
เริ่มการประมวลผลข้อมูลด้วย Kafka และ Spark
เผยแพร่แล้ว: 2022-09-09การประมวลผลข้อมูลขนาดใหญ่เป็นหนึ่งในขั้นตอนที่ซับซ้อนที่สุดที่องค์กรต้องเผชิญ กระบวนการจะซับซ้อนมากขึ้นเมื่อคุณมีข้อมูลแบบเรียลไทม์จำนวนมาก
ในโพสต์นี้ เราจะค้นพบว่าการประมวลผลข้อมูลขนาดใหญ่คืออะไร ทำอย่างไร และสำรวจ Apache Kafka และ Spark ซึ่งเป็นเครื่องมือประมวลผลข้อมูลที่มีชื่อเสียงที่สุดสองอย่าง!
การประมวลผลข้อมูลคืออะไร? มันทำอย่างไร?
การประมวลผลข้อมูลถูกกำหนดให้เป็นการดำเนินการหรือชุดของการดำเนินการใดๆ ไม่ว่าจะดำเนินการโดยใช้กระบวนการอัตโนมัติหรือไม่ก็ตาม สามารถคิดได้ว่าเป็นการรวบรวม การจัดลำดับ และการจัดข้อมูลตามลักษณะตรรกะและเหมาะสมสำหรับการตีความ

เมื่อผู้ใช้เข้าถึงฐานข้อมูลและได้รับผลลัพธ์สำหรับการค้นหา การประมวลผลข้อมูลจะได้รับผลลัพธ์ที่ต้องการ ข้อมูลที่ดึงออกมาเป็นผลการค้นหาเป็นผลมาจากการประมวลผลข้อมูล นั่นคือเหตุผลที่เทคโนโลยีสารสนเทศให้ความสำคัญกับการดำรงอยู่โดยมีศูนย์กลางอยู่ที่การประมวลผลข้อมูล
การประมวลผลข้อมูลแบบดั้งเดิมดำเนินการโดยใช้ซอฟต์แวร์อย่างง่าย อย่างไรก็ตาม ด้วยการเกิดขึ้นของ Big Data สิ่งต่างๆ ได้เปลี่ยนไป บิ๊กดาต้าหมายถึงข้อมูลที่มีปริมาณมากกว่าร้อยเทราไบต์และเพตาไบต์
นอกจากนี้ ข้อมูลนี้ได้รับการปรับปรุงอย่างสม่ำเสมอ ตัวอย่างรวมถึงข้อมูลที่มาจากคอนแทคเซ็นเตอร์ โซเชียลมีเดีย ข้อมูลการซื้อขายหุ้น ฯลฯ ข้อมูลดังกล่าวบางครั้งเรียกว่ากระแสข้อมูล ซึ่งเป็นกระแสข้อมูลคงที่และไม่มีการควบคุม ลักษณะสำคัญของมันคือข้อมูลไม่มีขีดจำกัดที่กำหนดไว้ ดังนั้นจึงเป็นไปไม่ได้ที่จะบอกว่าสตรีมเริ่มต้นหรือสิ้นสุดเมื่อใด
ข้อมูลจะถูกประมวลผลเมื่อถึงปลายทาง ผู้เขียนบางคนเรียกว่าการประมวลผลแบบเรียลไทม์หรือออนไลน์ วิธีอื่นคือการประมวลผลแบบบล็อก แบบกลุ่ม หรือแบบออฟไลน์ ซึ่งกลุ่มของข้อมูลจะได้รับการประมวลผลในกรอบเวลาเป็นชั่วโมงหรือเป็นวัน บ่อยครั้งที่แบทช์เป็นกระบวนการที่ทำงานในเวลากลางคืน โดยรวบรวมข้อมูลของวันนั้น มีบางกรณีของกรอบเวลาของสัปดาห์หรือแม้แต่เดือนที่สร้างรายงานที่ล้าสมัย
เนื่องจากแพลตฟอร์มประมวลผล Big Data ที่ดีที่สุดผ่านการสตรีมเป็นโอเพ่นซอร์ส เช่น Kafka และ Spark แพลตฟอร์มเหล่านี้จึงอนุญาตให้ใช้แพลตฟอร์มอื่นที่แตกต่างและเสริมกันได้ ซึ่งหมายความว่าเป็นโอเพ่นซอร์ส พวกเขาพัฒนาเร็วขึ้นและใช้เครื่องมือมากขึ้น ด้วยวิธีนี้ กระแสข้อมูลจะได้รับจากที่อื่นในอัตราผันแปรและไม่มีการหยุดชะงัก
