
Google広告のn-grams用の無料のPythonスクリプト
公開: 2022-04-12N-gramは、Google広告やSEOでの検索クエリを分析するための重要な武器になる可能性があります。 そのため、製品フィードと検索クエリの両方で任意の長さのn-gramを分析するのに役立つ無料のPythonスクリプトを作成しました。 n-gramとは何か、n-gramを使用してGoogle広告を最適化する方法、特にGoogleショッピングについて説明します。 最後に、無料のn-gramスクリプトを使用してGoogle広告の結果を改善する方法を紹介します。
n-gramとは何ですか?
Nグラムは、長いテキスト本文から抽出されたN個の単語のフレーズです。 ここでの「N」は任意の数字に置き換えることができます。
たとえば、「猫がマットにジャンプした」のような文では、「猫がジャンプした」または「マット」は両方とも2グラム(または「バイグラム」)になります。
「猫がジャンプした」または「猫がジャンプした」は、どちらもこの文の3グラム(または「トリグラム」)の例です。
n-gramが検索クエリにどのように役立つか
N-gramは、特定のキーフレーズがさまざまな検索クエリに表示される可能性があるため、Google広告内の検索クエリの分析に役立ちます。
N-gramを使用すると、在庫全体にわたるこれらのフレーズの影響を分析できます。 したがって、これらを使用すると、大規模でより適切な決定と最適化を行うことができます。
それは私たちが一言の影響を理解することさえ可能にします。 たとえば、「無料」(「1グラム」)という単語を含む検索でパフォーマンスが低下した場合は、すべてのキャンペーンからその単語を除外することにします。
または、「パーソナライズされた」を含む検索クエリによる強力なパフォーマンスにより、専用のキャンペーンを作成するように促される場合があります。
N-gramは、Googleショッピングからの検索クエリを調べるのに特に役立ちます。
商品リスト広告のキーワードターゲティングは自動化されているため、何十万もの検索クエリを表示できます。 特に、非常に特殊な機能を備えた製品バリアントが多数ある場合。
N-gramsスクリプトを使用すると、その雑然としたフレーズを重要なフレーズに切り詰めることができます。
n-gramを使用した検索クエリの分析
n-gramの最初のユースケースは、検索クエリの分析です。
Google広告用のn-gramspythonスクリプトには、実行方法の完全な手順が含まれていますが、
それを最大限に活用する方法について説明します。
- 開始するには、Pythonをマシンにインストールする必要があります。 そうでなければ、それはとても簡単です。 最初にAnacondaをインストールします。 次に、Anaconda Promptを開き、「condainstalljupyterlab」と入力します。 Jupyter Labは、このスクリプトを実行する環境です。
Google広告から検索クエリレポートをダウンロードするだけです。 Google広告の[レポート]セクションでカスタムレポートとして設定することをお勧めします。 このスクリプトを複数のアカウントで実行する場合は、これをMCCレベルで設定することもできます。

3.次に、スクリプトの設定を更新して必要な処理を実行し、すべてのセルを実行します。
実行には少し時間がかかりますが、しばらくお待ちください。 魔法のように、進行状況が下部で更新されているのがわかります。
出力は、ダウンロードフォルダーを使用することをお勧めする、スクリプトを実行しているフォルダー内のExcelファイルとして表示されます。 ファイルには、定義した任意の名前のラベルが付けられます。
Excelファイルの各タブには、異なるn-gram分析が含まれています。 たとえば、バイグラム分析は次のとおりです。
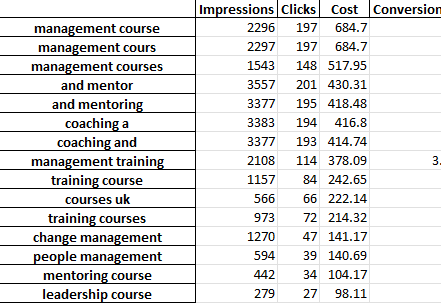
このレポートを使用して改善点を見つける方法はいくつかあります。
最も支出の多いフレーズから始めて、CPAまたはROASの外れ値を調べることができます。
非コンバーターへのレポートをフィルタリングすると、支出が少ない領域も強調表示されます。
[単一の単語]タブに不十分なコンバーターが表示されている場合は、[3グラム]タブでその単語が使用されているコンテキストを簡単に確認できます。
たとえば、専門的なトレーニングアカウントでは、「オックスフォード」のパフォーマンスが一貫して低いことに気付く場合があります。 [3-Gram]タブは、ユーザーがより正式な大学向けのコースを探している可能性が高いことをすぐに示します。
![[3-Gram]タブは、ユーザーがより正式な大学向けのコースを探している可能性が高いことをすぐに示します。](/uploads/article/52379/cYIzBX3sVVkBu8yO)
したがって、この言葉をすぐに否定することができます。
最終的には、このレポートを使用してください。
n-gramを使用した商品フィードの最適化
Google広告用の2番目のn-gramスクリプトは、製品のパフォーマンスを分析します。
繰り返しになりますが、スクリプト自体の中に完全な指示を見つけることができます
このスクリプトは、製品タイトル内のフレーズのパフォーマンスを調べます。 結局のところ、製品タイトルは、どのキーワードを表示するかを大部分決定します。 タイトルは、主要な広告コピーでもあります。 したがって、タイトルは非常に重要です。
このスクリプトは、これらのタイトル内の潜在的なフレーズを見つけるのに役立つように設計されており、Googleショッピングのパフォーマンスを向上させるために適応させることができます。

上記のように、このスクリプトの出力は少し異なります。 GoogleのレポートAPIには制限があるため、商品タイトルレベルでは、コンバージョン指標(収益など)にアクセスできません。
したがって、このレポートには、製品数、平均トラフィック、および製品フレーズの広がり(標準偏差)が表示されます。
可視性に基づいているため、レポートを使用して、製品をより見やすくする可能性のあるフレーズを特定できます。 その後、これらをより多くの製品タイトルに追加できます。

たとえば、平均インプレッション数が非常に多く、いくつかの商品のタイトルに表示されるフレーズを見つけることができます。 また、標準偏差も低くなっています。つまり、ここで数値を歪めている驚くべき製品が1つだけ存在する可能性は低いということです。
このツールを使用して、クライアントのショッピングの可視性を劇的に拡大しました。 クライアントは何千もの異なるサイズの製品を販売しました。 たとえば、8x10mm。 人々はまた、彼らが必要とする非常に特定のサイズを買い求めていました。
しかし、Googleは、このサイズ設定で考えられるさまざまな命名規則を理解するのが苦手でした。8mmx 10mm、8 x 10mm、8mm x 10mmなどの検索はすべて、ほぼ完全に異なる検索クエリとして扱われていました。
したがって、n-gramsスクリプトを使用して、これらの命名規則のどれが製品に最高の可視性を与えるかを判断しました。
