
Google Ads n-gramları için Ücretsiz Python Komut Dosyası
Yayınlanan: 2022-04-12N-gramlar, Google Ads veya SEO'daki arama sorgularını analiz etmek için önemli bir silah olabilir. Bu nedenle, hem ürün özet akışınızda hem de arama sorgularınızda herhangi bir uzunluktaki n-gramları analiz etmenize yardımcı olacak ücretsiz bir python betiği oluşturduk. N-gram'ın ne olduğunu ve özellikle Google Alışveriş için Google Ads'ünüzü optimize etmek için n-gramların nasıl kullanılacağını açıklayacağız. Sonunda, Google Ads sonuçlarınızı iyileştirmek için ücretsiz n-gram komut dosyamızı nasıl kullanacağınızı göstereceğiz.
n-gram nedir?
N-gramlar, daha uzun metin gövdelerinden çıkarılan N sayıda kelimeden oluşan ifadelerdir. Buradaki 'N' herhangi bir sayı ile değiştirilebilir.
Örneğin, "kedi mindere atladı", "kedi atladı" veya "mat" gibi bir cümlede her ikisi de 2 gram (veya 'bi-gram') olacaktır.
"Kedi atladı" veya "kedi atladı", bu cümleden 3 gram (veya 'üç gram') örnekleridir.
N-gram arama sorgularına nasıl yardımcı olur?
Belirli anahtar kelime öbekleri birçok farklı arama sorgusunda görünebileceğinden, N-gram'lar Google Ads'deki arama sorgularını analiz etmede kullanışlıdır.
N-gramlar, bu ifadelerin tüm envanteriniz üzerindeki etkisini analiz etmemize izin verir. Bu nedenle, ölçekte daha iyi kararlar ve optimizasyonlar yapmanızı sağlarlar.
Hatta tek kelimelerin etkisini anlamamızı sağlar. Örneğin, "ücretsiz" ("1 gram") kelimesini içeren aramalarda zayıf bir performans gördüyseniz, tüm kampanyalardan bu kelimeyi negatif çıkarmaya karar verebilirsiniz.
Veya "kişiselleştirilmiş" arama sorgularından elde edilen güçlü performans, sizi özel bir kampanya oluşturmaya teşvik edebilir.
N-gram'lar özellikle Google Alışveriş'teki arama sorgularına bakmak için kullanışlıdır.
Ürün Listeleme Reklamları anahtar kelime hedeflemesinin otomatik yapısı, yüz binlerce arama sorgusu için karşınıza çıkabileceğiniz anlamına gelir. Özellikle çok özel özelliklere sahip çok sayıda ürün çeşidiniz olduğunda.
N-gram komut dosyamız, bu karmaşayı ortadan kaldırarak önemli ifadelere ulaşmanızı sağlar.
Arama Sorgularını n-gramlarla Analiz Etme
n-gramlar için ilk kullanım durumu, arama sorgularını analiz etmektir.
Google Ads için n-gram python komut dosyamız, nasıl çalıştırılacağına ilişkin tüm talimatları içerir, ancak
bundan en iyi şekilde nasıl yararlanabileceğimizi ele alacağız.
- Başlamak için makinenizde python kurulu olması gerekir. Eğer yapmazsan, çok kolay. Önce Anaconda'yı kurarsınız. Ardından, Anaconda İstemi'ni açın ve 'conda install jupyter lab' yazın. Jupyter Lab, bu betiği çalıştıracağınız ortamdır.
Google Ads'inizden bir arama sorgusu raporu indirmeniz yeterlidir. Bunu, Google Ads'ün "raporlar" bölümünde özel bir rapor olarak ayarlamanızı öneririz. Bu komut dosyasını birden fazla hesapta çalıştırmak istiyorsanız, bunu MM düzeyinde bile ayarlayabilirsiniz.

3. Ardından, istediğinizi yapmak için komut dosyasındaki ayarları güncelleyin ve tüm hücreleri çalıştırın.
Koşmak biraz zaman alacak, ancak sabırlı olun. Sihrini yaparken en altta ilerlemenin güncellendiğini göreceksiniz.
Çıktı, betiği çalıştırdığınız klasörde bir excel dosyası olarak görünecektir, indirmeler klasörünü kullanmanızı öneririz. Dosya, tanımladığınız herhangi bir adla etiketlenecektir.
