Bildkommentar (z. B. Bildkommentare) für die Idee gespeichert werden.
Ein Annotator für Gesichtsbilder
Zur Veranschaulichung ein Gesichtsbildannotator:
- Legt fest, wie viele Gesichter sich in einem Bild befinden und wie groß jedes Gesicht ist
- Ein Fingerabdruck-Bildannotator extrahiert visuelle Bildmerkmale in komprimierter Form (Fingerabdruck), die dann mit dem Fingerabdruck eines anderen Bildes verglichen werden können, um festzustellen, ob die beiden Bilder ähnlich sind
- Ein Screenshot-Annotator bestimmt, ob es sich bei einem Bild um einen Screenshot handelt
- Ein Text-Bild-Annotator bestimmt, ob ein Bild Text enthält
- Eine Grafik-/Diagrammbildabfrage bestimmt, ob ein Bild Grafiken oder Diagramme (z. B. Balkendiagramme) enthält.
- Ein Annotator für dominante Farben bestimmt, ob ein Bild eine dominante Farbe enthält
Andere Bildannotatoren können ebenfalls verwendet werden. Beispielsweise werden mehrere Bildannotatoren in einem Artikel mit dem Titel „Rapid Object Detection Using a Boosted Cascade of Simple Features“ von Viola, P.; Jones, M., Mitsubishi Electric Research Laboratories, TR2004-043 (Mai 2004).
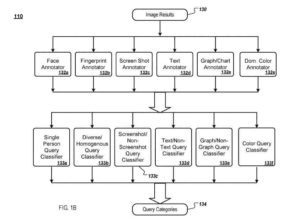
Als Nächstes analysiert die Kategorisierungsmaschine Bildergebnisse für eine gegebene Abfrage und ihre Anmerkungen, um Abfragekategorien (z. B. Abfragekategorien) zu bestimmen. Abfragekategorien werden mithilfe eines Klassifikators bestimmt, und ein Abfrageklassifikator kann mithilfe eines maschinellen Lernsystems realisiert werden.
Verwendung von Adaptive Boosting
Zur Veranschaulichung ist AdaBoost, kurz für Adaptive Boosting, ein maschinelles Lernsystem, das mit anderen Lernalgorithmen verwendet werden kann, um deren Leistung zu verbessern. AdaBoost wird verwendet, um eine Abfragekategorisierung zu generieren. (Weitere Lernalgorithmen sind möglich)
AdaBoost ruft in einer Reihe von Runden einen „schwachen“ Bildannotator auf. Zur Veranschaulichung kann der Ein-Personen-Anfrageklassifizierer basierend auf einem Lernmaschinenalgorithmus trainiert werden, um zu bestimmen, ob eine Anfrage Bilder einer einzelnen Person erfordert.
Zur Veranschaulichung kann ein solcher Abfrageklassifizierer mit Datensätzen trainiert werden, die eine Abfrage, einen Satz von Merkmalsvektoren, die Ergebnisbilder für die Frage mit null oder mehr Gesichtern darstellen, und die korrekte Kategorisierung für die Abfrage (d. h. Gesichter oder nicht) umfassen. . Für jeden Aufruf aktualisiert der Abfrageklassifizierer eine Gewichtungsverteilung, die die Wichtigkeit von Beispielen im Trainingsdatensatz für die Klassifizierung angibt.
In jeder Runde werden die Gewichtungen jedes klassifizierten Trainingsbeispiels erhöht (oder die Konsequenzen jedes klassifizierten Trainingsbeispiels werden verringert), sodass sich die neue Abfragekategorisierung mehr auf diese Beispiele konzentriert. Die resultierende trainierte Abfragekategorisierung kann als Eingabe eine Abfrage nehmen und eine Wahrscheinlichkeit ausgeben, dass die Abfrage Bilder aufruft, die einzelne Personen enthalten.
