
Kategoryzacja zapytań na podstawie wyników obrazu
Opublikowany: 2022-04-27Google otrzymał niedawno patent na kategoryzację zapytań na podstawie wyników obrazu.
Patent mówi nam, że: „wyszukiwarki internetowe dostarczają informacji o zasobach dostępnych w Internecie (takich jak strony internetowe, obrazy, dokumenty tekstowe, treści multimedialne) reagując na zapytanie użytkownika, zwracając podczas wyszukiwania obrazami zestaw wyników wyszukiwania obrazów w odpowiedzi na zapytanie.”
Wynik wyszukiwania obejmuje na przykład adres URL (Uniform Resource Locator) obrazu lub dokumentu zawierającego obraz i fragment informacji.
Ranking SERP za pomocą funkcji punktacji
Wyniki wyszukiwania mogą być uszeregowane (np. w kolejności) zgodnie z punktacją przypisaną przez funkcję punktacji.
Funkcja scoringu klasyfikuje wyniki wyszukiwania według różnych sygnałów:
- Gdzie (i jak często) tekst zapytania pojawia się w tekście dokumentu otaczającym obraz
- Podpis pod zdjęciem lub alternatywny tekst pomysłu
- Poziom standardu wyszukiwanych haseł w wynikach wyszukiwania indeksowanych przez wyszukiwarkę.
Ogólnie rzecz biorąc, temat opisany w tym patencie dotyczy metody, która obejmuje:
- Uzyskiwanie obrazów z pierwszego obrazu wyników dla pierwszego zapytania, gdzie liczba uzyskanych obrazów powiązanych z wynikami i danymi o zachowaniu użytkownika, które określają interakcję użytkownika z uzyskanymi obrazami, gdy uzyskane obrazy są wynikami wyszukiwania dla zapytania
- Wybranie liczby uzyskanych obrazów, z których każdy ma odpowiednie dane dotyczące zachowania, które spełniają próg
- Powiązanie wybranych pierwszych obrazów z kilkoma adnotacjami na podstawie analizy zawartości wybranych obrazów
Mogą one opcjonalnie obejmować następujące funkcje.
Pierwsze zapytanie można powiązać z kategoriami na podstawie adnotacji. Kategoryzacja zapytań i powiązania adnotacji mogą być przechowywane do wykorzystania w przyszłości. Drugi obraz odpowiada na drugie zapytanie, które jest takie samo lub podobne do pierwszego zapytania, które może zostać odebrane.
Każdy z drugich obrazów zostaje powiązany z wynikiem, a drugi obraz może zostać zmodyfikowany na podstawie kategorii związanych z pierwszym zapytaniem.
Jedna z kategoryzacji zapytań może stwierdzać, że pierwsze zapytanie jest zapytaniem jednoosobowym i zwiększa wyniki drugiego obrazu, którego adnotacje mówią, że zestaw drugich obrazów zawiera pojedynczą twarz.
Jedna kategoryzacja zapytań może stwierdzić, że pierwsze zapytanie jest zróżnicowane i zwiększyć wyniki drugich obrazów, których adnotacje mówią, że zbiór drugich obrazów jest zróżnicowany.
Jedna z kategorii może określać, że pierwsze zapytanie jest zapytaniem tekstowym i zwiększać wyniki drugiego obrazu, którego adnotacje mówią, że zbiór drugich obrazów zawiera tekst.
Pierwsze zapytanie może zostać dostarczone do wyszkolonego klasyfikatora w celu określenia kategoryzacji zapytań w kategoriach.
Analiza zawartości wybranych pierwszych obrazów może obejmować grupowanie wyników pierwszego obrazu w celu określenia adnotacji w adnotacjach. Dane o zachowaniu użytkowników mogą oznaczać, ile razy użytkownicy wybrali obraz w wynikach wyszukiwania dla pierwszego zapytania.
Tematyka opisana w tym patencie może zostać wdrożona, dzięki czemu można osiągnąć następujące korzyści:
Zestaw wyników obrazów jest analizowany w celu uzyskania adnotacji obrazów i kategoryzacji zapytań, a interakcja użytkownika z wynikami wyszukiwania obrazów może zostać przyzwyczajona do wyprowadzania typów zapytań.
Kategoryzacja zapytań
Kategorie zapytań mogą z kolei poprawić trafność, jakość i różnorodność wyników wyszukiwania grafiki.
Kategoryzacja zapytań może być również stosowana jako część przetwarzania zapytań lub w procesie offline.
Kategorie zapytań mogą być wykorzystywane do dostarczania automatycznych sugestii dotyczących zapytań, takich jak „pokaż tylko obrazy z twarzami” lub „pokaż tylko obiekty clipart”.
