
Darmowy skrypt Pythona dla n-gramów Google Ads
Opublikowany: 2022-04-12N-gramy mogą być potężną bronią do analizy zapytań w Google Ads lub SEO. Dlatego opracowaliśmy darmowy skrypt Pythona, który pomoże Ci analizować n-gramy o dowolnej długości zarówno w pliku danych o produktach, jak i zapytaniach. Wyjaśnimy, czym są n-gramy i jak używać n-gramów do optymalizacji reklam Google Ads, szczególnie w Zakupach Google. W końcu pokażemy Ci, jak korzystać z naszego bezpłatnego skryptu n-grams, aby poprawić wyniki w Google Ads.
Czym są n-gramy?
N-gramy to frazy o liczbie N słów, wyciągnięte z dłuższych części tekstu. Tutaj „N” można zastąpić dowolną liczbą.
Na przykład w zdaniu takim jak „kot skoczył na matę”, „kot skoczył” lub „mata” miałyby 2 gramy (lub „bi-gramy”).
„Kot skoczył” lub „kot wskoczył” to przykłady 3 gramów (lub „trigramów”) z tego zdania.
Jak n-gramy pomagają w wyszukiwaniu zapytań
N-gramy są przydatne w analizowaniu wyszukiwanych haseł w Google Ads, ponieważ określone frazy kluczowe mogą pojawiać się w wielu różnych wyszukiwanych hasłach.
N-gramy pozwalają nam przeanalizować wpływ tych fraz na cały Twój asortyment. Pozwalają zatem podejmować lepsze decyzje i optymalizacje na dużą skalę.
Pozwala nam nawet zrozumieć wpływ pojedynczych słów. Jeśli na przykład zauważysz słabą skuteczność wyszukiwań zawierających słowo „bezpłatne” („1 gram”), możesz wykluczyć to słowo ze wszystkich kampanii.
Lub wysoka skuteczność dzięki zapytaniom zawierającym „spersonalizowane” może zachęcić Cię do zbudowania dedykowanej kampanii.
N-gramy są szczególnie przydatne do wyszukiwania zapytań z Zakupów Google.
Zautomatyzowany charakter kierowania na słowa kluczowe reklam z listą produktów oznacza, że możesz wyświetlić setki tysięcy zapytań. Szczególnie w przypadku dużej liczby wariantów produktów o bardzo specyficznych cechach.
Nasz skrypt N-gramów pozwala przebić się przez ten bałagan do fraz, które mają znaczenie.
Analiza zapytań wyszukiwania za pomocą n-gramów
Pierwszym przypadkiem użycia n-gramów jest analiza zapytań wyszukiwania.
Nasz skrypt n-grams Pythona dla Google Ads zawiera pełne instrukcje, jak go uruchomić, ale
omówimy, jak najlepiej to wykorzystać.
- Aby rozpocząć, musisz mieć zainstalowanego Pythona na swoim komputerze. Jeśli nie, to bardzo proste. Najpierw instalujesz Anacondę. Następnie otwórz Anaconda Prompt i wpisz „conda install jupyter lab”. Jupyter Lab to środowisko, w którym uruchomisz ten skrypt.
Po prostu pobierz raport wyszukiwanych haseł z Google Ads. Zalecamy skonfigurowanie go jako raportu niestandardowego w sekcji „raporty” Google Ads. Możesz nawet skonfigurować to na poziomie MCK, jeśli chcesz uruchomić ten skrypt na wielu kontach.

3. Następnie po prostu zaktualizuj ustawienia w skrypcie, aby zrobić to, co chcesz, i uruchom wszystkie komórki.
Bieganie zajmie trochę czasu, ale bądź cierpliwy. Zobaczysz postępy aktualizowane na dole, ponieważ robi to swoją magię.
Dane wyjściowe pojawią się jako plik Excela w dowolnym folderze, w którym uruchamiasz skrypt, sugerujemy użycie folderu pobierania. Plik zostanie oznaczony dowolną nazwą, którą określisz.
