
Mulai Pemrosesan Data dengan Kafka dan Spark
Diterbitkan: 2022-09-09Pemrosesan data besar adalah salah satu prosedur paling kompleks yang dihadapi organisasi. Prosesnya menjadi lebih rumit ketika Anda memiliki volume data real-time yang besar.
Dalam posting ini, kita akan menemukan apa itu pemrosesan data besar, bagaimana hal itu dilakukan, dan menjelajahi Apache Kafka dan Spark – dua alat pemrosesan data paling terkenal!
Apa itu Pemrosesan Data? Bagaimana cara melakukannya?
Pemrosesan data didefinisikan sebagai setiap operasi atau serangkaian operasi, baik yang dilakukan dengan menggunakan proses otomatis maupun tidak. Ini dapat dianggap sebagai pengumpulan, pengurutan, dan pengorganisasian informasi menurut disposisi yang logis dan tepat untuk interpretasi.

Saat pengguna mengakses database dan mendapatkan hasil untuk pencarian mereka, pemrosesan datalah yang memberi mereka hasil yang mereka butuhkan. Informasi yang digali sebagai hasil pencarian merupakan hasil pengolahan data. Itulah sebabnya teknologi informasi memiliki fokus keberadaannya yang berpusat pada pengolahan data.
Pengolahan data tradisional dilakukan dengan menggunakan perangkat lunak sederhana. Namun, dengan munculnya Big Data, banyak hal telah berubah. Big Data mengacu pada informasi yang volumenya bisa lebih dari seratus terabyte dan petabyte.
Selain itu, informasi ini diperbarui secara berkala. Contohnya termasuk data yang berasal dari pusat kontak, media sosial, data perdagangan bursa, dll. Data tersebut terkadang juga disebut aliran data- aliran data yang konstan dan tidak terkendali. Karakteristik utamanya adalah bahwa data tidak memiliki batasan yang ditentukan, sehingga tidak mungkin untuk mengatakan kapan aliran dimulai atau berakhir.
Data diproses saat tiba di tempat tujuan. Beberapa penulis menyebutnya pemrosesan real-time atau online. Pendekatan yang berbeda adalah pemrosesan blok, batch, atau offline, di mana blok data diproses dalam jendela waktu jam atau hari. Seringkali batch adalah proses yang berjalan di malam hari, mengkonsolidasikan data hari itu. Ada kasus jendela waktu seminggu atau bahkan sebulan menghasilkan laporan usang.
Mengingat bahwa platform pemrosesan Big Data terbaik melalui streaming adalah sumber terbuka seperti Kafka dan Spark, platform ini memungkinkan penggunaan yang berbeda dan saling melengkapi. Ini berarti bahwa sebagai open source, mereka berkembang lebih cepat dan menggunakan lebih banyak alat. Dengan cara ini, aliran data diterima dari tempat lain dengan kecepatan yang bervariasi dan tanpa gangguan.
Sekarang, kita akan melihat dua alat pengolah data yang paling dikenal dan membandingkannya:
Apache Kafka
Apache Kafka adalah sistem perpesanan yang membuat aplikasi streaming dengan aliran data berkelanjutan. Awalnya dibuat oleh LinkedIn, Kafka berbasis log; log adalah bentuk dasar penyimpanan karena setiap informasi baru ditambahkan ke akhir file.

Kafka adalah salah satu solusi terbaik untuk big data karena karakteristik utamanya adalah throughput yang tinggi. Dengan Apache Kafka, bahkan dimungkinkan untuk mengubah pemrosesan batch secara real-time,
Apache Kafka adalah sistem pesan publish-subscribe di mana aplikasi menerbitkan dan aplikasi yang berlangganan menerima pesan. Waktu antara penerbitan dan penerimaan pesan bisa milidetik, sehingga solusi Kafka memiliki latensi rendah.
Bekerja di Kafka
Arsitektur Apache Kafka terdiri dari produsen, konsumen, dan cluster itu sendiri. Produser adalah aplikasi apa pun yang memublikasikan pesan ke cluster. Konsumen adalah aplikasi apa pun yang menerima pesan dari Kafka. Cluster Kafka adalah sekumpulan node yang berfungsi sebagai instance tunggal dari layanan pesan.
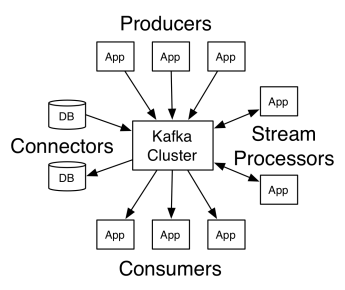
Sebuah cluster Kafka terdiri dari beberapa broker. Pialang adalah server Kafka yang menerima pesan dari produsen dan menulisnya ke disk. Setiap broker mengelola daftar topik, dan setiap topik dibagi menjadi beberapa partisi.
