
Запустите обработку данных с помощью Kafka и Spark
Опубликовано: 2022-09-09Обработка больших данных — одна из самых сложных процедур, с которыми сталкиваются организации. Процесс усложняется, когда у вас есть большой объем данных в реальном времени.
В этом посте мы узнаем, что такое обработка больших данных, как это делается, а также рассмотрим Apache Kafka и Spark — два самых известных инструмента обработки данных!
Что такое обработка данных? Как это делается?
Обработка данных определяется как любая операция или набор операций, независимо от того, выполняются ли они с использованием автоматизированного процесса. Его можно рассматривать как сбор, упорядочение и организацию информации в соответствии с логической и подходящей диспозицией для интерпретации.

Когда пользователь обращается к базе данных и получает результаты своего поиска, именно обработка данных дает ему нужные результаты. Информация, извлеченная в результате поиска, является результатом обработки данных. Вот почему информационная технология сосредоточила свое существование на обработке данных.
Традиционная обработка данных проводилась с помощью простого программного обеспечения. Однако с появлением больших данных все изменилось. Большие данные относятся к информации, объем которой может превышать сто терабайт и петабайт.
Причем эта информация регулярно обновляется. Примеры включают данные, поступающие из контакт-центров, социальных сетей, данные о биржевых торгах и т. д. Такие данные иногда также называют потоком данных — постоянный, неконтролируемый поток данных. Его главная особенность заключается в том, что данные не имеют определенных ограничений, поэтому невозможно сказать, когда поток начинается или заканчивается.
Данные обрабатываются по мере их поступления в пункт назначения. Некоторые авторы называют это обработкой в режиме реального времени или онлайн-обработкой. Другим подходом является блочная, пакетная или автономная обработка, при которой блоки данных обрабатываются во временных окнах часов или дней. Часто пакет — это процесс, который выполняется ночью и объединяет данные за этот день. Бывают случаи, когда временные окна в неделю или даже месяц генерируют устаревшие отчеты.
Учитывая, что лучшими платформами для обработки больших данных с помощью потоковой передачи являются открытые источники, такие как Kafka и Spark, эти платформы позволяют использовать другие разные и дополняющие друг друга. Это означает, что, будучи открытым исходным кодом, они развиваются быстрее и используют больше инструментов. Таким образом, потоки данных принимаются из других мест с переменной скоростью и без каких-либо перерывов.
Теперь мы рассмотрим два наиболее широко известных инструмента обработки данных и сравним их:
Апач Кафка
Apache Kafka — это система обмена сообщениями, которая создает потоковые приложения с непрерывным потоком данных. Первоначально созданный LinkedIn, Kafka основан на журналах; журнал — это основная форма хранения, поскольку каждая новая информация добавляется в конец файла.

Kafka — одно из лучших решений для больших данных, поскольку его главная характеристика — высокая пропускная способность. С Apache Kafka можно даже преобразовать пакетную обработку в режиме реального времени,
Apache Kafka — это система обмена сообщениями с публикацией и подпиской, в которой приложение публикует, а приложение, подписавшееся на получение сообщений. Время между публикацией и получением сообщения может составлять миллисекунды, поэтому решение Kafka имеет низкую задержку.
Работа Кафки
Архитектура Apache Kafka включает производителей, потребителей и сам кластер. Производитель — это любое приложение, которое публикует сообщения в кластере. Потребитель — это любое приложение, которое получает сообщения от Kafka. Кластер Kafka — это набор узлов, которые функционируют как единый экземпляр службы обмена сообщениями.
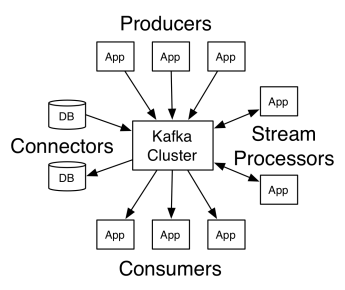
Кластер Kafka состоит из нескольких брокеров. Брокер — это сервер Kafka, который получает сообщения от производителей и записывает их на диск. Каждый брокер управляет списком тем, и каждая тема разделена на несколько разделов.
