
ابدأ معالجة البيانات مع كافكا وسبارك
نشرت: 2022-09-09تعد معالجة البيانات الضخمة من أكثر الإجراءات التي تواجهها المؤسسات تعقيدًا. تصبح العملية أكثر تعقيدًا عندما يكون لديك حجم كبير من البيانات في الوقت الفعلي.
في هذا المنشور ، سوف نكتشف ماهية معالجة البيانات الضخمة ، وكيف تتم ، واستكشاف Apache Kafka و Spark - وهما من أشهر أدوات معالجة البيانات!
ما هي معالجة البيانات؟ كيف يتم ذلك؟
يتم تعريف معالجة البيانات على أنها أي عملية أو مجموعة من العمليات ، سواء تم تنفيذها باستخدام عملية آلية أم لا. يمكن اعتباره جمع المعلومات وترتيبها وتنظيمها وفقًا لترتيب منطقي ومناسب للتفسير.

عندما يصل المستخدم إلى قاعدة بيانات ويحصل على نتائج لبحثه ، فإن معالجة البيانات هي التي تحصل على النتائج التي يحتاجونها. المعلومات المستخرجة كنتيجة بحث هي نتيجة معالجة البيانات. هذا هو السبب في أن تكنولوجيا المعلومات تركز في وجودها على معالجة البيانات.
تم تنفيذ معالجة البيانات التقليدية باستخدام برنامج بسيط. ومع ذلك ، مع ظهور البيانات الضخمة ، تغيرت الأمور. تشير البيانات الضخمة إلى المعلومات التي يمكن أن يزيد حجمها عن مائة تيرابايت وبيتابايت.
علاوة على ذلك ، يتم تحديث هذه المعلومات بانتظام. تشمل الأمثلة البيانات الواردة من مراكز الاتصال ، ووسائل التواصل الاجتماعي ، وبيانات تداول البورصة ، وما إلى ذلك. وتسمى هذه البيانات أحيانًا أيضًا دفق البيانات - دفق بيانات ثابت وغير متحكم فيه. السمة الرئيسية لها هي أن البيانات ليس لها حدود محددة ، لذلك من المستحيل تحديد متى يبدأ الدفق أو ينتهي.
تتم معالجة البيانات عند وصولها إلى الوجهة. يسميها بعض المؤلفين المعالجة في الوقت الفعلي أو عبر الإنترنت. هناك طريقة مختلفة تتمثل في الحظر أو الدُفعة أو المعالجة دون اتصال بالإنترنت ، حيث تتم معالجة كتل البيانات في نوافذ زمنية مدتها ساعات أو أيام. غالبًا ما تكون الدُفعة عبارة عن عملية يتم إجراؤها ليلاً ، وتدمج بيانات ذلك اليوم. هناك حالات من النوافذ الزمنية لمدة أسبوع أو حتى شهر لإنشاء تقارير قديمة.
نظرًا لأن أفضل منصات معالجة البيانات الضخمة عبر البث هي مصادر مفتوحة مثل كافكا وسبارك ، فإن هذه المنصات تسمح باستخدام منصات أخرى مختلفة ومكملة. هذا يعني أن كونها مفتوحة المصدر ، فإنها تتطور بشكل أسرع وتستخدم المزيد من الأدوات. بهذه الطريقة ، يتم تلقي تدفقات البيانات من أماكن أخرى بمعدل متغير ودون أي انقطاع.
الآن ، سنلقي نظرة على اثنتين من أكثر أدوات معالجة البيانات شهرة ونقارنهما:
أباتشي كافكا
Apache Kafka هو نظام مراسلة يقوم بإنشاء تطبيقات متدفقة بتدفق مستمر للبيانات. تم إنشاء كافكا في الأصل بواسطة LinkedIn ، وهو مستند إلى السجل ؛ السجل هو شكل أساسي من أشكال التخزين لأنه يتم إضافة كل معلومات جديدة إلى نهاية الملف.