Kategoryzacja zapytań na podstawie wyników obrazu
Wynalazcy: Anna Majkowska i Cristian Tapus
Przypisany: GOOGLE LLC
Patent USA: 11,308,149
Przyznano: 19 kwietnia 2022
Złożono: 3 listopada 2017 r.
Abstrakcyjny
Metody, systemy i urządzenia, w tym programy komputerowe zakodowane na komputerowym nośniku pamięci, do kategoryzacji zapytań na podstawie wyników obrazów.
W jednym aspekcie metoda obejmuje odbieranie obrazów z wyników obrazu w odpowiedzi na zapytanie, przy czym każde ze zdjęć jest kojarzone z zamówieniem w wynikach obrazu i odpowiednimi danymi dotyczącymi zachowania użytkownika dla obrazu jako wyniku wyszukiwania dla pierwszego zapytania i kojarzenia pierwsze obrazy z wieloma adnotacjami na podstawie analizy zawartości wybranych pierwszych obrazów.
System, który wykorzystuje kategoryzację zapytań, aby poprawić zestaw wyników zwracanych dla zapytania
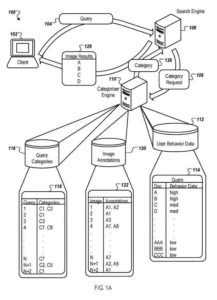
Klient, taki jak przeglądarka internetowa lub inny proces wykonywany na urządzeniu komputerowym, przesyła zapytanie wejściowe do wyszukiwarki, a wyszukiwarka zwraca wyniki wyszukiwania obrazów do klienta. W niektórych implementacjach zapytanie zawiera tekst, taki jak znaki w zestawie znaków (np. „czerwony pomidor”).
Zapytanie zawiera obrazy, dźwięki, filmy lub ich kombinacje. Możliwe są inne typy zapytań. Wyszukiwarka będzie wyszukiwać wyniki na podstawie alternatywnych wersji zapytania równych, szerszych lub bardziej szczegółowych niż zapytanie wejściowe.
Wyniki wyszukiwania obrazów to uporządkowana lub uszeregowana lista dokumentów lub łączy do takich, które mają odpowiadać na zapytanie wejściowe, przy czym dokumenty uznane za najtrafniejsze mają najwyższą rangę. Kopia to strona internetowa, obraz lub inny plik elektroniczny.
W przypadku wyszukiwania grafiki, wyszukiwarka określa trafność obrazu na podstawie, przynajmniej częściowo, następujących danych:
- Zawartość obrazu
- Tekst otaczający obraz
- Tytuł Zdjęcia
- Tekst alternatywny dla obrazu
Kategorie powiązane z zapytaniem
Tworząc wyniki wyszukiwania grafiki, wyszukiwarka w niektórych implementacjach przesyła żądanie dotyczące kategorii powiązanych z zapytaniem. Wyszukiwarka może użyć powiązanych kategorii, aby zmienić kolejność wyników wyszukiwania obrazów, zwiększając rangę wyników wyszukiwania obrazów uznanych za należące do powiązanych kategorii.
W niektórych przypadkach może to zmniejszyć wyniki obrazów, które nie należą do powiązanych kategorii lub obu.
Wyszukiwarka może również użyć kategorii wyników, aby określić, w jaki sposób powinny one zostać sklasyfikowane w ostatecznym zestawie wyników w połączeniu z lub z kategorią zapytania.
Mechanizm kategoryzujący lub inny proces wykorzystuje wyniki obrazów pobranych dla zapytania oraz repozytorium danych o zachowaniu użytkownika w celu uzyskania kategorii dla zapytania. Repozytorium zawiera dane dotyczące zachowań użytkowników. Pamięć wskazuje, ile razy populacje użytkowników wybrały wynik obrazu dla danego zapytania.
Wyboru obrazu można dokonać na różne sposoby, w tym za pomocą klawiatury, myszy komputerowej lub gestu palcem, polecenia głosowego lub innych metod. Dane dotyczące zachowań użytkowników obejmują „dane kliknięć”.
Dane kliknięcia wskazują, jak długo użytkownik ogląda lub „zamieszkuje” na obrazie wynikowym
Dane o kliknięciach wskazują, jak długo użytkownik wyświetla lub „zatrzymuje” wynik w postaci obrazu po wybraniu go na liście wyników zapytania. Na przykład długi czas przebywania na obrazie (np. dłuższy niż 1 minuta), nazywany „długim kliknięciem”, może oznaczać, że użytkownik uznał obraz za odpowiedni dla zapytania użytkownika.
