
如何使用谷歌數據集搜索數據集架構
已發表: 2019-10-01Google 數據集搜索:如何使用數據集架構進行查詢
2021 年 6 月 12 日更新
隨著數字數據數量的不斷增加,搜索營銷策略師面臨著越來越需要從數據中獲取意義。
許多高級數據庫應用程序開始支持 Google 數據庫搜索。 此外,SEO 還在 2019 年 9 月向 Google Search Console 添加了新報告,以更好地了解他們的數據。 通過將編碼為本體的領域級知識整合到對關係數據的查詢中,可以獲得很多好處。 對 SEO 說了這麼多,搜索營銷人員發現從虛構中篩選出事實更具挑戰性,從有用的 SEO 策略中篩選出有害的,以及經過測試的真實而不是僅僅談論。
很大程度上依賴過去的搜索營銷經驗和直覺很好,但往往不正確。 事實證明,受數據影響的決策始終比“我的直覺告訴我”要好。 許多數據洞察工具(如穀歌分析)提供了實際的支持證據,但現在比以往任何時候都更容易定位谷歌云公共數據集。
什麼是谷歌數據集搜索?
一個快速的大圖是,谷歌數據搜索依賴於數據集提供商,無論大小,使用開放的 schema.org/Dataset 標准在他們的網站中添加結構化的元數據。 Google 數據集搜索使搜索者能夠通過使用特定搜索詞組進行搜索來定位存儲在網絡上的數據集。 據谷歌稱,該工具可以顯示有關託管在網絡上數千個存儲庫中的數據集的信息,從而使這些數據集普遍可訪問和有用。
通過訪問與您的業務利基相關的高需求公共數據集,您可以從雲數據中發現新的消費者洞察。 通過分析 BigQuery 和 Cloud Storage 中託管的其他數據集,可以更輕鬆地體驗 Google Cloud 的全部價值。
數據記者已經熟悉獲取政府數據和社會科學數據集。 本文將幫助您建立基線並設置數據驅動的框架來衡量您的數字化進度並利用最新的 Google 架構標記機會。
谷歌的數據集搜索被認為是谷歌推出的一種搜索引擎,旨在幫助學者找到他們可能需要的數據。 搜索營銷人員正在更多地利用數據集。
數據集是否簡化了數據智能和復雜的本體?
是的。 當支持信息(例如提供者的名稱、描述、創建者和分發格式)使用結構化數據進行標記時,數據集更易於定位。 Google 通過 schema.org 和其他可以添加到描述數據集的 Web 內容中的元數據標準使數據集發現變得更加容易。
一旦谷歌建立了它的圖書館索引,它就會開始回答用戶查詢——並確定哪些結果最符合每個人的查詢,無論是口語還是打字。
“用關係 SQL 查詢語言或其擴展來表達對圖結構本體的查詢是極其困難的。 此外,語義查詢通常並不精確,尤其是當數據及其相關本體很複雜時。”
用戶甚至不需要知道本體表示。 所需要的只是用戶給出一些滿足他所想的查詢的例子。 接下來, Google 的系統會自動找到查詢的答案。 在這個過程中,語義這個通常很難表達的概念,在用戶的腦海中仍然是一個概念,而不必用查詢語言明確表達。 – Google 白皮書:語義查詢示例 *****
這提供了一個機會。 任何構建自然語言處理的人都可以使用基於海量數據集的預訓練模型。 從閱讀理解到情感分析再到 BERT; 一個關鍵的研究趨勢是 NLP 中遷移學習的興起。
隨著對數據消化需求的增加,搜索營銷人員的角色演變變得更加複雜。 創建自己的數據集是一種積極的 SEO 形式,可以融入學術文獻。 重新思考如何在更廣泛的層面應用圖像數據可能是一個起點。 這將有助於可擴展系統確定鏈接圖和網絡鏈接網絡中的短路徑。 在重新抓取和重新計算您網站的鏈接地圖時,它可能會幫助 Google。
“在描述打包數據的集合時,例如在科學、學術或政府“開放數據”存儲庫中發布的數據,可以使用 Dataset 類型,與 DataCatalog 一起指示整個集合,並使用 DataDownload 來表示數據集的特定表示。 – 數據和數據集 – schema.org
添加數據集架構的步驟
- 首先,閱讀數據集文檔標記以了解如何將其添加到您的域而不是單個 DCAT 文件。
- 接下來,以 Google 首選的 JSON-LD 標記格式將結構化數據片段添加到您的集合中; 使用數據集類型的模式。
- 使用 Google 結構化數據測試工具測試您的數據集實施。
- 最後,在站點地圖中提交您的網址,該站點地圖告訴 Googlebot 開始抓取數據集頁面。
注意:Google 確實接受帶有 DCAT 格式的標記。 Google 的數據集架構旨在顯示描述一些組織信息的結構化信息主體。 它可以在正文或頭部插入 JSON 結構化數據。
使用 JSON-LD 代碼和模式詞彙的 Google 數據集
什麼是谷歌數據集搜索引擎?
