
Kafka ve Spark ile Veri İşlemeyi Başlatın
Yayınlanan: 2022-09-09Büyük verilerin işlenmesi, kuruluşların karşılaştığı en karmaşık prosedürlerden biridir. Büyük miktarda gerçek zamanlı veriye sahip olduğunuzda süreç daha karmaşık hale gelir.
Bu yazıda, büyük veri işlemenin ne olduğunu, nasıl yapıldığını keşfedeceğiz ve en ünlü veri işleme araçlarından ikisi olan Apache Kafka ve Spark'ı keşfedeceğiz!
Veri İşleme Nedir? Nasıl oldu?
Veri işleme, otomatik bir süreç kullanılarak gerçekleştirilip gerçekleştirilmediğine bakılmaksızın herhangi bir işlem veya işlem dizisi olarak tanımlanır. Yorumlama için mantıklı ve uygun bir eğilime göre bilginin toplanması, düzenlenmesi ve düzenlenmesi olarak düşünülebilir.

Bir kullanıcı bir veritabanına eriştiğinde ve araması için sonuçlar aldığında, onlara ihtiyaç duydukları sonuçları sağlayan şey veri işlemedir. Arama sonucu olarak çıkarılan bilgiler, veri işlemenin sonucudur. Bu nedenle bilgi teknolojisi, varlığının odağını veri işlemeye odaklamıştır.
Geleneksel veri işleme, basit bir yazılım kullanılarak gerçekleştirildi. Ancak, Big Data'nın ortaya çıkmasıyla birlikte işler değişti. Büyük Veri, hacmi yüz terabayt ve petabayttan fazla olabilen bilgileri ifade eder.
Üstelik bu bilgiler düzenli olarak güncellenmektedir. Örnekler, iletişim merkezlerinden, sosyal medyadan, borsa ticaret verilerinden vb. gelen verileri içerir. Bu tür veriler bazen veri akışı olarak da adlandırılır - sabit, kontrolsüz bir veri akışı. Ana özelliği, verilerin tanımlanmış bir limitinin olmamasıdır, bu nedenle akışın ne zaman başladığını veya bittiğini söylemek imkansızdır.
Veriler hedefe ulaştığında işlenir. Bazı yazarlar buna gerçek zamanlı veya çevrimiçi işleme diyor. Farklı bir yaklaşım, veri bloklarının saat veya gün cinsinden zaman pencerelerinde işlendiği blok, toplu veya çevrimdışı işlemedir. Toplu iş, genellikle geceleri çalışan ve o günün verilerini birleştiren bir süreçtir. Güncel olmayan raporlar üreten bir haftalık, hatta bir aylık zaman pencereleri vardır.
Akış yoluyla en iyi Büyük Veri işleme platformlarının Kafka ve Spark gibi açık kaynaklar olduğu göz önüne alındığında, bu platformlar diğer farklı ve tamamlayıcı olanların kullanımına izin verir. Bu, açık kaynak oldukları için daha hızlı geliştikleri ve daha fazla araç kullandıkları anlamına gelir. Bu sayede veri akışları başka yerlerden değişken bir hızda ve kesintisiz olarak alınır.
Şimdi, en yaygın olarak bilinen iki veri işleme aracına bakacağız ve bunları karşılaştıracağız:
Apaçi Kafka
Apache Kafka, sürekli veri akışıyla akış uygulamaları oluşturan bir mesajlaşma sistemidir. İlk olarak LinkedIn tarafından oluşturulan Kafka, günlük tabanlıdır; günlük, temel bir depolama biçimidir, çünkü her yeni bilgi dosyanın sonuna eklenir.

Kafka, büyük veri için en iyi çözümlerden biridir çünkü ana özelliği yüksek verimidir. Apache Kafka ile toplu işlemeyi gerçek zamanlı olarak dönüştürmek bile mümkündür.
