
برنامج Python Script لإعلانات Google n-grams
نشرت: 2022-04-12يمكن أن تكون N-grams سلاحًا مهمًا لتحليل استعلامات البحث على إعلانات Google أو تحسين محركات البحث. لذلك ، قمنا بإنتاج نص برمجي مجاني من Python لمساعدتك في تحليل n-grams بأي طول عبر كلٍ من موجز المنتج واستعلامات البحث الخاصة بك. سنشرح ماهية n-grams وكيفية استخدام n-grams لتحسين إعلانات Google ، خاصةً بالنسبة إلى Google Shopping. سنبين لك أخيرًا كيفية استخدام برنامج n-grams المجاني لتحسين نتائج إعلانات Google.
ما هي n-grams؟
N-grams عبارة عن عبارات لعدد N من الكلمات ، مأخوذة من نصوص أطول. يمكن استبدال "N" بأي رقم.
على سبيل المثال ، في جملة مثل "قفز القطة على السجادة" ، سيكون كل من "قفز القطة" أو "حصيرة" كلاهما 2 جرام (أو "ثنائي جرام").
"القطة قفز" أو "قفزت القطة" مثالان على 3 جرامات (أو ثلاث جرامات) من هذه الجملة.
كيف تساعد n-grams استعلامات البحث
تُعد N-grams مفيدة في تحليل استعلامات البحث داخل إعلانات Google لأن بعض العبارات الأساسية يمكن أن تظهر في العديد من استعلامات البحث المختلفة.
تتيح لنا N-grams تحليل تأثير هذه العبارات عبر مخزونك بالكامل. وبالتالي ، فهي تتيح لك اتخاذ قرارات وتحسينات أفضل على نطاق واسع.
حتى أنه يسمح لنا بفهم تأثير الكلمات المفردة. على سبيل المثال ، إذا لاحظت أداءً ضعيفًا من خلال عمليات البحث التي تحتوي على كلمة "مجاني" ("1 جرام") ، فقد تقرر استبعاد هذه الكلمة من جميع الحملات.
أو قد يشجعك الأداء القوي من خلال استعلامات البحث التي تحتوي على "مخصصة" على إنشاء حملة مخصصة.
تعتبر N-grams مفيدة بشكل خاص للنظر في استعلامات البحث من Google Shopping.
تعني الطبيعة التلقائية لاستهداف الكلمات الرئيسية لإعلانات قائمة المنتجات أنه يمكنك الظهور لمئات الآلاف من استعلامات البحث. خاصة عندما يكون لديك عدد كبير من متغيرات المنتجات بميزات محددة للغاية.
يتيح لك البرنامج النصي N-grams اختراق هذه الفوضى للوصول إلى العبارات المهمة.
تحليل استعلامات البحث باستخدام n-grams
أول حالة استخدام لـ n-grams هي تحليل استعلامات البحث.
يحتوي سكربت python من n-grams لإعلانات Google على إرشادات كاملة حول كيفية تشغيله ، ولكن
سنستعرض كيفية تحقيق أقصى استفادة منه.
- ستحتاج إلى تثبيت Python على جهازك للبدء. إذا لم تفعل ، فالأمر سهل للغاية. قمت أولاً بتثبيت Anaconda. ثم افتح Anaconda Prompt واكتب "conda install jupyter lab". Jupyter Lab هي البيئة التي ستقوم فيها بتشغيل هذا البرنامج النصي.
ما عليك سوى تنزيل تقرير استعلام البحث من إعلانات Google. نوصي بإعداده كتقرير مخصص في قسم "التقارير" في إعلانات Google. يمكنك حتى إعداد هذا على مستوى مركز عملائي إذا كنت ترغب في تشغيل هذا النص البرمجي عبر حسابات متعددة.

3. بعد ذلك ، ما عليك سوى تحديث الإعدادات في البرنامج النصي للقيام بما تريد ، وتشغيل جميع الخلايا.
سيستغرق الجري بعض الوقت ، لكن تحلى بالصبر. سترى تقدمًا يتم تحديثه في الأسفل لأنه يفعل سحره.
سيظهر الإخراج كملف excel داخل أي مجلد تقوم بتشغيل البرنامج النصي فيه نقترح استخدام مجلد التنزيلات. سيتم تسمية الملف بأي اسم تحدده.