谷歌數據集搜索引擎是當用戶使用谷歌試圖找到可公開獲取的在線數據時。 Google 數據集搜索旨在與公司用於學術研究、研究和報告的搜索引擎 Google Scholar 一起工作。
最近對 Google 數據集文檔頁面的更改更新了在 Google 搜索的豐富結果中向網站管理員、SEO 和發布商推出數據集結構化數據的方式。 它與我們使用 Schema.org 的常見方式不同,數據集模式可以是任意格式或表示聚合統計信息。
Aaron 解釋說,谷歌在通知中用星號去掉了爪子圖標,他說:“這表明數據集豐富結果的推出迫在眉睫。”
為什麼要使用 Schema 標記數據集?
理想的客戶體驗常常讓人難以捉摸。 繪製客戶旅程圖並整理成堆的數字數據字符串並不容易。 這不僅僅是為正確的客戶提供正確的報價。 它從購買時間、數字渠道、過去報價的數據收集開始,有時甚至更多。 數據管理已經從戰術性媒體購買思維轉變為如何實施正確的戰略洞察力,這些洞察力是建立品牌信任的企業客戶體驗的核心。
您的內容可以更好地理解、匹配和用於答案和解決方案。 數據集模式利用機器學習方法來處理關係數據庫中的語義查詢。 在語義查詢處理中,最大的障礙是以關係形式提供準確的本體數據,以便關係數據庫引擎能夠以與操作數據一致的方式操作本體。
用模式標記的數據集更容易被其他人解釋,也更容易讓搜索引擎更好地理解數據。 這有助於他們將這種理解轉化為數據的可視化插圖。
谷歌表示數據集可用於以下情況:
- 包含一些數據的表格或 CSV 文件
- 有組織的表格集合
- 包含數據的專有格式的文件
- 一組文件共同構成了一些有意義的數據集
- 具有其他格式數據的結構化對象,您可能希望將其加載到特殊工具中進行處理
- 圖像捕捉數據