Excel dosyasının her sekmesi farklı bir n-gram analizi içerir. Örneğin, işte bir bi-gram analizi:
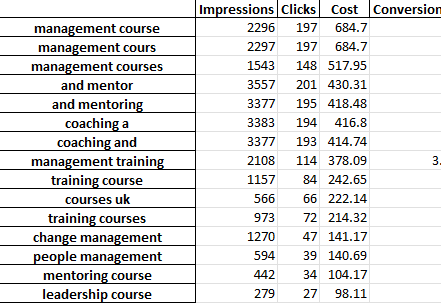
İyileştirmeleri bulmak için bu raporu kullanmanın birkaç yolu vardır.
En yüksek harcama ifadeleriyle başlayabilir ve EBM veya ROAS için herhangi bir aykırı değere bakabilirsiniz.
Raporlarınızı dönüşüm sağlamayanlara göre filtrelemek, aynı zamanda yetersiz harcama alanlarını da vurgulayacaktır.
Tek kelimeler sekmesinde zayıf dönüştürücüler görürseniz, 3-Gram sekmesinde kelimelerin hangi bağlamda kullanıldığını kolayca kontrol edebilirsiniz.
Örneğin, profesyonel bir eğitim hesabında, 'Oxford'un sürekli olarak düşük performans gösterdiğini görebiliriz. 3-Gram sekmesi, kullanıcıların daha resmi, üniversite odaklı bir kurs aradıklarını hemen ortaya koyuyor.

Bu nedenle, bu kelimeyi hızlı bir şekilde olumsuzlayabilirsiniz.
Sonuç olarak, bu raporu sizin için en uygun şekilde kullanın.
Ürün beslemelerini n-gram ile optimize etme
Google Ads için ikinci n-gram komut dosyamız, ürün performansınızı analiz eder.
Yine, komut dosyasının kendisinde tüm talimatları bulabilirsiniz.
Bu komut dosyası, ürün başlıklarınızdaki ifadelerin performansına bakar. Ne de olsa ürün başlığı, hangi anahtar kelimeleri gösterdiğinizi büyük ölçüde belirler. Başlık aynı zamanda birincil reklam kopyanızdır. Bu nedenle başlıklar inanılmaz derecede önemlidir.
Komut dosyası, Google Alışveriş'teki performansınızı artırmak için uyarlayabileceğiniz bu başlıklardaki olası ifadeleri bulmanıza yardımcı olmak için tasarlanmıştır.

Yukarıda görebileceğiniz gibi, bu betiğin çıktısı biraz farklıdır. Google'ın raporlama API'sindeki sınırlamalar nedeniyle, ürün başlığı düzeyindeyken dönüşüm metriklerine (gelir gibi) erişemezsiniz.
Bu nedenle bu rapor size ürün sayılarını, ortalama trafiği ve ürün ifadelerinin dağılımını (standart sapma) verir.
Görünürlüğe dayalı olduğu için, ürünlerinizi daha görünür kılma olasılığı olan ifadeleri belirlemek için raporu kullanabilirsiniz. Daha sonra bunları daha fazla ürün başlığınıza ekleyebilirsiniz.

Örneğin, ortalama gösterim sayısı çok yüksek olan ve birkaç ürünün başlığında görünen bir kelime öbeği bulabiliriz. Aynı zamanda düşük bir standart sapmaya sahiptir - bu, burada rakamlarımızı çarpıtan tek bir harika ürün olması muhtemel olmadığı anlamına gelir.
Bu aracı, bir müşteri için alışveriş görünürlüğünü önemli ölçüde genişletmek için kullandık. Müşteri binlerce farklı boyutta ürün sattı. Örneğin 8x10mm. İnsanlar ayrıca ihtiyaç duydukları çok özel bedenler için alışveriş yapıyorlardı.
Ancak Google, bu boyutlandırma için olası farklı adlandırma kurallarını anlamada başarısız oldu: 8 mm x 10 mm, 8 x 10 mm, 8 mm x 10 mm gibi aramaların tümü, neredeyse tamamen farklı arama sorguları olarak değerlendiriliyordu.
Bu nedenle, bu adlandırma kurallarından hangisinin ürünlerimize en iyi görünürlüğü sağladığını belirlemek için n-gram komut dosyamızı kullandık.
En iyi eşleşmeyi bulduk ve ürün feed'imizde değişiklikleri yaptık. Sonuç olarak, müşterinin alışveriş kampanyalarına gelen trafik, tek bir ay boyunca %550'nin üzerinde arttı.