Każda zakładka pliku Excel zawiera inną analizę n-gramów. Na przykład, oto analiza bigramowa:
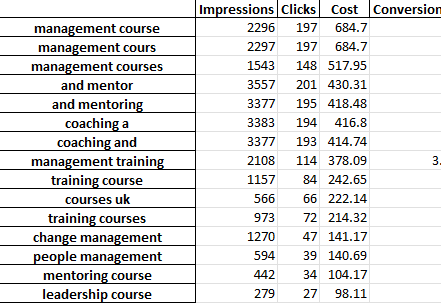
Istnieje kilka sposobów wykorzystania tego raportu w celu znalezienia ulepszeń.
Możesz zacząć od fraz o najwyższych wydatkach i przyjrzeć się wartościom odstającym dla CPA lub ROAS.
Filtrowanie raportów do osób, które nie dokonały konwersji, pozwoli również wskazać obszary o niskich wydatkach.
Jeśli widzisz słabe konwertery w zakładce pojedynczych słów, możesz łatwo sprawdzić, w jakim kontekście słowa są używane w zakładce 3-gramów.
Na przykład na profesjonalnym koncie szkoleniowym możemy zauważyć, że „Oxford” stale osiąga słabe wyniki. Zakładka 3 gramy szybko pokazuje, że użytkownicy prawdopodobnie będą szukać bardziej formalnego kursu uniwersyteckiego.

Możesz więc szybko odrzucić to słowo.
Ostatecznie skorzystaj z tego raportu, jednak działa on najlepiej dla Ciebie.
Optymalizacja feedów produktowych za pomocą n-gramów
Nasz drugi skrypt n-grams dla Google Ads analizuje skuteczność Twojego produktu.
Ponownie, pełne instrukcje można znaleźć w samym skrypcie
Ten skrypt analizuje działanie fraz w tytułach produktów. Tytuł produktu w dużej mierze determinuje bowiem, na jakie słowa kluczowe się wyświetlasz. Tytuł jest także Twoim podstawowym tekstem reklamy. Tytuły są zatem niezwykle ważne.
Skrypt został zaprojektowany, aby pomóc Ci znaleźć potencjalne frazy w tych tytułach, które możesz dostosować, aby poprawić swoje wyniki w Zakupach Google.

Jak widać powyżej, wynik działania tego skryptu jest nieco inny. Z powodu ograniczeń interfejsu API raportowania Google nie możesz uzyskać dostępu do danych konwersji (takich jak przychody), gdy jesteś na poziomie tytułu produktu.
Dlatego raport ten podaje liczbę produktów, średni ruch i rozrzut (odchylenie standardowe) fraz produktowych.
Ponieważ opiera się na widoczności, możesz wykorzystać raport do identyfikacji fraz, które mogą sprawić, że Twoje produkty będą bardziej widoczne. Następnie możesz dodać je do kolejnych tytułów produktów.

Na przykład możemy znaleźć frazę z bardzo dużą liczbą średnich wyświetleń, która pojawia się w tytule kilku produktów. Ma również niskie odchylenie standardowe - co oznacza, że prawdopodobnie nie będzie tylko jednego niesamowitego produktu, który wypacza nasze liczby.
Wykorzystaliśmy to narzędzie, aby radykalnie zwiększyć widoczność zakupów dla klienta. Klient sprzedawał produkty w tysiącach różnych rozmiarów. Na przykład 8x10mm. Ludzie kupowali również bardzo konkretne rozmiary, których potrzebowali.
Jednak Google źle zrozumiał różne możliwe konwencje nazewnictwa dla tego rozmiaru: wyszukiwania takie jak 8 mm na 10 mm, 8 x 10 mm, 8 mm x 10 mm były traktowane jako prawie całkowicie różne zapytania wyszukiwania.
Dlatego użyliśmy naszego skryptu n-grams, aby określić, która z tych konwencji nazewnictwa zapewniła naszym produktom najlepszą widoczność.
Znaleźliśmy najlepsze dopasowanie i wprowadziliśmy zmiany w naszym pliku danych o produktach. W efekcie ruch do kampanii zakupowych klienta wzrósł w ciągu miesiąca o ponad 550% .
Nazewnictwo produktów ma znaczenie, a n-gramy mogą Ci w tym pomóc.
Skrypty N-gramowe dla Google Ads
Oto oba kompletne skrypty.