Ein vielfältiger/homogener Abfrageklassifikator nimmt als Eingabe eine Abfrage und gibt eine Wahrscheinlichkeit aus, dass die Abfrage für verschiedene Bilder gilt. Der Klassifikator verwendet einen Clustering-Algorithmus, um Bildergebnisse gemäß ihrer Fingerabdrücke basierend auf einem Abstandsmaß voneinander zu gruppieren. Jedes Bild wird mit einer Cluster-ID verknüpft.
Die Bild-Cluster-ID wird verwendet, um die Anzahl der Cluster, die Größe der Gruppen und die Ähnlichkeit zwischen Clustern zu bestimmen, die durch Bilder in der Ergebnismenge gebildet werden. Diese Informationen werden beispielsweise verwendet, um eine Wahrscheinlichkeit zuzuordnen, ob die Abfrage spezifisch ist (oder Duplikate einlädt) oder nicht,
Verknüpfung von Abfragen mit kanonischen Bedeutungen und Darstellungen
Die Abfragekategorisierung kann auch verwendet werden, um Abfragen mit kanonischen Bedeutungen und Darstellungen zu verknüpfen. Wenn es beispielsweise einen einzelnen großen Cluster oder mehrere große Cluster gibt, ist die Wahrscheinlichkeit hoch, dass die Frage mit doppelten Bildergebnissen in Verbindung gebracht wird. Wenn viele kleinere Cluster vorhanden sind, ist die Wahrscheinlichkeit gering, dass die Abfrage denselben Bildergebnissen zugeordnet wird.

Duplikate von Bildern sind normalerweise nicht sehr nützlich, da sie keine weiteren Informationen liefern und daher als Abfrageergebnisse herabgestuft werden sollten. Aber es gibt Ausnahmen. Wenn beispielsweise viele Duplikate in den anfänglichen Ergebnissen vorhanden sind (wenige, große Cluster), ist die Abfrage besonders und Duplikate sollten nicht herabgestuft werden.
Eine Screenshot-/Nicht-Screenshot-Abfragekategorisierung nimmt als Eingabe eine Abfrage und gibt eine Wahrscheinlichkeit aus, dass die Abfrage Bilder aufruft, die Screenshots sind. Ein Text/Nicht-Text-Abfrageklassifizierer akzeptiert eine Abfrage als Eingabe und gibt eine Chance aus, dass die Abfrage Bilder aufruft, die Text enthalten.
Eine Graph/Nicht-Graph-Abfragekategorisierung nimmt eine Eingabe einer Abfrage und gibt eine Wahrscheinlichkeit aus, dass die Abfrage Bilder aufruft, die einen Graphen oder ein Diagramm enthalten. Ein Farbabfrageklassifizierer 133f nimmt eine Informationsabfrage und gibt eine Wahrscheinlichkeit aus, dass die Abfrage Aufnahmen aufruft, die von einer einzelnen Farbe dominiert werden. Andere Abfrageklassifikatoren sind möglich.
Verbesserung der Relevanz von Bildergebnissen basierend auf der Abfragekategorisierung
Ein Suchender kann über einen Client oder ein anderes Gerät mit dem System interagieren. Beispielsweise kann die Client-Vorrichtung ein Computerterminal innerhalb eines lokalen Netzwerks (LAN) oder eines ausgedehnten Netzwerks (WAN) sein. Die Client-Vorrichtung kann eine mobile Vorrichtung (z. B. ein Mobiltelefon, ein mobiler Computer, ein persönlicher Desktop-Assistent usw.) sein, die in der Lage ist, über ein LAN, ein WAN oder ein anderes Netzwerk (z. B. ein Mobilfunknetz) zu kommunizieren.
Das Clientgerät kann einen Direktzugriffsspeicher (RAM) (oder einen anderen Speicher und ein Speichergerät) und einen Prozessor umfassen.
Der Prozessor wird strukturiert, um Anweisungen und Daten innerhalb des Systems zu verarbeiten. Der Prozessor ist ein Singlethread- oder Multithread-Mikroprozessor mit Verarbeitungskernen. Der Prozessor empfängt strukturierte Anweisungen, die in dem RAM (oder einem anderen Speicher und einer Speichervorrichtung, die in der Client-Vorrichtung enthalten sind) gespeichert sind, um grafische Informationen für eine Benutzerschnittstelle wiederzugeben.