Ürün adlandırma konuları ve n-gramlar bu konuda size yardımcı olabilir.
Google Ads için N-gram komut dosyaları
İşte tam komut dosyalarının ikisi.
Google Ads arama sorguları için N-gram komut dosyası
#!/usr/bin/env python #coding: utf-8 # Ayima N-Grams Script for Google Ads #Takes in SQR data and outputs data split into phrases of N length #Script produced by Ayima Limited (www.ayima.com) # 2022. This work is licensed under a CC BY SA 4.0 license (https://creativecommons.org/licenses/by-sa/4.0/). #Version 1.1 ### Instructions #Download an SQR from within the reports section of Google ads. #The report must contain the following metrics: #+ Search term #+ Campaign #+ Campaign state #+ Currency code #+ Impressions #+ Clicks #+ Cost #+ Conversions #+ Conv. value #Then, complete the setting section as instructed and run the whole script #The script may take some time. Ngrams are computationally difficult, particularly for larger accounts. But, give it enough time to run, and it will log if it is running correctly. ### Settings # First, enter the name of the file to run this script on # By default, the script only looks in the folder it is in for the file. So, place this script in your downloads folder for ease. file_name = "N-Grams input - SQR (2).csv" grams_to_run = [1,2,3] #What length phrases you want to retrieve for. Recommended is < 4 max. Longer phrases retrieves far more results. campaigns_to_exclude = "" #input strings contained by campaigns you want to EXCLUDE, separated by commas if multiple (eg "DSA,PLA"). Case Insensitive campaigns_to_include = "PLA" #input strings contained by campaigns you want to INCLUDE, separated by commas if multiple (eg "DSA,PLA"). Case Insensitive character_limit = 3 #minimum number of characters in an ngram eg to filter out "a" or "i". Will filter everything below this limit client_name = "SAMPLE CLIENT" #Client name, to label on the final file enabled_campaigns_only = False #True/False - Whether to only run the script for enabled campaigns impressions_column_name = "Impr." #Google consistently flip between different names for their impressions column. We think just to annoy us. This spelling was correct at time of writing brand_terms = ["BRAND_TERM_2", #Labels brand and non-brand search terms. You can add as many as you want. Case insensitive. If none, leave as [""] "BRAND_TERM_2"] #eg ["Adidas","Addidas"] ## The Script #### You should not need to make changes below here import pandas as pd from nltk import ngrams import numpy as np import time import re def read_file(file_name): #find the file format and import if file_name.strip().split('.')[-1] == "xlsx": return pd.read_excel(f"{file_name}",skiprows = 2, thousands =",") elif file_name.strip().split('.')[-1] == "csv": return pd.read_csv(f"{file_name}",skiprows = 2, thousands =",") df = read_file(file_name) def filter_campaigns(df, to_ex = campaigns_to_exclude,to_inc = campaigns_to_include): to_ex = to_ex.split(",") to_inc = to_inc.split(",") if to_inc != ['']: to_inc = [word.lower() for word in to_inc] df = df[df["Campaign"].str.lower().str.strip().str.contains('|'.join(to_inc))] if to_ex != ['']: to_ex = [word.lower() for word in to_ex] df = df[~df["Campaign"].str.lower().str.strip().str.contains('|'.join(to_ex))] if enabled_campaigns_only: try: df = df[df["Campaign state"].str.contains("Enabled")] except KeyError: print("Couldn't find 'Campaign state' column") return df def generate_ngrams(list_of_terms, n): """ Turns a list of search terms into a set of unique n-grams that appear within """ # Clean the terms up first and remove special characters/commas etc. #clean_terms = [] #for st in list_of_terms: #st = st.strip() #clean_terms.append(re.sub(r'[^a-zA-Z0-9\s]', '', st)) #split into grams unique_ngrams = set() for term in list_of_terms: grams = ngrams(term.split(" "), n) [unique_ngrams.add(gram) for gram in grams] all_grams = set([' '.join(tups) for tups in unique_ngrams]) if character_limit > 0: n_grams_list = [ngram for ngram in all_grams if len(ngram) > character_limit] return n_grams_list def _collect_stats(term): #Slice the dataframe to the terms at hand sliced_df = df[df["Search term"].str.match(fr'. {re.escape(term)}. ')] #add our metrics raw_data =list(np.sum(sliced_df[[impressions_column_name,"Clicks","Cost","Conversions","Conv. value"]])) return