
適用於 Google Ads n-gram 的免費 Python 腳本
已發表: 2022-04-12N-gram 可以成為分析 Google Ads 或 SEO 上的搜索查詢的重要武器。 因此,我們製作了一個免費的 Python 腳本來幫助您分析產品提要和搜索查詢中任意長度的 n-gram。 我們將解釋什麼是 n-gram,以及如何使用 n-gram 來優化您的 Google Ads,尤其是針對 Google Shopping。 最後,我們將向您展示如何使用我們的免費 n-gram 腳本來改善您的 Google Ads 結果。
什麼是 n-gram?
N-gram 是從較長的文本中提取的 N 個單詞的短語。 這裡的“N”可以替換為任意數字。
例如,在“the cat jumped on the mat”這樣的句子中,“cat jumped”或“the mat”都是 2-grams(或“bi-grams”)。
“The cat jumped”或“cat jumped on”都是這句話中 3-grams(或“tri-grams”)的例子。
n-gram 如何幫助搜索查詢
N-gram 在分析 Google Ads 中的搜索查詢時很有用,因為某些關鍵短語可以出現在許多不同的搜索查詢中。
N-gram 讓我們可以分析這些短語對您整個庫存的影響。 因此,它們可以讓您在規模上做出更好的決策和優化。
它甚至可以讓我們理解單個單詞的影響。 例如,如果您發現包含“免費”(“1-gram”)一詞的搜索結果不佳,您可能會決定從所有廣告系列中排除該詞。
或者,通過包含“個性化”的搜索查詢的強勁表現可能會鼓勵您建立專門的廣告系列。
N-gram 對於查看來自 Google 購物的搜索查詢特別有用。
產品詳情廣告關鍵字定位的自動化特性意味著您可以針對數十萬個搜索查詢進行展示。 特別是當您擁有大量具有非常特定功能的產品變體時。
我們的 N-gram 腳本可讓您從雜亂無章的地方切入重要的短語。
使用 n-gram 分析搜索查詢
n-gram 的第一個用例是分析搜索查詢。
我們用於 Google Ads 的 n-gram python 腳本包含有關如何運行它的完整說明,但是
我們將討論如何充分利用它。
- 您需要在您的機器上安裝 python 才能開始。 如果你不這樣做,這很容易。 您首先安裝 Anaconda。 然後,打開 Anaconda Prompt 並輸入“conda install jupyter lab”。 Jupyter Lab 是您將在其中運行此腳本的環境。
只需從您的 Google Ads 下載搜索查詢報告。 我們建議在 Google Ads 的“報告”部分將其設置為自定義報告。 如果您希望跨多個帳戶運行此腳本,您甚至可以在 MCC 級別進行設置。

3. 然後,只需更新腳本中的設置以執行您想要的操作,然後運行所有單元格。
運行需要一點時間,但請保持耐心。 您將在底部看到進度更新,因為它發揮了它的魔力。
輸出將在您運行腳本的任何文件夾中顯示為 excel 文件,我們建議使用下載文件夾。 該文件將使用您定義的任何名稱進行標記。
excel 文件的每個選項卡都包含不同的 n-gram 分析。 例如,這是一個二元語法分析:
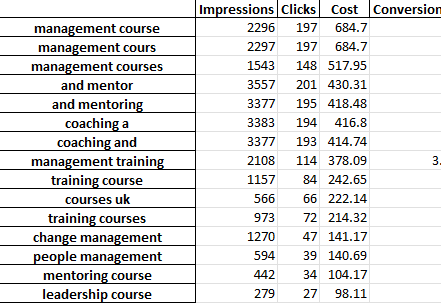
您可以通過多種方式使用此報告來尋找改進。
您可以從支出最高的短語開始,然後查看 CPA 或 ROAS 的任何異常值。
將您的報告過濾給非轉化者也將突出顯示支出不足的領域。
如果您在單個單詞選項卡中看到較差的轉換器,您可以輕鬆檢查在 3-Gram 選項卡中使用的單詞的上下文。
例如,在專業培訓帳戶中,我們可能會發現“Oxford”始終表現不佳。 3-Gram 選項卡很快表明用戶可能正在尋找更正式的、面向大學的課程。

因此,您可以快速否定這個詞。
最終,請使用此報告,但它最適合您。
使用 n-gram 優化產品提要
我們用於 Google Ads 的第二個 n-gram 腳本會分析您的產品效果。
同樣,您可以在腳本本身中找到完整的說明
此腳本查看產品標題中短語的表現。 畢竟,產品標題在很大程度上決定了你出現的關鍵詞。 標題也是您的主要廣告文案。 因此,標題非常重要。
該腳本旨在幫助您在這些標題中找到潛在的短語,您可以調整這些短語以提高您在 Google 購物中的表現。

正如你在上面看到的,這個腳本的輸出有點不同。 由於 Google 報告 API 的限制,您在產品標題級別時無法訪問轉化指標(如收入)。
因此,此報告為您提供產品數量、平均流量和產品短語的傳播(標準偏差)。
因為它基於可見性,所以您可以使用該報告來識別可能使您的產品更加可見的短語。 然後,您可以將這些添加到您的更多產品標題中。

例如,我們可能會發現一個平均展示次數非常多且出現在多個產品標題中的短語。 它的標準偏差也很低——這意味著這裡不可能只有一種令人驚嘆的產品會扭曲我們的數據。
我們使用此工具極大地擴大了客戶的購物知名度。 客戶銷售了數千種不同尺寸的產品。 例如 8x10 毫米。 人們也在購買他們需要的非常具體的尺寸。
但是,谷歌在理解這種大小的不同可能的命名約定方面很糟糕:像 8 毫米 x 10 毫米、8 x 10 毫米、8 毫米 x 10 毫米這樣的搜索都被視為幾乎完全不同的搜索查詢。
因此,我們使用我們的 n-gram 腳本來確定這些命名約定中的哪一個為我們的產品提供了最佳可見性。
我們找到了最佳匹配項並對我們的產品 Feed 進行了更改。 結果,客戶購物活動的流量在一個月內猛增了550%以上。
產品命名很重要,n-gram 可以幫助您。
Google Ads 的 N-gram 腳本
這是兩個完整的腳本。
用於 Google Ads 搜索查詢的 N-gram 腳本
#!/usr/bin/env python #coding: utf-8 # Ayima N-Grams Script for Google Ads #Takes in SQR data and outputs data split into phrases of N length #Script produced by Ayima Limited (www.ayima.com) # 2022. This work is licensed under a CC BY SA 4.0 license (https://creativecommons.org/licenses/by-sa/4.0/). #Version 1.1 ### Instructions #Download an SQR from within the reports section of Google ads. #The report must contain the following metrics: #+ Search term #+ Campaign #+ Campaign state #+ Currency code #+ Impressions #+ Clicks #+ Cost #+ Conversions #+ Conv. value #Then, complete the setting section as instructed and run the whole script #The script may take some time. Ngrams are computationally difficult, particularly for larger accounts. But, give it enough time to run, and it will log if it is running correctly. ### Settings # First, enter the name of the file to run this script on # By default, the script only looks in the folder it is in for the file. So, place this script in your downloads folder for ease. file_name = "N-Grams input - SQR (2).csv" grams_to_run = [1,2,3] #What length phrases you want to retrieve for. Recommended is < 4 max. Longer phrases retrieves far more results. campaigns_to_exclude = "" #input