
使用 Kafka 和 Spark 开始数据处理
已发表: 2022-09-09大数据的处理是组织面临的最复杂的过程之一。 当您拥有大量实时数据时,该过程会变得更加复杂。
在这篇文章中,我们将了解什么是大数据处理,它是如何完成的,并探索 Apache Kafka 和 Spark——这两个最著名的数据处理工具!
什么是数据处理? 它是如何完成的?
数据处理被定义为任何操作或一组操作,无论是否使用自动化流程执行。 它可以被认为是根据逻辑和适当的解释倾向对信息的收集、排序和组织。

当用户访问数据库并获得搜索结果时,正是数据处理为他们提供了所需的结果。 作为搜索结果提取的信息是数据处理的结果。 这就是为什么信息技术的存在焦点集中在数据处理上。
传统的数据处理是使用简单的软件进行的。 然而,随着大数据的出现,情况发生了变化。 大数据是指容量可以超过一百 TB 和 PB 的信息。
此外,这些信息会定期更新。 示例包括来自联络中心、社交媒体、证券交易所交易数据等的数据。此类数据有时也称为数据流——一种恒定的、不受控制的数据流。 它的主要特点是数据没有明确的限制,因此无法说流何时开始或结束。
数据在到达目的地时被处理。 一些作者称其为实时或在线处理。 另一种方法是块、批处理或离线处理,其中数据块在几小时或几天的时间窗口中处理。 批处理通常是一个在晚上运行的过程,用于整合当天的数据。 有一周甚至一个月的时间窗口生成过时报告的情况。
鉴于通过流传输的最佳大数据处理平台是开源的,例如 Kafka 和 Spark,这些平台允许使用其他不同且互补的平台。 这意味着作为开源,它们发展得更快并使用更多工具。 这样,从其他地方以可变速率接收数据流,并且没有任何中断。
现在,我们将研究两个最广为人知的数据处理工具并进行比较:
阿帕奇卡夫卡
Apache Kafka 是一种消息传递系统,可创建具有连续数据流的流式应用程序。 Kafka 最初由 LinkedIn 创建,是基于日志的; 日志是一种基本的存储形式,因为每个新信息都添加到文件末尾。

Kafka 是大数据的最佳解决方案之一,因为它的主要特点是其高吞吐量。 使用 Apache Kafka,甚至可以实时转换批处理,
Apache Kafka 是一个发布-订阅消息系统,其中一个应用程序发布,一个订阅的应用程序接收消息。 发布和接收消息之间的时间可以是毫秒,因此 Kafka 解决方案具有低延迟。
卡夫卡的工作
Apache Kafka 的架构包括生产者、消费者和集群本身。 生产者是向集群发布消息的任何应用程序。 消费者是从 Kafka 接收消息的任何应用程序。 Kafka 集群是一组节点,用作消息服务的单个实例。
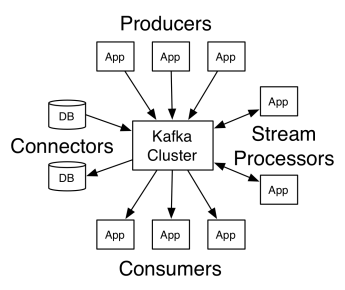
一个 Kafka 集群由多个代理组成。 代理是一个 Kafka 服务器,它接收来自生产者的消息并将它们写入磁盘。 每个broker管理一个topic列表,每个topic又分为若干个partition。
代理收到消息后,将消息发送给每个主题的注册消费者。
Apache Kafka 设置由 Apache Zookeeper 管理,它存储集群元数据,例如分区位置、名称列表、主题列表和可用节点。 因此,Zookeeper 保持集群不同元素之间的同步。
Zookeeper 很重要,因为 Kafka 是一个分布式系统; 也就是说,写入和读取是由多个客户端同时完成的。 当出现故障时,Zookeeper 会选择一个替换者并恢复操作。
用例
Kafka 变得流行起来,尤其是因为它用作消息传递工具,但它的多功能性还不止于此,它可以用于各种场景,如下面的示例所示。
消息传递
异步通信形式,将通信方解耦。 在此模型中,一方将数据作为消息发送到 Kafka,因此稍后另一个应用程序会使用它。
活动追踪
使您能够存储和处理跟踪用户与网站交互的数据,例如页面浏览量、点击量、数据输入等; 这种类型的活动通常会产生大量数据。
指标
涉及聚合来自多个来源的数据和统计数据以生成集中报告。
日志聚合
集中聚合和存储来自其他系统的日志文件。
流处理
数据管道的处理由多个阶段组成,其中原始数据从主题中消耗并聚合、丰富或转换为其他主题。
为了支持这些功能,平台本质上提供了三个 API:
- Streams API:它充当流处理器,使用来自一个主题的数据,对其进行转换,然后将其写入另一个主题。
- 连接器 API:它允许将主题连接到现有系统,例如关系数据库。
- 生产者和消费者 API:它允许应用程序发布和使用 Kafka 数据。
优点
复制、分区和有序
Kafka 中的消息按照它们到达的顺序跨集群节点的分区进行复制,以确保安全性和传递速度。
数据转换
借助 Apache Kafka,甚至可以使用批处理 ETL 流 API 实时转换批处理。
顺序磁盘访问
Apache Kafka 将消息保存在磁盘上而不是内存中,因为它应该更快。 事实上,在大多数情况下,内存访问速度更快,尤其是在考虑访问内存中随机位置的数据时。 但是,Kafka 进行顺序访问,在这种情况下,磁盘效率更高。
阿帕奇星火
Apache Spark 是一个大数据计算引擎和一组用于跨集群处理并行数据的库。 Spark 是 Hadoop 和 Map-Reduce 编程范式的演变。 由于它有效地使用了内存,并且在处理时不会将数据保存在磁盘上,因此它的速度可以提高 100 倍。