- 與機器學習相關的文件,例如訓練參數或神經網絡結構定義
- 任何對你來說看起來像數據集的東西
我們發現了一些巨大的數據集。 最好保持簡單。 谷歌建議“將所有文本屬性限制在 5000 個字符以內。 Google 數據集搜索僅使用任何文本屬性的前 5000 個字符。 名稱和標題通常是幾個詞或一個簡短的句子”。
如何使用安全、可靠的關係數據庫實現數據現代化
關係數據庫將數據收集並存儲在表和列中,從而組織和強調數據之間的關係。 關係數據庫適用於結構化和連接的數據。 Webopedia 將關係數據庫定義為能夠“設置為在數據的一個實例被編輯或更改時自動更新數據; 其他相關數據將實時更新。 人們經常交替使用關係數據庫和關係數據庫管理系統 (RDBMS)”。
這有助於企業使用現代架構構建數據解決方案,並實時獲得業務智能洞察,以更好地滿足用戶意圖。
表到文本模型從結構化數據中提取文本信息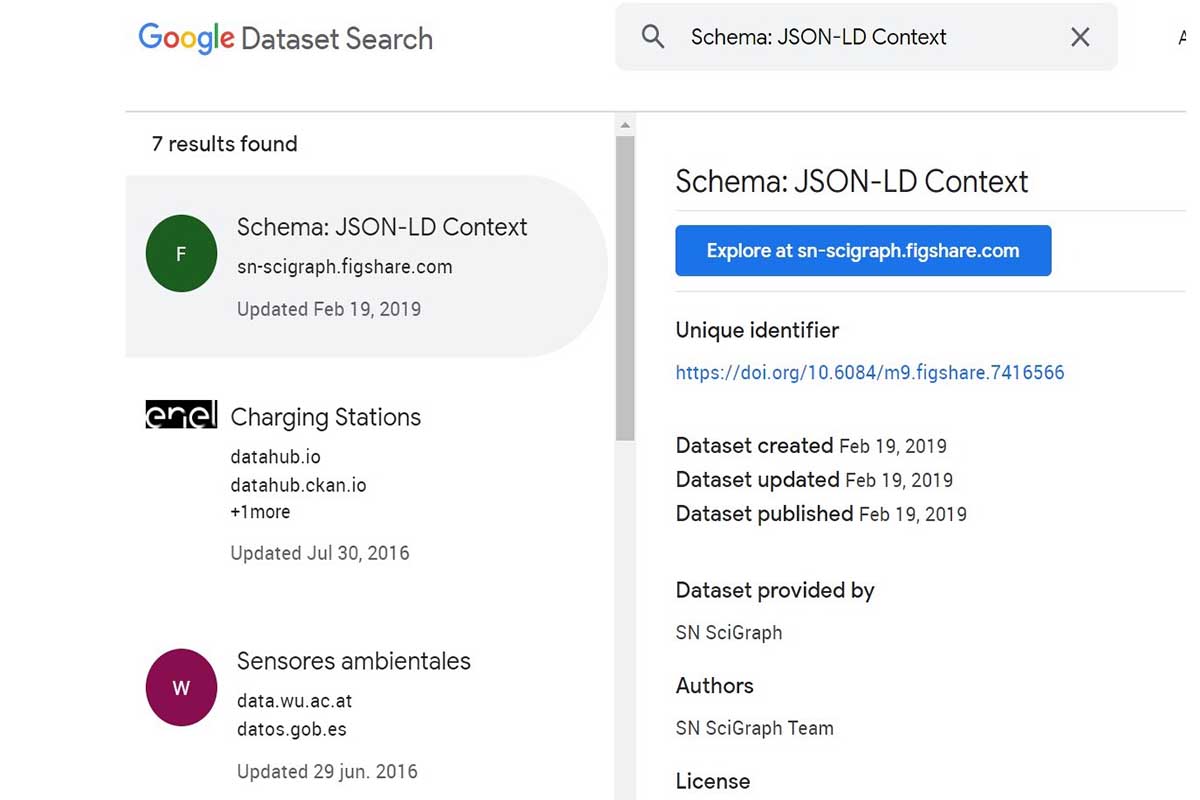
以數據為導向,以人為本
獲得用於字段級數據提取的順序機制有助於執行最終分類或回歸任務,評估您的總體輸入特徵,將它們映射到替代數據類型。
谷歌數據集報告可以幫助您更好地思考匹配搜索意圖。 搜索在線數據庫以查找您需要的內容或聘請數據科學家。 數據集豐富的結果對於快速研發工作流程非常有用,有助於將原始數據編碼簡化為有意義的見解。 它們有助於為您的數據創建結構化方法。 企業可以通過簡化決策流程和更快地獲得更高績效的結果而受益。
“快速研發進展的主要推動力之一是規範神經網絡架構的可用性,可以有效地將原始數據編碼為有意義的表示。 這些規範的架構與簡單的決策層集成,通常只需少量的額外調整工作即可在新數據集和相關任務上產生高性能。” – Google Cloud AI 上的細心可解釋表格學習