Skrypt N-gramów dla zapytań Google Ads
#!/usr/bin/env python #coding: utf-8 # Ayima N-Grams Script for Google Ads #Takes in SQR data and outputs data split into phrases of N length #Script produced by Ayima Limited (www.ayima.com) # 2022. This work is licensed under a CC BY SA 4.0 license (https://creativecommons.org/licenses/by-sa/4.0/). #Version 1.1 ### Instructions #Download an SQR from within the reports section of Google ads. #The report must contain the following metrics: #+ Search term #+ Campaign #+ Campaign state #+ Currency code #+ Impressions #+ Clicks #+ Cost #+ Conversions #+ Conv. value #Then, complete the setting section as instructed and run the whole script #The script may take some time. Ngrams are computationally difficult, particularly for larger accounts. But, give it enough time to run, and it will log if it is running correctly. ### Settings # First, enter the name of the file to run this script on # By default, the script only looks in the folder it is in for the file. So, place this script in your downloads folder for ease. file_name = "N-Grams input - SQR (2).csv" grams_to_run = [1,2,3] #What length phrases you want to retrieve for. Recommended is < 4 max. Longer phrases retrieves far more results. campaigns_to_exclude = "" #input strings contained by campaigns you want to EXCLUDE, separated by commas if multiple (eg "DSA,PLA"). Case Insensitive campaigns_to_include = "PLA" #input strings contained by campaigns you want to INCLUDE, separated by commas if multiple (eg "DSA,PLA"). Case Insensitive character_limit = 3 #minimum number of characters in an ngram eg to filter out "a" or "i". Will filter everything below this limit client_name = "SAMPLE CLIENT" #Client name, to label on the final file enabled_campaigns_only = False #True/False - Whether to only run the script for enabled campaigns impressions_column_name = "Impr." #Google consistently flip between different names for their impressions column. We think just to annoy us. This spelling was correct at time of writing brand_terms = ["BRAND_TERM_2", #Labels brand and non-brand search terms. You can add as many as you want. Case insensitive. If none, leave as [""] "BRAND_TERM_2"] #eg ["Adidas","Addidas"] ## The Script #### You should not need to make changes below here import pandas as pd from nltk import ngrams import numpy as np import time import re def read_file(file_name): #find the file format and import if file_name.strip().split('.')[-1] == "xlsx": return pd.read_excel(f"{file_name}",skiprows = 2, thousands =",") elif file_name.strip().split('.')[-1] == "csv": return pd.read_csv(f"{file_name}",skiprows = 2, thousands =",") df = read_file(file_name) def filter_campaigns(df, to_ex = campaigns_to_exclude,to_inc = campaigns_to_include): to_ex = to_ex.split(",") to_inc = to_inc.split(",") if to_inc != ['']: to_inc = [word.lower() for word in to_inc] df = df[df["Campaign"].str.lower().str.strip().str.contains('|'.join(to_inc))] if to_ex != ['']: to_ex = [word.lower() for word in to_ex] df = df[~df["Campaign"].str.lower().str.strip().str.contains('|'.join(to_ex))] if enabled_campaigns_only: try: df = df[df["Campaign state"].str.contains("Enabled")] except KeyError: print("Couldn't find 'Campaign state' column") return df def generate_ngrams(list_of_terms, n): """ Turns a list of search terms into a set of unique n-grams that appear within """ # Clean the terms up first and remove special characters/commas etc. #clean_terms = [] #for st in list_of_terms: #st = st.strip() #clean_terms.append(re.sub(r'[^a-zA-Z0-9\s]', '', st)) #split into grams unique_ngrams = set() for term in list_of_terms: grams = ngrams(term.split(" "), n) [unique_ngrams.add(gram) for gram in grams] all_grams = set([' '.join(tups) for tups in unique_ngrams]) if character_limit > 0: n_grams_list = [ngram for ngram in all_grams if len(ngram) > character_limit] return n_grams_list def _collect_stats(term): #Slice the dataframe to the terms at hand sliced_df = df[df["Search term"].str.match(fr'. {re.escape(term)}. ')] #add our metrics raw_data =list(np.sum(sliced_df[[impressions_column_name,"Clicks","Cost","Conversions","Conv. value"]])) return raw_data def _generate_metrics(df): #generate metrics try: df["CTR"] = df["Clicks"]/df[f"Impressions"] df["CVR"] = df["Conversions"]/df["Clicks"] df["CPC"] = df["Cost"]/df["Clicks"] df["ROAS"] = df[f"Conv. value"]/df["Cost"] df["CPA"] = df["Cost"]/df["Conversions"] except KeyError: print("Couldn't find a column") #replace infinites with NaN and replace with 0 df.replace([np.inf, -np.inf], np.nan, inplace=True) df.fillna(0, inplace= True) df.round(2) return df def build_ngrams_df(df, sq_column_name ,ngrams_list, character_limit = 0): """Takes in n-grams and df and returns df of those metrics df - dataframe in question sq_column_name - str. Name of the column containing search terms ngrams_list - list/set of unique ngrams, already generated character_limit - Words have to be over a certain length, useful for single word grams Outputs a dataframe """ #set up metrics lists to drop values array = [] raw_data = map(_collect_stats, ngrams_list) #stack into an array data = np.array(list(raw_data)) #turn the above into a dataframe columns = ["Impressions","Clicks","Cost","Conversions", "Conv. value"] ngrams_df = pd.DataFrame(columns= columns, data=data, index = list(ngrams_list), dtype = float) ngrams_ df.sort_values(by = "Cost", ascending = False, inplace = True) #calculate additional metrics and return return _generate_metrics(ngrams_df) def group_by_sqs(df): df = df.groupby("Search term", as_index = False).sum() return df df = group_by_sqs(df) def find_brand_terms(df, brand_terms = brand_terms): brand_terms = [str.lower(term) for term in brand_terms] st_brand_bool = [] for i, row in df.iterrows(): term = row["Search term"] #runs through the term and if any of our brand strings appear, labels the column brand if any([brand_term in term for brand_term in brand_terms]): st_brand_bool.append("Brand") else: st_brand_bool.append("Generic") return st_brand_bool df["Brand label"] = find_brand_terms(df) #This is necessary for larger search volumes to cut down the very outlier terms with extremely few searches i = 1 while len(df)> 40000: print(f"DF too long, at {len(df)} rows, filtering to impressions greater than {i}") df = df[df[impressions_column_name] > i] i+=1 writer = pd.ExcelWriter(f"Ayima N-Gram Script Output - {client_name} N-Grams.xlsx", engine='xlsxwriter') df.to_excel(writer, sheet_name='Raw Searches') for n in grams_to_run: print("Working on ",n, "-grams") n_grams = generate_ngrams(df["Search term"], n) print(f"Found {len(n_grams)} n_grams, building stats (may take some time)") n_gram_df = build_ngrams_df(df,"Search term", n_grams, character_limit) print("Adding to file") n_gram_df.to_excel(writer, sheet_name=f'{n}-Gram',) writer.close()Skrypt N-gramów do analizy feedów produktowych
#!/usr/bin/env python #coding: utf-8 # N-Grams for Google Shopping #This script looks to find patterns and trends in product feed data for Google shopping. It will help you find what words and phrases have been performing best for you #Script produced by Ayima Limited (www.ayima.com) # 2022. This work is licensed under a CC BY SA 4.0 license (https://creativecommons.org/licenses/by-sa/4.0/). #Version 1.1 ## Instructions #Download an SQR from within the reports section of Google ads. #The report must contain the following metrics: #+ Item ID #+ Product title #+ Impressions #+ Clicks #Then, complete the setting section as instructed and run the whole script #The script may take some time. Ngrams are computationally difficult, particularly for larger accounts. But, give it enough time to run, and it will log if it is running correctly. ## Settings #First, enter the name of the file to run this script on #By default, the script only looks in the folder it is in for the file. So, place this script in your downloads folder for ease. file_name = "Product report for N-Grams (1).csv" grams_to_run = [1,2,3] #The number of words in a phrase to run this for (eg 3 = three-word phrases only) character_limit = 0 #Words have to be over a certain length, useful for single word grams to rule out tiny words/symbols title_column_name = "Product Title" #Name of our product title column desc_column_name = "" #Name of our product description column, if we have one file_label = "Sample Client Name" #The label you want to add to the output file (eg the client name, or the run date) impressions_column_name = "Impr." #Google consistently flip between different names for their impressions column. We think just to annoy us. This spelling was correct at time of writing client_name = "SAMPLE" ## The Script #### You should not need to make changes below here #First import all of the relevant modules/packages import pandas as pd from nltk import ngrams import numpy as np import time import re #import our data file def read_file(file_name): #find the file format and import if file_name.strip().split('.')