يعد كافكا أحد أفضل الحلول للبيانات الضخمة لأن السمة الرئيسية لها هي الإنتاجية العالية. مع Apache Kafka ، من الممكن تحويل معالجة الدُفعات في الوقت الفعلي ،
Apache Kafka هو نظام مراسلة للنشر والاشتراك حيث ينشر التطبيق ويستقبل التطبيق الذي يشترك الرسائل. يمكن أن يكون الوقت بين نشر الرسالة واستلامها مللي ثانية ، لذا فإن حل كافكا له زمن انتقال منخفض.
عمل كافكا
تضم بنية أباتشي كافكا المنتجين والمستهلكين والمجموعة نفسها. المنتج هو أي تطبيق ينشر الرسائل إلى الكتلة. المستهلك هو أي تطبيق يستقبل رسائل من كافكا. كتلة كافكا عبارة عن مجموعة من العقد التي تعمل كمثيل واحد لخدمة المراسلة.
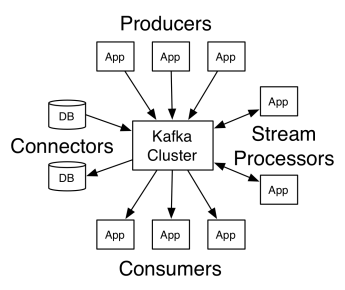
تتكون كتلة كافكا من عدة وسطاء. الوسيط هو خادم كافكا يتلقى الرسائل من المنتجين ويكتبها على القرص. يدير كل وسيط قائمة بالموضوعات ، وينقسم كل موضوع إلى عدة أقسام.
بعد استلام الرسائل ، يرسلها الوسيط إلى المستهلكين المسجلين لكل موضوع.
تتم إدارة إعدادات Apache Kafka بواسطة Apache Zookeeper ، والذي يقوم بتخزين البيانات الوصفية للمجموعة مثل موقع القسم وقائمة الأسماء وقائمة الموضوعات والعقد المتاحة. وبالتالي ، يحافظ Zookeeper على التزامن بين العناصر المختلفة للكتلة.
Zookeeper مهم لأن كافكا نظام موزع ؛ أي أن الكتابة والقراءة تتم من قبل العديد من العملاء في وقت واحد. عندما يكون هناك فشل ، يختار Zookeeper بديلاً ويستعيد العملية.
استخدم حالات
أصبح كافكا رائجًا ، خاصة لاستخدامه كأداة مراسلة ، لكن تعدد استخداماته يتجاوز ذلك ، ويمكن استخدامه في مجموعة متنوعة من السيناريوهات ، كما في الأمثلة أدناه.
المراسلة
شكل غير متزامن من الاتصال يفصل بين الأطراف التي تتواصل. في هذا النموذج ، يرسل أحد الأطراف البيانات كرسالة إلى كافكا ، لذلك يستهلكها تطبيق آخر لاحقًا.
تتبع النشاط
يمكّنك من تخزين ومعالجة بيانات تتبع تفاعل المستخدم مع موقع الويب ، مثل مشاهدات الصفحة والنقرات وإدخال البيانات وما إلى ذلك ؛ عادة ما ينتج عن هذا النوع من النشاط حجم كبير من البيانات.
المقاييس
يتضمن تجميع البيانات والإحصائيات من مصادر متعددة لإنشاء تقرير مركزي.
تجميع السجل
لتجميع وتخزين ملفات السجل التي تنشأ من أنظمة أخرى بشكل مركزي.
تيار المعالجة
تتكون معالجة خطوط أنابيب البيانات من مراحل متعددة ، حيث يتم استهلاك البيانات الأولية من الموضوعات وتجميعها أو إثرائها أو تحويلها إلى مواضيع أخرى.
لدعم هذه الميزات ، يوفر النظام الأساسي بشكل أساسي ثلاث واجهات برمجة تطبيقات:
- واجهة برمجة تطبيقات Streams: تعمل كمعالج دفق يستهلك البيانات من موضوع واحد ويحولها ويكتبها إلى موضوع آخر.