Google 數據集搜索測試版有哪些變化? 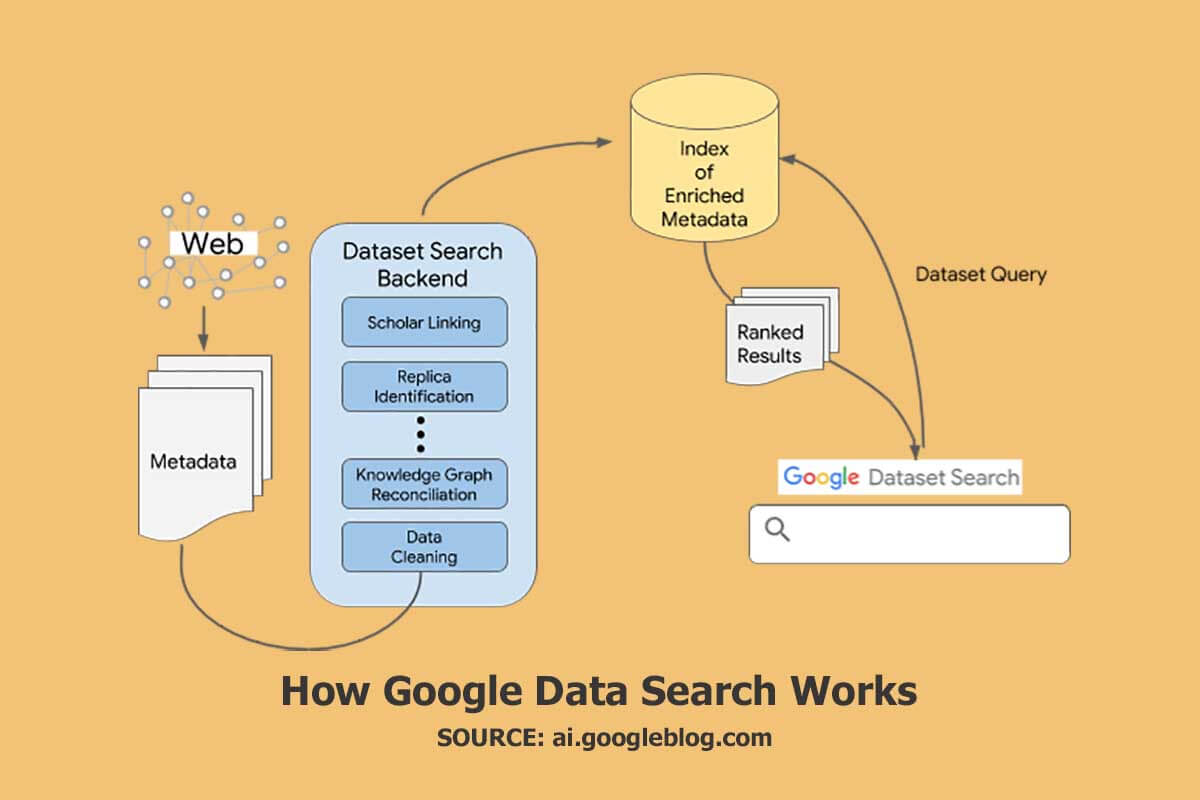
以前,谷歌文檔指出:“數據集標記在發佈到普遍可用之前可供您試驗”,並警告說,雖然您可以使用結構化數據測試工具進行驗證,但您“不會,但是,請查看您的數據集出現在搜索中。” 對於那些等待此功能推出的人,將數據集結構化數據添加到您的網站可以幫助衡量移動挑戰和屬性規範。 谷歌數據集搜索支持谷歌學術,這家科技公司的學術研究和基於事實的報告的搜索引擎。
2020 年 1 月 23 日,Google 的 Natasha Noy 表示:“Dataset Search 已為其中近 2500 萬個數據集編制索引,讓您可以在一個地方搜索數據集並找到指向數據所在位置的鏈接。 在過去的一年裡,人們已經嘗試過並提供了反饋,現在 Dataset Search 正式退出測試版。”
在網絡上發現數百萬個數據集一文告訴我們,世界上大多數政府都會發布他們的數據並使用 schema.org 對其進行標記。 “美國在可用的開放政府數據集數量上領先,超過 200 萬。”
這意味著市場研究人員比我們的數字歷史上任何時候都可以更好地訪問數據。
數據集可以管理您網站的所有內容
一旦收集乾淨和有用的數據,即使需要大量時間,它也可以支持和幫助管理您網站上的所有內容。
您可以學習如何使用具有更真實數據集的不同機器學習任務來獲得更真實的信息。 對於您的每個業務 KPI,Hill Web Marketing 可以幫助您了解哪些指標很重要,如何使用架構將它們與您的行業目標保持一致,並規劃如何獲得改進的性能。