[-1] == "xlsx": return pd.read_excel(f"{file_name}",skiprows = 2, thousands =",") elif file_name.strip().split('.')[-1] == "csv": return pd.read_csv(f"{file_name}",skiprows = 2, thousands =",")# df = read_file(file_name) df.head() def generate_ngrams(list_of_terms, n): """ Turns our list of product titles into a set of unique n-grams that appear within """ unique_ngrams = set() for term in list_of_terms: grams = ngrams(term.split(" "), n) [unique_ngrams.add(gram) for gram in grams if ' ' not in gram] ngrams_list = set([' '.join(tups) for tups in unique_ngrams]) return ngrams_list def _collect_stats(term): #Slice the dataframe to the terms at hand sliced_df = df[df[title_column_name].str.match(fr'. {re.escape(term)}. ')] #add our metrics raw_data = [len(sliced_df), #number of products np.sum(sliced_df[impressions_column_name]), #total impressions np.sum(sliced_df["Clicks"]), #total clicks np.mean(sliced_df[impressions_column_name]), #average number of impressions np.mean(sliced_df["Clicks"]), #average number of clicks np.median(sliced_df[impressions_column_name]), #median impressions np.std(sliced_df[impressions_column_name])] #standard deviation return raw_data def build_ngrams_df(df, title_column_name, ngrams_list, character_limit = 0, desc_column_name = ''): """ Takes in n-grams and df and returns df of those metrics df - our dataframe title_column_name - str. Name of the column containing product titles ngrams_list - list/set of unique ngrams, already generated character_limit - Words have to be over a certain length, useful for single word grams to rule out tiny words/symbols desc_column_name = str. Name of the column containing product descriptions, if applicable Outputs a dataframe """ #first cut it to only grams longer than our minimum if character_limit > 0: ngrams_list = [ngram for ngram in ngrams_list if len(ngram) > character_limit] raw_data = map(_collect_stats, ngrams_list) #stack into an array data = np.array(list(raw_data)) #data[np.isnan(data)] = 0 columns = ["Product Count","Impressions","Clicks","Avg. Impressions", "Avg. Clicks","Median Impressions","Spread (Standard Deviation)"] #turn the above into a dataframe ngrams_df = pd.DataFrame(columns= columns, data=data, index = list(ngrams_list)) #clean the dataframe and add other key metrics ngrams_df["CTR"] = ngrams_df["Clicks"]/ ngrams_df["Impressions"] ngrams_df.fillna(0, inplace=True) ngrams_df.round(2) ngrams_df[["Impressions","Clicks","Product Count"]] = ngrams_df[["Impressions","Clicks","Product Count"]].astype(int) ngrams_df.sort_values(by = "Avg. Impressions", ascending = False, inplace = True) return ngrams_df writer = pd.ExcelWriter(f"{client_name} Product Feed N-Grams.xlsx", engine='xlsxwriter') start_time = time.time() for n in grams_to_run: print("Working on ",n, "-grams") n_grams = generate_ngrams(df["Product Title"], n) print(f"Found {len(n_grams)} n_grams, building stats (may take some time)") n_gram_df = build_ngrams_df(df,"Product Title", n_grams, character_limit) print("Adding to file") n_gram_df.to_excel(writer, sheet_name=f'{n}-Gram',) time_taken = time.time() - start_time print("Took "+str(time_taken) + " Seconds") writer.close()Możesz również znaleźć zaktualizowane wersje skryptu n-grams na github do pobrania.

Skrypty te są objęte licencją Creative Commons BY SA 4.0, co oznacza, że możesz je swobodnie udostępniać i dostosowywać, ale zachęcamy Cię do swobodnego udostępniania swoich ulepszonych wersji, aby każdy mógł z nich korzystać. N-gramy są zbyt przydatne, by ich nie udostępniać.
To tylko jedno z wielu darmowych narzędzi, skryptów i szablonów, które udostępniamy członkom Ayima Insights Club. Możesz dowiedzieć się więcej o Insights Club i bezpłatnie zarejestrować się tutaj.