
สคริปต์ Python ฟรีสำหรับโฆษณา Google n-grams
เผยแพร่แล้ว: 2022-04-12N-grams อาจเป็นอาวุธสำคัญในการวิเคราะห์คำค้นหาใน Google Ads หรือ SEO ดังนั้นเราจึงได้จัดทำสคริปต์ python ฟรีเพื่อช่วยคุณวิเคราะห์ n-grams ที่มีความยาวเท่าใดก็ได้จากฟีดผลิตภัณฑ์และคำค้นหาของคุณ เราจะอธิบายว่า n-gram คืออะไร และวิธีใช้ n-gram เพื่อเพิ่มประสิทธิภาพ Google Ads ของคุณ โดยเฉพาะสำหรับ Google Shopping ในที่สุด เราจะแสดงให้คุณเห็นถึงวิธีใช้สคริปต์ n-grams ฟรีของเราเพื่อปรับปรุงผลลัพธ์ Google Ads ของคุณ
n-grams คืออะไร?
N-grams คือวลีจำนวน N จำนวนคำที่ดึงออกมาจากเนื้อหาที่ยาวกว่า 'N' ที่นี่สามารถแทนที่ด้วยตัวเลขใดก็ได้
ตัวอย่างเช่น ในประโยคเช่น "the cat jumped on the mat", "cat jumped" หรือ "the mat" จะเป็น 2 กรัม (หรือ 'bi-grams')
“The cat jumped” หรือ “cat jumped on” เป็นทั้งตัวอย่าง 3 กรัม (หรือ 'tri-grams') จากประโยคนี้
n-grams ช่วยค้นหาได้อย่างไร
N-gram มีประโยชน์ในการวิเคราะห์คำค้นหาภายใน Google Ads เนื่องจากวลีสำคัญบางวลีสามารถปรากฏในคำค้นหาต่างๆ มากมาย
N-grams ให้เราวิเคราะห์ผลกระทบของวลีเหล่านี้ทั่วทั้งคลังของคุณ สิ่งเหล่านี้ช่วยให้คุณตัดสินใจได้ดีขึ้นและปรับให้เหมาะสมตามขนาด
มันยังช่วยให้เราเข้าใจผลกระทบของคำเดียว ตัวอย่างเช่น หากคุณเห็นประสิทธิภาพที่อ่อนแอจากการค้นหาที่มีคำว่า "ฟรี" ("1 กรัม") คุณอาจตัดสินใจลบคำนั้นออกจากทุกแคมเปญ
หรือประสิทธิภาพที่ดีจากคำค้นหาที่มีคำว่า "เฉพาะบุคคล" อาจสนับสนุนให้คุณสร้างแคมเปญเฉพาะ
N-gram มีประโยชน์อย่างยิ่งในการดูคำค้นหาจาก Google Shopping
ลักษณะอัตโนมัติของการกำหนดเป้าหมายจากคำหลักของโฆษณาตามรายการผลิตภัณฑ์หมายความว่าคุณสามารถแสดงข้อความค้นหาหลายแสนรายการ โดยเฉพาะอย่างยิ่งเมื่อคุณมีตัวเลือกสินค้าจำนวนมากที่มีคุณสมบัติเฉพาะเจาะจงมาก
สคริปต์ N-grams ของเราช่วยให้คุณตัดความยุ่งเหยิงนั้นไปยังวลีที่สำคัญได้
การวิเคราะห์คำค้นหาด้วย n-grams
กรณีการใช้งานครั้งแรกสำหรับ n-grams คือการวิเคราะห์คำค้นหา
สคริปต์ n-grams python สำหรับ Google Ads มีคำแนะนำแบบเต็มเกี่ยวกับวิธีการเรียกใช้ แต่
เราจะพูดถึงวิธีการใช้ประโยชน์สูงสุดจากมัน
- คุณจะต้องติดตั้ง python บนเครื่องของคุณเพื่อเริ่มต้น ถ้าคุณไม่ทำ มันง่ายมาก คุณติดตั้งอนาคอนด้าก่อน จากนั้นเปิด Anaconda Prompt แล้วพิมพ์ 'conda install jupyter lab' Jupyter Lab คือสภาพแวดล้อมที่คุณจะเรียกใช้สคริปต์นี้
เพียงดาวน์โหลดรายงานคำค้นหาจาก Google Ads ของคุณ ขอแนะนำให้ตั้งค่าเป็นรายงานที่กำหนดเองในส่วน "รายงาน" ของ Google Ads คุณยังสามารถตั้งค่านี้ที่ระดับ MCC หากคุณต้องการเรียกใช้สคริปต์นี้ในหลายบัญชี

3. จากนั้นเพียงอัปเดตการตั้งค่าในสคริปต์เพื่อทำสิ่งที่คุณต้องการ และเรียกใช้เซลล์ทั้งหมด
จะใช้เวลาเล็กน้อยในการทำงาน แต่อดทนไว้ คุณจะเห็นความคืบหน้าได้รับการอัปเดตที่ด้านล่างเหมือนกับที่มันใช้เวทย์มนตร์
ผลลัพธ์จะปรากฏเป็นไฟล์ excel ภายในโฟลเดอร์ใดก็ตามที่คุณเรียกใช้สคริปต์ เราขอแนะนำให้ใช้โฟลเดอร์ดาวน์โหลด ไฟล์จะถูกติดป้ายกำกับด้วยชื่อใดๆ ที่คุณกำหนด
แต่ละแท็บของไฟล์ excel มีการวิเคราะห์ n-gram ที่แตกต่างกัน ตัวอย่างเช่น นี่คือการวิเคราะห์แบบไบกรัม:
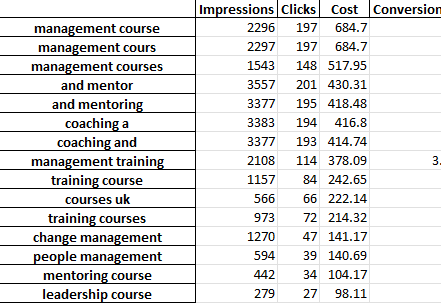
คุณสามารถใช้รายงานนี้เพื่อค้นหาการปรับปรุงได้หลายวิธี
คุณสามารถเริ่มต้นด้วยวลีการใช้จ่ายสูงสุดและดูค่าผิดปกติสำหรับ CPA หรือ ROAS
การกรองรายงานของคุณไปยังผู้ที่ไม่แปลงจะเน้นให้เห็นถึงการใช้จ่ายที่ไม่ดี