ตอนนี้ เราจะดูสองเครื่องมือประมวลผลข้อมูลที่รู้จักกันดีที่สุดและเปรียบเทียบ:
Apache Kafka
Apache Kafka เป็นระบบส่งข้อความที่สร้างแอปพลิเคชันการสตรีมด้วยกระแสข้อมูลอย่างต่อเนื่อง สร้างขึ้นโดย LinkedIn Kafka เป็นแบบบันทึก บันทึกเป็นรูปแบบพื้นฐานของการจัดเก็บเนื่องจากข้อมูลใหม่แต่ละรายการจะถูกเพิ่มที่ส่วนท้ายของไฟล์

Kafka เป็นหนึ่งในโซลูชันที่ดีที่สุดสำหรับข้อมูลขนาดใหญ่ เนื่องจากคุณลักษณะหลักคือปริมาณงานสูง ด้วย Apache Kafka ยังสามารถแปลงการประมวลผลแบบแบตช์ในแบบเรียลไทม์
Apache Kafka เป็นระบบส่งข้อความสมัครรับข่าวสารซึ่งแอปพลิเคชันเผยแพร่และแอปพลิเคชันที่สมัครรับข้อความ เวลาระหว่างการเผยแพร่และรับข้อความอาจเป็นมิลลิวินาที ดังนั้นโซลูชัน Kafka จึงมีเวลาแฝงต่ำ
การทำงานของคาฟคา
สถาปัตยกรรมของ Apache Kafka ประกอบด้วยผู้ผลิต ผู้บริโภค และคลัสเตอร์เอง ผู้ผลิตคือแอปพลิเคชันใดๆ ที่เผยแพร่ข้อความไปยังคลัสเตอร์ ผู้บริโภคคือแอปพลิเคชันใด ๆ ที่ได้รับข้อความจาก Kafka คลัสเตอร์ Kafka คือชุดของโหนดที่ทำหน้าที่เป็นอินสแตนซ์เดียวของบริการส่งข้อความ
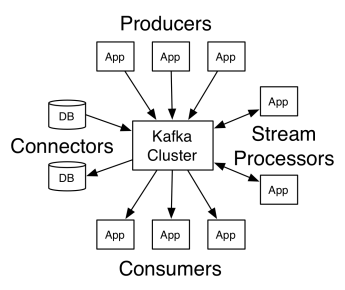
คลัสเตอร์ Kafka ประกอบด้วยโบรกเกอร์หลายราย นายหน้าคือเซิร์ฟเวอร์ Kafka ที่รับข้อความจากผู้ผลิตและเขียนลงในดิสก์ โบรกเกอร์แต่ละรายจัดการรายการหัวข้อ และแต่ละหัวข้อจะถูกแบ่งออกเป็นหลายพาร์ติชั่น
หลังจากได้รับข้อความ นายหน้าจะส่งไปยังผู้บริโภคที่ลงทะเบียนสำหรับแต่ละหัวข้อ
การตั้งค่า Apache Kafka ได้รับการจัดการโดย Apache Zookeeper ซึ่งจัดเก็บข้อมูลเมตาของคลัสเตอร์ เช่น ตำแหน่งพาร์ติชัน รายชื่อ รายชื่อหัวข้อ และโหนดที่พร้อมใช้งาน ดังนั้น Zookeeper จึงรักษาการซิงโครไนซ์ระหว่างองค์ประกอบต่างๆ ของคลัสเตอร์
ผู้ดูแลสัตว์มีความสำคัญเนื่องจาก Kafka เป็นระบบแบบกระจาย นั่นคือการเขียนและการอ่านทำโดยลูกค้าหลายรายพร้อมกัน เมื่อมีความล้มเหลว Zookeeper จะเลือกคนมาแทนที่และกู้คืนการดำเนินการ
ใช้กรณี
Kafka กลายเป็นที่นิยมโดยเฉพาะอย่างยิ่งสำหรับการใช้เป็นเครื่องมือในการส่งข้อความ แต่ความเก่งกาจของ Kafka นั้นมีมากกว่านั้น และสามารถใช้ได้ในสถานการณ์ต่างๆ ดังตัวอย่างด้านล่าง