Setelah menerima pesan, broker mengirimkannya ke konsumen terdaftar untuk setiap topik.
Pengaturan Apache Kafka dikelola oleh Apache Zookeeper, yang menyimpan metadata cluster seperti lokasi partisi, daftar nama, daftar topik, dan node yang tersedia. Dengan demikian, Zookeeper mempertahankan sinkronisasi antara berbagai elemen cluster.
Zookeeper penting karena Kafka adalah sistem terdistribusi; yaitu, menulis dan membaca dilakukan oleh beberapa klien secara bersamaan. Ketika ada kegagalan, Zookeeper memilih pengganti dan memulihkan operasi.
Gunakan Kasus
Kafka menjadi populer, terutama karena penggunaannya sebagai alat perpesanan, tetapi keserbagunaannya melampaui itu, dan dapat digunakan dalam berbagai skenario, seperti pada contoh di bawah ini.
Perpesanan
Bentuk komunikasi asinkron yang memisahkan pihak-pihak yang berkomunikasi. Dalam model ini, satu pihak mengirimkan data sebagai pesan ke Kafka, sehingga aplikasi lain kemudian mengkonsumsinya.
Pelacakan aktivitas
Memungkinkan Anda menyimpan dan memproses data pelacakan interaksi pengguna dengan situs web, seperti tampilan halaman, klik, entri data, dll.; jenis aktivitas ini biasanya menghasilkan volume data yang besar.
Metrik
Melibatkan pengumpulan data dan statistik dari berbagai sumber untuk menghasilkan laporan terpusat.
Agregasi log
Mengumpulkan dan menyimpan file log yang berasal dari sistem lain secara terpusat.
Pemrosesan Aliran
Pemrosesan jalur pipa data terdiri dari beberapa tahap, di mana data mentah dikonsumsi dari topik dan dikumpulkan, diperkaya, atau diubah menjadi topik lain.
Untuk mendukung fitur ini, platform pada dasarnya menyediakan tiga API:
- Streams API: Bertindak sebagai pemroses aliran yang menggunakan data dari satu topik, mengubahnya, dan menulisnya ke topik lain.
- Connectors API: Memungkinkan menghubungkan topik ke sistem yang ada, seperti database relasional.
- Producer and Consumer APIs: Memungkinkan aplikasi untuk memublikasikan dan menggunakan data Kafka.
kelebihan
Direplikasi, Dipartisi, dan Diurutkan
Pesan di Kafka direplikasi di seluruh partisi di seluruh node cluster sesuai urutannya untuk memastikan keamanan dan kecepatan pengiriman.
Transformasi Data
Dengan Apache Kafka, bahkan dimungkinkan untuk mengubah pemrosesan batch secara real-time menggunakan API aliran ETL batch.
Akses disk berurutan
Apache Kafka menyimpan pesan di disk dan bukan di memori, karena seharusnya lebih cepat. Faktanya, akses memori lebih cepat di sebagian besar situasi, terutama ketika mempertimbangkan untuk mengakses data yang berada di lokasi acak di memori. Namun, Kafka melakukan akses sekuensial, dan dalam hal ini, disk lebih efisien.
Apache Spark
Apache Spark adalah mesin komputasi data besar dan kumpulan perpustakaan untuk memproses data paralel di seluruh cluster. Spark adalah evolusi dari Hadoop dan paradigma pemrograman Map-Reduce. Ini bisa 100x kali lebih cepat berkat penggunaan memori yang efisien yang tidak menyimpan data pada disk saat memproses.

Spark diatur pada tiga tingkatan:
- API Tingkat Rendah: Tingkat ini berisi fungsionalitas dasar untuk menjalankan tugas dan fungsionalitas lain yang diperlukan oleh komponen lain. Fungsi penting lainnya dari lapisan ini adalah manajemen keamanan, jaringan, penjadwalan, dan akses logis ke sistem file HDFS, GlusterFS, Amazon S3, dan lainnya.
- API Terstruktur: Level API Terstruktur berhubungan dengan manipulasi data melalui DataSet atau DataFrames, yang dapat dibaca dalam format seperti Hive, Parket, JSON, dan lainnya. Menggunakan SparkSQL (API yang memungkinkan kita untuk menulis kueri dalam SQL), kita dapat memanipulasi data seperti yang kita inginkan.