หากคุณเห็นตัวแปลงที่ไม่ดีในแท็บคำเดียว คุณสามารถตรวจสอบบริบทที่ใช้คำในแท็บ 3-Gram ได้อย่างง่ายดาย
ตัวอย่างเช่น ในบัญชีการฝึกอบรมแบบมืออาชีพ เราอาจพบว่า 'Oxford' ทำงานได้ไม่ดีอย่างสม่ำเสมอ แท็บ 3-Gram เผยอย่างรวดเร็วว่าผู้ใช้มักจะมองหาหลักสูตรที่เป็นทางการและเน้นไปที่มหาวิทยาลัย

คุณจึงสามารถลบคำนี้ออกได้อย่างรวดเร็ว
ท้ายที่สุด ใช้รายงานนี้แต่จะได้ผลดีที่สุดสำหรับคุณ
เพิ่มประสิทธิภาพฟีดผลิตภัณฑ์ด้วย n-grams
สคริปต์ n-grams ตัวที่สองสำหรับ Google Ads จะวิเคราะห์ประสิทธิภาพผลิตภัณฑ์ของคุณ
อีกครั้ง คุณสามารถค้นหาคำแนะนำแบบเต็มได้ภายในสคริปต์เอง
สคริปต์นี้จะพิจารณาประสิทธิภาพของวลีภายในชื่อผลิตภัณฑ์ของคุณ ท้ายที่สุดแล้ว ชื่อผลิตภัณฑ์เป็นตัวกำหนดว่าคำหลักใดที่คุณต้องการแสดง ชื่อเรื่องยังเป็นข้อความโฆษณาหลักของคุณอีกด้วย ชื่อเรื่องจึงมีความสำคัญอย่างไม่น่าเชื่อ
สคริปต์นี้ออกแบบมาเพื่อช่วยคุณค้นหาวลีที่เป็นไปได้ในชื่อเหล่านี้ ซึ่งคุณสามารถปรับเปลี่ยนเพื่อปรับปรุงประสิทธิภาพของคุณจาก Google Shopping

ดังที่คุณเห็นด้านบน ผลลัพธ์ของสคริปต์นี้แตกต่างกันเล็กน้อย เนื่องจาก API การรายงานของ Google มีข้อจำกัด คุณจึงไม่สามารถเข้าถึงเมตริกการแปลง (เช่น รายได้) ในขณะที่คุณอยู่ที่ระดับชื่อผลิตภัณฑ์
รายงานนี้จึงให้การนับผลิตภัณฑ์ การเข้าชมเฉลี่ย และสเปรด (ส่วนเบี่ยงเบนมาตรฐาน) ของวลีผลิตภัณฑ์
เนื่องจากรายงานนี้อิงตามการมองเห็น คุณสามารถใช้รายงานเพื่อระบุวลีที่มีแนวโน้มจะทำให้ผลิตภัณฑ์ของคุณมองเห็นได้ชัดเจนขึ้น จากนั้นคุณสามารถเพิ่มสิ่งเหล่านี้ลงในชื่อผลิตภัณฑ์ของคุณได้มากขึ้น

ตัวอย่างเช่น เราอาจพบวลีที่มีจำนวนการแสดงผลเฉลี่ยสูงมาก และปรากฏอยู่ในชื่อผลิตภัณฑ์หลายรายการ นอกจากนี้ยังมีค่าเบี่ยงเบนมาตรฐานต่ำ ซึ่งหมายความว่าไม่น่าจะมีผลิตภัณฑ์ที่น่าทึ่งเพียงชิ้นเดียวที่บิดเบือนตัวเลขของเราที่นี่
เราใช้เครื่องมือนี้เพื่อขยายการมองเห็นการช็อปปิ้งสำหรับลูกค้าอย่างมาก ลูกค้าขายสินค้าในขนาดต่างๆ หลายพันขนาด เช่น 8x10mm. ผู้คนยังซื้อขนาดเฉพาะที่ต้องการอีกด้วย
แต่ Google ไม่ค่อยเข้าใจรูปแบบการตั้งชื่อที่เป็นไปได้สำหรับการปรับขนาดนี้: การค้นหาเช่น 8 มม. x 10 มม., 8 x 10 มม., 8 มม. x 10 มม. ถือเป็นข้อความค้นหาที่แตกต่างกันเกือบทั้งหมด
ดังนั้นเราจึงใช้สคริปต์ n-grams เพื่อกำหนดรูปแบบการตั้งชื่อใดที่ทำให้ผลิตภัณฑ์ของเรามีทัศนวิสัยดีที่สุด
เราพบรายการที่ตรงกันที่สุดและทำการเปลี่ยนแปลงฟีดผลิตภัณฑ์ของเรา ด้วยเหตุนี้ การเข้าชมแคมเปญการช็อปปิ้งของลูกค้าจึงเพิ่มขึ้นกว่า 550% ในช่วงเดือนเดียว
การตั้งชื่อผลิตภัณฑ์มีความสำคัญและ n-grams สามารถช่วยคุณได้
สคริปต์ N-gram สำหรับ Google Ads
นี่คือสคริปต์ที่สมบูรณ์ทั้งสองฉบับ
สคริปต์ N-grams สำหรับคำค้นหาของ Google Ads
#!/usr/bin/env python #coding: utf-8 # Ayima N-Grams Script for Google Ads #Takes in SQR data and outputs data split into phrases of N length #Script produced by Ayima Limited (www.ayima.com) # 2022. This work is licensed under a CC BY SA 4.0 license (https://creativecommons.org/licenses/by-sa/4.0/). #Version 1.1 ### Instructions #Download an SQR from within the reports section of Google ads. #The report must contain the following metrics: #+ Search term #+ Campaign #+ Campaign state #+ Currency code #+ Impressions #+ Clicks #+ Cost #+ Conversions #+ Conv. value #Then, complete the setting section as instructed and run the whole script #The