ข้อความ
รูปแบบการสื่อสารแบบอะซิงโครนัสที่แยกฝ่ายที่สื่อสารออก ในแบบจำลองนี้ ฝ่ายหนึ่งส่งข้อมูลเป็นข้อความไปยัง Kafka ดังนั้นแอปพลิเคชันอื่นจึงใช้ข้อมูลดังกล่าวในภายหลัง
ติดตามกิจกรรม
ช่วยให้คุณสามารถจัดเก็บและประมวลผลข้อมูลที่ติดตามการโต้ตอบของผู้ใช้กับเว็บไซต์ เช่น การดูหน้าเว็บ การคลิก การป้อนข้อมูล ฯลฯ กิจกรรมประเภทนี้มักจะสร้างข้อมูลจำนวนมาก
ตัวชี้วัด
เกี่ยวข้องกับการรวมข้อมูลและสถิติจากหลายแหล่งเพื่อสร้างรายงานแบบรวมศูนย์
การรวมบันทึก
รวมและจัดเก็บไฟล์บันทึกจากระบบอื่นจากส่วนกลาง
การประมวลผลสตรีม
การประมวลผลไปป์ไลน์ข้อมูลประกอบด้วยหลายขั้นตอน ซึ่งข้อมูลดิบถูกใช้จากหัวข้อและรวม เสริม หรือแปลงเป็นหัวข้ออื่น
เพื่อรองรับคุณสมบัติเหล่านี้ แพลตฟอร์มดังกล่าวมี API สามตัว:
- Streams API: ทำหน้าที่เป็นตัวประมวลผลสตรีมที่ใช้ข้อมูลจากหัวข้อหนึ่ง แปลง และเขียนไปยังอีกหัวข้อหนึ่ง
- Connectors API: อนุญาตให้เชื่อมต่อหัวข้อกับระบบที่มีอยู่ เช่น ฐานข้อมูลเชิงสัมพันธ์
- ผู้ผลิตและผู้บริโภค APIs: อนุญาตให้แอปพลิเคชันเผยแพร่และใช้ข้อมูล Kafka
ข้อดี
ทำซ้ำ แบ่งพาร์ติชัน และสั่งซื้อ
ข้อความใน Kafka จะถูกจำลองแบบข้ามพาร์ติชั่นข้ามโหนดคลัสเตอร์ตามลำดับที่มาถึง เพื่อความปลอดภัยและความเร็วในการจัดส่ง
การแปลงข้อมูล
ด้วย Apache Kafka ยังสามารถแปลงการประมวลผลแบบแบตช์ในแบบเรียลไทม์โดยใช้ API สตรีม ETL แบบแบตช์
การเข้าถึงดิสก์ตามลำดับ
Apache Kafka ยังคงข้อความบนดิสก์และไม่ได้อยู่ในหน่วยความจำ เนื่องจากควรจะเร็วกว่า ในความเป็นจริง การเข้าถึงหน่วยความจำทำได้เร็วกว่าในสถานการณ์ส่วนใหญ่ โดยเฉพาะอย่างยิ่งเมื่อพิจารณาถึงการเข้าถึงข้อมูลที่อยู่ในตำแหน่งสุ่มในหน่วยความจำ อย่างไรก็ตาม Kafka เข้าถึงได้ตามลำดับ และในกรณีนี้ ดิสก์จะมีประสิทธิภาพมากกว่า
Apache Spark
Apache Spark เป็นเอ็นจิ้นการประมวลผลข้อมูลขนาดใหญ่และชุดของไลบรารีสำหรับประมวลผลข้อมูลแบบขนานข้ามคลัสเตอร์ Spark เป็นวิวัฒนาการของ Hadoop และกระบวนทัศน์การเขียนโปรแกรม Map-Reduce อาจเร็วขึ้น 100 เท่า ด้วยการใช้หน่วยความจำอย่างมีประสิทธิภาพซึ่งไม่เก็บข้อมูลบนดิสก์ขณะประมวลผล

Spark จัดเป็นสามระดับ:
- API ระดับต่ำ: ระดับนี้มีฟังก์ชันพื้นฐานเพื่อเรียกใช้งานและฟังก์ชันอื่นๆ ที่จำเป็นสำหรับส่วนประกอบอื่นๆ ฟังก์ชันที่สำคัญอื่นๆ ของเลเยอร์นี้คือการจัดการความปลอดภัย เครือข่าย การตั้งเวลา และการเข้าถึงระบบไฟล์ HDFS, GlusterFS, Amazon S3 และอื่นๆ
- API ที่มี โครงสร้าง: ระดับ API ที่มีโครงสร้างเกี่ยวข้องกับการจัดการข้อมูลผ่านชุดข้อมูลหรือกรอบข้อมูล ซึ่งสามารถอ่านได้ในรูปแบบต่างๆ เช่น Hive, Parquet, JSON และอื่นๆ การใช้ SparkSQL (API ที่ช่วยให้เราสามารถเขียนแบบสอบถามใน SQL) เราสามารถจัดการข้อมูลตามที่เราต้องการได้
- ระดับสูง: ที่ระดับสูงสุด เรามีระบบนิเวศ Spark ที่มีไลบรารีต่างๆ รวมถึง Spark Streaming, Spark MLlib และ Spark GraphX พวกเขามีหน้าที่ดูแลการนำเข้าสตรีมมิงและกระบวนการโดยรอบ เช่น การกู้คืนข้อขัดข้อง การสร้างและการตรวจสอบโมเดลการเรียนรู้ของเครื่องแบบคลาสสิก และการจัดการกับกราฟและอัลกอริธึม
การทำงานของ Spark
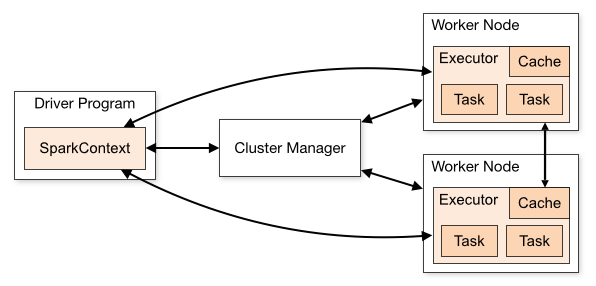
สถาปัตยกรรมของแอปพลิเคชัน Spark ประกอบด้วยสามส่วนหลัก:

โปรแกรมไดรเวอร์ : รับผิดชอบในการเตรียมการประมวลผลข้อมูล
Cluster Manager : เป็นส่วนประกอบที่รับผิดชอบในการจัดการเครื่องต่างๆ ในคลัสเตอร์ จำเป็นเฉพาะในกรณีที่ Spark ทำงานแบบกระจาย
โหนดคนงาน : เหล่านี้เป็นเครื่องที่ทำงานของโปรแกรม หาก Spark ทำงานบนเครื่องของคุณ มันจะมีบทบาทโปรแกรมไดรเวอร์และงาน วิธีการเรียกใช้ Spark นี้เรียกว่าแบบสแตนด์อโลน
Spark code สามารถเขียนได้หลายภาษา คอนโซล Spark ที่เรียกว่า Spark Shell เป็นแบบโต้ตอบสำหรับการเรียนรู้และสำรวจข้อมูล
แอปพลิเคชัน Spark ที่เรียกว่าประกอบด้วยงานตั้งแต่หนึ่งงานขึ้นไป ซึ่งช่วยให้รองรับการประมวลผลข้อมูลขนาดใหญ่
เมื่อเราพูดถึงการดำเนินการ Spark มีสองโหมด:
- ไคลเอนต์: โปรแกรมควบคุมทำงานบนไคลเอนต์โดยตรง ซึ่งไม่ผ่านตัวจัดการทรัพยากร
- คลัสเตอร์: ไดรเวอร์ที่ทำงานบน Application Master ผ่าน Resource Manager (ในโหมดคลัสเตอร์ หากไคลเอ็นต์ยกเลิกการเชื่อมต่อ แอปพลิเคชันจะทำงานต่อไป)
จำเป็นต้องใช้ Spark อย่างถูกต้อง เพื่อให้บริการที่เชื่อมโยง เช่น Resource Manager สามารถระบุความจำเป็นในการดำเนินการแต่ละครั้ง โดยให้ประสิทธิภาพที่ดีที่สุด ดังนั้นจึงขึ้นอยู่กับนักพัฒนาที่จะทราบวิธีที่ดีที่สุดในการรันงาน Spark จัดโครงสร้างการโทร และด้วยเหตุนี้ คุณสามารถจัดโครงสร้างและกำหนดค่าตัวดำเนินการ Spark ตามที่คุณต้องการ