最適なものを見つけて、商品フィードに変更を加えました。 その結果、クライアントのショッピングキャンペーンへのトラフィックは、1か月の間に550%以上増加しました。
製品の命名の問題とn-gramはそれを助けることができます。
Google広告のNグラムスクリプト
これが両方の完全なスクリプトです。
Google広告検索クエリ用のN-gramスクリプト
#!/usr/bin/env python #coding: utf-8 # Ayima N-Grams Script for Google Ads #Takes in SQR data and outputs data split into phrases of N length #Script produced by Ayima Limited (www.ayima.com) # 2022. This work is licensed under a CC BY SA 4.0 license (https://creativecommons.org/licenses/by-sa/4.0/). #Version 1.1 ### Instructions #Download an SQR from within the reports section of Google ads. #The report must contain the following metrics: #+ Search term #+ Campaign #+ Campaign state #+ Currency code #+ Impressions #+ Clicks #+ Cost #+ Conversions #+ Conv. value #Then, complete the setting section as instructed and run the whole script #The script may take some time. Ngrams are computationally difficult, particularly for larger accounts. But, give it enough time to run, and it will log if it is running correctly. ### Settings # First, enter the name of the file to run this script on # By default, the script only looks in the folder it is in for the file. So, place this script in your downloads folder for ease. file_name = "N-Grams input - SQR (2).csv" grams_to_run = [1,2,3] #What length phrases you want to retrieve for. Recommended is < 4 max. Longer phrases retrieves far more results. campaigns_to_exclude = "" #input strings contained by campaigns you want to EXCLUDE, separated by commas if multiple (eg "DSA,PLA"). Case Insensitive campaigns_to_include = "PLA" #input strings contained by campaigns you want to INCLUDE, separated by commas if multiple (eg "DSA,PLA"). Case Insensitive character_limit = 3 #minimum number of characters in an ngram eg to filter out "a" or "i". Will filter everything below this limit client_name = "SAMPLE CLIENT" #Client name, to label on the final file enabled_campaigns_only = False #True/False - Whether to only run the script for enabled campaigns impressions_column_name = "Impr." #Google consistently flip between different names for their impressions column. We think just to annoy us. This spelling was correct at time of writing brand_terms = ["BRAND_TERM_2", #Labels brand and non-brand search terms. You can add as many as you want. Case insensitive. If none, leave as [""] "BRAND_TERM_2"] #eg ["Adidas","Addidas"] ## The Script #### You should not need to make changes below here import pandas as pd from nltk import ngrams import numpy as np import time import re def read_file(file_name): #find the file format and import if file_name.strip().split('.')[-1] == "xlsx": return pd.read_excel(f"{file_name}",skiprows = 2, thousands =",") elif file_name.strip().split('.')