script may take some time. Ngrams are computationally difficult, particularly for larger accounts. But, give it enough time to run, and it will log if it is running correctly. ### Settings # First, enter the name of the file to run this script on # By default, the script only looks in the folder it is in for the file. So, place this script in your downloads folder for ease. file_name = "N-Grams input - SQR (2).csv" grams_to_run = [1,2,3] #What length phrases you want to retrieve for. Recommended is < 4 max. Longer phrases retrieves far more results. campaigns_to_exclude = "" #input strings contained by campaigns you want to EXCLUDE, separated by commas if multiple (eg "DSA,PLA"). Case Insensitive campaigns_to_include = "PLA" #input strings contained by campaigns you want to INCLUDE, separated by commas if multiple (eg "DSA,PLA"). Case Insensitive character_limit = 3 #minimum number of characters in an ngram eg to filter out "a" or "i". Will filter everything below this limit client_name = "SAMPLE CLIENT" #Client name, to label on the final file enabled_campaigns_only = False #True/False - Whether to only run the script for enabled campaigns impressions_column_name = "Impr." #Google consistently flip between different names for their impressions column. We think just to annoy us. This spelling was correct at time of writing brand_terms = ["BRAND_TERM_2", #Labels brand and non-brand search terms. You can add as many as you want. Case insensitive. If none, leave as [""] "BRAND_TERM_2"] #eg ["Adidas","Addidas"] ## The Script #### You should not need to make changes below here import pandas as pd from nltk import ngrams import numpy as np import time import re def read_file(file_name): #find the file format and import if file_name.strip().split('.')[-1] == "xlsx": return pd.read_excel(f"{file_name}",skiprows = 2, thousands =",") elif file_name.strip().split('.')[-1] == "csv": return pd.read_csv(f"{file_name}",skiprows = 2, thousands =",") df = read_file(file_name) def filter_campaigns(df, to_ex = campaigns_to_exclude,to_inc = campaigns_to_include): to_ex = to_ex.split(",") to_inc = to_inc.split(",") if to_inc != ['']: to_inc = [word.lower() for word in to_inc] df = df[df["Campaign"].str.lower().str.strip().str.contains('|'.join(to_inc))] if to_ex != ['']: to_ex = [word.lower() for word in to_ex] df = df[~df["Campaign"].str.lower().str.strip().str.contains('|'.join(to_ex))] if enabled_campaigns_only: try: df = df[df["Campaign state"].str.contains("Enabled")] except KeyError: print("Couldn't find 'Campaign state' column") return df def generate_ngrams(list_of_terms, n): """ Turns a list of search terms into a set of unique n-grams that appear within """ # Clean the terms up first and remove special characters/commas etc. #clean_terms = [] #for st in list_of_terms: #st = st.strip() #clean_terms.append(re.sub(r'[^a-zA-Z0-9\s]', '', st)) #split into grams unique_ngrams = set() for term in list_of_terms: grams = ngrams(term.split(" "), n) [unique_ngrams.add(gram) for