raw_data def _generate_metrics(df): #generate metrics try: df["CTR"] = df["Clicks"]/df[f"Impressions"] df["CVR"] = df["Conversions"]/df["Clicks"] df["CPC"] = df["Cost"]/df["Clicks"] df["ROAS"] = df[f"Conv. value"]/df["Cost"] df["CPA"] = df["Cost"]/df["Conversions"] except KeyError: print("Couldn't find a column") #replace infinites with NaN and replace with 0 df.replace([np.inf, -np.inf], np.nan, inplace=True) df.fillna(0, inplace= True) df.round(2) return df def build_ngrams_df(df, sq_column_name ,ngrams_list, character_limit = 0): """Takes in n-grams and df and returns df of those metrics df - dataframe in question sq_column_name - str. Name of the column containing search terms ngrams_list - list/set of unique ngrams, already generated character_limit - Words have to be over a certain length, useful for single word grams Outputs a dataframe """ #set up metrics lists to drop values array = [] raw_data = map(_collect_stats, ngrams_list) #stack into an array data = np.array(list(raw_data)) #turn the above into a dataframe columns = ["Impressions","Clicks","Cost","Conversions", "Conv. value"] ngrams_df = pd.DataFrame(columns= columns, data=data, index = list(ngrams_list), dtype = float) ngrams_ df.sort_values(by = "Cost", ascending = False, inplace = True) #calculate additional metrics and return return _generate_metrics(ngrams_df) def group_by_sqs(df): df = df.groupby("Search term", as_index = False).sum() return df df = group_by_sqs(df) def find_brand_terms(df, brand_terms = brand_terms): brand_terms = [str.lower(term) for term in brand_terms] st_brand_bool = [] for i, row in df.iterrows(): term = row["Search term"] #runs through the term and if any of our brand strings appear, labels the column brand if any([brand_term in term for brand_term in brand_terms]): st_brand_bool.append("Brand") else: st_brand_bool.append("Generic") return st_brand_bool df["Brand label"] = find_brand_terms(df) #This is necessary for larger search volumes to cut down the very outlier terms with extremely few searches i = 1 while len(df)> 40000: print(f"DF too long, at {len(df)} rows, filtering to impressions greater than {i}") df = df[df[impressions_column_name] > i] i+=1 writer = pd.ExcelWriter(f"Ayima N-Gram Script Output - {client_name} N-Grams.xlsx", engine='xlsxwriter') df.to_excel(writer, sheet_name='Raw Searches') for n in grams_to_run: print("Working on ",n, "-grams") n_grams = generate_ngrams(df["Search term"], n) print(f"Found {len(n_grams)} n_grams, building stats (may take some time)") n_gram_df = build_ngrams_df(df,"Search term", n_grams, character_limit) print("Adding to file") n_gram_df.to_excel(writer, sheet_name=f'{n}-Gram',) writer.close()Ürün feed'lerini analiz etmek için N-gram komut dosyası
#!/usr/bin/env python #coding: utf-8 # N-Grams for Google Shopping #This script looks to find patterns and trends in product feed data for Google shopping. It will help you find what words and phrases have been performing best for you #Script produced by Ayima Limited (www.ayima.com) # 2022. This work is licensed under a CC BY SA 4.0 license (https://creativecommons.org/licenses/by-sa/4.0/). #Version 1.1 ## Instructions #Download an SQR from within the reports section of Google ads. #The report must contain the following metrics: #+ Item ID #+ Product title #+ Impressions #+ Clicks #Then, complete the setting section as instructed and run the whole script #The script may take some time. Ngrams are computationally difficult, particularly for larger accounts. But, give it enough time to run, and it will log if it is running correctly. ## Settings #First, enter the name of the file to run this script on #By default, the script only looks in the folder it is in for the file. So, place this script in your downloads folder for ease. file_name = "Product report for N-Grams (1).csv" grams_to_run = [1,2,3] #The number of words in a phrase to run this for (eg 3 = three-word phrases only) character_limit = 0 #Words have to be over a certain length, useful for single word grams to rule out tiny words/symbols title_column_name = "Product Title" #Name of our product title column desc_column_name = "" #Name of our product description column, if we have one file_label = "Sample Client Name" #The label you want to add to the output file (eg the client name, or the run date) impressions_column_name = "Impr." #Google consistently flip between different names for their impressions column. We think just to annoy us. This spelling was correct at time of writing client_name = "SAMPLE" ## The Script #### You should not need to make changes below here #First import all of the relevant modules/packages import pandas as pd from nltk import ngrams import numpy as np import time import re #import our data file def read_file(file_name): #find the file format and import if file_name.strip().split('.')