Google AI 的研究科學家 Natasha Noy 於 2018 年 9 月 5 日發表了讓發現數據集變得更容易,並指出“數據集搜索支持多種語言,即將支持其他語言”。**** 顯然,這是網絡的發展方向; 實施基本類型的 Schema 標記將幫助您找到業務。
使用數據集有助於確保產品收入流
谷歌數據集搜索是如何工作的?
當您提供包含名稱、描述、創建者和分發格式等結構化數據的信息時,可以輕鬆發現數據集。 Google 正在增強數據集發現能力,並利用 schema.org 和其他可合併到描述數據集的網頁中的數據格式。 此架構可以支持您出現在產品輪播搜索結果中的機會。
您的企業未來的成功取決於推動您的組織實現持續收入流所需的洞察力。 關於您的產品的信息需要激發潛在買家足夠的信心,以採取必要的行動來達成交易。 您對公司知識圖中顯示的內容有一定程度的控制。 “風險很高,國際數據公司估計,到 2020 年,全球對 D&A 的商業投資將超過每年 2000 億美元”,據《哈佛商業評論》報導。

“一個強大、成功的 D&A(數據和分析)功能不僅包含一堆技術,也不僅僅包含隔離在大樓一層的幾個人。 D&A 應該是組織的脈搏,並納入銷售、營銷、供應鏈、客戶體驗和其他核心職能的所有關鍵決策中。” - 哈佛商業評論
產品圖片可以是 Google 圖片數據集的一部分! 在某些數據集中,每張圖像平均有 8.4 個對象。 這是一個經常更新的數據集列表。
Google 的文檔頁麵包含一個用於實現 schema.org/Dataset 的 JSON-LD 示例。 由於管狀數據集處於測試階段,將出現數據集描述和使用的最佳實踐。 隨著代碼要求的變化,進行技術 SEO 審核以找到需要更新的地方。
如何將產品和圖像數據集上傳到 Google BigQuery?