После получения сообщений брокер отправляет их зарегистрированным потребителям для каждой темы.
Настройки Apache Kafka управляются Apache Zookeeper, в котором хранятся метаданные кластера, такие как расположение разделов, список имен, список тем и доступные узлы. Таким образом, Zookeeper поддерживает синхронизацию между разными элементами кластера.
Zookeeper важен, потому что Kafka — распределенная система; то есть запись и чтение выполняются несколькими клиентами одновременно. В случае сбоя Zookeeper выбирает замену и восстанавливает операцию.
Сценарии использования
Kafka стала популярной, особенно из-за ее использования в качестве инструмента для обмена сообщениями, но ее универсальность выходит за рамки этого, и ее можно использовать в различных сценариях, как в примерах ниже.
Обмен сообщениями
Асинхронная форма общения, которая развязывает взаимодействующие стороны. В этой модели одна сторона отправляет данные в виде сообщения в Kafka, поэтому их позже использует другое приложение.
Отслеживание активности
Позволяет хранить и обрабатывать данные, отслеживающие взаимодействие пользователя с веб-сайтом, такие как просмотры страниц, клики, ввод данных и т. д.; этот вид деятельности обычно генерирует большой объем данных.
Метрики
Включает агрегирование данных и статистики из нескольких источников для создания централизованного отчета.
Агрегация журналов
Централизованно собирает и хранит файлы журналов, происходящие из других систем.
Потоковая обработка
Обработка конвейеров данных состоит из нескольких этапов, на которых необработанные данные потребляются из тем и агрегируются, обогащаются или преобразуются в другие темы.
Для поддержки этих функций платформа по существу предоставляет три API:
- Streams API: он действует как потоковый процессор, который потребляет данные из одной темы, преобразует их и записывает в другую.
- API соединителей: позволяет подключать темы к существующим системам, таким как реляционные базы данных.
- API производителя и потребителя: он позволяет приложениям публиковать и использовать данные Kafka.
Плюсы
Реплицированные, секционированные и упорядоченные
Сообщения в Kafka реплицируются между разделами и узлами кластера в порядке их поступления для обеспечения безопасности и скорости доставки.
Преобразование данных
С помощью Apache Kafka можно даже преобразовать пакетную обработку в режиме реального времени с помощью API пакетных потоков ETL.
Последовательный доступ к диску
Apache Kafka сохраняет сообщение на диске, а не в памяти, так как это должно быть быстрее. На самом деле в большинстве ситуаций доступ к памяти происходит быстрее, особенно при рассмотрении доступа к данным, которые находятся в случайных местах памяти. Однако Kafka осуществляет последовательный доступ, и в этом случае диск более эффективен.
Апач Спарк
Apache Spark — это механизм обработки больших данных и набор библиотек для обработки параллельных данных в кластерах. Spark — это эволюция Hadoop и парадигмы программирования Map-Reduce. Это может быть в 100 раз быстрее благодаря эффективному использованию памяти, которая не сохраняет данные на дисках во время обработки.

Spark организован на трех уровнях:
- Низкоуровневые API: этот уровень содержит базовые функции для запуска заданий и другие функции, необходимые для других компонентов. Другими важными функциями этого уровня являются управление безопасностью, сетью, планированием и логическим доступом к файловым системам HDFS, GlusterFS, Amazon S3 и другим.
- Структурированные API. Уровень структурированного API связан с манипулированием данными с помощью наборов данных или фреймов данных, которые можно читать в таких форматах, как Hive, Parquet, JSON и других. Используя SparkSQL (API, который позволяет нам писать запросы на SQL), мы можем манипулировать данными так, как мы хотим.
