
Kafka と Spark でデータ処理を開始
公開: 2022-09-09ビッグデータの処理は、組織が直面する最も複雑な手順の 1 つです。 大量のリアルタイム データがある場合、プロセスはより複雑になります。
この記事では、ビッグ データ処理とは何か、その方法を説明し、最も有名なデータ処理ツールである Apache Kafka と Spark について説明します。
データ処理とは? それはどのように行われますか?
データ処理は、自動化されたプロセスを使用して実行されるかどうかにかかわらず、任意の操作または一連の操作として定義されます。 これは、解釈のための論理的かつ適切な配置に従って、情報の収集、順序付け、編成と考えることができます。

ユーザーがデータベースにアクセスして検索結果を取得するとき、必要な結果を取得しているのはデータ処理です。 検索結果として抽出された情報は、データ処理の結果です。 そのため、情報技術はデータ処理を中心にその存在の焦点を当てています。
従来のデータ処理は、単純なソフトウェアを使用して実行されました。 しかし、ビッグデータの出現により、状況は一変しました。 ビッグ データとは、100 テラバイトやペタバイトを超える量の情報を指します。
また、この情報は定期的に更新されます。 例としては、コンタクト センター、ソーシャル メディア、証券取引所の取引データなどからのデータがあります。このようなデータは、データ ストリームと呼ばれることもあり、一定の制御されていないデータ ストリームです。 その主な特徴は、データに制限が定義されていないため、ストリームがいつ開始または終了するかを言うことができないことです。
データは宛先に到着すると処理されます。 一部の著者は、これをリアルタイム処理またはオンライン処理と呼んでいます。 別のアプローチは、ブロック、バッチ、またはオフライン処理であり、データのブロックが数時間または数日の時間枠で処理されます。 多くの場合、バッチは夜間に実行され、その日のデータを統合するプロセスです。 古いレポートを生成する 1 週間または 1 か月のタイム ウィンドウの場合もあります。
ストリーミングによる最適なビッグデータ処理プラットフォームが Kafka や Spark などのオープン ソースであることを考えると、これらのプラットフォームでは他の異なる補完的なプラットフォームを使用できます。 これは、オープンソースであるため、より速く進化し、より多くのツールを使用することを意味します. このようにして、データ ストリームは他の場所から可変レートで途切れることなく受信されます。
ここで、最も広く知られている 2 つのデータ処理ツールを見て、それらを比較します。
アパッチ・カフカ
Apache Kafka は、継続的なデータ フローでストリーミング アプリケーションを作成するメッセージング システムです。 LinkedIn によって最初に作成された Kafka はログベースです。 ログは、新しい情報がファイルの末尾に追加されるため、基本的なストレージ形式です。

Kafka は、その主な特徴が高いスループットであるため、ビッグ データに最適なソリューションの 1 つです。 Apache Kafka を使用すると、バッチ処理をリアルタイムで変換することさえ可能です。
Apache Kafka は、アプリケーションがパブリッシュし、サブスクライブするアプリケーションがメッセージを受信するパブリッシュ/サブスクライブ メッセージング システムです。 メッセージの発行と受信の間の時間はミリ秒になる可能性があるため、Kafka ソリューションの待機時間は短くなります。
カフカの働き
Apache Kafka のアーキテクチャは、プロデューサー、コンシューマー、およびクラスター自体で構成されています。 プロデューサーは、クラスターにメッセージを発行する任意のアプリケーションです。 コンシューマーは、Kafka からメッセージを受信する任意のアプリケーションです。 Kafka クラスターは、メッセージング サービスの単一インスタンスとして機能する一連のノードです。