[-1] == "csv": return pd.read_csv(f"{file_name}",skiprows = 2, thousands =",") df = read_file(file_name) def filter_campaigns(df, to_ex = campaigns_to_exclude,to_inc = campaigns_to_include): to_ex = to_ex.split(",") to_inc = to_inc.split(",") if to_inc != ['']: to_inc = [word.lower() for word in to_inc] df = df[df["Campaign"].str.lower().str.strip().str.contains('|'.join(to_inc))] if to_ex != ['']: to_ex = [word.lower() for word in to_ex] df = df[~df["Campaign"].str.lower().str.strip().str.contains('|'.join(to_ex))] if enabled_campaigns_only: try: df = df[df["Campaign state"].str.contains("Enabled")] except KeyError: print("Couldn't find 'Campaign state' column") return df def generate_ngrams(list_of_terms, n): """ Turns a list of search terms into a set of unique n-grams that appear within """ # Clean the terms up first and remove special characters/commas etc. #clean_terms = [] #for st in list_of_terms: #st = st.strip() #clean_terms.append(re.sub(r'[^a-zA-Z0-9\s]', '', st)) #split into grams unique_ngrams = set() for term in list_of_terms: grams = ngrams(term.split(" "), n) [unique_ngrams.add(gram) for gram in grams] all_grams = set([' '.join(tups) for tups in unique_ngrams]) if character_limit > 0: n_grams_list = [ngram for ngram in all_grams if len(ngram) > character_limit] return n_grams_list def _collect_stats(term): #Slice the dataframe to the terms at hand sliced_df = df[df["Search term"].str.match(fr'. {re.escape(term)}. ')] #add our metrics raw_data =list(np.sum(sliced_df[[impressions_column_name,"Clicks","Cost","Conversions","Conv. value"]])) return raw_data def _generate_metrics(df): #generate metrics try: df["CTR"] = df["Clicks"]/df[f"Impressions"] df["CVR"] = df["Conversions"]/df["Clicks"] df["CPC"] = df["Cost"]/df["Clicks"] df["ROAS"] = df[f"Conv. value"]/df["Cost"] df["CPA"] = df["Cost"]/df["Conversions"] except KeyError: print("Couldn't find a column") #replace infinites with NaN and replace with 0 df.replace([np.inf, -np.inf], np.nan, inplace=True) df.fillna(0, inplace= True) df.round(2) return df def build_ngrams_df(df, sq_column_name ,ngrams_list, character_limit = 0): """Takes in n-grams and df and returns df of those metrics df - dataframe in question sq_column_name - str. Name of the column containing search terms ngrams_list - list/set of unique ngrams, already generated character_limit - Words have to be over a certain length, useful for single word grams Outputs a dataframe """ #set up metrics lists to drop values array = [] raw_data = map(_collect_stats, ngrams_list) #stack into an array data = np.array(list(raw_data)) #turn the above into a dataframe columns = ["Impressions","Clicks","Cost","Conversions", "Conv. value"] ngrams_df = pd.DataFrame(columns= columns, data=data, index = list(ngrams_list), dtype = float) ngrams_ df.sort_values(by = "Cost", ascending = False, inplace = True) #calculate additional metrics and return return _generate_metrics(ngrams_df) def group_by_sqs(df): df = df.groupby("Search term", as_index = False).sum() return df df = group_by_sqs(df) def find_brand_terms(df, brand_terms = brand_terms): brand_terms = [str.lower(term) for term in brand_terms] st_brand_bool = [] for i, row in df.iterrows(): term = row["Search term"] #runs through the term and if any of our brand strings appear, labels the column brand if any([brand_term in term for brand_term in brand_terms]): st_brand_bool.append("Brand") else: st_brand_bool.append("Generic") return st_brand_bool df["Brand label"] = find_brand_terms(df) #This is necessary for larger search volumes to cut down the very outlier