strings contained by campaigns you want to EXCLUDE, separated by commas if multiple (eg "DSA,PLA"). Case Insensitive campaigns_to_include = "PLA" #input strings contained by campaigns you want to INCLUDE, separated by commas if multiple (eg "DSA,PLA"). Case Insensitive character_limit = 3 #minimum number of characters in an ngram eg to filter out "a" or "i". Will filter everything below this limit client_name = "SAMPLE CLIENT" #Client name, to label on the final file enabled_campaigns_only = False #True/False - Whether to only run the script for enabled campaigns impressions_column_name = "Impr." #Google consistently flip between different names for their impressions column. We think just to annoy us. This spelling was correct at time of writing brand_terms = ["BRAND_TERM_2", #Labels brand and non-brand search terms. You can add as many as you want. Case insensitive. If none, leave as [""] "BRAND_TERM_2"] #eg ["Adidas","Addidas"] ## The Script #### You should not need to make changes below here import pandas as pd from nltk import ngrams import numpy as np import time import re def read_file(file_name): #find the file format and import if file_name.strip().split('.')[-1] == "xlsx": return pd.read_excel(f"{file_name}",skiprows = 2, thousands =",") elif file_name.strip().split('.')[-1] == "csv": return pd.read_csv(f"{file_name}",skiprows = 2, thousands =",") df = read_file(file_name) def filter_campaigns(df, to_ex = campaigns_to_exclude,to_inc = campaigns_to_include): to_ex = to_ex.split(",") to_inc = to_inc.split(",") if to_inc != ['']: to_inc = [word.lower() for word in to_inc] df = df[df["Campaign"].str.lower().str.strip().str.contains('|'.join(to_inc))] if to_ex != ['']: to_ex = [word.lower() for word in to_ex] df = df[~df["Campaign"].str.lower().str.strip().str.contains('|'.join(to_ex))] if enabled_campaigns_only: try: df = df[df["Campaign state"].str.contains("Enabled")] except KeyError: print("Couldn't find 'Campaign state' column") return df def generate_ngrams(list_of_terms, n): """ Turns a list of search terms into a set of unique n-grams that appear within """ # Clean the terms up first and remove special characters/commas etc. #clean_terms = [] #for st in list_of_terms: #st = st.strip() #clean_terms.append(re.sub(r'[^a-zA-Z0-9\s]', '', st)) #split into grams unique_ngrams = set() for term in list_of_terms: grams = ngrams(term.split(" "), n) [unique_ngrams.add(gram) for gram in grams] all_grams = set([' '.join(tups) for tups in unique_ngrams]) if character_limit > 0: n_grams_list = [ngram for ngram in all_grams if len(ngram) > character_limit] return n_grams_list def _collect_stats(term): #Slice the dataframe to the terms at hand sliced_df = df[df["Search term"].str.match(fr'. {re.escape(term)}. ')] #add our metrics raw_data =list(np.sum(sliced_df[[impressions_column_name,"Clicks","Cost","Conversions","Conv. value"]])) return raw_data def _generate_metrics(df): #generate metrics try: df["CTR"] = df["Clicks"]/df[f"Impressions"] df["CVR"] = df["Conversions"]/df["Clicks"] df["CPC"] = df["Cost"]/df["Clicks"] df["ROAS"] = df[f"Conv. value"]/df["Cost"] df["CPA"] = df["Cost"]/df["Conversions"] except KeyError: print("Couldn't find a column") #replace infinites with NaN and replace with 0 df.replace([np.inf, -np.inf], np.nan, inplace=True) df.fillna(0, inplace= True) df.round(2) return df def build_ngrams_df(df, sq_column_name ,ngrams_list, character_limit = 0): """Takes in n-grams and df and returns df of those metrics df - dataframe in question sq_column_name - str. Name of the column containing search terms ngrams_list - list/set of unique ngrams, already generated character_limit - Words have to be over a certain length, useful