Krótki okres oglądania obrazu (np. krótszy niż 30 sekund), nazywany „krótkim kliknięciem”, może zostać zinterpretowany jako brak trafności obrazu. Możliwe są inne rodzaje danych o zachowaniu użytkownika.
Na przykład, dane dotyczące zachowań użytkowników mogą zostać wygenerowane przez proces, który tworzy rekord dla dokumentów wynikowych wybranych przez użytkowników w odpowiedzi na określone zapytanie. Każdy formularz może być reprezentowany jako krotka: <dokument, zapytanie, dane>), która zawiera:
- Pytanie przesłane przez użytkowników
- Odwołanie do zapytania wskazujące zapytanie
- Dokument odwołuje się do artykułu wybranego przez użytkowników w odpowiedzi na zapytanie
- Agregacja danych o kliknięciach (takich jak liczba każdego typu kliknięcia) dla wszystkich użytkowników lub podzbioru wszystkich użytkowników, którzy wybrali odwołanie do dokumentu w odpowiedzi na zapytanie.
Możliwe są rozszerzenia tego opartego na krotkach podejścia do danych o zachowaniu użytkowników. Na przykład dane dotyczące zachowania użytkownika mogą zostać rozszerzone o identyfikatory specyficzne dla lokalizacji (takie jak kraj lub stan) lub specyficzne dla języka.
Po uwzględnieniu takich identyfikatorów krotka specyficzna dla kraju składałaby się z kraju, z którego pochodzi zapytanie użytkownika, a krotka specyficzna dla języka składałaby się z języka zapytania użytkownika.
Dla uproszczenia prezentacji dane dotyczące zachowania użytkownika powiązane z dokumentami A-CCC dla zapytania są przedstawiane w tabeli jako „wysoka”, „średnia” lub „niska” ilość korzystnych danych o zachowaniu użytkownika (takich jak zachowanie użytkownika dane wskazujące na związek między dokumentem a zapytaniem).
Dane dotyczące zachowania użytkownika dla dokumentu
Dane o korzystnym zachowaniu użytkownika dla dokumentu mogą oznaczać, że papier jest wybierany przez użytkowników, gdy jest przeglądany w wynikach zapytania, lub gdy użytkownicy przeglądają dokument po wybraniu go z wyników zapytania, użytkownicy przeglądają dokument dla dłuższy okres (na przykład, gdy użytkownik uzna dokument za odpowiedni dla pytania).
Mechanizm kategoryzujący działa w połączeniu z wyszukiwarką, korzystając ze zwróconych wyników i danych o zachowaniu użytkownika, aby określić kategorie zapytań, a następnie ponownie uszeregować wyniki, zanim zostaną zwrócone użytkownikowi.
Ogólnie rzecz biorąc, w przypadku zapytania (takiego jak zapytanie lub alternatywna forma zapytania) określonego w żądaniu kategorii zapytań aparat kategoryzujący analizuje wyniki obrazów dla zapytania, aby określić, czy zapytanie należy do kategorii. Wyniki graficzne analizowane w niektórych implementacjach zostały wybrane przez użytkowników jako wynik wyszukiwania zapytania łącznie kilka razy powyżej określonego progu (np. co najmniej dziesięć razy).
Mechanizm kategoryzujący analizuje wszystkie wyniki wyszukiwania obrazów pobrane przez wyszukiwarkę dla danego zapytania. w innych realizacjach
Mechanizm kategoryzujący analizuje wyniki wyszukiwania obrazów dla zapytania, w którym metryka (np. całkowita liczba selekcji lub inna miara) danych dotyczących kliknięć przekracza próg.
Wyniki obrazu mogą być analizowane online przy użyciu technik widzenia komputerowego na różne sposoby, zarówno offline, jak i online, podczas procesu punktacji. Obrazy są opatrzone adnotacjami z informacjami wydobytymi z ich treści wizualnych.
Adnotacje do obrazów
Na przykład adnotacje do obrazów mogą być przechowywane w magazynie adnotacji. Każdy analizowany obraz (np. obraz 1, obraz 2 itd.) zostaje powiązany z adnotacjami (np. A1, A2 itd.) w powiązaniu zdjęcia z adnotacją.
Adnotacje mogą zawierać:
- Liczba twarzy na obrazie
- Rozmiar każdej twarzy
- Dominujące kolory obrazu
- Czy obraz zawiera tekst czy wykres
- Czy obraz jest zrzutem ekranu
Dodatkowo, każdy obraz może zostać opatrzony adnotacjami odciskiem palca, który może następnie określić, czy dwa obrazy są identyczne, czy identyczne.