gram in grams] all_grams = set([' '.join(tups) for tups in unique_ngrams]) if character_limit > 0: n_grams_list = [ngram for ngram in all_grams if len(ngram) > character_limit] return n_grams_list def _collect_stats(term): #Slice the dataframe to the terms at hand sliced_df = df[df["Search term"].str.match(fr'. {re.escape(term)}. ')] #add our metrics raw_data =list(np.sum(sliced_df[[impressions_column_name,"Clicks","Cost","Conversions","Conv. value"]])) return raw_data def _generate_metrics(df): #generate metrics try: df["CTR"] = df["Clicks"]/df[f"Impressions"] df["CVR"] = df["Conversions"]/df["Clicks"] df["CPC"] = df["Cost"]/df["Clicks"] df["ROAS"] = df[f"Conv. value"]/df["Cost"] df["CPA"] = df["Cost"]/df["Conversions"] except KeyError: print("Couldn't find a column") #replace infinites with NaN and replace with 0 df.replace([np.inf, -np.inf], np.nan, inplace=True) df.fillna(0, inplace= True) df.round(2) return df def build_ngrams_df(df, sq_column_name ,ngrams_list, character_limit = 0): """Takes in n-grams and df and returns df of those metrics df - dataframe in question sq_column_name - str. Name of the column containing search terms ngrams_list - list/set of unique ngrams, already generated character_limit - Words have to be over a certain length, useful for single word grams Outputs a dataframe """ #set up metrics lists to drop values array = [] raw_data = map(_collect_stats, ngrams_list) #stack into an array data = np.array(list(raw_data)) #turn the above into a dataframe columns = ["Impressions","Clicks","Cost","Conversions", "Conv. value"] ngrams_df = pd.DataFrame(columns= columns, data=data, index = list(ngrams_list), dtype = float) ngrams_ df.sort_values(by = "Cost", ascending = False, inplace = True) #calculate additional metrics and return return _generate_metrics(ngrams_df) def group_by_sqs(df): df = df.groupby("Search term", as_index = False).sum() return df df = group_by_sqs(df) def find_brand_terms(df, brand_terms = brand_terms): brand_terms = [str.lower(term) for term in brand_terms] st_brand_bool = [] for i, row in df.iterrows(): term = row["Search term"] #runs through the term and if any of our brand strings appear, labels the column brand if any([brand_term in term for brand_term in brand_terms]): st_brand_bool.append("Brand") else: st_brand_bool.append("Generic") return st_brand_bool df["Brand label"] = find_brand_terms(df) #This is necessary for larger search volumes to cut down the very outlier terms with extremely few searches i = 1 while len(df)> 40000: print(f"DF too long, at {len(df)} rows, filtering to impressions greater than {i}") df = df[df[impressions_column_name] > i] i+=1 writer = pd.ExcelWriter(f"Ayima N-Gram Script Output - {client_name} N-Grams.xlsx", engine='xlsxwriter') df.to_excel(writer, sheet_name='Raw Searches') for n in grams_to_run: print("Working on ",n, "-grams") n_grams = generate_ngrams(df["Search term"], n) print(f"Found {len(n_grams)} n_grams, building stats (may take some time)") n_gram_df = build_ngrams_df(df,"Search term", n_grams, character_limit) print("Adding to file") n_gram_df.to_excel(writer, sheet_name=f'{n}-Gram',) writer.close()สคริปต์ N-grams สำหรับวิเคราะห์ฟีดผลิตภัณฑ์