Ein Suchender kann sich innerhalb eines Serversystems mit der Suchmaschine verbinden, um eine Eingabeabfrage zu übermitteln. Die Suchmaschine ist eine Bildsuchmaschine oder eine generische Suchmaschine, die Bilder und andere Arten von Inhalten wie Dokumente (z. B. HTML-Seiten) abrufen kann.
Wenn der Benutzer die Eingabeabfrage über ein Eingabegerät übermittelt, das an ein Clientgerät angeschlossen ist, wird eine clientseitige Frage an ein Netzwerk gesendet und als serverseitige Abfrage an das Serversystem weitergeleitet. Das Serversystem können Servergeräte an Standorten sein. Eine Servervorrichtung umfasst eine Speichervorrichtung, die aus der darin geladenen Suchmaschine besteht.
Ein Prozessor wird strukturiert, um Anweisungen innerhalb des Geräts zu verarbeiten. Diese Anweisungen können Komponenten der Suchmaschine installieren. Der Prozessor kann Single-Threaded oder Multi-Threaded sein und viele Verarbeitungskerne umfassen. Der Prozessor kann im Speicher gespeicherte Anweisungen in Bezug auf die Suchmaschine verarbeiten und Informationen über das Netzwerk an das Client-Gerät senden, um eine grafische Darstellung in der Benutzeroberfläche des Client-Geräts zu erstellen (z. B. Suchergebnisse auf einer Webseite, die in einem Web angezeigt werden). Browser).
Die serverseitige Abfrage wird von der Suchmaschine empfangen. Die Suchmaschine verwendet die Informationen in der Eingabeabfrage (z. B. Abfragebegriffe), um relevante Dokumente zu finden. Die Suchmaschine kann eine Indizierungsmaschine umfassen, die einen Korpus (z. B. Webseiten im Internet) durchsucht, um die in diesem Korpus gefundenen Dokumente zu indizieren. Die Indexinformationen für die Korpusdokumente können in einer Indexdatenbank gespeichert werden.
Auf diese Indexdatenbank kann zugegriffen werden, um Dokumente zu identifizieren, die sich auf den Benutzer beziehen. Beachten Sie, dass eine elektronische Kopie (die als Dokument bezeichnet wird) keiner Datei entspricht. Ein Datensatz kann in einem Teil einer Akte gespeichert werden, der andere Dokumente enthält, in einer einzelnen Akte, die dem betreffenden Dokument gewidmet ist, oder in vielen koordinierten Akten. Darüber hinaus kann eine Kopie in einem Speicher gespeichert werden, ohne in einer Datei gespeichert zu werden.
Die Suchmaschine kann eine Ranking-Engine umfassen, um die Dokumente in Bezug auf die Eingabeabfrage zu ordnen. Das Ranking der Dokumente kann unter Verwendung traditioneller Techniken durchgeführt werden, um bei einer gegebenen Abfrage einen Information Retrieval (IR)-Score für indizierte Datensätze zu bestimmen.
Jedes geeignete Verfahren kann die Relevanz eines bestimmten Dokuments für einen bestimmten Suchbegriff oder für andere bereitgestellte Informationen bestimmen. Beispielsweise kann die allgemeine Ebene von Backlinks zu einem Dokument, das Übereinstimmungen für einen Suchbegriff enthält, verwendet werden, um auf die Relevanz eines Dokuments zu schließen.
Insbesondere wenn ein Dokument mit vielen anderen relevanten Dokumenten (z. B. Dokumenten, die Übereinstimmungen mit den Suchbegriffen enthalten) verknüpft wird (z. B. das Ziel eines Hyperlinks ist), kann gefolgert werden, dass das Zieldokument besonders relevant ist. Diese Schlussfolgerung kann gezogen werden, weil die Autoren der Pointing Papers vermutlich zum größten Teil auf andere Dokumente verweisen, die für ihr Publikum relevant sind.