Następnie aparat kategoryzujący analizuje wyniki obrazów dla danego zapytania i ich adnotacje w celu określenia kategorii zapytań. Powiązania kategorii zapytań (np. C1, C2 itd.) dla danego zapytania (takiego jak zapytanie 1, zapytanie 2 itd.) można określić na wiele sposobów, na przykład za pomocą prostej heurystyki lub automatycznego klasyfikatora.
Prosty kategoryzator zapytań oparty na heurystyce
Na przykład prosty kategoryzator zapytań oparty na heurystyce może zostać użyty do określenia pożądanego dominującego koloru zapytania (i tego, czy taki istnieje).
Heurystyka może polegać na przykład na tym, że jeśli spośród 20 najczęściej klikanych obrazów w zapytaniu co najmniej 70% ma dominujący kolor czerwony, to zapytanie może zostać sklasyfikowane jako „czerwone zapytanie”. W przypadku takich zapytań wyszukiwarka może zmienić kolejność pobranych wyników, aby podnieść rangę wszystkich obrazów oznaczonych kolorem czerwonym jako dominującym.
Ta sama kategoryzacja może być stosowana ze wszystkimi innymi standardowymi kolorami. Zaletą tego podejścia do nadmiernej analizy tekstu zapytania jest to, że działa ono we wszystkich językach bez potrzeby tłumaczenia (np. będzie promować obrazy z dominującym czerwonym kolorem dla pytania „czerwone jabłko” w dowolnym języku). Jest bardziej niezawodny (na przykład nie zwiększy rangi czerwonych obrazów dla zapytania „morze czerwone”).
Przykładowy silnik kategoryzujący
Aparat kategoryzujący może działać w trybie online lub offline, w którym powiązania kategorii zapytań są przechowywane z wyprzedzeniem (np. w tabeli) do wykorzystania przez wyszukiwarkę podczas przetwarzania zapytań.
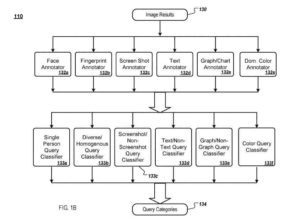
Silnik otrzymuje wyniki zapytania w postaci obrazu dla danego zapytania i udostępnia wyniki w obrazie adnotatorom obrazu. Każdy adnotator obrazu analizuje wyniki obrazu i wyodrębnia informacje o wizualnej zawartości obrazu, które są przechowywane jako adnotacja obrazu (np. adnotacje obrazu) dla pomysłu.
Adnotator obrazu twarzy
Tytułem ilustracji, adnotator obrazu twarzy:
- Określa liczbę twarzy na obrazie i rozmiar każdej twarzy
- adnotator obrazu odcisku palca wyodrębnia cechy obrazu wizualnego w skondensowanej formie (odcisk palca), które następnie można porównać z odciskiem palca innego obrazu, aby określić, czy oba obrazy są podobne
- Adnotator obrazu zrzutu ekranu określa, czy obraz jest zrzutem ekranu
- Adnotator obrazu tekstowego określa, czy obraz zawiera tekst
- Zapytanie o obraz wykresu/wykresu określa, czy obraz zawiera wykresy lub wykresy (np. wykresy słupkowe)
- Adnotator koloru dominującego określa, czy obraz zawiera kolor dominujący
Można również użyć innych adnotatorów obrazu. Na przykład kilka adnotatorów obrazu zostało opisanych w artykule zatytułowanym „Rapid Object Detection Using a Boosted Cascade of Simple Features”, autorstwa Viola, P.; Jones, M., Mitsubishi Electric Research Laboratories, TR2004-043 (maj 2004).
Następnie aparat kategoryzujący analizuje wyniki obrazów dla danego zapytania i ich adnotacje w celu określenia kategorii zapytań (np. kategorii zapytań). Kategorie zapytań są określane za pomocą klasyfikatora, a klasyfikator zapytań można zrealizować za pomocą systemu uczenia maszynowego.
Korzystanie z adaptacyjnego wzmocnienia
Na przykład AdaBoost, skrót od Adaptive Boosting, to system uczenia maszynowego, którego można używać z innymi algorytmami uczenia w celu poprawy ich wydajności. AdaBoost przyzwyczaja się do generowania kategoryzacji zapytań. (Możliwych jest więcej algorytmów uczenia się)
AdaBoost wywołuje „słaby” adnotator obrazu w serii rund. Na przykład, klasyfikator zapytań dla jednej osoby może opierać się na algorytmie uczącym się maszyny wyszkolonym w celu określenia, czy zapytanie wywołuje obrazy jednej osoby.
Na przykład, taki klasyfikator zapytań może zostać przeszkolony z zestawami danych składającymi się z zapytania, zestawem wektorów cech reprezentujących obrazy wyników dla pytania o zerowej lub większej liczbie twarzy oraz poprawną kategoryzację zapytania (tj. twarze lub nie). . Dla każdego wywołania klasyfikator zapytań aktualizuje rozkład wag, który wskazuje na znaczenie przykładów w zestawie danych uczących dla klasyfikacji.