Google BigQuery (GBQ) 允許搜索營銷人員從不同來源收集數據。 我們建議使用 Google Merchant Center、Cloud Storage、BigQuery,或者您可以在發出請求時指定內聯數據。 在您上傳任何數據之前,首先在 Google BigQuery 中創建一個數據集和表,其中包含您的產品信息,包括圖片詳細信息。 ***
我們更喜歡使用 Product item JSON-LD 數據格式。 這是一個完整對象的示例:
{
"name": "projects/[PROJECT_NUMBER]/locations/global/catalogs/default_catalog/branches/0/products/1234",
"id": "1234",
"categories": "Apparel & Accessories > Shoes",
"title": "ABC sneakers",
"description": "Sneakers for the rest of us",
"attributes": { "vendor": {"text": ["vendor123", "vendor456"]} },
"language_code": "en",
"tags": [ "black-friday" ],
"priceInfo": {"currencyCode": "USD", "price":100, "originalPrice":200, "cost": 50},
"availableTime": "2020-01-01T03:33:33.000001Z",
"availableQuantity": "1",
"uri":"http://foobar",
"images": [{"uri": "http://foobar/img1", "height": 320, "width": 320 }]
}
使您的產品目錄保持最新。 谷歌關心質量,它的人工智能需要高質量的數據才能做出高質量的預測。 注意不再出售的產品,並在您網站的電子商務產品架構標記中更新數據。
“表格數據集是主要根據行和列的網格組織的數據集。 對於嵌入表格數據集的頁面,您還可以在上述基本方法的基礎上創建更明確的標記。 目前,我們了解 CSVW(“Web 上的 CSV”,參見 W3C)的一個變體,它與 HTML 頁面上面向用戶的表格內容並行提供。”,它聲明截至 2019 年 9 月 30 日。
如果為 Dataset、DataCatalog 或 DataDownload 列出的屬性發生變化,請繼續關注 Google 文檔頁面以獲取更新。 當前文件更新了組織方面; 屬性規範現在合併到每個屬性所屬的類型下(以前它們是按主題組織的)。 這些新屬性是增強網站屬性的一種方式。
如何從圖像創建數據集以進行對象分類。
在 IBM 集群管理控制台中,選擇 (1) 工作負載、(2) Spark,然後選擇 (3) 深度學習。 **
* 單擊“數據集”選項卡。
* 選擇“新建”。
* 從“用於對象分類的圖像”創建數據集。
* 輸入數據集名稱。
* 指明您想要的 Spark 實例組。
* 指定您喜歡的圖像存儲格式(我們更喜歡 TensorFlow 的 TFRecords)。
* 如果選擇了 TFRecords,請導航到如何按分片或類生成記錄。 如果選擇了分片,請輸入分片號。
* 指定如何選擇訓練圖像。
通過遵守 Google 圖片指南和 AMP 圖片要求,您的產品更有可能出現在與產品相關的特色片段中。
數據集結構化數據屬性
確實,此時所需的屬性很少。 為了鼓勵使用它,這家技術巨頭在為機器數據消費者提供內容時可能會採取“保持簡單”的策略。 最終目標是在其數據庫中擁有更多更好的匹配項,以滿足用戶的搜索意圖。
所需屬性:
- 姓名
- 描述
推薦屬性:
- 備用名稱
- 創造者
- 引文
- 標識符
- 關鍵詞
- 執照
- 與...一樣
- 空間覆蓋
- 時間覆蓋
- 變量測量
- 版本
- 網址
您可能尚未在網絡上發布數據集,但搜索營銷正在迅速轉向更多的數據科學搜索方法。 隨著個人和人們可以訪問越來越多的數據集,數據集搜索將會增加。 令人驚訝的是,任何發布數據的人都可以使用 schema.org 的描述信息的開放標準來描述他們的數據集。
在 Search Console 索引報告中測試您的數據時,請通讀“已知錯誤和警告”部分、“Google 結構化數據測試工具中的錯誤或警告”以及結構化數據 Linter 驗證系統。 聘請架構數據實施專家或使用表格來幫助篩選出您可以安全地放過哪些警告。