- Connectors API: يسمح بربط الموضوعات بالأنظمة الحالية ، مثل قواعد البيانات العلائقية.
- واجهات برمجة تطبيقات المنتج والمستهلك: تسمح للتطبيقات بنشر واستهلاك بيانات كافكا.
الايجابيات
منسوخة ومقسمة ومرتبة
يتم نسخ الرسائل في كافكا عبر الأقسام عبر العقد العنقودية بالترتيب الذي تصل إليه لضمان الأمن وسرعة التسليم.
تحويل البيانات
باستخدام Apache Kafka ، من الممكن تحويل معالجة الدُفعات في الوقت الفعلي باستخدام واجهة برمجة تطبيقات دفق ETL الدفعية.
الوصول المتسلسل للقرص
أباتشي كافكا يستمر في إرسال الرسالة على القرص وليس في الذاكرة ، لأنه من المفترض أن يكون أسرع. في الواقع ، يكون الوصول إلى الذاكرة أسرع في معظم المواقف ، خاصةً عند التفكير في الوصول إلى البيانات الموجودة في مواقع عشوائية في الذاكرة. ومع ذلك ، فإن كافكا يقوم بوصول تسلسلي ، وفي هذه الحالة يكون القرص أكثر كفاءة.
اباتشي سبارك
يعد Apache Spark محركًا لحوسبة البيانات الضخمة ومجموعة من المكتبات لمعالجة البيانات المتوازية عبر المجموعات. Spark هو تطور Hadoop ونموذج برمجة Map-Reduce. يمكن أن يكون أسرع 100 مرة بفضل استخدامه الفعال للذاكرة التي لا تحافظ على البيانات الموجودة على الأقراص أثناء المعالجة.

يتم تنظيم Spark على ثلاثة مستويات:
- واجهات برمجة التطبيقات ذات المستوى المنخفض: يحتوي هذا المستوى على الوظائف الأساسية لتشغيل الوظائف والوظائف الأخرى التي تتطلبها المكونات الأخرى. الوظائف المهمة الأخرى لهذه الطبقة هي إدارة الأمان والشبكة والجدولة والوصول المنطقي لأنظمة الملفات HDFS و GlusterFS و Amazon S3 وغيرها.
- واجهات برمجة التطبيقات الهيكلية: يتعامل مستوى واجهة برمجة التطبيقات الهيكلية مع معالجة البيانات من خلال مجموعات البيانات أو إطارات البيانات ، والتي يمكن قراءتها بتنسيقات مثل Hive و Parquet و JSON وغيرها. باستخدام SparkSQL (API الذي يسمح لنا بكتابة استعلامات في SQL) ، يمكننا معالجة البيانات بالطريقة التي نريدها.
- مستوى عالٍ: على أعلى مستوى ، لدينا نظام Spark البيئي مع مكتبات مختلفة ، بما في ذلك Spark Streaming و Spark MLlib و Spark GraphX. فهم مسؤولون عن رعاية البث المتدفق والعمليات المحيطة ، مثل استعادة الأعطال وإنشاء نماذج التعلم الآلي الكلاسيكية والتحقق من صحتها والتعامل مع الرسوم البيانية والخوارزميات.
عمل سبارك
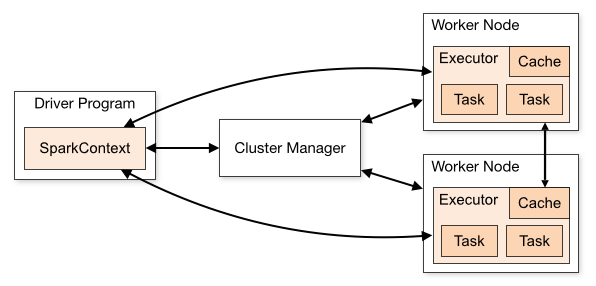
تتكون بنية تطبيق Spark من ثلاثة أجزاء رئيسية:

برنامج السائق : وهو مسؤول عن تنظيم تنفيذ معالجة البيانات.