W każdej rundzie wagi każdego sklasyfikowanego przykładu szkolenia są zwiększane (lub konsekwencje każdego sklasyfikowanego przykładu szkolenia ulegają zmniejszeniu), więc nowa kategoryzacja zapytań koncentruje się bardziej na tych przykładach. Wynikowa kategoryzacja wytrenowanego zapytania może przyjąć jako dane wejściowe zapytanie i wyprowadzić prawdopodobieństwo, że zapytanie wywoła obrazy zawierające pojedyncze osoby.
Zróżnicowany/jednorodny klasyfikator zapytań przyjmuje jako dane wejściowe zapytanie i wyprowadza prawdopodobieństwo, że zapytanie dotyczy różnych obrazów. Klasyfikator wykorzystuje algorytm grupowania do grupowania wyników obrazu zgodnie z ich odciskami palców na podstawie miary odległości od siebie. Każdy obraz zostaje powiązany z identyfikatorem klastra.
Identyfikator klastra obrazu jest używany do określenia liczby klastrów, rozmiaru grup i podobieństwa między klastrami utworzonymi przez obrazy w zestawie wyników. Na przykład informacje te są wykorzystywane do kojarzenia prawdopodobieństwa, że zapytanie jest konkretne (lub zaprasza do duplikatów) lub nie,
Kojarzenie zapytań ze znaczeniami i reprezentacjami kanonicznymi
Kategoryzacja zapytań może również zostać przyzwyczajona do kojarzenia zapytań z kanonicznymi znaczeniami i reprezentacjami. Na przykład, jeśli istnieje jeden duży klaster lub kilka dużych klastrów, prawdopodobieństwo, że pytanie zostanie powiązane ze zduplikowanymi wynikami obrazu, jest wysokie. Jeśli istnieje wiele mniejszych klastrów, prawdopodobieństwo, że zapytanie zostanie powiązane z tymi samymi wynikami obrazów, jest niskie.

Duplikaty obrazów zwykle nie są zbyt przydatne, ponieważ nie dostarczają więcej informacji, więc powinny zostać zdegradowane jako wyniki zapytania. Ale są wyjątki. Na przykład, jeśli w początkowych wynikach jest wiele duplikatów (kilka dużych klastrów), zapytanie jest szczególne i duplikaty nie powinny być obniżane.
Kategoryzacja zapytania zrzutu ekranu/nie zrzutu ekranu przyjmuje jako dane wejściowe zapytanie i generuje prawdopodobieństwo, że zapytanie wywoła obrazy, które są zrzutami ekranu. Klasyfikator zapytań tekstowych/nietekstowych przyjmuje jako dane wejściowe zapytanie i generuje prawdopodobieństwo, że zapytanie wywoła obrazy zawierające tekst.
Kategoryzacja zapytań typu wykres/niewykres pobiera dane wejściowe zapytania i generuje prawdopodobieństwo, że zapytanie wywoła obrazy zawierające wykres lub wykres. Klasyfikator zapytań o kolor 133f pobiera zapytanie informacyjne i generuje szansę, że zapytanie wywoła ujęcia zdominowane przez pojedynczy kolor. Możliwe są inne klasyfikatory zapytań.
Poprawa trafności wyników obrazu na podstawie kategoryzacji zapytań
Wyszukiwarka może wchodzić w interakcję z systemem za pośrednictwem klienta lub innego urządzenia. Na przykład urządzeniem klienckim może być terminal komputerowy w sieci lokalnej (LAN) lub sieci rozległej (WAN). Urządzenie klienckie może być urządzeniem mobilnym (np. telefonem komórkowym, komputerem mobilnym, osobistym asystentem pulpitu itp.) zdolnym do komunikowania się przez sieć LAN, WAN lub inną sieć (np. sieć telefonii komórkowej).
Urządzenie klienckie może zawierać pamięć o dostępie swobodnym (RAM) (lub inną pamięć i urządzenie magazynujące) oraz procesor.
Procesor zostaje zorganizowany w celu przetwarzania instrukcji i danych w systemie. Procesor jest mikroprocesorem jedno- lub wielowątkowym z rdzeniami przetwarzającymi. Procesor otrzymuje struktury do wykonywania instrukcji przechowywanych w pamięci RAM (lub innej pamięci i urządzeniu pamięciowym dołączonym do urządzenia klienckiego) w celu renderowania informacji graficznych dla interfejsu użytkownika.