Spark 分为三个层次:
- 低级 API:此级别包含运行作业的基本功能和其他组件所需的其他功能。 该层的其他重要功能是管理安全、网络、调度和对文件系统 HDFS、GlusterFS、Amazon S3 等的逻辑访问。
- 结构化 API:结构化 API 级别通过 DataSet 或 DataFrame 处理数据操作,这些数据可以以 Hive、Parquet、JSON 等格式读取。 使用 SparkSQL(允许我们在 SQL 中编写查询的 API),我们可以按照我们想要的方式操作数据。
- 高级:在最高级别,我们拥有包含各种库的 Spark 生态系统,包括 Spark Streaming、Spark MLlib 和 Spark GraphX。 他们负责处理流式摄取和周边流程,例如崩溃恢复、创建和验证经典机器学习模型,以及处理图形和算法。
Spark的工作
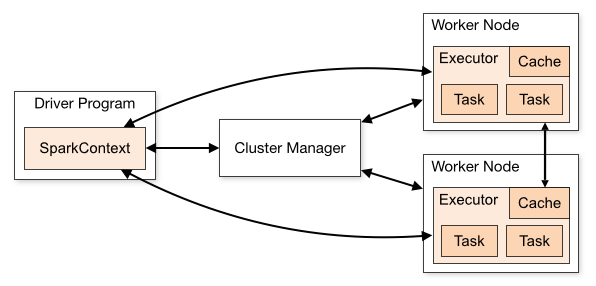
Spark 应用程序的架构由三个主要部分组成:

驱动程序:负责编排数据处理的执行。
集群管理器:它是负责管理集群中不同机器的组件。 仅当 Spark 以分布式方式运行时才需要。
工人节点:这些是执行程序任务的机器。 如果 Spark 在您的机器上本地运行,它将扮演驱动程序和工作角色。 这种运行 Spark 的方式称为 Standalone。
Spark 代码可以用多种不同的语言编写。 Spark 控制台(称为 Spark Shell)是交互式的,用于学习和探索数据。
所谓 Spark 应用由一个或多个 Jobs 组成,能够支持大规模数据处理。
当我们谈到执行时,Spark 有两种模式:
- 客户端:驱动直接在客户端运行,不经过资源管理器。
- Cluster:通过资源管理器在Application Master上运行的驱动程序(在Cluster模式下,如果客户端断开连接,应用程序将继续运行)。
必须正确使用 Spark,以便资源管理器等链接服务能够识别每次执行的需求,从而提供最佳性能。 因此,开发人员需要知道运行 Spark 作业的最佳方式,构建调用的结构,为此,您可以按照自己的方式构建和配置执行器 Spark。
Spark 作业主要使用内存,因此通常为工作节点执行器调整 Spark 配置值。 根据 Spark 工作负载,可以确定某个非标准 Spark 配置提供了更优化的执行。 为此,可以在各种可用配置选项和默认 Spark 配置本身之间进行比较测试。
用例
Apache Spark 有助于处理大量数据,无论是实时的还是存档的、结构化的还是非结构化的。 以下是它的一些流行用例。
数据丰富
公司通常将历史客户数据与实时行为数据结合使用。 Spark 可以帮助构建连续的 ETL 管道,将非结构化事件数据转换为结构化数据。
触发事件检测
Spark Streaming 允许快速检测和响应一些可能表明潜在问题或欺诈的罕见或可疑行为。
复杂的会话数据分析
使用 Spark Streaming,可以对与用户会话相关的事件(例如登录应用程序后的活动)进行分组和分析。 此信息还可用于持续更新机器学习模型。
优点
迭代处理
如果任务是重复处理数据,Spark 的弹性分布式数据集 (RDD) 允许多个内存映射操作,而无需将中间结果写入磁盘。
图形处理
Spark 的带有 GraphX API 的计算模型非常适合图形处理的典型迭代计算。
机器学习
Spark 有 MLlib——一个内置的机器学习库,它有现成的算法,也可以在内存中运行。
卡夫卡与火花
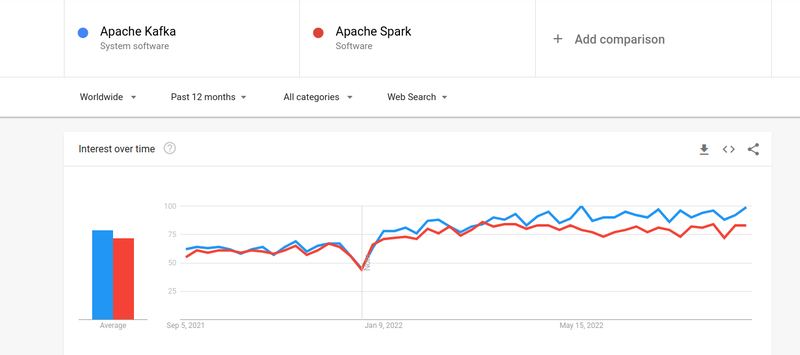
尽管人们对 Kafka 和 Spark 的兴趣几乎相似,但两者之间确实存在一些重大差异。 我们来看一下。
#1。 数据处理
Kafka 是一个实时数据流和存储工具,负责在应用程序之间传输数据,但不足以构建完整的解决方案。 因此,Kafka 没有的任务需要其他工具,例如 Spark。 另一方面,Spark 是一个批处理优先的数据处理平台,它从 Kafka 主题中提取数据并将其转换为组合模式。
#2。 内存管理
Spark 使用鲁棒分布式数据集 (RDD) 进行内存管理。 它不是试图处理庞大的数据集,而是将它们分布在集群中的多个节点上。 相比之下,Kafka 使用类似于 HDFS 的顺序访问,并将数据存储在缓冲存储器中。
#3。 ETL 转换
Spark 和 Kafka 都支持 ETL 转换过程,它将记录从一个数据库复制到另一个数据库,通常从事务基础 (OLTP) 到分析基础 (OLAP)。 然而,与内置 ETL 过程能力的 Spark 不同,Kafka 依赖于 Streams API 来支持它。
#4。 数据持久性

Spark 对 RRD 的使用允许您将数据存储在多个位置以供以后使用,而在 Kafka 中,您必须在配置中定义数据集对象才能持久化数据。
#5。 困难
Spark 是一个完整的解决方案,由于它支持各种高级编程语言,因此更易于学习。 Kafka 依赖于许多不同的 API 和第三方模块,这可能使其难以使用。
#6。 恢复
Spark 和 Kafka 都提供恢复选项。 Spark使用RRD,可以连续保存数据,如果集群出现故障,可以恢复。

Kafka 不断复制集群内的数据并跨代理进行复制,这允许您在出现故障时转移到不同的代理。
Spark 和 Kafka 的相似之处
| 阿帕奇星火 | 阿帕奇卡夫卡 |
| 开源 | 开源 |
| 构建数据流应用 | 构建数据流应用 |
| 支持有状态处理 | 支持有状态处理 |
| 支持 SQL | 支持 SQL |
最后的话
Kafka 和 Spark 都是用 Scala 和 Java 编写的开源工具,可让您构建实时数据流应用程序。 它们有几个共同点,包括状态处理、对 SQL 的支持和 ETL。 Kafka 和 Spark 也可以作为互补工具,帮助解决应用程序之间传输数据的复杂性问题。