#!/usr/bin/env python #coding: utf-8 # N-Grams for Google Shopping #This script looks to find patterns and trends in product feed data for Google shopping. It will help you find what words and phrases have been performing best for you #Script produced by Ayima Limited (www.ayima.com) # 2022. This work is licensed under a CC BY SA 4.0 license (https://creativecommons.org/licenses/by-sa/4.0/). #Version 1.1 ## Instructions #Download an SQR from within the reports section of Google ads. #The report must contain the following metrics: #+ Item ID #+ Product title #+ Impressions #+ Clicks #Then, complete the setting section as instructed and run the whole script #The script may take some time. Ngrams are computationally difficult, particularly for larger accounts. But, give it enough time to run, and it will log if it is running correctly. ## Settings #First, enter the name of the file to run this script on #By default, the script only looks in the folder it is in for the file. So, place this script in your downloads folder for ease. file_name = "Product report for N-Grams (1).csv" grams_to_run = [1,2,3] #The number of words in a phrase to run this for (eg 3 = three-word phrases only) character_limit = 0 #Words have to be over a certain length, useful for single word grams to rule out tiny words/symbols title_column_name = "Product Title" #Name of our product title column desc_column_name = "" #Name of our product description column, if we have one file_label = "Sample Client Name" #The label you want to add to the output file (eg the client name, or the run date) impressions_column_name = "Impr." #Google consistently flip between different names for their impressions column. We think just to annoy us. This spelling was correct at time of writing client_name = "SAMPLE" ## The Script #### You should not need to make changes below here #First import all of the relevant modules/packages import pandas as pd from nltk import ngrams import numpy as np import time import re #import our data file def read_file(file_name): #find the file format and import if file_name.strip().split('.')[-1] == "xlsx": return pd.read_excel(f"{file_name}",skiprows = 2, thousands =",") elif file_name.strip().split('.')[-1] == "csv": return pd.read_csv(f"{file_name}",skiprows = 2, thousands =",")# df = read_file(file_name) df.head() def generate_ngrams(list_of_terms, n): """ Turns our list of product titles into a set of unique n-grams that appear within """ unique_ngrams = set() for term in list_of_terms: grams = ngrams(term.split(" "), n) [unique_ngrams.add(gram) for gram in grams if ' ' not in gram] ngrams_list = set([' '.join(tups) for tups in unique_ngrams]) return ngrams_list def _collect_stats(term): #Slice the dataframe to the terms at hand sliced_df = df[df[title_column_name].str.match(fr'. {re.escape(term)}. ')] #add our metrics raw_data = [len(sliced_df), #number of products np.sum(sliced_df[impressions_column_name]), #total impressions np.sum(sliced_df["Clicks"]), #total clicks np.mean(sliced_df[impressions_column_name]), #average number of impressions np.mean(sliced_df["Clicks"]), #average number of clicks np.median(sliced_df[impressions_column_name]), #median impressions np.std(sliced_df[impressions_column_name])] #standard deviation return raw_data def build_ngrams_df(df, title_column_name, ngrams_list, character_limit = 0, desc_column_name = ''): """ Takes in n-grams and df and returns df of those metrics df - our dataframe title_column_name - str. Name of the column containing product titles ngrams_list - list/set of unique ngrams, already generated character_limit - Words have to be over a certain length, useful for single word grams to rule out tiny words/symbols desc_column_name = str. Name of the column containing product descriptions, if applicable Outputs a dataframe """ #first cut it to only grams longer than our minimum if character_limit > 0: ngrams_list = [ngram for ngram in ngrams_list if len(ngram) > character_limit] raw_data = map(_collect_stats, ngrams_list) #stack into an array data = np.array(list(raw_data)) #data[np.isnan(data)] = 0 columns = ["Product Count","Impressions","Clicks","Avg. Impressions", "Avg. Clicks","Median Impressions","Spread (Standard Deviation)"] #turn the above into a dataframe ngrams_df = pd.DataFrame(columns= columns, data=data, index = list(ngrams_list)) #clean the dataframe and add other key metrics ngrams_df["CTR"] = ngrams_df["Clicks"]/ ngrams_df["Impressions"] ngrams_df.fillna(0, inplace=True) ngrams_df.round(2) ngrams_df[["Impressions","Clicks","Product Count"]] = ngrams_df[["Impressions","Clicks","Product Count"]].astype(int) ngrams_df.sort_values(by = "Avg. Impressions", ascending = False, inplace = True) return ngrams_df writer = pd.ExcelWriter(f"{client_name} Product Feed N-Grams.xlsx", engine='xlsxwriter') start_time = time.time() for n in grams_to_run: print("Working on ",n, "-grams") n_grams = generate_ngrams(df["Product Title"], n) print(f"Found {len(n_grams)} n_grams, building stats (may take some time)") n_gram_df = build_ngrams_df(df,"Product Title", n_grams, character_limit) print("Adding to file") n_gram_df.to_excel(writer, sheet_name=f'{n}-Gram',) time_taken = time.time() - start_time print("Took "+str(time_taken) + " Seconds") writer.close()คุณยังสามารถค้นหาเวอร์ชันที่อัปเดตของสคริปต์ n-grams บน github เพื่อดาวน์โหลด

สคริปต์เหล่านี้ได้รับอนุญาตภายใต้สัญญาอนุญาต Creative Commons BY SA 4.0 ซึ่งหมายความว่าคุณสามารถแบ่งปันและปรับเปลี่ยนได้อย่างอิสระ แต่เราขอแนะนำให้คุณแบ่งปันเวอร์ชันที่ปรับปรุงแล้วของคุณได้อย่างอิสระเพื่อให้ทุกคนใช้งานได้ N-grams มีประโยชน์เกินกว่าที่จะไม่แบ่งปัน
นี่เป็นเพียงหนึ่งในเครื่องมือ สคริปต์ และเทมเพลตฟรีมากมายที่เรามีให้สำหรับสมาชิกของ Ayima Insights Club คุณสามารถเรียนรู้เพิ่มเติมเกี่ยวกับ Insights Club และลงทะเบียนได้ฟรีที่นี่