Wyszukiwarka może połączyć się z wyszukiwarką w systemie serwera, aby przesłać zapytanie wejściowe. Wyszukiwarka to wyszukiwarka obrazów lub ogólna wyszukiwarka, która może pobierać obrazy i inne rodzaje treści, takie jak dokumenty (np. strony HTML).
Gdy użytkownik przesyła zapytanie wejściowe za pośrednictwem urządzenia wejściowego podłączonego do urządzenia klienckiego, pytanie po stronie klienta jest wysyłane do sieci i przekazywane do systemu serwera jako zapytanie po stronie serwera. System serwerowy może być urządzeniami serwerowymi w lokalizacjach. Urządzenie serwerowe zawiera urządzenie pamięci składające się z załadowanej do niego wyszukiwarki.
Procesor zostaje zorganizowany w celu przetwarzania instrukcji w urządzeniu. Te instrukcje mogą zainstalować komponenty wyszukiwarki. Procesor może być jednowątkowy lub wielowątkowy i zawierać wiele rdzeni przetwarzających. Procesor może przetwarzać instrukcje przechowywane w pamięci związane z wyszukiwarką i wysyłać informacje do urządzenia klienckiego przez sieć, aby utworzyć graficzną prezentację w interfejsie użytkownika urządzenia klienckiego (np. wyniki wyszukiwania na stronie internetowej wyświetlanej w sieci przeglądarka).
Zapytanie po stronie serwera jest odbierane przez wyszukiwarkę. Wyszukiwarka wykorzystuje informacje zawarte w zapytaniu wejściowym (takie jak terminy zapytania), aby znaleźć odpowiednie dokumenty. Wyszukiwarka może zawierać mechanizm indeksowania, który przeszukuje korpus (np. strony internetowe w Internecie) w celu indeksowania dokumentów znalezionych w tym korpusie. Informacje indeksowe dla dokumentów korpusu mogą być przechowywane w bazie danych indeksów.
Ta baza danych indeksów może być dostępna w celu identyfikacji dokumentów związanych z użytkownikiem. Należy pamiętać, że kopia elektroniczna (która będzie określana jako dokument) nie odpowiada plikowi. Rekord może być przechowywany w części pliku, w której znajdują się inne dokumenty, w jednym pliku poświęconym danemu dokumentowi lub w wielu skoordynowanych plikach. Co więcej, kopia może zostać zapisana w pamięci bez zapisywania jej w pliku.
Wyszukiwarka może zawierać mechanizm rankingowy, który ocenia dokumenty związane z zapytaniem wejściowym. Ranking dokumentów można przeprowadzić przy użyciu tradycyjnych technik w celu określenia wyniku wyszukiwania informacji (IR) dla zindeksowanych rekordów dla danego zapytania.
Dowolna odpowiednia metoda może określić trafność danego dokumentu w określonym wyszukiwanym terminie lub w odniesieniu do innych dostarczonych informacji. Na przykład ogólny poziom linków zwrotnych do dokumentu zawierającego dopasowania do wyszukiwanego terminu może zostać wykorzystany do ustalenia trafności dokumentu.
W szczególności, jeśli dokument zostanie połączony (np. jest celem hiperłącza) przez wiele innych odpowiednich dokumentów (takich jak dokumenty zawierające dopasowania do wyszukiwanych terminów), można wywnioskować, że dokument docelowy jest szczególnie istotny. Taki wniosek można wyciągnąć, ponieważ autorzy referatów prawdopodobnie wskazują w większości inne dokumenty, które są istotne dla ich odbiorców.
Dokumenty wskazujące mają na celu linki z innych odpowiednich dokumentów, które można uznać za bardziej odpowiednie. Pierwszy dokument jest szczególnie odpowiedni, ponieważ dotyczy odpowiednich (lub nawet bardzo istotnych) dokumentów.
Taka technika może określać trafność dokumentu lub jeden z wielu wyznaczników. Odpowiednie metody mogą również zostać wykorzystane do zidentyfikowania i wyeliminowania prób oddawania fałszywych głosów w celu zwiększenia trafności strony.
Aby jeszcze bardziej ulepszyć takie tradycyjne techniki rankingowania dokumentów, silnik rankingu może odbierać więcej sygnałów z silnika modyfikującego ranking, aby pomóc w określeniu odpowiedniego rankingu dokumentów.
W połączeniu z opisanymi powyżej adnotatorami obrazów i kategoryzacją zapytań, mechanizm modyfikujący rangę zapewnia miary trafności artykułów. Silnik rankingowy może wykorzystać do poprawy rankingu wyników wyszukiwania dostarczanego użytkownikowi.
Aparat modyfikujący rangę może wykonywać operacje w celu wygenerowania miar istotności.