تحتوي كل علامة تبويب في ملف Excel على تحليل n-gram مختلف. على سبيل المثال ، إليك تحليل ثنائي الجرام:
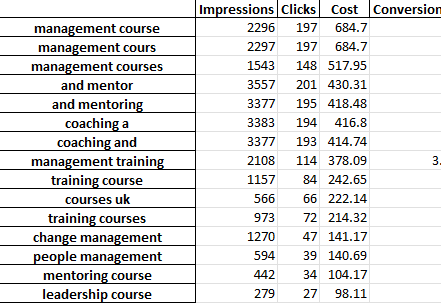
هناك عدد من الطرق التي يمكنك من خلالها استخدام هذا التقرير للعثور على التحسينات.
يمكنك البدء بأعلى عبارات الإنفاق وإلقاء نظرة على القيم المتطرفة لتكلفة الاكتساب أو عائد النفقات الإعلانية.
ستؤدي تصفية تقاريرك إلى غير المحولين أيضًا إلى إبراز مجالات الإنفاق الضعيف.
إذا رأيت محولات ضعيفة في علامة تبويب الكلمات المفردة ، فيمكنك بسهولة التحقق من السياق الذي يتم استخدام الكلمات فيه في علامة التبويب 3 جرام.
على سبيل المثال ، في حساب تدريب احترافي ، قد نلاحظ أن أداء "أكسفورد" ضعيف باستمرار. تكشف علامة التبويب 3-Gram بسرعة أنه من المحتمل أن يبحث المستخدمون عن دورة تدريبية أكثر رسمية وموجهة نحو الجامعة.

لذلك يمكنك استبعاد هذه الكلمة بسرعة.
في النهاية ، استخدم هذا التقرير على الرغم من أنه يعمل بشكل أفضل بالنسبة لك.
تحسين تغذية المنتج باستخدام n-grams
يحلل البرنامج النصي الثاني من نوع n-grams لبرنامج إعلانات Google أداء منتجك.
مرة أخرى ، يمكنك العثور على تعليمات كاملة داخل البرنامج النصي نفسه
يبحث هذا البرنامج النصي في أداء العبارات في عناوين منتجك. بعد كل شيء ، يحدد عنوان المنتج إلى حد كبير الكلمات الرئيسية التي تظهر من أجلها. العنوان هو أيضًا نسختك الإعلانية الأساسية. لذلك فإن الألقاب مهمة للغاية.
تم تصميم البرنامج النصي لمساعدتك في العثور على عبارات محتملة داخل هذه العناوين والتي يمكنك تكييفها لتحسين أدائك من Google Shopping.

كما ترى أعلاه ، فإن إخراج هذا البرنامج النصي مختلف قليلاً. نظرًا للقيود المفروضة على واجهة برمجة التطبيقات لإعداد التقارير من Google ، لا يمكنك الوصول إلى مقاييس التحويل (مثل الإيرادات) بينما تكون في مستوى عنوان المنتج.
لذلك ، يمنحك هذا التقرير عدد المنتجات ، ومتوسط حركة المرور ، وانتشار عبارات المنتج (الانحراف المعياري).
نظرًا لأنه يعتمد على الرؤية ، يمكنك استخدام التقرير لتحديد العبارات التي من المحتمل أن تجعل منتجاتك أكثر وضوحًا. يمكنك بعد ذلك إضافة هذه إلى المزيد من عناوين المنتجات الخاصة بك.

على سبيل المثال ، قد نجد عبارة تحتوي على عدد كبير جدًا من متوسط مرات الظهور وتظهر ضمن عنوان العديد من المنتجات. كما أن لها انحرافًا معياريًا منخفضًا - مما يعني أنه من غير المحتمل أن يكون هناك منتج واحد مذهل يحرف أرقامنا هنا.
استخدمنا هذه الأداة لتوسيع نطاق رؤية التسوق للعميل بشكل كبير. باع العميل المنتجات بآلاف الأحجام المختلفة. على سبيل المثال 8x10mm. كان الناس يتسوقون أيضًا للحصول على أحجام محددة جدًا يحتاجون إليها.
لكن ، كان Google سيئًا في فهم اصطلاحات التسمية المختلفة الممكنة لهذا الحجم: تم التعامل مع عمليات البحث مثل 8 مم في 10 مم و 8 × 10 مم و 8 مم × 10 مم على أنها استعلامات بحث مختلفة تمامًا تقريبًا.
لذلك ، استخدمنا البرنامج النصي n-grams لتحديد أي من اصطلاحات التسمية هذه أعطت منتجاتنا أفضل رؤية.
