
Бесплатный скрипт Python для n-грамм Google Ads
Опубликовано: 2022-04-12N-граммы могут быть важным оружием для анализа поисковых запросов в Google Ads или SEO. Итак, мы создали бесплатный скрипт на Python, который поможет вам анализировать n-граммы любой длины как в фиде товаров, так и в поисковых запросах. Мы объясним, что такое n-граммы и как использовать n-граммы для оптимизации ваших объявлений Google, особенно для Google Покупок. Наконец-то мы покажем вам, как использовать наш бесплатный скрипт n-grams для улучшения ваших результатов в Google Ads.
Что такое n-граммы?
N-граммы — это фразы из N слов, извлеченные из более длинных текстов. «N» здесь можно заменить любым числом.
Например, в таком предложении, как «кошка прыгнула на коврик», «кошка прыгнула» или «мат» оба будут равны 2 граммам (или «биграммам»).
«Кошка прыгнула» или «кошка прыгнула» — оба примера 3-грамм (или «триграмм») из этого предложения.
Как n-граммы помогают поисковым запросам
N-граммы полезны при анализе поисковых запросов в Google Ads, поскольку определенные ключевые фразы могут встречаться в разных поисковых запросах.
N-граммы позволяют нам анализировать влияние этих фраз на весь ваш инвентарь. Таким образом, они позволяют принимать более эффективные решения и оптимизировать масштабирование.
Это даже позволяет нам понять влияние отдельных слов. Например, если вы заметили низкую эффективность запросов, содержащих слово «бесплатно» («1 грамм»), вы можете исключить это слово из всех кампаний.
Или высокая эффективность поисковых запросов, содержащих «персонализированные», может побудить вас создать специальную кампанию.
N-граммы особенно полезны для просмотра поисковых запросов из Google Shopping.
Автоматизированный характер таргетинга по ключевым словам товарных объявлений означает, что вы можете найти сотни тысяч поисковых запросов. Особенно, когда у вас есть большое количество вариантов продукта с очень специфическими функциями.
Наш скрипт N-grams позволяет разобрать этот беспорядок на важные фразы.
Анализ поисковых запросов с помощью n-грамм
Первый вариант использования n-грамм — анализ поисковых запросов.
Наш скрипт Python n-grams для Google Ads содержит полные инструкции по его запуску, но
мы рассмотрим, как извлечь из этого максимальную пользу.
- Для начала вам нужно будет установить python на свой компьютер. Если нет, то очень легко. Сначала вы устанавливаете Anaconda. Затем откройте Anaconda Prompt и введите «conda install jupyter lab». Jupyter Lab — это среда, в которой вы будете запускать этот скрипт.
Просто загрузите отчет о поисковых запросах из Google Ads. Мы рекомендуем настроить его как пользовательский отчет в разделе «Отчеты» Google Ads. Вы даже можете настроить это на уровне Центра клиентов, если хотите запустить этот скрипт в нескольких учетных записях.

3. Затем просто обновите настройки в скрипте, чтобы они делали то, что вы хотите, и запустите все ячейки.
Это займет немного времени, чтобы бежать, но будьте терпеливы. Вы увидите, как прогресс обновляется внизу, поскольку он делает свое волшебство.
Результат будет отображаться в виде файла Excel в любой папке, в которой вы запускаете скрипт, мы рекомендуем использовать папку загрузок. Файл будет помечен любым именем, которое вы определите.
Каждая вкладка файла Excel содержит отдельный анализ n-грамм. Например, вот биграммный анализ:
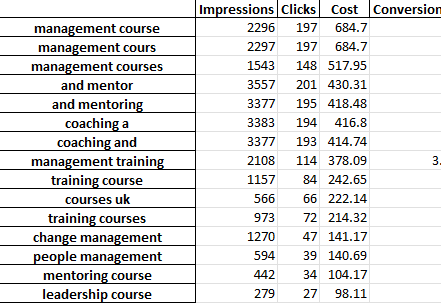
Существует несколько способов использования этого отчета для поиска улучшений.