To, czy wynik wyniku obrazu wzrośnie, czy zmniejszy się, zależy od tego, czy zawartość wizualna obrazu (przedstawiona w adnotacjach obrazu) pasuje do kategoryzacji zapytania, uwzględniana jest każda kategoria obrazu.
Na przykład, jeśli kategoria zapytania to „pojedyncza osoba”, wynik w postaci obrazu, który zostanie sklasyfikowany zarówno jako „zrzut ekranu”, jak i „pojedyncza twarz”, najpierw będzie miał obniżony wynik ze względu na kategorię „zrzut ekranu”. Następnie może zwiększyć swój wynik dzięki kategorii „pojedyncza twarz”.
Wyszukiwarka może przesyłać przez sieć ostateczną, uporządkowaną listę wyników w wynikach wyszukiwania po stronie serwera. Po wyjściu z sieci wyniki wyszukiwania po stronie klienta mogą zostać odebrane przez urządzenie klienckie, gdzie wyniki mogą być przechowywane w pamięci RAM i wykorzystywane przez procesor do wyświetlania wyników na urządzeniu wyjściowym dla użytkownika.
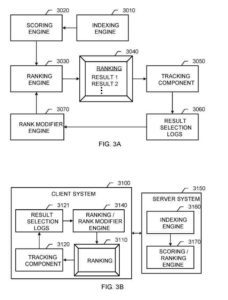
System wyszukiwania informacji
Te elementy obejmują:
- Silnik indeksujący
- Silnik punktacji
- Silnik rankingowy
- Silnik modyfikatora rang
Mechanizm indeksowania działa w sposób opisany powyżej dla mechanizmu indeksowania. Mechanizm oceniania generuje wyniki dla wyników dokumentów na podstawie wielu funkcji, w tym funkcji opartych na treści, które łączą zapytanie z wynikami dokumentów oraz części niezależnych od zapytania, które ogólnie określają jakość wyników dokumentów.
Funkcje oparte na zawartości obrazów obejmują aspekty dokumentu, który zawiera obraz, takie jak dopasowania zapytań do tytułu dokumentu lub podpisu obrazu.
Funkcje niezależne od zapytania obejmują, na przykład, aspekty powiązania dokumentów z wymiarami artykułu, domeny lub obrazu.
Co więcej, poszczególne funkcje używane przez silnik oceniania mogą zostać dostrojone w celu dostosowania wkładu różnych funkcji do końcowego wyniku IR, przy użyciu procesów automatycznych lub półautomatycznych.
Mechanizm rankingowy klasyfikuje wyniki dokumentu do wyświetlenia użytkownikowi na podstawie wyników IR otrzymanych z urządzenia oceniającego i sygnałów z silnika modyfikującego rangę.
Mechanizm modyfikujący rangę zapewnia miary trafności dokumentów, które może wykorzystać do poprawienia rankingu wyników wyszukiwania udostępnianego użytkownikowi. Komponent śledzący rejestruje informacje o zachowaniu użytkownika, takie jak indywidualne wybory wyników przedstawionych w zamówieniu.
Komponent śledzący otrzymuje osadzony kod JavaScript zawarty w rankingu stron internetowych, który identyfikuje wybrane przez użytkownika wyniki poszczególnych dokumentów i identyfikuje, kiedy użytkownik powraca do strony wyników, wskazując w ten sposób ilość czasu, jaką użytkownik spędził na przeglądaniu wybranego wyniku dokumentu.
Komponent śledzenia to system proxy, przez który kierowane są wybory użytkownika wyników dokumentów. Komponent śledzący może również obejmować wstępnie zainstalowane oprogramowanie klienta (takie jak wtyczka paska narzędzi do systemu operacyjnego klienta).
Możliwe są również inne implementacje, na przykład taka, która wykorzystuje funkcję przeglądarki internetowej, która umożliwia umieszczenie tagu/dyrektywy na stronie, która żąda od przeglądarki połączenia z powrotem z serwerem z komunikatami o linkach klikniętych przez użytkownika.
Zarejestrowane informacje są zapisywane w logach wyboru wyników. Zarejestrowane informacje obejmują wpisy w dzienniku, które określają interakcję użytkownika z każdym dokumentem wynikowym prezentowanym dla każdego przesłanego zapytania.
Dla każdego wyboru przez użytkownika dokumentu wynikowego przedstawionego dla zapytania, wpisy dziennika określają zapytanie (Q), papier (D), czas przebywania użytkownika (T) w dokumencie, język (L) używany przez użytkownika, oraz kraj (C), w którym prawdopodobnie znajduje się użytkownik (np. na podstawie serwera używanego do uzyskania dostępu do systemu IR) oraz kod regionu (R) identyfikujący obszar miejski użytkownika.