Apache Kafka, bir uygulamanın yayınladığı ve abone olan bir uygulamanın mesajları aldığı bir yayınla-abone ol mesajlaşma sistemidir. İletiyi yayınlama ve alma arasındaki süre milisaniye olabilir, bu nedenle Kafka çözümünün gecikme süresi düşüktür.
Kafka'nın Çalışması
Apache Kafka'nın mimarisi üreticiler, tüketiciler ve kümenin kendisinden oluşur. Üretici, kümeye mesaj yayınlayan herhangi bir uygulamadır. Tüketici, Kafka'dan mesaj alan herhangi bir uygulamadır. Kafka kümesi, mesajlaşma hizmetinin tek bir örneği olarak işlev gören bir dizi düğümdür.
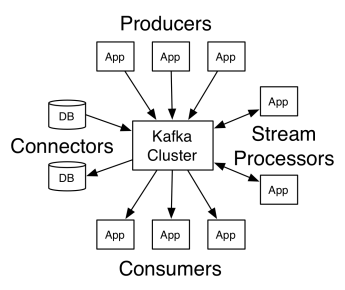
Bir Kafka kümesi, birkaç aracıdan oluşur. Aracı, üreticilerin mesajlarını alan ve bunları diske yazan bir Kafka sunucusudur. Her komisyoncu bir konu listesini yönetir ve her konu birkaç bölüme ayrılır.
Mesajları aldıktan sonra, komisyoncu bunları her konu için kayıtlı tüketicilere gönderir.
Apache Kafka ayarları, bölüm konumu, ad listesi, konu listesi ve kullanılabilir düğümler gibi küme meta verilerini depolayan Apache Zookeeper tarafından yönetilir. Böylece Zookeeper, kümenin farklı öğeleri arasındaki senkronizasyonu korur.
Zookeeper önemlidir çünkü Kafka dağıtılmış bir sistemdir; yani, yazma ve okuma aynı anda birkaç müşteri tarafından yapılır. Bir arıza olduğunda, Zookeeper bir yedek seçer ve işlemi geri alır.
Kullanım Durumları
Kafka, özellikle bir mesajlaşma aracı olarak kullanımı nedeniyle popüler oldu, ancak çok yönlülüğü bunun ötesine geçiyor ve aşağıdaki örneklerde olduğu gibi çeşitli senaryolarda kullanılabilir.
mesajlaşma
İletişim kuran tarafları birbirinden ayıran asenkron iletişim biçimi. Bu modelde, bir taraf verileri Kafka'ya mesaj olarak gönderir, böylece daha sonra başka bir uygulama onu tüketir.
Aktivite takibi
Sayfa görüntülemeleri, tıklamalar, veri girişi vb. gibi bir kullanıcının bir web sitesiyle etkileşimini izleyen verileri depolamanıza ve işlemenize olanak tanır; bu tür faaliyetler genellikle büyük miktarda veri üretir.
Metrikler
Merkezi bir rapor oluşturmak için birden çok kaynaktan veri ve istatistiklerin bir araya getirilmesini içerir.
Günlük toplama
Diğer sistemlerden kaynaklanan günlük dosyalarını merkezi olarak toplar ve depolar.
Akış İşleme
Veri ardışık düzenlerinin işlenmesi, konulardan ham verilerin tüketildiği ve toplandığı, zenginleştirildiği veya diğer konulara dönüştürüldüğü birden çok aşamadan oluşur.
Bu özellikleri desteklemek için platform temel olarak üç API sağlar:
- Akışlar API'si: Bir konudan veri tüketen, dönüştüren ve diğerine yazan bir akış işlemcisi görevi görür.
- Bağlayıcılar API'si: Konuların ilişkisel veritabanları gibi mevcut sistemlere bağlanmasına izin verir.
- Üretici ve tüketici API'leri: Uygulamaların Kafka verilerini yayınlamasına ve tüketmesine olanak tanır.