Die Verweisdokumente zielen auf Links aus anderen relevanten Dokumenten ab, die als relevanter angesehen werden können. Das erste Dokument ist besonders geeignet, da es auf anwendbare (oder sogar höchst relevante) Dokumente abzielt.
Eine solche Technik kann die Relevanz eines Dokuments oder eine von vielen Determinanten bestimmen. Es können auch geeignete Methoden ergriffen werden, um Versuche zu identifizieren und zu unterbinden, betrügerische Stimmen abzugeben, um die Relevanz einer Seite zu erhöhen.
Um solche herkömmlichen Dokumenten-Ranking-Techniken weiter zu verbessern, kann die Ranking-Engine mehr Signale von einer Rang-Modifikator-Engine empfangen, um bei der Bestimmung einer angemessenen Rangfolge für die Dokumente zu helfen.
In Verbindung mit den oben beschriebenen Bildannotatoren und der Abfragekategorisierung stellt die Rangmodifizierer-Engine Relevanzmaße für die Papiere bereit. Die Ranking-Engine kann verwendet werden, um das Ranking der Suchergebnisse zu verbessern, das dem Benutzer bereitgestellt wird.
Die Rangmodifizierer-Engine kann Operationen durchführen, um die Relevanzmaße zu erzeugen.
Ob die Punktzahl eines Bildergebnisses steigt oder sinkt, hängt davon ab, ob der visuelle Inhalt des Bildes (wie in Bildanmerkungen dargestellt) mit der Suchanfragekategorisierung übereinstimmt, jede Bildkategorie wird berücksichtigt.
Wenn die Kategorisierung der Suchanfrage beispielsweise „einzelne Person“ lautet, wird die Punktzahl eines Bildergebnisses, das sowohl als „Screenshot“ als auch als „einzelnes Gesicht“ klassifiziert wird, zunächst aufgrund der Kategorie „Screenshot“ verringert. Aufgrund der Kategorie „Single Face“ kann es dann seine Punktzahl erhöhen.
Die Suchmaschine kann die endgültige, geordnete Ergebnisliste innerhalb der serverseitigen Suchergebnisse durch das Netzwerk weiterleiten. Beim Verlassen des Netzwerks können clientseitige Suchergebnisse von der Clientvorrichtung empfangen werden, wo die Ergebnisse im RAM gespeichert und vom Prozessor verwendet werden können, um die Ergebnisse auf einer Ausgabevorrichtung für den Benutzer anzuzeigen.
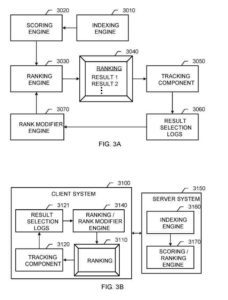
Ein Informationsabrufsystem
Zu diesen Komponenten gehören:
- Indizierungs-Engine
- Scoring-Engine
- Ranking-Engine
- Rangmodifikator-Engine
Die Indizierungsmaschine funktioniert wie oben für die Indizierungsmaschine beschrieben. Die Scoring-Engine generiert Bewertungen für Dokumentergebnisse basierend auf vielen Funktionen, einschließlich inhaltsbasierter Funktionen, die eine Abfrage mit Dokumentergebnissen verknüpfen, und abfrageunabhängigen Teilen, die im Allgemeinen die Qualität der Dokumentergebnisse angeben.
Inhaltsbasierte Funktionen für Bilder umfassen Aspekte des Dokuments, das das Bild enthält, wie z. B. Abfrageübereinstimmungen mit dem Titel des Dokuments oder der Bildunterschrift.
Zu den abfrageunabhängigen Merkmalen gehören beispielsweise Aspekte der Dokumentenquerverweise des Papiers oder der Domänen- oder Bildabmessungen.