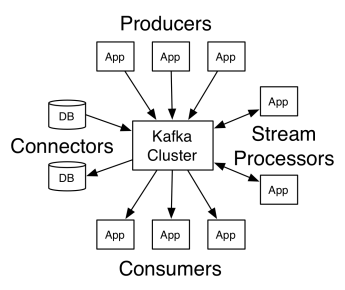
Kafka クラスターは、複数のブローカーで構成されています。 ブローカーは、プロデューサーからメッセージを受信してディスクに書き込む Kafka サーバーです。 各ブローカーはトピックのリストを管理し、各トピックはいくつかのパーティションに分割されます。
メッセージを受信した後、ブローカーはトピックごとに登録済みのコンシューマーにメッセージを送信します。
Apache Kafka の設定は、パーティションの場所、名前のリスト、トピックのリスト、使用可能なノードなどのクラスター メタデータを格納する Apache Zookeeper によって管理されます。 したがって、Zookeeper は、クラスターのさまざまな要素間の同期を維持します。
Kafka は分散システムであるため、Zookeeper は重要です。 つまり、書き込みと読み取りは複数のクライアントによって同時に行われます。 障害が発生した場合、Zookeeper は代替を選択し、操作を回復します。
ユースケース
Kafka は、特にメッセージング ツールとしての使用で人気を博しましたが、その汎用性はそれを超えており、以下の例のようにさまざまなシナリオで使用できます。
メッセージング
通信する当事者を切り離す非同期形式の通信。 このモデルでは、一方の当事者がデータをメッセージとして Kafka に送信するため、後で別のアプリケーションがそれを消費します。
活動追跡
ページビュー、クリック、データ入力など、Web サイトでのユーザーの操作を追跡するデータを保存および処理できるようにします。 このタイプのアクティビティでは、通常、大量のデータが生成されます。
指標
複数のソースからのデータと統計を集約して、一元化されたレポートを生成します。
ログ集計
他のシステムから発生したログ ファイルを一元的に集約して保存します。
ストリーム処理
データ パイプラインの処理は複数のステージで構成され、未加工データがトピックから消費され、集計、強化、または他のトピックへの変換が行われます。
これらの機能をサポートするために、プラットフォームは基本的に次の 3 つの API を提供します。
- Streams API: あるトピックからのデータを消費し、変換し、別のトピックに書き込むストリーム プロセッサとして機能します。
- コネクタ API: トピックをリレーショナル データベースなどの既存のシステムに接続できます。
- プロデューサーおよびコンシューマー API: アプリケーションが Kafka データを公開および使用できるようにします。
長所
複製、分割、順序付け
Kafka のメッセージは、セキュリティと配信速度を確保するために、到着順にクラスター ノード全体のパーティションにレプリケートされます。
データ変換
Apache Kafka では、バッチ ETL ストリーム API を使用してリアルタイムでバッチ処理を変換することも可能です。
シーケンシャル ディスク アクセス
Apache Kafka はメッセージをメモリではなくディスクに保持します。 実際、ほとんどの状況で、特にメモリ内のランダムな場所にあるデータへのアクセスを考慮すると、メモリ アクセスの方が高速です。 ただし、Kafka はシーケンシャル アクセスを行います。この場合、ディスクはより効率的です。
アパッチスパーク
Apache Spark は、クラスター間で並列データを処理するためのビッグ データ コンピューティング エンジンおよびライブラリ セットです。 Spark は、Hadoop と Map-Reduce プログラミング パラダイムを進化させたものです。 処理中にディスクにデータを保持しないメモリの効率的な使用により、100 倍高速になる可能性があります。

Spark は次の 3 つのレベルで編成されています。
- 低レベル API:このレベルには、ジョブを実行するための基本的な機能と、他のコンポーネントに必要なその他の機能が含まれています。 このレイヤーのその他の重要な機能は、セキュリティ、ネットワーク、スケジューリング、およびファイル システム HDFS、GlusterFS、Amazon S3 などへの論理アクセスの管理です。