وجدنا أفضل تطابق وأجرينا التغييرات على خلاصة منتجاتنا. نتيجةً لذلك ، ارتفع عدد الزيارات إلى حملات التسوق الخاصة بالعميل بنسبة تزيد عن 550٪ على مدار شهر واحد.
تسمية المنتج مهمة ويمكن أن تساعدك n-grams في ذلك.
نصوص N-gram لبرنامج إعلانات Google
هنا كلا من النصوص الكاملة.
نص برمجي N-grams لطلبات بحث إعلانات Google
#!/usr/bin/env python #coding: utf-8 # Ayima N-Grams Script for Google Ads #Takes in SQR data and outputs data split into phrases of N length #Script produced by Ayima Limited (www.ayima.com) # 2022. This work is licensed under a CC BY SA 4.0 license (https://creativecommons.org/licenses/by-sa/4.0/). #Version 1.1 ### Instructions #Download an SQR from within the reports section of Google ads. #The report must contain the following metrics: #+ Search term #+ Campaign #+ Campaign state #+ Currency code #+ Impressions #+ Clicks #+ Cost #+ Conversions #+ Conv. value #Then, complete the setting section as instructed and run the whole script #The script may take some time. Ngrams are computationally difficult, particularly for larger accounts. But, give it enough time to run, and it will log if it is running correctly. ### Settings # First, enter the name of the file to run this script on # By default, the script only looks in the folder it is in for the file. So, place this script in your downloads folder for ease. file_name = "N-Grams input - SQR (2).csv" grams_to_run = [1,2,3] #What length phrases you want to retrieve for. Recommended is < 4 max. Longer phrases retrieves far more results. campaigns_to_exclude = "" #input strings contained by campaigns you want to EXCLUDE, separated by commas if multiple (eg "DSA,PLA"). Case Insensitive campaigns_to_include = "PLA" #input strings contained by campaigns you want to INCLUDE, separated by commas if multiple (eg "DSA,PLA"). Case Insensitive character_limit = 3 #minimum number of characters in an ngram eg to filter out "a" or "i". Will filter everything below this limit client_name = "SAMPLE CLIENT" #Client name, to label on the final file enabled_campaigns_only = False #True/False - Whether to only run the script for enabled campaigns impressions_column_name = "Impr." #Google consistently flip between different names for their impressions column. We think just to annoy us. This spelling was correct at time of writing brand_terms = ["BRAND_TERM_2", #Labels brand and non-brand search terms. You can add as many as you want. Case insensitive. If none, leave as [""] "BRAND_TERM_2"] #eg ["Adidas","Addidas"] ## The Script #### You should not need to make changes below here import pandas as pd from nltk import ngrams import numpy as np import time import re def read_file(file_name): #find the file format and import if file_name.strip().split('.')[-1] == "xlsx": return pd.read_excel(f"{file_name}",skiprows = 2, thousands =",") elif file_name.strip().split('.')[-1] == "csv": return pd.read_csv(f"{file_name}",skiprows = 2, thousands =",") df = read_file(file_name) def filter_campaigns(df, to_ex = campaigns_to_exclude,to_inc = campaigns_to_include): to_ex = to_ex.split(",") to_inc = to_inc.split(",") if to_inc != ['']: to_inc = [word.lower() for word in to_inc] df = df[df["Campaign"].str.lower().str.strip().str.contains('|'.join(to_inc))] if to_ex != ['']: to_ex = [word.lower() for word in to_ex] df = df[~df["Campaign"].str.lower().str.strip().str.contains('|'.join(to_ex))] if enabled_campaigns_only: try: df = df[df["Campaign state"].str.contains("Enabled")] except KeyError: print("Couldn't find 'Campaign state' column") return df def generate_ngrams(list_of_terms, n): """ Turns a list of search terms into a set of unique n-grams that appear within """ # Clean the terms up first and remove special characters/commas etc. #clean_terms = [] #for st in list_of_terms: #st = st.strip() #clean_terms.append(re.sub(r'[^a-zA-Z0-9\s]', '', st)) #split into grams unique_ngrams = set() for term in list_of_terms: grams = ngrams(term.split(" "), n) [unique_ngrams.add(gram) for gram in grams] all_grams = set([' '.join(tups) for tups in unique_ngrams]) if character_limit > 0: n_grams_list = [ngram for ngram in all_grams if len(ngram) > character_limit] return n_grams_list def _collect_stats(term): #Slice the dataframe to the terms at hand sliced_df = df[df["Search term"].str.match(fr'. {re.escape(term)}. ')] #add