Вы можете начать с фраз с самыми высокими расходами и посмотреть на любые выбросы для CPA или ROAS.
Фильтрация ваших отчетов по неконвертерам также выявит области плохих расходов.
Если вы видите плохие преобразователи на вкладке отдельных слов, вы можете легко проверить, в каком контексте используются слова, на вкладке 3-Gram.
Например, в учетной записи профессионального обучения мы можем заметить, что «Оксфорд» постоянно работает плохо. Вкладка 3-Gram быстро показывает, что пользователи, скорее всего, ищут более формальный, ориентированный на университет курс.

Таким образом, вы можете быстро отрицать это слово.
В конечном счете, используйте этот отчет, однако он лучше всего подходит для вас.
Оптимизация подачи товаров с помощью n-грамм
Наш второй скрипт n-grams для Google Ads анализирует эффективность вашего продукта.
Опять же, вы можете найти полные инструкции в самом скрипте.
Этот скрипт оценивает эффективность фраз в названиях ваших продуктов. Название продукта, в конце концов, в значительной степени определяет, по каким ключевым словам вы показываетесь. Заголовок также является вашей основной рекламной копией. Поэтому титулы невероятно важны.
Скрипт предназначен для того, чтобы помочь вам найти потенциальные фразы в этих заголовках, которые вы можете адаптировать для повышения эффективности работы с Google Покупками.

Как вы можете видеть выше, вывод этого скрипта немного отличается. Из-за ограничений API отчетов Google вы не можете получить доступ к показателям конверсии (например, доходу), пока вы находитесь на уровне названия продукта.
Таким образом, этот отчет дает вам количество продуктов, средний трафик и разброс (стандартное отклонение) фраз продукта.
Поскольку он основан на видимости, вы можете использовать отчет, чтобы определить фразы, которые могут сделать ваши продукты более заметными. Затем вы можете добавить их к другим названиям ваших продуктов.

Например, мы можем найти фразу с очень большим средним количеством показов, которая появляется в названии нескольких продуктов. Он также имеет низкое стандартное отклонение, а это означает, что вряд ли будет только один удивительный продукт, который искажает наши цифры.
Мы использовали этот инструмент, чтобы значительно расширить видимость покупок для клиента. Клиент продавал товары тысячами разных размеров. Например 8х10мм. Люди также покупали очень конкретные размеры, которые им были нужны.
Но Google плохо понимал различные возможные соглашения об именах для этого размера: поисковые запросы, такие как 8 мм на 10 мм, 8 x 10 мм, 8 мм x 10 мм, обрабатывались как почти совершенно разные поисковые запросы.
Поэтому мы использовали наш сценарий n-грамм, чтобы определить, какие из этих соглашений об именах обеспечивают наилучшую видимость наших продуктов.
Мы нашли наилучшее соответствие и внесли изменения в наш фид товаров. В результате трафик торговых кампаний клиента за один месяц вырос более чем на 550% .
Название продукта имеет значение, и n-граммы могут вам в этом помочь.
Скрипты N-gram для Google Ads
Вот оба полных сценария.