Darüber hinaus können die speziellen Funktionen, die von der Bewertungsmaschine verwendet werden, abgestimmt werden, um die verschiedenen Merkmalsbeiträge an die endgültige IR-Bewertung anzupassen, indem automatische oder halbautomatische Prozesse verwendet werden.
Die Ranking-Engine ordnet Dokumentergebnisse zur Anzeige für einen Benutzer basierend auf IR-Scores, die von der Bewertungsmaschine empfangen werden, und Signalen von der Ranking-Modifikator-Engine.
Die Rangmodifizierermaschine stellt Relevanzmaße für die Dokumente bereit, die die Rangordnungsmaschine verwenden kann, um die Rangfolge der Suchergebnisse zu verbessern, die dem Benutzer bereitgestellt wird. Eine Tracking-Komponente zeichnet Informationen zum Benutzerverhalten auf, wie z. B. individuelle Benutzerauswahlen der in der Bestellung präsentierten Ergebnisse.
Die Tracking-Komponente erhält eingebetteten JavaScript-Code, der in ein Webseiten-Ranking eingefügt wird, das Benutzerauswahlen einzelner Dokumentergebnisse identifiziert und identifiziert, wann der Benutzer zur Ergebnisseite zurückkehrt, wodurch die Zeit angegeben wird, die der Benutzer damit verbracht hat, das ausgewählte Dokumentergebnis anzuzeigen.
Die Tracking-Komponente ist ein Proxy-System, durch das Benutzerauswahlen der Dokumentenergebnisse geleitet werden. Die Tracking-Komponente kann auch vorinstallierte Software für den Client enthalten (wie etwa ein Symbolleisten-Plug-In für das Betriebssystem des Clients).
Andere Implementierungen sind ebenfalls möglich, z. B. eine, die eine Funktion eines Webbrowsers verwendet, die es ermöglicht, ein Tag/eine Anweisung in eine Seite einzufügen, die den Browser auffordert, sich mit Nachrichten über Links, auf die der Benutzer geklickt hat, wieder mit dem Server zu verbinden.
Die aufgezeichneten Informationen werden in Ergebnisauswahlprotokollen gespeichert. Die aufgezeichneten Informationen enthalten Protokolleinträge, die die Benutzerinteraktion mit jedem Ergebnisdokument angeben, das für jede übermittelte Abfrage präsentiert wird.
Die Protokolleinträge geben für jede Benutzerauswahl eines für eine Abfrage präsentierten Ergebnisdokuments die Abfrage (Q), das Papier (D), die Verweildauer des Benutzers (T) auf dem Dokument, die vom Benutzer verwendete Sprache (L), und das Land (C), in dem sich der Benutzer wahrscheinlich befindet (z. B. basierend auf dem Server, der verwendet wird, um auf das IR-System zuzugreifen), und einen Regionalcode (R), der den Ballungsraum des Benutzers identifiziert.
Die Protokolleinträge zeichnen auch negative Informationen auf, z. B. dass ein Dokumentergebnis einem Benutzer angezeigt wird, aber nicht ausgewählt wurde.
Weitere Informationen wie:
- Positionen von Klicks (d. h. Benutzerauswahlen in der Benutzeroberfläche
- Informationen über die Sitzung (z. B. Vorhandensein und Art früherer Klicks (Post-Click-Sitzungsaktivität))
- R-Scores der angeklickten Ergebnisse
- IR-Scores aller Ergebnisse, die vor dem Klicken angezeigt werden
- Titles und Snippets werden dem User vor dem Klick angezeigt
- Cookie des Benutzers
- Cookie-Zeitalter
- IP (Internet Protocol)-Adresse
- User-Agent des Browsers
- Bald
Die Zeit (T) zwischen dem ersten Durchklicken zum Dokumentergebnis und dem Zurückkehren des Benutzers zur Hauptseite und dem Klicken auf ein anderes Dokumentergebnis (oder dem Absenden einer neuen Suchanfrage) wird ebenfalls aufgezeichnet.