for single word grams Outputs a dataframe """ #set up metrics lists to drop values array = [] raw_data = map(_collect_stats, ngrams_list) #stack into an array data = np.array(list(raw_data)) #turn the above into a dataframe columns = ["Impressions","Clicks","Cost","Conversions", "Conv. value"] ngrams_df = pd.DataFrame(columns= columns, data=data, index = list(ngrams_list), dtype = float) ngrams_ df.sort_values(by = "Cost", ascending = False, inplace = True) #calculate additional metrics and return return _generate_metrics(ngrams_df) def group_by_sqs(df): df = df.groupby("Search term", as_index = False).sum() return df df = group_by_sqs(df) def find_brand_terms(df, brand_terms = brand_terms): brand_terms = [str.lower(term) for term in brand_terms] st_brand_bool = [] for i, row in df.iterrows(): term = row["Search term"] #runs through the term and if any of our brand strings appear, labels the column brand if any([brand_term in term for brand_term in brand_terms]): st_brand_bool.append("Brand") else: st_brand_bool.append("Generic") return st_brand_bool df["Brand label"] = find_brand_terms(df) #This is necessary for larger search volumes to cut down the very outlier terms with extremely few searches i = 1 while len(df)> 40000: print(f"DF too long, at {len(df)} rows, filtering to impressions greater than {i}") df = df[df[impressions_column_name] > i] i+=1 writer = pd.ExcelWriter(f"Ayima N-Gram Script Output - {client_name} N-Grams.xlsx", engine='xlsxwriter') df.to_excel(writer, sheet_name='Raw Searches') for n in grams_to_run: print("Working on ",n, "-grams") n_grams = generate_ngrams(df["Search term"], n) print(f"Found {len(n_grams)} n_grams, building stats (may take some time)") n_gram_df = build_ngrams_df(df,"Search term", n_grams, character_limit) print("Adding to file") n_gram_df.to_excel(writer, sheet_name=f'{n}-Gram',) writer.close()用於分析產品提要的 N-gram 腳本
#!/usr/bin/env python #coding: utf-8 # N-Grams for Google Shopping #This script looks to find patterns and trends in product feed data for Google shopping. It will help you find what words and phrases have been performing best for you #Script produced by Ayima Limited (www.ayima.com) # 2022. This work is licensed under a CC BY SA 4.0 license (https://creativecommons.org/licenses/by-sa/4.0/). #Version 1.1 ## Instructions #Download an SQR from within the reports section of Google ads. #The report must contain the following metrics: #+ Item ID #+ Product title #+ Impressions #+ Clicks #Then, complete the setting section as instructed and run the whole script #The script may take some time. Ngrams are computationally difficult, particularly for larger accounts. But, give it enough time to run, and it will log if it is running correctly. ## Settings #First, enter the name of the file to run this script on #By default, the script only looks in the folder it is in for the file. So, place this script in your downloads folder for ease. file_name = "Product report for N-Grams (1).csv" grams_to_run = [1,2,3] #The number of words in a phrase to run this for (eg 3 = three-word phrases only) character_limit = 0 #Words have to be over a certain length, useful for single word grams to rule out tiny words/symbols title_column_name = "Product Title" #Name of our product title column desc_column_name = "" #Name of our product description column, if we have one file_label = "Sample Client Name" #The label you want to add to the output file (eg the client name, or the run date) impressions_column_name = "Impr." #Google consistently flip between different names for their impressions column. We think just to annoy us. This spelling was correct at time of writing client_name = "SAMPLE" ## The Script #### You should not need to make changes below here #First import all of the relevant modules/packages import pandas as pd from nltk import ngrams import numpy as np import time import re #import our data file def read_file(file_name): #find the file format and import if file_name.strip().split('.')