Wpisy dziennika rejestrują również negatywne informacje, takie jak to, że wynik dokumentu jest prezentowany użytkownikowi, ale nie został wybrany.
Inne informacje, takie jak:
- Pozycje kliknięć (tj. wybory użytkownika w interfejsie użytkownika
- Informacje o sesji (takie jak istnienie i rodzaj poprzednich kliknięć (aktywność sesji po kliknięciu))
- Wyniki R klikniętych wyników
- Wyniki IR wszystkich wyników pokazanych przed kliknięciem
- Tytuły i fragmenty są wyświetlane użytkownikowi przed kliknięciem
- Plik cookie użytkownika
- Wiek ciasteczek
- Adres IP (protokół internetowy)
- Klient użytkownika przeglądarki
- Już wkrótce
Rejestrowany jest również czas (T) między początkowym kliknięciem i przejściem do wyniku dotyczącego dokumentu a powrotem użytkownika do strony głównej i kliknięciem wyniku innego dokumentu (lub przesłaniem nowego zapytania wyszukiwania).
Dokonuje się oceny czasu (T) określającego, czy ten czas wskazuje na dłuższy widok dokumentu, czy krótszy, ponieważ bardziej rozbudowane argumenty generalnie pokazują jakość lub znaczenie dla klikniętego wyniku. Ocenę czasu (T) można przeprowadzić w połączeniu z różnymi technikami ważenia.
Przedstawione komponenty można łączyć na różne sposoby i w wielu konfiguracjach systemu. Silniki tankowania końcowego punktacji łączą się w jeden silnik rankingowy, taki jak silnik rankingowy. Mechanizm modyfikatora rangi i mechanizm rankingu również mogą zostać połączone. Ogólnie rzecz biorąc, mechanizm rankingowy zawiera dowolny składnik oprogramowania, który po zapytaniu generuje ranking wyników dokumentów. Co więcej, silnik rankingowy może dopasować system klienta również (lub zamiast) do systemu serwera.
Innym przykładem jest system wyszukiwania informacji. System serwera zawiera silnik indeksowania i silnik oceniania/rankingu.
W tym systemie System klienta obejmuje:
- Interfejs użytkownika do prezentacji rankingu
- Komponent śledzący
- Dzienniki wyboru wyników
- Silnik modyfikatora rankingu/rangi.
Na przykład system kliencki może obejmować sieć firmową i komputery osobiste, w których wtyczka do przeglądarki zawiera mechanizm modyfikujący ranking/ranking.
Gdy pracownik w firmie inicjuje wyszukiwanie w systemie serwerowym, silnik scoringowy/rankingowy może zwrócić wyniki wyszukiwania. Wstępny ranking lub rzeczywiste wyniki IR dla wyników. Wtyczka przeglądarki zmienia następnie ranking wyników na podstawie śledzonych wyborów stron dla bazy użytkowników specyficznej dla firmy.
Technika kategoryzacji zapytań
Ta technika może być wykonywana w trybie online (w ramach przetwarzania zapytań) lub w trybie offline.
Otrzymane wyniki pierwszego obrazu odpowiadające pierwszemu zapytaniu. Każdy z pierwszych obrazów zostaje powiązany z zamówieniem (takim jak wynik IR) i odpowiednimi danymi dotyczącymi zachowania użytkownika (takimi jak dane o kliknięciach).
Wybrana zostaje liczba pierwszych obrazów, gdzie metryka dla odpowiednich danych zachowania dla każdego wybranego obrazu spełnia próg.
Wybrane pierwsze obrazy są kojarzone z kilkoma adnotacjami na podstawie analizy zawartości wybranych pierwszych obrazów. Adnotacje obrazu mogą zostać utrwalone w adnotacjach obrazu.
Kategorie są następnie kojarzone z pierwszym zapytaniem na podstawie adnotacji.
Powiązania kategoryzacji zapytań mogą trwać w kategoriach zapytań.
Następnie odbierane są wyniki drugiego obrazu odpowiadające drugiemu zapytaniu, które jest takie samo lub pierwsze zapytanie.
(Jeśli drugie zapytanie nie zostanie znalezione w kategoryzacji zapytań, drugie zapytanie może zostać przekształcone lub „przepisane”, aby określić, czy forma alternatywna pasuje do zapytania w kategoryzacji zapytań).
W tym przykładzie drugie zapytanie jest takie samo jak pierwsze zapytanie lub może zostać przepisane.
Drugie wyniki obrazów są ponownie porządkowane na podstawie kategoryzacji zapytania przed powiązaniem z pierwszym zapytaniem.
Przeszukaj wiadomości prosto do skrzynki odbiorczej
*Wymagany