مدير الكتلة : هو المكون المسؤول عن إدارة الأجهزة المختلفة في الكتلة. مطلوب فقط إذا تم توزيع Spark.
عقد العمال : هي الآلات التي تؤدي مهام البرنامج. إذا تم تشغيل Spark محليًا على جهازك ، فسيؤدي دور برنامج التشغيل ودور العمل. هذه الطريقة في تشغيل Spark تسمى Standalone.
يمكن كتابة كود Spark بعدد من اللغات المختلفة. وحدة Spark ، المسماة Spark Shell ، تفاعلية للتعلم واستكشاف البيانات.
يتكون تطبيق Spark المزعوم من وظيفة واحدة أو أكثر ، مما يتيح دعم معالجة البيانات على نطاق واسع.
عندما نتحدث عن التنفيذ ، فإن Spark لها وضعان:
- العميل: يتم تشغيل برنامج التشغيل مباشرة على العميل ، والذي لا يمر عبر إدارة الموارد.
- الكتلة: برنامج التشغيل الذي يتم تشغيله على التطبيق الرئيسي من خلال إدارة الموارد (في وضع الكتلة ، إذا انقطع اتصال العميل ، فسيستمر التطبيق في العمل).
من الضروري استخدام Spark بشكل صحيح حتى تتمكن الخدمات المرتبطة ، مثل Resource Manager ، من تحديد الحاجة لكل تنفيذ ، مما يوفر أفضل أداء. لذا فإن الأمر متروك للمطور لمعرفة أفضل طريقة لتشغيل وظائف Spark الخاصة به ، وتنظيم المكالمة التي تم إجراؤها ، ولهذا ، يمكنك هيكلة وتهيئة المنفذين Spark بالطريقة التي تريدها.
تستخدم وظائف Spark الذاكرة بشكل أساسي ، لذلك من الشائع ضبط قيم تكوين Spark لمنفذي عقد العمل. اعتمادًا على عبء عمل Spark ، من الممكن تحديد أن تكوين Spark غير قياسي يوفر عمليات تنفيذ أكثر مثالية. تحقيقا لهذه الغاية ، يمكن إجراء اختبارات المقارنة بين خيارات التكوين المختلفة المتاحة وتكوين Spark الافتراضي نفسه.
يستخدم الحالات
يساعد Apache Spark في معالجة كميات هائلة من البيانات ، سواء كانت في الوقت الفعلي أو مؤرشفة أو منظمة أو غير منظمة. فيما يلي بعض حالات الاستخدام الشائعة.
إثراء البيانات
غالبًا ما تستخدم الشركات مجموعة من بيانات العملاء التاريخية مع البيانات السلوكية في الوقت الفعلي. يمكن أن يساعد Spark في بناء خط أنابيب ETL مستمر لتحويل بيانات الأحداث غير المنظمة إلى بيانات منظمة.
كشف حدث الزناد
يسمح Spark Streaming بالكشف والاستجابة بسرعة لبعض السلوكيات النادرة أو المشبوهة التي قد تشير إلى مشكلة محتملة أو احتيال.
تحليل بيانات الجلسة المعقدة
باستخدام Spark Streaming ، يمكن تجميع الأحداث المتعلقة بجلسة المستخدم ، مثل أنشطتهم بعد تسجيل الدخول إلى التطبيق ، وتحليلها. يمكن أيضًا استخدام هذه المعلومات بشكل مستمر لتحديث نماذج التعلم الآلي.
الايجابيات
المعالجة المتكررة
إذا كانت المهمة هي معالجة البيانات بشكل متكرر ، فإن مجموعات البيانات الموزعة المرنة (RDD) الخاصة بشركة Spark تسمح بعمليات تعيين متعددة في الذاكرة دون الحاجة إلى كتابة نتائج مؤقتة على القرص.
معالجة الجرافيك
يعد نموذج Spark الحسابي مع GraphX API ممتازًا للحسابات التكرارية النموذجية لمعالجة الرسومات.