[-1] == "xlsx": return pd.read_excel(f"{file_name}",skiprows = 2, thousands =",") elif file_name.strip().split('.')[-1] == "csv": return pd.read_csv(f"{file_name}",skiprows = 2, thousands =",")# df = read_file(file_name) df.head() def generate_ngrams(list_of_terms, n): """ Turns our list of product titles into a set of unique n-grams that appear within """ unique_ngrams = set() for term in list_of_terms: grams = ngrams(term.split(" "), n) [unique_ngrams.add(gram) for gram in grams if ' ' not in gram] ngrams_list = set([' '.join(tups) for tups in unique_ngrams]) return ngrams_list def _collect_stats(term): #Slice the dataframe to the terms at hand sliced_df = df[df[title_column_name].str.match(fr'. {re.escape(term)}. ')] #add our metrics raw_data = [len(sliced_df), #number of products np.sum(sliced_df[impressions_column_name]), #total impressions np.sum(sliced_df["Clicks"]), #total clicks np.mean(sliced_df[impressions_column_name]), #average number of impressions np.mean(sliced_df["Clicks"]), #average number of clicks np.median(sliced_df[impressions_column_name]), #median impressions np.std(sliced_df[impressions_column_name])] #standard deviation return raw_data def build_ngrams_df(df, title_column_name, ngrams_list, character_limit = 0, desc_column_name = ''): """ Takes in n-grams and df and returns df of those metrics df - our dataframe title_column_name - str. Name of the column containing product titles ngrams_list - list/set of unique ngrams, already generated character_limit - Words have to be over a certain length, useful for single word grams to rule out tiny words/symbols desc_column_name = str. Name of the column containing product descriptions, if applicable Outputs a dataframe """ #first cut it to only grams longer than our minimum if character_limit > 0: ngrams_list = [ngram for ngram in ngrams_list if len(ngram) > character_limit] raw_data = map(_collect_stats, ngrams_list) #stack into an array data = np.array(list(raw_data)) #data[np.isnan(data)] = 0 columns = ["Product Count","Impressions","Clicks","Avg. Impressions", "Avg. Clicks","Median Impressions","Spread (Standard Deviation)"] #turn the above into a dataframe ngrams_df = pd.DataFrame(columns= columns, data=data, index = list(ngrams_list)) #clean the dataframe and add other key metrics ngrams_df["CTR"] = ngrams_df["Clicks"]/ ngrams_df["Impressions"] ngrams_df.fillna(0, inplace=True) ngrams_df.round(2) ngrams_df[["Impressions","Clicks","Product Count"]] = ngrams_df[["Impressions","Clicks","Product Count"]].astype(int) ngrams_df.sort_values(by = "Avg. Impressions", ascending = False, inplace = True) return ngrams_df writer = pd.ExcelWriter(f"{client_name} Product Feed N-Grams.xlsx", engine='xlsxwriter') start_time = time.time() for n in grams_to_run: print("Working on ",n, "-grams") n_grams = generate_ngrams(df["Product Title"], n) print(f"Found {len(n_grams)} n_grams, building stats (may take some time)") n_gram_df = build_ngrams_df(df,"Product Title", n_grams, character_limit) print("Adding to file") n_gram_df.to_excel(writer, sheet_name=f'{n}-Gram',) time_taken = time.time() - start_time print("Took "+str(time_taken) + " Seconds") writer.close()Ayrıca indirmek için github'da n-grams betiğinin güncellenmiş sürümlerini bulabilirsiniz.

Bu komut dosyaları Creative Commons BY SA 4.0 lisansı altında lisanslanmıştır, yani onu paylaşmakta ve uyarlamakta özgürsünüz, ancak herkesin kullanması için geliştirilmiş sürümlerinizi her zaman özgürce paylaşmanızı öneririz. N-gramlar paylaşılmayacak kadar faydalıdır.
Bu, Ayima Insights Club üyelerine sunduğumuz birçok ücretsiz araç, komut dosyası ve şablondan yalnızca biridir. Insights Club hakkında daha fazla bilgi edinebilir ve buradan ücretsiz üye olabilirsiniz.