terms with extremely few searches i = 1 while len(df)> 40000: print(f"DF too long, at {len(df)} rows, filtering to impressions greater than {i}") df = df[df[impressions_column_name] > i] i+=1 writer = pd.ExcelWriter(f"Ayima N-Gram Script Output - {client_name} N-Grams.xlsx", engine='xlsxwriter') df.to_excel(writer, sheet_name='Raw Searches') for n in grams_to_run: print("Working on ",n, "-grams") n_grams = generate_ngrams(df["Search term"], n) print(f"Found {len(n_grams)} n_grams, building stats (may take some time)") n_gram_df = build_ngrams_df(df,"Search term", n_grams, character_limit) print("Adding to file") n_gram_df.to_excel(writer, sheet_name=f'{n}-Gram',) writer.close()商品フィードを分析するためのN-gramスクリプト
#!/usr/bin/env python #coding: utf-8 # N-Grams for Google Shopping #This script looks to find patterns and trends in product feed data for Google shopping. It will help you find what words and phrases have been performing best for you #Script produced by Ayima Limited (www.ayima.com) # 2022. This work is licensed under a CC BY SA 4.0 license (https://creativecommons.org/licenses/by-sa/4.0/). #Version 1.1 ## Instructions #Download an SQR from within the reports section of Google ads. #The report must contain the following metrics: #+ Item ID #+ Product title #+ Impressions #+ Clicks #Then, complete the setting section as instructed and run the whole script #The script may take some time. Ngrams are computationally difficult, particularly for larger accounts. But, give it enough time to run, and it will log if it is running correctly. ## Settings #First, enter the name of the file to run this script on #By default, the script only looks in the folder it is in for the file. So, place this script in your downloads folder for ease. file_name = "Product report for N-Grams (1).csv" grams_to_run = [1,2,3] #The number of words in a phrase to run this for (eg 3 = three-word phrases only) character_limit = 0 #Words have to be over a certain length, useful for single word grams to rule out tiny words/symbols title_column_name = "Product Title" #Name of our product title column desc_column_name = "" #Name of our product description column, if we have one file_label = "Sample Client Name" #The label you want to add to the output file (eg the client name, or the run date) impressions_column_name = "Impr." #Google consistently flip between different names for their impressions column. We think just to annoy us. This spelling was correct at time of writing client_name = "SAMPLE" ## The Script #### You should not need to make changes below here #First import all of the relevant modules/packages import pandas as pd from nltk import ngrams import numpy as np import time import re #import our data file def read_file(file_name): #find the file format and import if file_name.strip().split('.')[-1] == "xlsx": return pd.read_excel(f"{file_name}",skiprows = 2, thousands =",") elif file_name.strip().split('.')