Скрипт N-grams для поисковых запросов Google Ads
#!/usr/bin/env python #coding: utf-8 # Ayima N-Grams Script for Google Ads #Takes in SQR data and outputs data split into phrases of N length #Script produced by Ayima Limited (www.ayima.com) # 2022. This work is licensed under a CC BY SA 4.0 license (https://creativecommons.org/licenses/by-sa/4.0/). #Version 1.1 ### Instructions #Download an SQR from within the reports section of Google ads. #The report must contain the following metrics: #+ Search term #+ Campaign #+ Campaign state #+ Currency code #+ Impressions #+ Clicks #+ Cost #+ Conversions #+ Conv. value #Then, complete the setting section as instructed and run the whole script #The script may take some time. Ngrams are computationally difficult, particularly for larger accounts. But, give it enough time to run, and it will log if it is running correctly. ### Settings # First, enter the name of the file to run this script on # By default, the script only looks in the folder it is in for the file. So, place this script in your downloads folder for ease. file_name = "N-Grams input - SQR (2).csv" grams_to_run = [1,2,3] #What length phrases you want to retrieve for. Recommended is < 4 max. Longer phrases retrieves far more results. campaigns_to_exclude = "" #input strings contained by campaigns you want to EXCLUDE, separated by commas if multiple (eg "DSA,PLA"). Case Insensitive campaigns_to_include = "PLA" #input strings contained by campaigns you want to INCLUDE, separated by commas if multiple (eg "DSA,PLA"). Case Insensitive character_limit = 3 #minimum number of characters in an ngram eg to filter out "a" or "i". Will filter everything below this limit client_name = "SAMPLE CLIENT" #Client name, to label on the final file enabled_campaigns_only = False #True/False - Whether to only run the script for enabled campaigns impressions_column_name = "Impr." #Google consistently flip between different names for their impressions column. We think just to annoy us. This spelling was correct at time of writing brand_terms = ["BRAND_TERM_2", #Labels brand and non-brand search terms. You can add as many as you want. Case insensitive. If none, leave as [""] "BRAND_TERM_2"] #eg ["Adidas","Addidas"] ## The Script #### You should not need to make changes below here import pandas as pd from nltk import ngrams import numpy as np import time import re def read_file(file_name): #find the file format and import if file_name.strip().split('.')[-1] == "xlsx": return pd.read_excel(f"{file_name}",skiprows = 2, thousands =",") elif file_name.strip().split('.')[-1] == "csv": return pd.read_csv(f"{file_name}",skiprows = 2, thousands =",") df = read_file(file_name) def filter_campaigns(df, to_ex = campaigns_to_exclude,to_inc = campaigns_to_include): to_ex = to_ex.split(",") to_inc = to_inc.split(",") if to_inc != ['']: to_inc = [word.lower() for word in to_inc] df = df[df["Campaign"].str.lower().str.strip().str.contains('|'.join(to_inc))] if to_ex != ['']: to_ex = [word.lower() for word in to_ex] df = df[~df["Campaign"].str.lower().str.strip().str.contains('|'.join(to_ex))] if enabled_campaigns_only: try: df = df[df["Campaign state"].str.contains("Enabled")] except KeyError: print("Couldn't find 'Campaign state' column") return df def generate_ngrams(list_of_terms, n): """ Turns a list of search terms into a set of unique n-grams that appear within """ # Clean the terms up first and remove special characters/commas etc. #clean_terms = [] #for st in list_of_terms: #st = st.strip() #clean_terms.append(re.sub(r'[^a-zA-Z0-9\s]', '', st)) #split into grams unique_ngrams = set() for term in list_of_terms: grams = ngrams(term.split(" "), n) [unique_ngrams.add(gram) for gram in grams] all_grams = set([' '.join(tups) for tups in unique_ngrams]) if character_limit > 0: n_grams_list = [ngram for ngram in all_grams if len(ngram) > character_limit] return n_grams_list def _collect_stats(term): #Slice the dataframe to the terms at hand sliced_df = df[df["Search term"].str.match(fr'. {re.escape(term)}. ')] #add our metrics raw_data =list(np.sum(sliced_df[[impressions_column_name,"Clicks","Cost","Conversions","Conv. value"]])) return raw_data def _generate_metrics(df): #generate metrics try: df["CTR"] = df["Clicks"]/df[f"Impressions"] df["CVR"] = df["Conversions"]/df["Clicks"] df["CPC"] = df["Cost"]/df["Clicks"] df["ROAS"] = df[f"Conv. value"]/df["Cost"] df["CPA"] = df["Cost"]/df["Conversions"] except KeyError: print("Couldn't find a column") #replace infinites with NaN and replace with 0 df.replace([np.inf, -np.inf], np.nan, inplace=True) df.fillna(0, inplace= True) df.round(2) return df def build_ngrams_df(df, sq_column_name ,ngrams_list, character_limit = 0): """Takes in n-grams and df and returns df of those metrics df - dataframe in question sq_column_name - str. Name of the column containing search terms ngrams_list - list/set of unique ngrams, already generated character_limit - Words have to be over a certain length, useful for single word grams Outputs a dataframe """ #set up metrics lists to drop values array = [] raw_data = map(_collect_stats, ngrams_list) #stack into an array data = np.array(list(raw_data)) #turn the above into a dataframe columns = ["Impressions","Clicks","Cost","Conversions", "Conv. value"] ngrams_df = pd.DataFrame(columns= columns, data=data, index = list(ngrams_list), dtype = float) ngrams_ df.sort_values(by = "Cost", ascending = False, inplace = True) #calculate additional metrics and return return _generate_metrics(ngrams_df) def group_by_sqs(df): df = df.groupby("Search term", as_index = False).sum() return df df = group_by_sqs(df) def find_brand_terms(df, brand_terms = brand_terms): brand_terms = [str.lower(term) for term in brand_terms] st_brand_bool = [] for i, row in df.iterrows(): term = row["Search term"] #runs through the term and if any of our brand strings appear, labels the column brand if any([brand_term in term for brand_term in brand_terms]): st_brand_bool.append("Brand") else: st_brand_bool.append("Generic") return st_brand_bool df["Brand label"] = find_brand_terms(df) #This is necessary for larger search volumes to cut down the very outlier terms with extremely few searches i = 1 while len(df)> 40000: print(f"DF too long, at {len(df)} rows, filtering to impressions greater than {i}") df = df[df[impressions_column_name] > i] i+=1 writer = pd.ExcelWriter(f"Ayima N-Gram Script Output - {client_name} N-Grams.xlsx", engine='xlsxwriter') df.to_excel(writer, sheet_name='Raw Searches') for n in grams_to_run: print("Working on ",n, "-grams") n_grams = generate_ngrams(df["Search term"], n) print(f"Found {len(n_grams)} n_grams, building stats (may take some time)") n_gram_df = build_ngrams_df(df,"Search term", n_grams, character_limit) print("Adding to file") n_gram_df.to_excel(writer, sheet_name=f'{n}-Gram',) writer.close()Скрипт N-grams для анализа фидов товаров
#!/usr/bin/env python #coding: utf-8 # N-Grams for Google Shopping #This script looks to find patterns and trends in product feed data for Google shopping. It will help you find what words and phrases have been performing best for you #Script produced by Ayima Limited (www.ayima.com) # 2022. This work is licensed under a CC BY SA 4.0 license (https://creativecommons.org/licenses/by-sa/4.0/). #Version 1.1 ## Instructions #Download an SQR from within the reports section of Google ads. #The report must contain the following metrics: #+ Item ID #+ Product title #+ Impressions #+ Clicks #Then, complete the setting section as instructed and run the whole script #The script may take some time. Ngrams are computationally difficult, particularly for larger accounts. But, give it enough time to run, and it will log if it is running correctly. ## Settings #First, enter the name of the file to run this script on #By default, the script only looks in the folder it is in for the file. So, place this script in your downloads folder for ease. file_name = "Product report for N-Grams (1).csv" grams_to_run = [1,2,3] #The number of words in a phrase to run this for (eg 3 = three-word phrases only) character_limit = 0 #Words have to be over a certain length, useful for single word grams to rule out tiny words/symbols title_column_name = "Product Title" #Name of our product title column desc_column_name = "" #Name of our product description column, if we have one file_label = "Sample Client Name" #The label you want to add to the output file (eg the client name, or the run date) impressions_column_name = "Impr." #Google consistently flip between different names for their impressions column. We think just to annoy us. This spelling was correct at time of writing client_name = "SAMPLE" ## The Script #### You should not need to make changes below here #First import all of the relevant modules/packages import pandas as pd from nltk import ngrams import numpy as np import time import re #import our data file def read_file(file_name): #find the file format and import if file_name.strip().split('.')