- Tingkat Tinggi: Di tingkat tertinggi, kami memiliki ekosistem Spark dengan berbagai perpustakaan, termasuk Spark Streaming, Spark MLlib, dan Spark GraphX. Mereka bertanggung jawab untuk menangani penyerapan streaming dan proses di sekitarnya, seperti pemulihan kerusakan, membuat dan memvalidasi model pembelajaran mesin klasik, dan menangani grafik dan algoritme.
Bekerja di Spark
Arsitektur aplikasi Spark terdiri dari tiga bagian utama:

Program Driver : Bertanggung jawab untuk mengatur pelaksanaan pemrosesan data.
Cluster Manager : Ini adalah komponen yang bertanggung jawab untuk mengelola mesin yang berbeda dalam sebuah cluster. Hanya diperlukan jika Spark berjalan terdistribusi.
Pekerja Nodes : Ini adalah mesin yang melakukan tugas-tugas program. Jika Spark dijalankan secara lokal di mesin Anda, itu akan memainkan peran Program Driver dan Pekerjaan. Cara menjalankan Spark ini disebut Standalone.
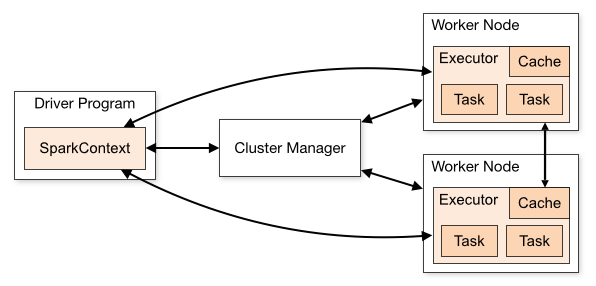
Kode percikan dapat ditulis dalam beberapa bahasa yang berbeda. Konsol Spark, yang disebut Spark Shell, bersifat interaktif untuk mempelajari dan menjelajahi data.
Aplikasi Spark yang disebut terdiri dari satu atau lebih Pekerjaan, memungkinkan dukungan pemrosesan data skala besar.
Ketika kita berbicara tentang eksekusi, Spark memiliki dua mode:
- Klien: Driver berjalan langsung pada klien, yang tidak melalui Resource Manager.
- Cluster: Driver yang berjalan pada Master Aplikasi melalui Resource Manager (Dalam mode Cluster, jika klien terputus, aplikasi akan terus berjalan).
Perlu menggunakan Spark dengan benar sehingga layanan tertaut, seperti Resource Manager, dapat mengidentifikasi kebutuhan untuk setiap eksekusi, memberikan kinerja terbaik. Jadi terserah pengembang untuk mengetahui cara terbaik untuk menjalankan pekerjaan Spark mereka, menyusun panggilan yang dibuat, dan untuk ini, Anda dapat menyusun dan mengonfigurasi pelaksana Spark seperti yang Anda inginkan.
Pekerjaan Spark terutama menggunakan memori, jadi biasanya menyesuaikan nilai konfigurasi Spark untuk pelaksana node kerja. Bergantung pada beban kerja Spark, dimungkinkan untuk menentukan bahwa konfigurasi Spark non-standar tertentu menyediakan eksekusi yang lebih optimal. Untuk tujuan ini, tes perbandingan antara berbagai opsi konfigurasi yang tersedia dan konfigurasi Spark default itu sendiri dapat dilakukan.
Menggunakan Kasus
Apache Spark membantu dalam memproses sejumlah besar data, baik real-time atau diarsipkan, terstruktur atau tidak terstruktur. Berikut ini adalah beberapa kasus penggunaan yang populer.
Pengayaan Data
Seringkali perusahaan menggunakan kombinasi data pelanggan historis dengan data perilaku waktu nyata. Spark dapat membantu membangun saluran ETL berkelanjutan untuk mengonversi data peristiwa tidak terstruktur menjadi data terstruktur.
Deteksi Peristiwa Pemicu
Spark Streaming memungkinkan deteksi dan respons cepat terhadap beberapa perilaku langka atau mencurigakan yang dapat mengindikasikan potensi masalah atau penipuan.
Analisis Data Sesi Kompleks
Menggunakan Spark Streaming, peristiwa yang terkait dengan sesi pengguna, seperti aktivitas mereka setelah masuk ke aplikasi, dapat dikelompokkan dan dianalisis. Informasi ini juga dapat digunakan terus menerus untuk memperbarui model pembelajaran mesin.
kelebihan
Pemrosesan berulang
Jika tugasnya adalah memproses data berulang kali, Dataset Terdistribusi (RDD) Spark yang tangguh memungkinkan beberapa operasi peta dalam memori tanpa harus menulis hasil sementara ke disk.