- Высокий уровень: на самом высоком уровне у нас есть экосистема Spark с различными библиотеками, включая Spark Streaming, Spark MLlib и Spark GraphX. Они отвечают за прием потоковой передачи и сопутствующие процессы, такие как восстановление после сбоя, создание и проверка классических моделей машинного обучения, а также работу с графиками и алгоритмами.
Работа искры
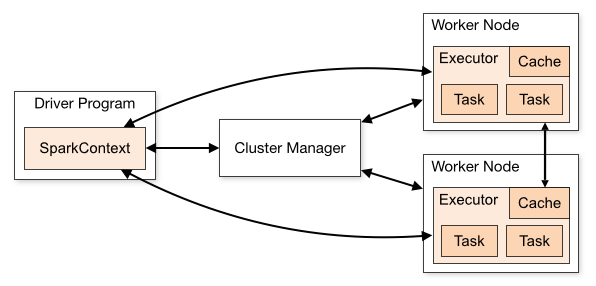
Архитектура приложения Spark состоит из трех основных частей:

Программа-драйвер : отвечает за организацию выполнения обработки данных.
Менеджер кластера : это компонент, отвечающий за управление различными машинами в кластере. Требуется только в том случае, если Spark работает в распределенном режиме.
Рабочие узлы : это машины, которые выполняют задачи программы. Если Spark запущен локально на вашем компьютере, он будет играть роль программы-драйвера и рабочей роли. Такой способ запуска Spark называется автономным.
Код Spark может быть написан на разных языках. Консоль Spark, называемая Spark Shell, является интерактивной для изучения и изучения данных.
Так называемое приложение Spark состоит из одного или нескольких заданий, что позволяет поддерживать крупномасштабную обработку данных.
Когда мы говорим о выполнении, у Spark есть два режима:
- Клиент: Драйвер запускается непосредственно на клиенте, который не проходит через диспетчер ресурсов.
- Кластер: Драйвер, работающий на мастере приложений через диспетчер ресурсов (в режиме кластера, если клиент отключается, приложение продолжит работу).
Необходимо правильно использовать Spark, чтобы связанные службы, такие как диспетчер ресурсов, могли определить потребность в каждом выполнении, обеспечивая наилучшую производительность. Таким образом, разработчик должен знать, как лучше всего запускать свои задания Spark, структурируя сделанный вызов, и для этого вы можете структурировать и настраивать исполнителей Spark так, как вы хотите.
Задания Spark в основном используют память, поэтому обычно настраиваются значения конфигурации Spark для исполнителей рабочих узлов. В зависимости от рабочей нагрузки Spark можно определить, что определенная нестандартная конфигурация Spark обеспечивает более оптимальное выполнение. С этой целью можно выполнить сравнительные тесты между различными доступными параметрами конфигурации и самой конфигурацией Spark по умолчанию.
Варианты использования
Apache Spark помогает обрабатывать огромные объемы данных, будь то в режиме реального времени или в архиве, структурированные или неструктурированные. Ниже приведены некоторые из его популярных вариантов использования.
Обогащение данных
Часто компании используют комбинацию исторических данных о клиентах с поведенческими данными в реальном времени. Spark может помочь построить непрерывный конвейер ETL для преобразования неструктурированных данных о событиях в структурированные данные.
Обнаружение триггерного события
Spark Streaming позволяет быстро обнаруживать редкие или подозрительные действия, которые могут указывать на потенциальную проблему или мошенничество, и реагировать на них.
Комплексный анализ данных сеанса
С помощью Spark Streaming можно группировать и анализировать события, связанные с сеансом пользователя, например его действия после входа в приложение. Эту информацию также можно постоянно использовать для обновления моделей машинного обучения.
Плюсы
Итеративная обработка
Если задача заключается в повторной обработке данных, устойчивые распределенные наборы данных (RDD) Spark позволяют выполнять несколько операций сопоставления в памяти без необходимости записи промежуточных результатов на диск.
Графическая обработка
Вычислительная модель Spark с GraphX API отлично подходит для итерационных вычислений, характерных для обработки графики.