[-1] == "xlsx": return pd.read_excel(f"{file_name}",skiprows = 2, thousands =",") elif file_name.strip().split('.')[-1] == "csv": return pd.read_csv(f"{file_name}",skiprows = 2, thousands =",")# df = read_file(file_name) df.head() def generate_ngrams(list_of_terms, n): """ Turns our list of product titles into a set of unique n-grams that appear within """ unique_ngrams = set() for term in list_of_terms: grams = ngrams(term.split(" "), n) [unique_ngrams.add(gram) for gram in grams if ' ' not in gram] ngrams_list = set([' '.join(tups) for tups in unique_ngrams]) return ngrams_list def _collect_stats(term): #Slice the dataframe to the terms at hand sliced_df = df[df[title_column_name].str.match(fr'. {re.escape(term)}. ')] #add our metrics raw_data = [len(sliced_df), #number of products np.sum(sliced_df[impressions_column_name]), #total impressions np.sum(sliced_df["Clicks"]), #total clicks np.mean(sliced_df[impressions_column_name]), #average number of impressions np.mean(sliced_df["Clicks"]), #average number of clicks np.median(sliced_df[impressions_column_name]), #median impressions np.std(sliced_df[impressions_column_name])] #standard deviation return raw_data def build_ngrams_df(df, title_column_name, ngrams_list, character_limit = 0, desc_column_name = ''): """ Takes in n-grams and df and returns df of those metrics df - our dataframe title_column_name - str. Name of the column containing product titles ngrams_list - list/set of unique ngrams, already generated character_limit - Words have to be over a certain length, useful for single word grams to rule out tiny words/symbols desc_column_name = str. Name of the column containing product descriptions, if applicable Outputs a dataframe """ #first cut it to only grams longer than our minimum if character_limit > 0: ngrams_list = [ngram for ngram in ngrams_list if len(ngram) > character_limit] raw_data = map(_collect_stats, ngrams_list) #stack into an array data = np.array(list(raw_data)) #data[np.isnan(data)] = 0 columns = ["Product Count","Impressions","Clicks","Avg. Impressions", "Avg. Clicks","Median Impressions","Spread (Standard Deviation)"] #turn the above into a dataframe ngrams_df = pd.DataFrame(columns= columns, data=data, index = list(ngrams_list)) #clean the dataframe and add other key metrics ngrams_df["CTR"] = ngrams_df["Clicks"]/ ngrams_df["Impressions"] ngrams_df.fillna(0, inplace=True) ngrams_df.round(2) ngrams_df[["Impressions","Clicks","Product Count"]] = ngrams_df[["Impressions","Clicks","Product Count"]].astype(int) ngrams_df.sort_values(by = "Avg. Impressions", ascending = False, inplace = True) return ngrams_df writer = pd.ExcelWriter(f"{client_name} Product Feed N-Grams.xlsx", engine='xlsxwriter') start_time = time.time() for n in grams_to_run: print("Working on ",n, "-grams") n_grams = generate_ngrams(df["Product Title"], n) print(f"Found {len(n_grams)} n_grams, building stats (may take some time)") n_gram_df = build_ngrams_df(df,"Product Title", n_grams, character_limit) print("Adding to file") n_gram_df.to_excel(writer, sheet_name=f'{n}-Gram',) time_taken = time.time() - start_time print("Took "+str(time_taken) + " Seconds") writer.close()Вы также можете найти обновленные версии скрипта n-grams на github для загрузки.

Эти скрипты находятся под лицензией Creative Commons BY SA 4.0, что означает, что вы можете свободно делиться ими и адаптировать их, но мы рекомендуем вам всегда бесплатно делиться своими улучшенными версиями для всех. N-граммы слишком полезны, чтобы ими не поделиться.
Это лишь один из многих бесплатных инструментов, сценариев и шаблонов, которые мы предоставляем членам Ayima Insights Club. Вы можете узнать больше о Insights Club и бесплатно зарегистрироваться здесь.