our metrics raw_data =list(np.sum(sliced_df[[impressions_column_name,"Clicks","Cost","Conversions","Conv. value"]])) return raw_data def _generate_metrics(df): #generate metrics try: df["CTR"] = df["Clicks"]/df[f"Impressions"] df["CVR"] = df["Conversions"]/df["Clicks"] df["CPC"] = df["Cost"]/df["Clicks"] df["ROAS"] = df[f"Conv. value"]/df["Cost"] df["CPA"] = df["Cost"]/df["Conversions"] except KeyError: print("Couldn't find a column") #replace infinites with NaN and replace with 0 df.replace([np.inf, -np.inf], np.nan, inplace=True) df.fillna(0, inplace= True) df.round(2) return df def build_ngrams_df(df, sq_column_name ,ngrams_list, character_limit = 0): """Takes in n-grams and df and returns df of those metrics df - dataframe in question sq_column_name - str. Name of the column containing search terms ngrams_list - list/set of unique ngrams, already generated character_limit - Words have to be over a certain length, useful for single word grams Outputs a dataframe """ #set up metrics lists to drop values array = [] raw_data = map(_collect_stats, ngrams_list) #stack into an array data = np.array(list(raw_data)) #turn the above into a dataframe columns = ["Impressions","Clicks","Cost","Conversions", "Conv. value"] ngrams_df = pd.DataFrame(columns= columns, data=data, index = list(ngrams_list), dtype = float) ngrams_ df.sort_values(by = "Cost", ascending = False, inplace = True) #calculate additional metrics and return return _generate_metrics(ngrams_df) def group_by_sqs(df): df = df.groupby("Search term", as_index = False).sum() return df df = group_by_sqs(df) def find_brand_terms(df, brand_terms = brand_terms): brand_terms = [str.lower(term) for term in brand_terms] st_brand_bool = [] for i, row in df.iterrows(): term = row["Search term"] #runs through the term and if any of our brand strings appear, labels the column brand if any([brand_term in term for brand_term in brand_terms]): st_brand_bool.append("Brand") else: st_brand_bool.append("Generic") return st_brand_bool df["Brand label"] = find_brand_terms(df) #This is necessary for larger search volumes to cut down the very outlier terms with extremely few searches i = 1 while len(df)> 40000: print(f"DF too long, at {len(df)} rows, filtering to impressions greater than {i}") df = df[df[impressions_column_name] > i] i+=1 writer = pd.ExcelWriter(f"Ayima N-Gram Script Output - {client_name} N-Grams.xlsx", engine='xlsxwriter') df.to_excel(writer, sheet_name='Raw Searches') for n in grams_to_run: print("Working on ",n, "-grams") n_grams = generate_ngrams(df["Search term"], n) print(f"Found {len(n_grams)} n_grams, building stats (may take some time)") n_gram_df = build_ngrams_df(df,"Search term", n_grams, character_limit) print("Adding to file") n_gram_df.to_excel(writer, sheet_name=f'{n}-Gram',) writer.close()البرنامج النصي N-grams لتحليل خلاصات المنتج
#!/usr/bin/env python #coding: utf-8 # N-Grams for Google Shopping #This script looks to find patterns and trends in product feed data for Google shopping. It will help you find what words and phrases have been performing best for you #Script produced by Ayima Limited (www.ayima.com) # 2022. This work is licensed under a CC BY SA 4.0 license (https://creativecommons.org/licenses/by-sa/4.0/). #Version 1.1 ## Instructions #Download an SQR from within the reports section of Google ads. #The report must contain the following metrics: #+ Item ID #+ Product title #+ Impressions #+ Clicks #Then, complete the setting section as instructed and run the whole script #The script may take some time. Ngrams are computationally difficult, particularly for larger accounts. But, give it enough time to run, and it will log if it is running correctly. ## Settings #First, enter the name of the file to run this script on #By default, the script only looks in the folder it is in for the file. So, place this script in your downloads folder for ease. file_name = "Product report for N-Grams (1).csv" grams_to_run = [1,2,3] #The number of words in a phrase to run this for (eg 3 = three-word phrases only) character_limit = 0 #Words have to be over a certain length, useful for single word grams to rule out tiny words/symbols title_column_name = "Product Title" #Name of our product title column desc_column_name = "" #Name of our product description column, if