التعلم الالي
يحتوي Spark على MLlib - مكتبة تعلم آلي مدمجة بها خوارزميات جاهزة تعمل أيضًا في الذاكرة.
كافكا مقابل سبارك
على الرغم من أن اهتمام الناس في كل من كافكا وسبارك كان متشابهًا تقريبًا ، إلا أنه توجد بعض الاختلافات الرئيسية بين الاثنين ؛ لنلقي نظرة.
# 1. معالجة البيانات
كافكا هي أداة تخزين وتدفق البيانات في الوقت الفعلي مسؤولة عن نقل البيانات بين التطبيقات ، لكنها لا تكفي لبناء حل كامل. لذلك ، هناك حاجة لأدوات أخرى للمهام التي لا يفعلها كافكا ، مثل سبارك. من ناحية أخرى ، فإن Spark عبارة عن نظام أساسي لمعالجة البيانات على أساس الدُفعة الأولى يستمد البيانات من موضوعات كافكا ويحولها إلى مخططات مجمعة.
# 2. إدارة الذاكرة
يستخدم Spark مجموعات البيانات الموزعة القوية (RDD) لإدارة الذاكرة. بدلاً من محاولة معالجة مجموعات البيانات الضخمة ، تقوم بتوزيعها على عقد متعددة في مجموعة. في المقابل ، يستخدم كافكا وصولاً تسلسليًا مشابهًا لـ HDFS ويخزن البيانات في ذاكرة عازلة.
# 3. تحويل ETL
يدعم كل من Spark و Kafka عملية تحويل ETL ، التي تنسخ السجلات من قاعدة بيانات إلى أخرى ، عادةً من أساس المعاملات (OLTP) إلى أساس تحليلي (OLAP). ومع ذلك ، على عكس Spark ، التي تأتي مع قدرة مضمنة لعملية ETL ، يعتمد كافكا على Streams API لدعمها.
# 4. ثبات البيانات

يسمح لك استخدام Spark لـ RRD بتخزين البيانات في مواقع متعددة لاستخدامها لاحقًا ، بينما في كافكا ، عليك تحديد كائنات مجموعة البيانات في التكوين لاستمرار البيانات.
# 5. صعوبة
يعد Spark حلاً كاملاً وأسهل في التعلم نظرًا لدعمه لمختلف لغات البرمجة عالية المستوى. يعتمد كافكا على عدد من واجهات برمجة التطبيقات المختلفة ووحدات الطرف الثالث ، مما يجعل من الصعب العمل معها.
# 6. استعادة
يوفر كل من Spark و Kafka خيارات الاسترداد. يستخدم Spark RRD ، والذي يسمح له بحفظ البيانات بشكل مستمر ، وإذا كان هناك فشل في الكتلة ، فيمكن استعادته.

يكرر كافكا البيانات باستمرار داخل الكتلة وتكرارها عبر الوسطاء ، مما يسمح لك بالانتقال إلى الوسطاء المختلفين إذا كان هناك فشل.
أوجه التشابه بين سبارك وكافكا
| اباتشي سبارك | أباتشي كافكا |
| مفتوح المصدر | مفتوح المصدر |
| بناء تطبيق دفق البيانات | بناء تطبيق دفق البيانات |
| يدعم المعالجة ذات الحالة | يدعم المعالجة ذات الحالة |
| يدعم SQL | يدعم SQL |
الكلمات الأخيرة
يعد كل من Kafka و Spark أدوات مفتوحة المصدر مكتوبة بلغة Scala و Java ، والتي تتيح لك إنشاء تطبيقات دفق البيانات في الوقت الفعلي. لديهم العديد من الأشياء المشتركة ، بما في ذلك المعالجة ذات الحالة ، ودعم SQL و ETL. يمكن أيضًا استخدام كافكا وسبارك كأدوات تكميلية للمساعدة في حل مشكلة تعقيد نقل البيانات بين التطبيقات.