Artıları
Çoğaltılan, Bölümlenen ve Sıralanan
Kafka'daki mesajlar, güvenlik ve teslimat hızı sağlamak için geldikleri sırayla küme düğümleri arasında bölümler arasında çoğaltılır.
Veri Dönüşümü
Apache Kafka ile toplu ETL akışları API'sini kullanarak toplu işlemeyi gerçek zamanlı olarak dönüştürmek bile mümkündür.
Sıralı disk erişimi
Apache Kafka, daha hızlı olması gerektiği için mesajı bellekte değil diskte tutar. Aslında, özellikle bellekte rastgele konumlardaki verilere erişim düşünüldüğünde, çoğu durumda belleğe erişim daha hızlıdır. Ancak Kafka sıralı erişim yapar ve bu durumda disk daha verimlidir.
Apaçi Kıvılcımı
Apache Spark, kümeler arasında paralel verileri işlemek için bir büyük veri bilgi işlem motoru ve kitaplıklar kümesidir. Spark, Hadoop ve Map-Reduce programlama paradigmasının bir evrimidir. Verileri işlerken disklerde tutmayan verimli bellek kullanımı sayesinde 100 kat daha hızlı olabilir.

Spark üç düzeyde düzenlenmiştir:
- Düşük Düzey API'ler: Bu düzey, diğer bileşenlerin gerektirdiği işleri ve diğer işlevleri çalıştırmak için temel işlevleri içerir. Bu katmanın diğer önemli işlevleri güvenlik yönetimi, ağ, zamanlama ve HDFS, GlusterFS, Amazon S3 ve diğer dosya sistemlerine mantıksal erişimdir.
- Yapılandırılmış API'ler: Yapılandırılmış API düzeyi, Hive, Parquet, JSON ve diğerleri gibi formatlarda okunabilen DataSets veya DataFrame'ler aracılığıyla veri manipülasyonu ile ilgilenir. SparkSQL'i (SQL'de sorgu yazmamıza izin veren API) kullanarak verileri istediğimiz gibi değiştirebiliriz.
- Üst Düzey: En üst düzeyde, Spark Streaming, Spark MLlib ve Spark GraphX dahil olmak üzere çeşitli kitaplıklara sahip Spark ekosistemine sahibiz. Akış alımı ve kilitlenme kurtarma, klasik makine öğrenimi modelleri oluşturma ve doğrulama ve grafikler ve algoritmalarla ilgilenme gibi çevreleyen süreçlerle ilgilenmekten sorumludurlar.
Spark'ın Çalışması
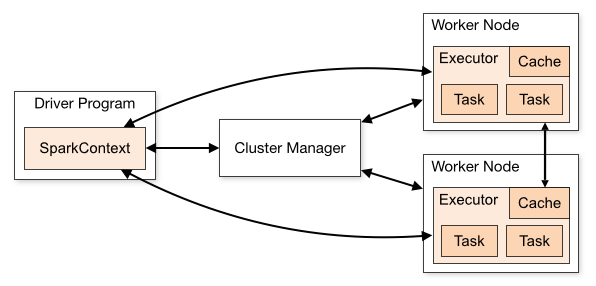
Spark uygulamasının mimarisi üç ana bölümden oluşur:

Sürücü Programı : Veri işlemenin yürütülmesinin düzenlenmesinden sorumludur.
Küme Yöneticisi : Bir kümedeki farklı makineleri yönetmekten sorumlu bileşendir. Yalnızca Spark dağıtılmış olarak çalışıyorsa gereklidir.
İşçi Düğümleri : Bir programın görevlerini yerine getiren makinelerdir. Spark, makinenizde yerel olarak çalıştırılıyorsa, bir Sürücü Programı ve Workes rolü oynayacaktır. Spark'ı çalıştırmanın bu yoluna Bağımsız denir.
Spark kodu birkaç farklı dilde yazılabilir. Spark Shell adlı Spark konsolu, verileri öğrenmek ve keşfetmek için etkileşimlidir.