由於這涉及到 Web 內容的解析——無論它是否已經包含結構化數據——最好以最高比例的數據消費者(最重要的是搜索引擎)理解的格式提供數據。
數據集為構建知識圖譜提供了路線圖
查找數據集並利用來自開放數據源和 https schema.org 的學術搜索。
研究人員重視對揭示市場動態的全球數據科學和機器學習解決方案的精確分析。 尋求衡量可持續營銷趨勢的搜索營銷人員依靠大數據來支持未來的市場增長。 谷歌數據集搜索完成測試版後,它可能具有進行數據研究的新功能,可以減少企業當前面臨的風險和挑戰。 對數據中的細節進行廣泛研究可以改進您的銷售方法。
我們繼續尋求構建客戶知識圖譜的實用方法,並有機會將它們用於業務應用程序。 試試你的手。
在您的站點上使用數據集架構後,您將在 GSC 中的增強功能下找到一個新報告。 我們使用它們來改進我們針對來自多種設備的用戶的移動內容營銷策略。
數據集功能和新的 Google 增強報告
與其他結構化數據實現的情況一樣,僅僅因為您合併了模式結構化數據,您就有資格。 但是,它不保證會出現在 Google 搜索中。 優先使用支持銷售和零售登陸頁面的數據集。
在發布結構化數據功能的同時,Google Search Console 中出現了新的數據集增強報告。 這會告知搜索營銷策略師 Google 是否已經學習並識別了您的數據集架構的結構化數據。 了解數據集結構化數據文檔規範後,通讀並修復任何結構化數據錯誤。 它將提供您的 Google 助理數據。
很少有企業主或內容創建者有空閒時間考慮您的元數據格式是否正確。 然而,它必須允許 GoogleBot 抓取您的網站、查找您的數據並將其編入索引。 幸運的是,我們喜歡它並且在您的角落。
數據集構建權限
構建權限與數據集相關。 當用戶被授予構建權限時,他們可以在現有數據集上構建新內容。 這對於報告、儀表板、來自 QandA 的固定磁貼和 Insights Discovery 很常見。 他們還可以在 Power BI 之外的數據集上構建新的數據條目,通常是通過在 Excel、XMLA 中分析的 Excel 工作表,並導出基礎數據。 它可以幫助企業進行客戶分析。
與深度學習一樣新穎而全面,谷歌和其他搜索引擎仍然面臨著在生產中部署的機器學習管道環境中出現的數據管理挑戰。 理解語義搜索查詢的新努力旨在支持理解、驗證、清理和豐富訓練數據。 由此,可信數據庫源的增長有望擴大,並更有助於推動商店流量。
數字營銷受到對數據的需求以及將其用作科學方法的約束。
“像這樣的搜索工具僅與數據發布者願意提供的元數據一樣好。 我們希望看到你們中的許多人使用開放標準來描述您的數據,使我們的用戶能夠找到他們正在尋找的數據。 如果您發布數據但未在結果中看到它,請訪問我們在開發人員網站上的說明,其中還包含一個用於提問和提供反饋的鏈接。” - 谷歌 *
“我們可以使用 http://schema.org 數據集標記或以 W3C 的數據目錄詞彙 (DCAT) 格式表示的等效結構來理解網頁中有關數據集的結構化數據。” ——艾倫·莫里森在推特上的評論
Google 數據集架構摘要
使用數據集來滿足站點用戶的需求更側重於用戶體驗並添加回答和通知的實體。 雖然它可能起源於數據科學社區,但任何企業都可以使用它。 我們還建議向在數據集的結構化數據標記方面經驗豐富的高級專家尋求同行評審意見。
Hill Web Marketing 渴望參與這項計劃,並希望它能鼓勵我們的讀者擴展當前可用的數據集數量。 雖然它可能起源於數據科學社區,但任何企業都可以使用它。
請致電數字營銷策略師 Hill Web Marketing 的所有者珍妮·希爾 (Jeannie Hill) 合作夥伴:651-206-2410。 安排您的諮詢以獲得競爭優勢
* https://arxiv.org/pdf/1908.07442.pdf
** https://www.ibm.com/support/knowledgecenter/SSWQ2D_1.1.0/us/create-dataset-image-object-classification.html
*** https://cloud.google.com/retail/recommendations-ai/docs/upload-catalog
**** https://www.blog.google/products/search/making-it-easier-discover-datasets/
***** https://storage.googleapis.com/pub-tools-public-publication-data/pdf/40761.pdf