งาน Spark ใช้หน่วยความจำเป็นหลัก ดังนั้นจึงเป็นเรื่องปกติที่จะปรับค่าการกำหนดค่า Spark สำหรับตัวดำเนินการโหนดงาน ขึ้นอยู่กับปริมาณงาน Spark เป็นไปได้ที่จะพิจารณาว่าการกำหนดค่า Spark ที่ไม่ได้มาตรฐานบางอย่างให้การดำเนินการที่เหมาะสมที่สุด ด้วยเหตุนี้ การทดสอบเปรียบเทียบระหว่างตัวเลือกการกำหนดค่าต่างๆ ที่มีและการกำหนดค่า Spark เริ่มต้นนั้นสามารถทำได้
ใช้กรณี
Apache Spark ช่วยในการประมวลผลข้อมูลจำนวนมหาศาล ไม่ว่าจะเป็นแบบเรียลไทม์หรือเก็บถาวร มีโครงสร้างหรือไม่มีโครงสร้าง ต่อไปนี้เป็นกรณีการใช้งานยอดนิยมบางส่วน
การเพิ่มประสิทธิภาพของข้อมูล
บ่อยครั้งที่บริษัทต่างๆ ใช้ข้อมูลลูกค้าในอดีตร่วมกับข้อมูลพฤติกรรมแบบเรียลไทม์ Spark ช่วยสร้างไปป์ไลน์ ETL แบบต่อเนื่องเพื่อแปลงข้อมูลเหตุการณ์ที่ไม่มีโครงสร้างเป็นข้อมูลที่มีโครงสร้าง
ทริกเกอร์การตรวจจับเหตุการณ์
Spark Streaming ช่วยให้ตรวจจับและตอบสนองต่อพฤติกรรมที่หายากหรือน่าสงสัยบางอย่างที่อาจบ่งบอกถึงปัญหาที่อาจเกิดขึ้นหรือการฉ้อโกงได้อย่างรวดเร็ว
การวิเคราะห์ข้อมูลเซสชันที่ซับซ้อน
การใช้ Spark Streaming ทำให้สามารถจัดกลุ่มและวิเคราะห์กิจกรรมที่เกี่ยวข้องกับเซสชันของผู้ใช้ได้ เช่น กิจกรรมหลังจากลงชื่อเข้าใช้แอปพลิเคชัน ข้อมูลนี้สามารถใช้อย่างต่อเนื่องเพื่ออัปเดตโมเดลการเรียนรู้ของเครื่อง
ข้อดี
การประมวลผลแบบวนซ้ำ
หากงานคือการประมวลผลข้อมูลซ้ำๆ ชุดข้อมูล Distributed Datasets (RDD) ที่ยืดหยุ่นของ Spark จะอนุญาตการดำเนินการแมปในหน่วยความจำหลายรายการโดยไม่ต้องเขียนผลลัพธ์ชั่วคราวไปยังดิสก์
การประมวลผลกราฟิก
โมเดลการคำนวณของ Spark พร้อม GraphX API นั้นยอดเยี่ยมสำหรับการคำนวณซ้ำตามแบบฉบับของการประมวลผลกราฟิก
การเรียนรู้ของเครื่อง
Spark มี MLlib — ไลบรารีแมชชีนเลิร์นนิงในตัวที่มีอัลกอริธึมสำเร็จรูปที่ทำงานในหน่วยความจำด้วย
Kafka vs. Spark
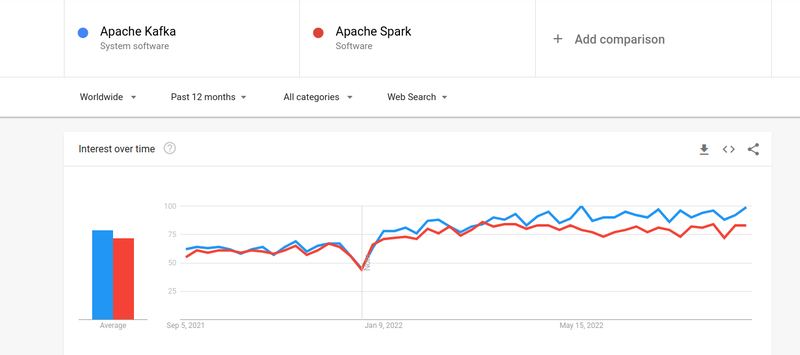
แม้ว่าความสนใจของผู้คนใน Kafka และ Spark จะใกล้เคียงกัน แต่ก็มีความแตกต่างที่สำคัญระหว่างคนทั้งสอง มาดูกัน
#1. การประมวลผลข้อมูล
Kafka เป็นเครื่องมือสตรีมมิ่งและจัดเก็บข้อมูลแบบเรียลไทม์ที่รับผิดชอบในการถ่ายโอนข้อมูลระหว่างแอปพลิเคชัน แต่ยังไม่เพียงพอที่จะสร้างโซลูชันที่สมบูรณ์ ดังนั้น จึงจำเป็นต้องใช้เครื่องมืออื่นๆ สำหรับงานที่ Kafka ไม่มี เช่น Spark ในทางกลับกัน Spark เป็นแพลตฟอร์มการประมวลผลข้อมูลแบบกลุ่มแรกที่ดึงข้อมูลจากหัวข้อ Kafka และแปลงเป็นสคีมาแบบรวม