we have one file_label = "Sample Client Name" #The label you want to add to the output file (eg the client name, or the run date) impressions_column_name = "Impr." #Google consistently flip between different names for their impressions column. We think just to annoy us. This spelling was correct at time of writing client_name = "SAMPLE" ## The Script #### You should not need to make changes below here #First import all of the relevant modules/packages import pandas as pd from nltk import ngrams import numpy as np import time import re #import our data file def read_file(file_name): #find the file format and import if file_name.strip().split('.')[-1] == "xlsx": return pd.read_excel(f"{file_name}",skiprows = 2, thousands =",") elif file_name.strip().split('.')[-1] == "csv": return pd.read_csv(f"{file_name}",skiprows = 2, thousands =",")# df = read_file(file_name) df.head() def generate_ngrams(list_of_terms, n): """ Turns our list of product titles into a set of unique n-grams that appear within """ unique_ngrams = set() for term in list_of_terms: grams = ngrams(term.split(" "), n) [unique_ngrams.add(gram) for gram in grams if ' ' not in gram] ngrams_list = set([' '.join(tups) for tups in unique_ngrams]) return ngrams_list def _collect_stats(term): #Slice the dataframe to the terms at hand sliced_df = df[df[title_column_name].str.match(fr'. {re.escape(term)}. ')] #add our metrics raw_data = [len(sliced_df), #number of products np.sum(sliced_df[impressions_column_name]), #total impressions np.sum(sliced_df["Clicks"]), #total clicks np.mean(sliced_df[impressions_column_name]), #average number of impressions np.mean(sliced_df["Clicks"]), #average number of clicks np.median(sliced_df[impressions_column_name]), #median impressions np.std(sliced_df[impressions_column_name])] #standard deviation return raw_data def build_ngrams_df(df, title_column_name, ngrams_list, character_limit = 0, desc_column_name = ''): """ Takes in n-grams and df and returns df of those metrics df - our dataframe title_column_name - str. Name of the column containing product titles ngrams_list - list/set of unique ngrams, already generated character_limit - Words have to be over a certain length, useful for single word grams to rule out tiny words/symbols desc_column_name = str. Name of the column containing product descriptions, if applicable Outputs a dataframe """ #first cut it to only grams longer than our minimum if character_limit > 0: ngrams_list = [ngram for ngram in ngrams_list if len(ngram) > character_limit] raw_data = map(_collect_stats, ngrams_list) #stack into an array data = np.array(list(raw_data)) #data[np.isnan(data)] = 0 columns = ["Product Count","Impressions","Clicks","Avg. Impressions", "Avg. Clicks","Median Impressions","Spread (Standard Deviation)"] #turn the above into a dataframe ngrams_df = pd.DataFrame(columns= columns, data=data, index = list(ngrams_list)) #clean the dataframe and add other key metrics ngrams_df["CTR"] = ngrams_df["Clicks"]/ ngrams_df["Impressions"] ngrams_df.fillna(0, inplace=True) ngrams_df.round(2) ngrams_df[["Impressions","Clicks","Product Count"]] = ngrams_df[["Impressions","Clicks","Product Count"]].astype(int) ngrams_df.sort_values(by = "Avg. Impressions", ascending = False, inplace = True) return ngrams_df writer = pd.ExcelWriter(f"{client_name} Product Feed N-Grams.xlsx", engine='xlsxwriter') start_time = time.time() for n in grams_to_run: print("Working on ",n, "-grams") n_grams = generate_ngrams(df["Product Title"], n) print(f"Found {len(n_grams)} n_grams, building stats (may take some time)") n_gram_df = build_ngrams_df(df,"Product Title", n_grams, character_limit) print("Adding to file") n_gram_df.to_excel(writer, sheet_name=f'{n}-Gram',) time_taken = time.time() - start_time print("Took "+str(time_taken) + " Seconds") writer.close()يمكنك أيضًا العثور على إصدارات محدثة من البرنامج النصي n-grams على جيثب لتنزيله.

تم ترخيص هذه البرامج النصية بموجب ترخيص Creative Commons BY SA 4.0 ، مما يعني أن لك الحرية في مشاركتها وتكييفها ، لكننا نشجعك دائمًا على مشاركة إصداراتك المحسنة بحرية ليستخدمها الجميع. إن جرامات النيتروجين مفيدة للغاية لعدم مشاركتها.
هذه مجرد واحدة من العديد من الأدوات والنصوص والقوالب المجانية التي نوفرها لأعضاء Ayima Insights Club. يمكنك معرفة المزيد حول Insights Club والاشتراك مجانًا هنا.