Sözde Spark uygulaması, büyük ölçekli veri işleme desteği sağlayan bir veya daha fazla İş'ten oluşur.
Yürütme hakkında konuştuğumuzda, Spark'ın iki modu vardır:
- İstemci: Sürücü, Kaynak Yöneticisinden geçmeyen doğrudan istemcide çalışır.
- Küme: Kaynak Yöneticisi aracılığıyla Uygulama Yöneticisinde çalışan sürücü (Küme modunda, istemcinin bağlantısı kesilirse uygulama çalışmaya devam eder).
Kaynak Yöneticisi gibi bağlantılı hizmetlerin en iyi performansı sağlayarak her yürütmeye yönelik ihtiyacı belirleyebilmesi için Spark'ı doğru şekilde kullanmak gerekir. Bu nedenle, Spark işlerini yürütmenin, yapılan çağrıyı yapılandırmanın en iyi yolunu bilmek geliştiriciye kalmıştır ve bunun için Spark yürütücülerini istediğiniz şekilde yapılandırabilir ve yapılandırabilirsiniz.
Spark işleri öncelikle bellek kullanır, bu nedenle iş düğümü yürütücüleri için Spark yapılandırma değerlerini ayarlamak yaygındır. Spark iş yüküne bağlı olarak, standart olmayan belirli bir Spark yapılandırmasının daha optimum yürütmeler sağladığını belirlemek mümkündür. Bu amaçla, mevcut çeşitli konfigürasyon seçenekleri ile varsayılan Spark konfigürasyonunun kendisi arasında karşılaştırma testleri gerçekleştirilebilir.
Kullanım Alanları
Apache Spark, gerçek zamanlı veya arşivlenmiş, yapılandırılmış veya yapılandırılmamış büyük miktarda verinin işlenmesine yardımcı olur. Aşağıda, popüler kullanım durumlarından bazıları verilmiştir.
Veri Zenginleştirme
Şirketler genellikle geçmiş müşteri verileriyle gerçek zamanlı davranış verilerinin bir kombinasyonunu kullanır. Spark, yapılandırılmamış olay verilerini yapılandırılmış verilere dönüştürmek için sürekli bir ETL ardışık düzeni oluşturmaya yardımcı olabilir.
Tetikleyici Olay Algılama
Spark Streaming, olası bir soruna veya dolandırıcılığa işaret edebilecek bazı nadir veya şüpheli davranışların hızlı bir şekilde algılanmasına ve yanıtlanmasına olanak tanır.
Karmaşık Oturum Veri Analizi
Spark Streaming kullanılarak, uygulamada oturum açtıktan sonraki etkinlikleri gibi kullanıcının oturumuyla ilgili olaylar gruplandırılabilir ve analiz edilebilir. Bu bilgiler, makine öğrenimi modellerini güncellemek için sürekli olarak da kullanılabilir.
Artıları
yinelemeli işleme
Görev verileri tekrar tekrar işlemekse, Spark'ın esnek Dağıtılmış Veri Kümeleri (RDD'ler), ara sonuçları diske yazmak zorunda kalmadan birden çok bellek içi harita işlemine izin verir.
Grafik işleme
Spark'ın GraphX API'li hesaplama modeli, grafik işlemeye özgü yinelemeli hesaplamalar için mükemmeldir.
Makine öğrenme
Spark, bellekte de çalışan hazır algoritmalara sahip yerleşik bir makine öğrenimi kitaplığı olan MLlib'e sahiptir.