[-1] == "xlsx": return pd.read_excel(f"{file_name}",skiprows = 2, thousands =",") elif file_name.strip().split('.')[-1] == "csv": return pd.read_csv(f"{file_name}",skiprows = 2, thousands =",")# df = read_file(file_name) df.head() def generate_ngrams(list_of_terms, n): """ Turns our list of product titles into a set of unique n-grams that appear within """ unique_ngrams = set() for term in list_of_terms: grams = ngrams(term.split(" "), n) [unique_ngrams.add(gram) for gram in grams if ' ' not in gram] ngrams_list = set([' '.join(tups) for tups in unique_ngrams]) return ngrams_list def _collect_stats(term): #Slice the dataframe to the terms at hand sliced_df = df[df[title_column_name].str.match(fr'. {re.escape(term)}. ')] #add our metrics raw_data = [len(sliced_df), #number of products np.sum(sliced_df[impressions_column_name]), #total impressions np.sum(sliced_df["Clicks"]), #total clicks np.mean(sliced_df[impressions_column_name]), #average number of impressions np.mean(sliced_df["Clicks"]), #average number of clicks np.median(sliced_df[impressions_column_name]), #median impressions np.std(sliced_df[impressions_column_name])] #standard deviation return raw_data def build_ngrams_df(df, title_column_name, ngrams_list, character_limit = 0, desc_column_name = ''): """ Takes in n-grams and df and returns df of those metrics df - our dataframe title_column_name - str. Name of the column containing product titles ngrams_list - list/set of unique ngrams, already generated character_limit - Words have to be over a certain length, useful for single word grams to rule out tiny words/symbols desc_column_name = str. Name of the column containing product descriptions, if applicable Outputs a dataframe """ #first cut it to only grams longer than our minimum if character_limit > 0: ngrams_list = [ngram for ngram in ngrams_list if len(ngram) > character_limit] raw_data = map(_collect_stats, ngrams_list) #stack into an array data = np.array(list(raw_data)) #data[np.isnan(data)] = 0 columns = ["Product Count","Impressions","Clicks","Avg. Impressions", "Avg. Clicks","Median Impressions","Spread (Standard Deviation)"] #turn the above into a dataframe ngrams_df = pd.DataFrame(columns= columns, data=data, index = list(ngrams_list)) #clean the dataframe and add other key metrics ngrams_df["CTR"] = ngrams_df["Clicks"]/ ngrams_df["Impressions"] ngrams_df.fillna(0, inplace=True) ngrams_df.round(2) ngrams_df[["Impressions","Clicks","Product Count"]] = ngrams_df[["Impressions","Clicks","Product Count"]].astype(int) ngrams_df.sort_values(by = "Avg. Impressions", ascending = False, inplace = True) return ngrams_df writer = pd.ExcelWriter(f"{client_name} Product Feed N-Grams.xlsx", engine='xlsxwriter') start_time = time.time() for n in grams_to_run: print("Working on ",n, "-grams") n_grams = generate_ngrams(df["Product Title"], n) print(f"Found {len(n_grams)} n_grams, building stats (may take some time)") n_gram_df = build_ngrams_df(df,"Product Title", n_grams, character_limit) print("Adding to file") n_gram_df.to_excel(writer, sheet_name=f'{n}-Gram',) time_taken = time.time() - start_time print("Took "+str(time_taken) + " Seconds") writer.close()您還可以在 github 上找到 n-gram 腳本的更新版本以進行下載。

這些腳本在 Creative Commons BY SA 4.0 許可下獲得許可,這意味著您可以自由分享和改編它,但我們鼓勵您始終免費分享您的改進版本供所有人使用。 N-gram 太有用了,不能分享。
這只是我們向 Ayima Insights Club 成員提供的眾多免費工具、腳本和模板之一。 您可以了解有關 Insights Club 的更多信息,並在此處免費註冊。