- 構造化 API:構造化 API レベルは、Hive、Parquet、JSON などの形式で読み取ることができる DataSets または DataFrames によるデータ操作を扱います。 SparkSQL (SQL でクエリを記述できるようにする API) を使用すると、データを思い通りに操作できます。
- 高レベル: 高レベルでは、Spark Streaming、Spark MLlib、Spark GraphX などのさまざまなライブラリを備えた Spark エコシステムがあります。 これらは、ストリーミング インジェストと、クラッシュ リカバリ、従来の機械学習モデルの作成と検証、グラフとアルゴリズムの処理などの周辺プロセスの処理を担当します。
スパークの働き
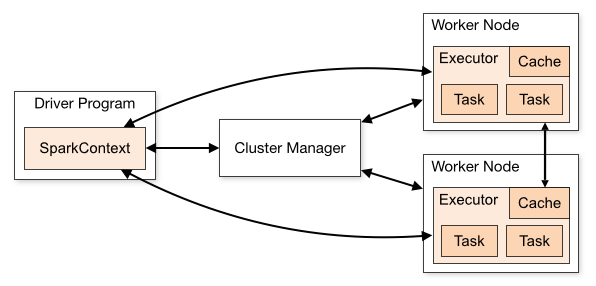
Spark アプリケーションのアーキテクチャは、次の 3 つの主要部分で構成されています。

ドライバー プログラム: データ処理の実行の調整を担当します。
Cluster Manager : クラスタ内のさまざまなマシンを管理するコンポーネントです。 Spark が分散して実行される場合にのみ必要です。
ワーカー ノード: プログラムのタスクを実行するマシンです。 Spark がマシン上でローカルに実行されている場合、Spark は Driver Program と Workes の役割を果たします。 このように Spark を実行する方法は、スタンドアロンと呼ばれます。
Spark コードは、さまざまな言語で記述できます。 Spark Shell と呼ばれる Spark コンソールは、データの学習と探索のために対話型です。
いわゆる Spark アプリケーションは、1 つ以上のジョブで構成され、大規模なデータ処理のサポートを可能にします。
実行について話すとき、Spark には 2 つのモードがあります。
- クライアント:ドライバーはクライアント上で直接実行され、リソース マネージャーを経由しません。
- クラスター:リソース マネージャーを介して Application Master で実行されるドライバー (クラスター モードでは、クライアントが切断されても、アプリケーションは実行を継続します)。
Resource Manager などのリンクされたサービスが各実行の必要性を識別し、最高のパフォーマンスを提供できるように、Spark を正しく使用する必要があります。 そのため、Spark ジョブを実行し、行われた呼び出しを構造化するための最良の方法を知るのは開発者次第です。このために、必要な方法でエグゼキュータ Spark を構造化および構成できます。
Spark ジョブは主にメモリを使用するため、作業ノード エグゼキュータの Spark 構成値を調整するのが一般的です。 Spark ワークロードによっては、特定の非標準の Spark 構成がより最適な実行を提供すると判断することができます。 この目的のために、さまざまな利用可能な構成オプションとデフォルトの Spark 構成自体との間の比較テストを実行できます。
ユースケース
Apache Spark は、リアルタイムかアーカイブか、構造化か非構造化かを問わず、膨大な量のデータの処理に役立ちます。 以下は、その一般的な使用例の一部です。
データ強化
多くの場合、企業は過去の顧客データとリアルタイムの行動データを組み合わせて使用します。 Spark は、継続的な ETL パイプラインを構築して、非構造化イベント データを構造化データに変換するのに役立ちます。
トリガー イベント検出
Spark Streaming を使用すると、潜在的な問題や不正行為を示す可能性のあるまれなまたは疑わしい動作を迅速に検出して対応できます。
複雑なセッション データ分析
Spark Streaming を使用すると、アプリケーションへのログイン後のアクティビティなど、ユーザーのセッションに関連するイベントをグループ化して分析できます。 この情報は、機械学習モデルを更新するために継続的に使用することもできます。