Машинное обучение
В Spark есть MLlib — встроенная библиотека машинного обучения с готовыми алгоритмами, которые также выполняются в памяти.
Кафка против Спарка
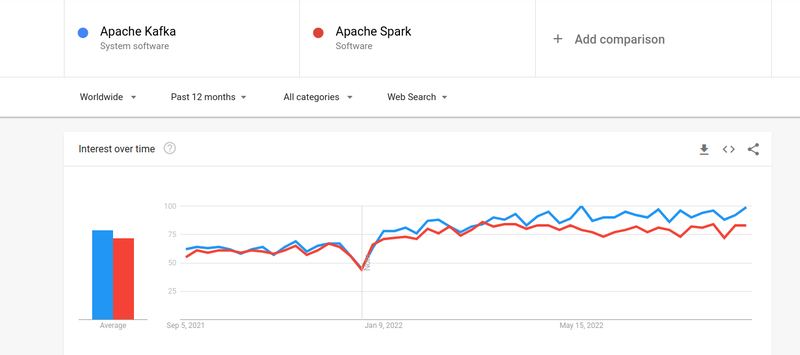
Несмотря на то, что интерес людей и к Кафке, и к Спарку был почти одинаковым, между ними существуют некоторые существенные различия; Давайте посмотрим.
№1. Обработка данных
Kafka — это инструмент для потоковой передачи и хранения данных в реальном времени, отвечающий за передачу данных между приложениями, но этого недостаточно для создания полноценного решения. Поэтому для задач, которых нет у Kafka, нужны другие инструменты, например Spark. Spark, с другой стороны, представляет собой платформу пакетной обработки данных, которая извлекает данные из разделов Kafka и преобразует их в комбинированные схемы.
№ 2. Управление памятью
Spark использует надежные распределенные наборы данных (RDD) для управления памятью. Вместо того, чтобы пытаться обрабатывать огромные наборы данных, он распределяет их по нескольким узлам в кластере. Напротив, Kafka использует последовательный доступ, аналогичный HDFS, и хранит данные в буферной памяти.
№3. Преобразование ETL
И Spark, и Kafka поддерживают процесс преобразования ETL, который копирует записи из одной базы данных в другую, обычно из транзакционной основы (OLTP) в аналитическую основу (OLAP). Однако, в отличие от Spark, который поставляется со встроенной возможностью для процесса ETL, Kafka полагается на Streams API для его поддержки.
№ 4. Сохранение данных

Использование RRD в Spark позволяет хранить данные в нескольких местах для последующего использования, тогда как в Kafka вам необходимо определить объекты набора данных в конфигурации для сохранения данных.
№ 5. Сложность
Spark — это комплексное решение, которое легче освоить благодаря поддержке различных языков программирования высокого уровня. Kafka зависит от ряда различных API и сторонних модулей, что может затруднить работу с ним.
№ 6. Восстановление
И Spark, и Kafka предоставляют варианты восстановления. Spark использует RRD, что позволяет ему непрерывно сохранять данные, и в случае сбоя кластера их можно восстановить.

Kafka постоянно реплицирует данные внутри кластера и репликацию между брокерами, что позволяет вам переходить к другим брокерам в случае сбоя.
Сходства между Спарком и Кафкой
| Апач Спарк | Апач Кафка |
| Открытый исходный код | Открытый исходный код |
| Создание приложения для потоковой передачи данных | Создание приложения для потоковой передачи данных |
| Поддерживает обработку состояния | Поддерживает обработку состояния |
| Поддерживает SQL | Поддерживает SQL |
Заключительные слова
Kafka и Spark — это инструменты с открытым исходным кодом, написанные на Scala и Java, которые позволяют создавать приложения для потоковой передачи данных в реальном времени. У них есть несколько общих черт, включая обработку с отслеживанием состояния, поддержку SQL и ETL. Kafka и Spark также можно использовать в качестве взаимодополняющих инструментов, помогающих решить проблему сложности передачи данных между приложениями.