Über die Zeit (T) wird abgeschätzt, ob diese Zeit eine längere Betrachtung des Dokuments oder eine kürzere anzeigt, da längere Argumente in der Regel Qualität oder Relevanz für das durchgeklickte Ergebnis zeigen. Diese Zeitbewertung (T) kann in Verbindung mit verschiedenen Gewichtungstechniken vorgenommen werden.
Die gezeigten Komponenten können auf verschiedene Arten und zu mehreren Systemkonfigurationen kombiniert werden. Die Scoring-End-Tanking-Engines verschmelzen zu einer einzigen Ranking-Engine, beispielsweise der Ranking-Engine. Die Rangmodifikator-Engine und die Ranking-Engine können auch zusammengeführt werden. Im Allgemeinen umfasst eine Ranking-Engine jede Softwarekomponente, die nach einer Abfrage ein Ranking von Dokumentergebnissen generiert. Darüber hinaus kann eine Ranking-Engine ein Client-System auch (oder eher als) in ein Server-System integrieren.
Ein weiteres Beispiel ist das Informationsabrufsystem. Das Serversystem umfasst eine Indizierungsmaschine und eine Bewertungs-/Einstufungsmaschine.
In diesem System umfasst ein Client-System:
- Eine Benutzeroberfläche zur Darstellung eines Rankings
- Eine Tracking-Komponente
- Ergebnisauswahlprotokolle
- Eine Ranking-/Rank-Modifier-Engine.
Zum Beispiel kann das Client-System das Unternehmensnetzwerk und Personalcomputer einer Firma umfassen, in denen ein Browser-Plug-in die Ranking-/Rank-Modifikator-Engine enthält.
Wenn ein Mitarbeiter im Unternehmen eine Suche auf dem Serversystem initiiert, kann die Bewertungs-/Ranking-Engine die Suchergebnisse zurückgeben. Ein anfängliches Ranking oder die tatsächlichen IR-Scores für die Ergebnisse. Das Browser-Plug-in ordnet dann die Ergebnisse basierend auf der verfolgten Seitenauswahl für die unternehmensspezifische Benutzerbasis neu.
Eine Technik zur Abfragekategorisierung
Diese Technik kann online (als Teil der Abfrageverarbeitung) oder offline durchgeführt werden.
Erste Bildergebnisse, die auf die erste Abfrage reagieren, werden empfangen. Jedes der ersten Bilder wird mit einer Bestellung (z. B. einem IR-Score) und entsprechenden Benutzerverhaltensdaten (z. B. Klickdaten) verknüpft.
Eine Anzahl der ersten Bilder wird ausgewählt, wenn eine Metrik für die jeweiligen Verhaltensdaten für jedes ausgewählte Bild einen Schwellenwert erfüllt.
Die ausgewählten ersten Bilder werden basierend auf der Inhaltsanalyse der ausgewählten ersten Bilder mit mehreren Anmerkungen verknüpft. Die Bildanmerkungen können in Bildanmerkungen gespeichert werden.
Kategorien werden dann basierend auf den Anmerkungen der ersten Abfrage zugeordnet.
Die Abfragekategorisierungszuordnungen können in Abfragekategorien bestehen bleiben.
Dann werden zweite Bildergebnisse empfangen, die auf eine zweite Abfrage reagieren, die dieselbe oder die erste Abfrage ist.
(Wenn die zweite Abfrage nicht in der Abfragekategorisierung gefunden wird, kann die zweite Abfrage transformiert oder „umgeschrieben“ werden, um zu bestimmen, ob eine alternative Form mit einer Abfrage in der Abfragekategorisierung übereinstimmt.)
In diesem Beispiel ist die zweite Abfrage die gleiche wie die erste Abfrage oder kann als solche umgeschrieben werden.
Die zweiten Bildergebnisse werden basierend auf der Abfragekategorisierung neu geordnet, bevor sie der ersten Abfrage zugeordnet werden.
Suchen Sie Nachrichten direkt in Ihren Posteingang
*Erforderlich