長所
反復処理
タスクがデータを繰り返し処理することである場合、Spark の回復力のある分散データセット (RDD) により、中間結果をディスクに書き込むことなく、複数のメモリ内マップ操作が可能になります。
グラフィック処理
GraphX API を使用した Spark の計算モデルは、グラフィックス処理に典型的な反復計算に優れています。
機械学習
Spark には MLlib があります。これは、メモリ内でも実行される既製のアルゴリズムを備えた組み込みの機械学習ライブラリです。
Kafka vs. Spark
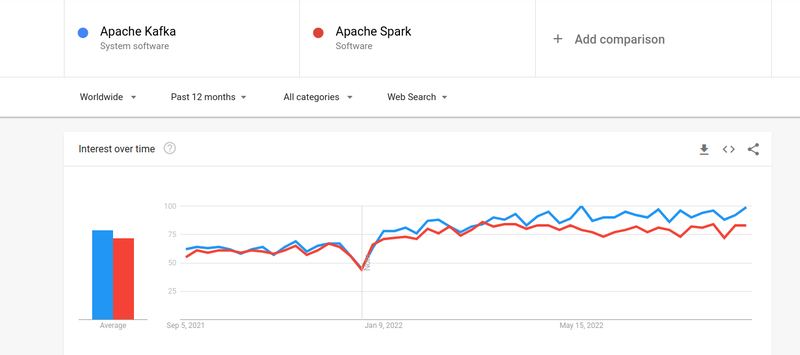
Kafka と Spark の両方に対する人々の関心はほぼ同じですが、両者にはいくつかの大きな違いがあります。 みてみましょう。
#1。 情報処理
Kafka は、アプリケーション間のデータ転送を担当するリアルタイムのデータ ストリーミングおよびストレージ ツールですが、完全なソリューションを構築するにはそれだけでは不十分です。 したがって、Spark など、Kafka が実行しないタスクには他のツールが必要です。 一方、Spark は、Kafka トピックからデータを取得し、結合されたスキーマに変換するバッチ優先のデータ処理プラットフォームです。
#2。 メモリ管理
Spark は、メモリ管理に堅牢な分散データセット (RDD) を使用します。 巨大なデータ セットを処理しようとする代わりに、クラスター内の複数のノードに分散します。 対照的に、Kafka は HDFS と同様のシーケンシャル アクセスを使用し、データをバッファー メモリに格納します。
#3。 ETL 変換
Spark と Kafka はどちらも ETL 変換プロセスをサポートしており、レコードをあるデータベースから別のデータベースに、通常はトランザクション ベース (OLTP) から分析ベース (OLAP) にコピーします。 ただし、ETL プロセスの機能が組み込まれている Spark とは異なり、Kafka はそれをサポートするために Streams API に依存しています。
#4。 データの永続性

Spark で RRD を使用すると、後で使用するためにデータを複数の場所に保存できますが、Kafka では、データを永続化するために構成でデータセット オブジェクトを定義する必要があります。
#5。 困難
Spark は完全なソリューションであり、さまざまな高水準プログラミング言語をサポートしているため、習得が容易です。 Kafka は、さまざまな API やサードパーティ モジュールに依存しているため、操作が難しくなる可能性があります。
#6。 回復
Spark と Kafka の両方が回復オプションを提供します。 Spark は RRD を使用しているため、データを継続的に保存でき、クラスターに障害が発生した場合は復旧できます。

Kafka はクラスター内のデータを継続的にレプリケートし、ブローカー間でレプリケーションを行います。これにより、障害が発生した場合に別のブローカーに移ることができます。
Spark と Kafka の類似点
| アパッチスパーク | アパッチ・カフカ |
| オープンソース | オープンソース |
| データ ストリーミング アプリケーションの構築 | データ ストリーミング アプリケーションの構築 |
| ステートフル処理をサポート | ステートフル処理をサポート |
| SQLをサポート | SQLをサポート |
最後の言葉
Kafka と Spark はどちらも、Scala と Java で記述されたオープンソース ツールであり、リアルタイムのデータ ストリーミング アプリケーションを構築できます。 これらには、ステートフル処理、SQL のサポート、ETL など、いくつかの共通点があります。 Kafka と Spark は、アプリケーション間のデータ転送の複雑さの問題を解決するのに役立つ補完的なツールとしても使用できます。