[-1] == "csv": return pd.read_csv(f"{file_name}",skiprows = 2, thousands =",")# df = read_file(file_name) df.head() def generate_ngrams(list_of_terms, n): """ Turns our list of product titles into a set of unique n-grams that appear within """ unique_ngrams = set() for term in list_of_terms: grams = ngrams(term.split(" "), n) [unique_ngrams.add(gram) for gram in grams if ' ' not in gram] ngrams_list = set([' '.join(tups) for tups in unique_ngrams]) return ngrams_list def _collect_stats(term): #Slice the dataframe to the terms at hand sliced_df = df[df[title_column_name].str.match(fr'. {re.escape(term)}. ')] #add our metrics raw_data = [len(sliced_df), #number of products np.sum(sliced_df[impressions_column_name]), #total impressions np.sum(sliced_df["Clicks"]), #total clicks np.mean(sliced_df[impressions_column_name]), #average number of impressions np.mean(sliced_df["Clicks"]), #average number of clicks np.median(sliced_df[impressions_column_name]), #median impressions np.std(sliced_df[impressions_column_name])] #standard deviation return raw_data def build_ngrams_df(df, title_column_name, ngrams_list, character_limit = 0, desc_column_name = ''): """ Takes in n-grams and df and returns df of those metrics df - our dataframe title_column_name - str. Name of the column containing product titles ngrams_list - list/set of unique ngrams, already generated character_limit - Words have to be over a certain length, useful for single word grams to rule out tiny words/symbols desc_column_name = str. Name of the column containing product descriptions, if applicable Outputs a dataframe """ #first cut it to only grams longer than our minimum if character_limit > 0: ngrams_list = [ngram for ngram in ngrams_list if len(ngram) > character_limit] raw_data = map(_collect_stats, ngrams_list) #stack into an array data = np.array(list(raw_data)) #data[np.isnan(data)] = 0 columns = ["Product Count","Impressions","Clicks","Avg. Impressions", "Avg. Clicks","Median Impressions","Spread (Standard Deviation)"] #turn the above into a dataframe ngrams_df = pd.DataFrame(columns= columns, data=data, index = list(ngrams_list)) #clean the dataframe and add other key metrics ngrams_df["CTR"] = ngrams_df["Clicks"]/ ngrams_df["Impressions"] ngrams_df.fillna(0, inplace=True) ngrams_df.round(2) ngrams_df[["Impressions","Clicks","Product Count"]] = ngrams_df[["Impressions","Clicks","Product Count"]].astype(int) ngrams_df.sort_values(by = "Avg. Impressions", ascending = False, inplace = True) return ngrams_df writer = pd.ExcelWriter(f"{client_name} Product Feed N-Grams.xlsx", engine='xlsxwriter') start_time = time.time() for n in grams_to_run: print("Working on ",n, "-grams") n_grams = generate_ngrams(df["Product Title"], n) print(f"Found {len(n_grams)} n_grams, building stats (may take some time)") n_gram_df = build_ngrams_df(df,"Product Title", n_grams, character_limit) print("Adding to file") n_gram_df.to_excel(writer, sheet_name=f'{n}-Gram',) time_taken = time.time() - start_time print("Took "+str(time_taken) + " Seconds") writer.close()githubでn-gramsスクリプトの更新バージョンをダウンロードして見つけることもできます。

これらのスクリプトは、Creative Commons BY SA 4.0ライセンスの下でライセンスされています。つまり、自由に共有および適合させることができますが、改善されたバージョンを誰もが使用できるように常に自由に共有することをお勧めします。 Nグラムは共有できないほど便利です。
これは、Ayima Insights Clubのメンバーが利用できる多くの無料ツール、スクリプト、およびテンプレートの1つにすぎません。 Insights Clubの詳細については、こちらから無料で登録できます。