Kafka vs Kıvılcım
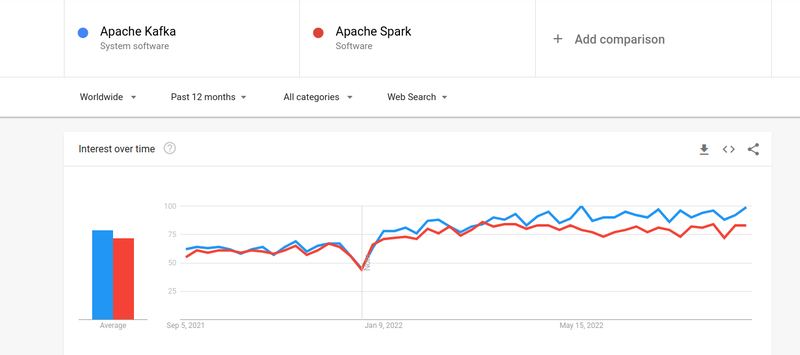
İnsanların hem Kafka'ya hem de Spark'a ilgisi hemen hemen benzer olsa da, ikisi arasında bazı büyük farklılıklar var; bir bakalım.
#1. Veri işleme
Kafka, uygulamalar arasında veri aktarımından sorumlu gerçek zamanlı bir veri akışı ve depolama aracıdır, ancak eksiksiz bir çözüm oluşturmak için yeterli değildir. Bu nedenle, Kafka'nın yapmadığı görevler için Spark gibi başka araçlara ihtiyaç vardır. Spark ise Kafka konularından veri çeken ve bunları birleştirilmiş şemalara dönüştüren toplu ilk veri işleme platformudur.
#2. Hafıza yönetimi
Spark, bellek yönetimi için Sağlam Dağıtılmış Veri Kümeleri (RDD) kullanır. Büyük veri kümelerini işlemeye çalışmak yerine, bunları bir kümedeki birden çok düğüme dağıtır. Buna karşılık Kafka, HDFS'ye benzer sıralı erişim kullanır ve verileri bir ara bellekte depolar.
#3. ETL Dönüşümü
Hem Spark hem de Kafka, kayıtları bir veritabanından diğerine, genellikle işlem temelinden (OLTP) analitik temele (OLAP) kopyalayan ETL dönüştürme sürecini destekler. Ancak, ETL süreci için yerleşik bir yetenekle gelen Spark'ın aksine, Kafka, onu desteklemek için Streams API'sine güveniyor.
#4. Veri Kalıcılığı

Spark'ın RRD kullanımı, verileri daha sonra kullanmak üzere birden çok konumda saklamanıza olanak tanırken, Kafka'da verileri kalıcı kılmak için yapılandırmada veri kümesi nesneleri tanımlamanız gerekir.
#5. Zorluk
Spark eksiksiz bir çözümdür ve çeşitli üst düzey programlama dillerini desteklediği için öğrenmesi daha kolaydır. Kafka, birlikte çalışmayı zorlaştırabilecek bir dizi farklı API'ye ve üçüncü taraf modüle bağlıdır.
#6. Kurtarma
Hem Spark hem de Kafka, kurtarma seçenekleri sunar. Spark, verileri sürekli olarak kaydetmesine izin veren RRD'yi kullanır ve bir küme hatası varsa kurtarılabilir.

Kafka, küme içindeki verileri sürekli olarak çoğaltır ve aracılar arasında eşleme yapar; bu, bir arıza olması durumunda farklı aracılara geçmenize olanak tanır.
Spark ve Kafka arasındaki benzerlikler
| Apaçi Kıvılcımı | Apaçi Kafka |
| Açık kaynak | Açık kaynak |
| Veri Akışı Uygulaması Oluşturun | Veri Akışı Uygulaması Oluşturun |
| Durum Bilgili İşlemeyi Destekler | Durum Bilgili İşlemeyi Destekler |
| SQL'i destekler | SQL'i destekler |
Son sözler
Kafka ve Spark, gerçek zamanlı veri akışı uygulamaları oluşturmanıza olanak tanıyan, Scala ve Java'da yazılmış açık kaynaklı araçlardır. Durum bilgisi olan işleme, SQL desteği ve ETL dahil olmak üzere birçok ortak noktaları vardır. Kafka ve Spark, uygulamalar arasında veri aktarımının karmaşıklığı sorununu çözmeye yardımcı olmak için tamamlayıcı araçlar olarak da kullanılabilir.