#2. การจัดการหน่วยความจำ
Spark ใช้ Robust Distributed Datasets (RDD) สำหรับการจัดการหน่วยความจำ แทนที่จะพยายามประมวลผลชุดข้อมูลขนาดใหญ่ มันจะกระจายไปยังหลาย ๆ โหนดในคลัสเตอร์ ในทางตรงกันข้าม Kafka ใช้การเข้าถึงตามลำดับคล้ายกับ HDFS และจัดเก็บข้อมูลในหน่วยความจำบัฟเฟอร์
#3. การแปลง ETL
ทั้ง Spark และ Kafka รองรับกระบวนการแปลง ETL ซึ่งคัดลอกบันทึกจากฐานข้อมูลหนึ่งไปยังอีกฐานข้อมูลหนึ่ง โดยปกติแล้วจะมาจากพื้นฐานธุรกรรม (OLTP) ไปยังพื้นฐานการวิเคราะห์ (OLAP) อย่างไรก็ตาม ไม่เหมือน Spark ซึ่งมาพร้อมกับความสามารถในตัวสำหรับกระบวนการ ETL Kafka อาศัย Streams API เพื่อรองรับ
#4. ความคงอยู่ของข้อมูล

การใช้ RRD ของ Spark ทำให้คุณสามารถจัดเก็บข้อมูลในหลายตำแหน่งเพื่อใช้ในภายหลัง ในขณะที่ใน Kafka คุณต้องกำหนดออบเจ็กต์ชุดข้อมูลในการกำหนดค่าเพื่อคงข้อมูลไว้
#5. ความยาก
Spark เป็นโซลูชันที่สมบูรณ์และเรียนรู้ได้ง่ายขึ้นเนื่องจากรองรับภาษาการเขียนโปรแกรมระดับสูงต่างๆ Kafka ขึ้นอยู่กับ API และโมดูลของบริษัทอื่นจำนวนหนึ่ง ซึ่งทำให้การทำงานด้วยยากขึ้น
#6. การกู้คืน
ทั้ง Spark และ Kafka มีตัวเลือกการกู้คืน Spark ใช้ RRD ซึ่งช่วยให้สามารถบันทึกข้อมูลได้อย่างต่อเนื่อง และหากมีความล้มเหลวของคลัสเตอร์ ก็สามารถกู้คืนได้

Kafka ทำซ้ำข้อมูลภายในคลัสเตอร์อย่างต่อเนื่องและทำซ้ำข้ามโบรกเกอร์ ซึ่งช่วยให้คุณย้ายไปยังโบรกเกอร์ต่างๆ ได้หากมีความล้มเหลว
ความคล้ายคลึงกันระหว่าง Spark และ Kafka
| Apache Spark | Apache Kafka |
| โอเพ่นซอร์ส | โอเพ่นซอร์ส |
| สร้างแอปพลิเคชันการสตรีมข้อมูล | สร้างแอปพลิเคชันการสตรีมข้อมูล |
| รองรับ Stateful Processing | รองรับ Stateful Processing |
| รองรับSQL | รองรับSQL |
คำพูดสุดท้าย
Kafka และ Spark เป็นทั้งเครื่องมือโอเพนซอร์ซที่เขียนใน Scala และ Java ซึ่งช่วยให้คุณสามารถสร้างแอปพลิเคชันการสตรีมข้อมูลแบบเรียลไทม์ มีหลายสิ่งที่เหมือนกัน รวมถึงการประมวลผลแบบเก็บสถานะ การสนับสนุน SQL และ ETL นอกจากนี้ยังสามารถใช้ Kafka และ Spark เป็นเครื่องมือเสริมเพื่อช่วยแก้ปัญหาความซับซ้อนของการถ่ายโอนข้อมูลระหว่างแอปพลิเคชัน