
使用 Kafka 和 Spark 開始數據處理
已發表: 2022-09-09大數據的處理是組織面臨的最複雜的過程之一。 當您擁有大量實時數據時,該過程會變得更加複雜。
在這篇文章中,我們將了解什麼是大數據處理,它是如何完成的,並探索 Apache Kafka 和 Spark——這兩個最著名的數據處理工具!
什麼是數據處理? 它是如何完成的?
數據處理被定義為任何操作或一組操作,無論是否使用自動化流程執行。 它可以被認為是根據邏輯和適當的解釋傾向對信息的收集、排序和組織。

當用戶訪問數據庫並獲得搜索結果時,正是數據處理為他們提供了所需的結果。 作為搜索結果提取的信息是數據處理的結果。 這就是為什麼信息技術的存在焦點集中在數據處理上。
傳統的數據處理是使用簡單的軟件進行的。 然而,隨著大數據的出現,情況發生了變化。 大數據是指容量可以超過一百 TB 和 PB 的信息。
此外,這些信息會定期更新。 示例包括來自聯絡中心、社交媒體、證券交易所交易數據等的數據。此類數據有時也稱為數據流——一種恆定的、不受控制的數據流。 它的主要特點是數據沒有明確的限制,因此無法說流何時開始或結束。
數據在到達目的地時被處理。 一些作者稱其為實時或在線處理。 另一種方法是塊、批處理或離線處理,其中數據塊在幾小時或幾天的時間窗口中處理。 批處理通常是一個在晚上運行的過程,用於整合當天的數據。 有一周甚至一個月的時間窗口生成過時報告的情況。
鑑於通過流傳輸的最佳大數據處理平台是開源的,例如 Kafka 和 Spark,這些平台允許使用其他不同且互補的平台。 這意味著作為開源,它們發展得更快並使用更多工具。 這樣,從其他地方以可變速率接收數據流,並且沒有任何中斷。
現在,我們將研究兩個最廣為人知的數據處理工具並進行比較:
阿帕奇卡夫卡
Apache Kafka 是一種消息傳遞系統,可創建具有連續數據流的流式應用程序。 Kafka 最初由 LinkedIn 創建,是基於日誌的; 日誌是一種基本的存儲形式,因為每個新信息都添加到文件末尾。

Kafka 是大數據的最佳解決方案之一,因為它的主要特點是其高吞吐量。 使用 Apache Kafka,甚至可以實時轉換批處理,
Apache Kafka 是一個發布-訂閱消息系統,其中一個應用程序發布,一個訂閱的應用程序接收消息。 發布和接收消息之間的時間可以是毫秒,因此 Kafka 解決方案具有低延遲。
卡夫卡的工作
Apache Kafka 的架構包括生產者、消費者和集群本身。 生產者是向集群發布消息的任何應用程序。 消費者是從 Kafka 接收消息的任何應用程序。 Kafka 集群是一組節點,用作消息服務的單個實例。
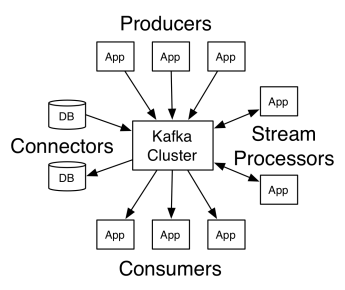
一個 Kafka 集群由多個代理組成。 代理是一個 Kafka 服務器,它接收來自生產者的消息並將它們寫入磁盤。 每個broker管理一個topic列表,每個topic又分為若干個partition。
代理收到消息後,將消息發送給每個主題的註冊消費者。
Apache Kafka 設置由 Apache Zookeeper 管理,它存儲集群元數據,例如分區位置、名稱列表、主題列表和可用節點。 因此,Zookeeper 保持集群不同元素之間的同步。
Zookeeper 很重要,因為 Kafka 是一個分佈式系統; 也就是說,寫入和讀取是由多個客戶端同時完成的。 當出現故障時,Zookeeper 會選擇一個替換者並恢復操作。
用例
Kafka 變得流行起來,尤其是因為它用作消息傳遞工具,但它的多功能性還不止於此,它可以用於各種場景,如下面的示例所示。
消息傳遞
異步通信形式,將通信方解耦。 在此模型中,一方將數據作為消息發送到 Kafka,因此稍後另一個應用程序會使用它。
活動追踪
使您能夠存儲和處理跟踪用戶與網站交互的數據,例如頁面瀏覽量、點擊量、數據輸入等; 這種類型的活動通常會產生大量數據。
指標
涉及聚合來自多個來源的數據和統計數據以生成集中報告。
日誌聚合
集中聚合和存儲來自其他系統的日誌文件。
流處理
數據管道的處理由多個階段組成,其中原始數據從主題中消耗並聚合、豐富或轉換為其他主題。
為了支持這些功能,平臺本質上提供了三個 API:
- Streams API:它充當流處理器,使用來自一個主題的數據,對其進行轉換,然後將其寫入另一個主題。
- 連接器 API:它允許將主題連接到現有系統,例如關係數據庫。
- 生產者和消費者 API:它允許應用程序發布和使用 Kafka 數據。
優點
複製、分區和有序
Kafka 中的消息按照它們到達的順序跨集群節點的分區進行複制,以確保安全性和傳遞速度。
數據轉換
借助 Apache Kafka,甚至可以使用批處理 ETL 流 API 實時轉換批處理。
順序磁盤訪問
Apache Kafka 將消息保存在磁盤上而不是內存中,因為它應該更快。 事實上,在大多數情況下,內存訪問速度更快,尤其是在考慮訪問內存中隨機位置的數據時。 但是,Kafka 進行順序訪問,在這種情況下,磁盤效率更高。
阿帕奇星火
Apache Spark 是一個大數據計算引擎和一組用於跨集群處理並行數據的庫。 Spark 是 Hadoop 和 Map-Reduce 編程範式的演變。 由於它有效地使用了內存,並且在處理時不會將數據保存在磁盤上,因此它的速度可以提高 100 倍。