Pemrosesan grafis
Model komputasi Spark dengan GraphX API sangat baik untuk perhitungan berulang yang khas dari pemrosesan grafis.
Pembelajaran mesin
Spark memiliki MLlib — perpustakaan pembelajaran mesin bawaan yang memiliki algoritme siap pakai yang juga berjalan di memori.
Kafka vs. Spark
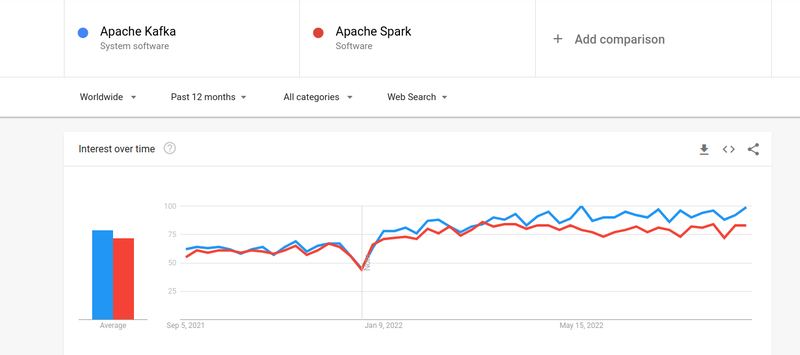
Meskipun minat orang-orang di Kafka dan Spark hampir serupa, ada beberapa perbedaan besar di antara keduanya; Mari kita lihat.
#1. Pengolahan data
Kafka adalah alat streaming dan penyimpanan data real-time yang bertanggung jawab untuk mentransfer data antar aplikasi, tetapi itu tidak cukup untuk membangun solusi yang lengkap. Oleh karena itu, alat lain diperlukan untuk tugas yang tidak dilakukan Kafka, seperti Spark. Spark, di sisi lain, adalah platform pemrosesan data batch pertama yang mengambil data dari topik Kafka dan mengubahnya menjadi skema gabungan.
#2. Manajemen memori
Spark menggunakan Robust Distributed Datasets (RDD) untuk manajemen memori. Alih-alih mencoba memproses kumpulan data besar, ini mendistribusikannya ke beberapa node dalam sebuah cluster. Sebaliknya, Kafka menggunakan akses sekuensial yang mirip dengan HDFS dan menyimpan data dalam memori buffer.
#3. Transformasi ETL
Baik Spark dan Kafka mendukung proses transformasi ETL, yang menyalin catatan dari satu database ke database lainnya, biasanya dari basis transaksional (OLTP) ke basis analitis (OLAP). Namun, tidak seperti Spark, yang hadir dengan kemampuan bawaan untuk proses ETL, Kafka mengandalkan Streams API untuk mendukungnya.
#4. Persistensi Data

Penggunaan RRD oleh Spark memungkinkan Anda untuk menyimpan data di beberapa lokasi untuk digunakan nanti, sedangkan di Kafka, Anda harus mendefinisikan objek kumpulan data dalam konfigurasi untuk mempertahankan data.
#5. Kesulitan
Spark merupakan solusi yang lengkap dan lebih mudah dipelajari karena dukungannya terhadap berbagai bahasa pemrograman tingkat tinggi. Kafka bergantung pada sejumlah API dan modul pihak ketiga yang berbeda, yang dapat menyulitkan untuk digunakan.
#6. Pemulihan
Baik Spark dan Kafka menyediakan opsi pemulihan. Spark menggunakan RRD, yang memungkinkannya untuk menyimpan data secara terus menerus, dan jika ada kegagalan cluster, itu dapat dipulihkan.

Kafka terus-menerus mereplikasi data di dalam cluster dan replikasi di seluruh broker, yang memungkinkan Anda untuk beralih ke broker yang berbeda jika ada kegagalan.
Kesamaan antara Spark dan Kafka
| Apache Spark | Apache Kafka |
| Sumber Terbuka | Sumber Terbuka |
| Bangun Aplikasi Streaming Data | Bangun Aplikasi Streaming Data |
| Mendukung Pemrosesan Stateful | Mendukung Pemrosesan Stateful |
| Mendukung SQL | Mendukung SQL |
Kata-kata Terakhir
Kafka dan Spark keduanya merupakan alat sumber terbuka yang ditulis dalam Scala dan Java, yang memungkinkan Anda membuat aplikasi streaming data waktu nyata. Mereka memiliki beberapa kesamaan, termasuk pemrosesan stateful, dukungan untuk SQL, dan ETL. Kafka dan Spark juga dapat digunakan sebagai alat pelengkap untuk membantu menyelesaikan masalah rumitnya transfer data antar aplikasi.