Spark 分為三個層次:
- 低級 API:此級別包含運行作業的基本功能和其他組件所需的其他功能。 該層的其他重要功能是管理安全、網絡、調度和對文件系統 HDFS、GlusterFS、Amazon S3 等的邏輯訪問。
- 結構化 API:結構化 API 級別通過 DataSet 或 DataFrame 處理數據操作,這些數據可以以 Hive、Parquet、JSON 等格式讀取。 使用 SparkSQL(允許我們在 SQL 中編寫查詢的 API),我們可以按照我們想要的方式操作數據。
- 高級:在最高級別,我們擁有包含各種庫的 Spark 生態系統,包括 Spark Streaming、Spark MLlib 和 Spark GraphX。 他們負責處理流式攝取和周邊流程,例如崩潰恢復、創建和驗證經典機器學習模型,以及處理圖形和算法。
Spark的工作
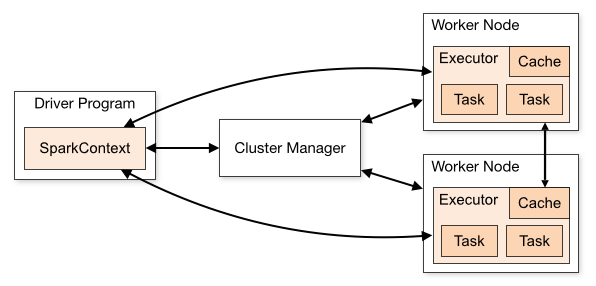
Spark 應用程序的架構由三個主要部分組成:

驅動程序:負責編排數據處理的執行。
集群管理器:它是負責管理集群中不同機器的組件。 僅當 Spark 以分佈式方式運行時才需要。
工人節點:這些是執行程序任務的機器。 如果 Spark 在您的機器上本地運行,它將扮演驅動程序和工作角色。 這種運行 Spark 的方式稱為 Standalone。
Spark 代碼可以用多種不同的語言編寫。 Spark 控制台(稱為 Spark Shell)是交互式的,用於學習和探索數據。
所謂 Spark 應用由一個或多個 Jobs 組成,能夠支持大規模數據處理。
當我們談到執行時,Spark 有兩種模式:
- 客戶端:驅動直接在客戶端運行,不經過資源管理器。
- Cluster:通過資源管理器在Application Master上運行的驅動程序(在Cluster模式下,如果客戶端斷開連接,應用程序將繼續運行)。
必須正確使用 Spark,以便資源管理器等鏈接服務能夠識別每次執行的需求,從而提供最佳性能。 因此,開發人員需要知道運行 Spark 作業的最佳方式,構建調用的結構,為此,您可以按照自己的方式構建和配置執行器 Spark。
Spark 作業主要使用內存,因此通常為工作節點執行器調整 Spark 配置值。 根據 Spark 工作負載,可以確定某個非標準 Spark 配置提供了更優化的執行。 為此,可以在各種可用配置選項和默認 Spark 配置本身之間進行比較測試。
用例
Apache Spark 有助於處理大量數據,無論是實時的還是存檔的、結構化的還是非結構化的。 以下是它的一些流行用例。
數據豐富
公司通常將歷史客戶數據與實時行為數據結合使用。 Spark 可以幫助構建連續的 ETL 管道,將非結構化事件數據轉換為結構化數據。
觸發事件檢測
Spark Streaming 允許快速檢測和響應一些可能表明潛在問題或欺詐的罕見或可疑行為。
複雜的會話數據分析
使用 Spark Streaming,可以對與用戶會話相關的事件(例如登錄應用程序後的活動)進行分組和分析。 此信息還可用於持續更新機器學習模型。
優點
迭代處理
如果任務是重複處理數據,Spark 的彈性分佈式數據集 (RDD) 允許多個內存映射操作,而無需將中間結果寫入磁盤。
圖形處理
Spark 的帶有 GraphX API 的計算模型非常適合圖形處理的典型迭代計算。
機器學習
Spark 有 MLlib——一個內置的機器學習庫,它有現成的算法,也可以在內存中運行。
卡夫卡與火花
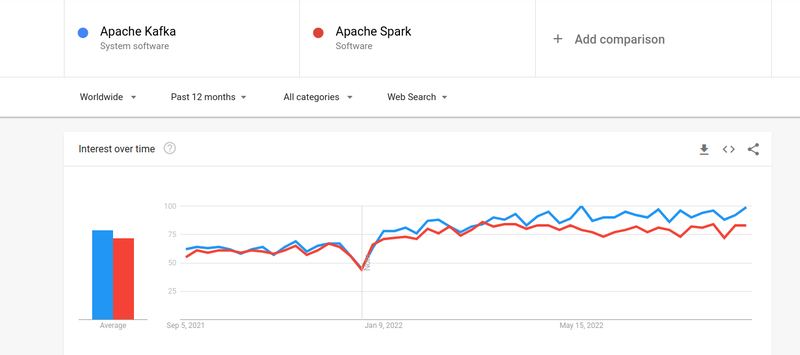
儘管人們對 Kafka 和 Spark 的興趣幾乎相似,但兩者之間確實存在一些重大差異。 我們來看一下。
#1。 數據處理
Kafka 是一個實時數據流和存儲工具,負責在應用程序之間傳輸數據,但不足以構建完整的解決方案。 因此,Kafka 沒有的任務需要其他工具,例如 Spark。 另一方面,Spark 是一個批處理優先的數據處理平台,它從 Kafka 主題中提取數據並將其轉換為組合模式。
#2。 內存管理
Spark 使用魯棒分佈式數據集 (RDD) 進行內存管理。 它不是試圖處理龐大的數據集,而是將它們分佈在集群中的多個節點上。 相比之下,Kafka 使用類似於 HDFS 的順序訪問,並將數據存儲在緩衝存儲器中。
#3。 ETL 轉換
Spark 和 Kafka 都支持 ETL 轉換過程,該過程將記錄從一個數據庫複製到另一個數據庫,通常是從事務基礎 (OLTP) 到分析基礎 (OLAP)。 然而,與內置 ETL 過程能力的 Spark 不同,Kafka 依賴於 Streams API 來支持它。
#4。 數據持久性

Spark 對 RRD 的使用允許您將數據存儲在多個位置以供以後使用,而在 Kafka 中,您必須在配置中定義數據集對象才能持久化數據。
#5。 困難
Spark 是一個完整的解決方案,由於它支持各種高級編程語言,因此更易於學習。 Kafka 依賴於許多不同的 API 和第三方模塊,這可能使其難以使用。
#6。 恢復
Spark 和 Kafka 都提供恢復選項。 Spark使用RRD,可以連續保存數據,如果集群出現故障,可以恢復。

Kafka 不斷複製集群內的數據並跨代理複製,這允許您在出現故障時轉移到不同的代理。
Spark 和 Kafka 的相似之處
| 阿帕奇星火 | 阿帕奇卡夫卡 |
| 開源 | 開源 |
| 構建數據流應用 | 構建數據流應用 |
| 支持有狀態處理 | 支持有狀態處理 |
| 支持 SQL | 支持 SQL |
最後的話
Kafka 和 Spark 都是用 Scala 和 Java 編寫的開源工具,可讓您構建實時數據流應用程序。 它們有幾個共同點,包括狀態處理、對 SQL 的支持和 ETL。 Kafka 和 Spark 也可以作為互補工具,幫助解決應用程序之間傳輸數據的複雜性問題。