
So verwenden Sie die Google-Datensatzsuche für das Datensatzschema
Veröffentlicht: 2019-10-01Google Dataset Search: So verwenden Sie das Dataset-Schema für Abfragen
Aktualisiert am 12.6.2021
Angesichts der wachsenden Mengen digitaler Daten sehen sich Suchmaschinenmarketing-Strategen einem wachsenden Bedürfnis gegenüber, aus den Daten einen Sinn zu machen.
Viele fortschrittliche Datenbankanwendungen beginnen damit, die Google-Datenbanksuche zu unterstützen. Außerdem haben SEOs im September 2019 neue Berichte zur Google Search Console hinzugefügt, um ihre Daten besser zu verstehen. Es wird viel gewonnen, wenn als Ontologien codiertes Wissen auf Domänenebene in Abfragen über relationale Daten integriert wird. Da so viel über SEO gesagt wird, finden es Suchmaschinen-Vermarkter schwieriger, Fakten von Fiktionen, schädlichen von hilfreichen SEO-Taktiken und geprüften Wahrheiten gegenüber bloßem Gerede zu trennen.
Sich weitgehend auf vergangene Erfahrungen und Intuitionen im Suchmaschinenmarketing zu verlassen, ist nett, aber zu häufig falsch. Datenbeeinflusste Entscheidungen erweisen sich durchweg besser als „mein Bauchgefühl sagt“. Viele Data-Insight-Tools wie Google Analytics liefern tatsächlich unterstützende Beweise, aber jetzt ist es einfacher denn je, öffentliche Google Cloud-Datensätze zu finden.
Was ist die Google-Datensatzsuche?
Ein schnelles Gesamtbild ist, dass die Google-Datensuche von Datensatzanbietern abhängig ist, ob groß oder klein, die strukturierte Metadaten innerhalb ihrer Websites hinzufügen, indem sie den offenen schema.org/Dataset-Standard verwenden. Die Google-Datensatzsuche ermöglicht Suchenden das Auffinden von im Internet gespeicherten Datensätzen durch Suchen mit bestimmten Suchphrasen. Laut Google zeigt das Tool Informationen über Datensätze an, die in Tausenden von Repositories im Internet gehostet werden, wodurch diese Datensätze universell zugänglich und nützlich werden.
Durch den Zugriff auf stark nachgefragte öffentliche Datensätze, die sich auf Ihre Geschäftsnische beziehen, können Sie neue Verbrauchereinblicke aus Cloud-Daten gewinnen. Durch die Analyse zusätzlicher Datensätze, die in BigQuery und Cloud Storage gehostet werden, ist es einfacher, den vollen Wert von Google Cloud auszuschöpfen.
Datenjournalisten sind bereits mit der Beschaffung von Behördendaten und Datensätzen für die Sozialwissenschaften vertraut. Dieser Artikel hilft Ihnen dabei, eine Basislinie zu erstellen und ein datengesteuertes Framework einzurichten, um Ihren digitalen Fortschritt zu messen und die neuesten Google-Schema-Markup-Möglichkeiten zu nutzen.
Die Datensatzsuche von Google wird als eine Art Suchmaschine anerkannt, die von Google mit der Absicht gestartet wurde, Wissenschaftlern dabei zu helfen, die Daten zu finden, die sie möglicherweise benötigen. Suchmaschinenvermarkter setzen zunehmend auf Datensätze.
Vereinfachen Datensätze Datenintelligenz und komplizierte Ontologie?
Jawohl. Datensätze sind einfacher zu finden, wenn unterstützende Informationen wie Name des Anbieters, Beschreibung, Ersteller und Verbreitungsformate mit strukturierten Daten gekennzeichnet sind. Google erleichtert das Auffinden von Datensätzen durch schema.org und andere Metadatenstandards, die zu Webinhalten hinzugefügt werden können, die Datensätze darstellen.
Sobald Google seinen Bibliotheksindex erstellt hat, beginnt es mit der Beantwortung von Nutzeranfragen – und der Bestimmung, welche Ergebnisse am besten zu den Suchanfragen der einzelnen Personen passen, gesprochen oder getippt.
„Es ist extrem schwierig, Abfragen gegen eine graphstrukturierte Ontologie in der relationalen SQL-Abfragesprache oder ihren Erweiterungen auszudrücken. Darüber hinaus sind semantische Abfragen normalerweise nicht präzise, insbesondere wenn Daten und die zugehörige Ontologie kompliziert sind.“
Benutzer müssen nicht einmal die Darstellung der Ontologie kennen. Alles, was erforderlich ist, ist, dass der Benutzer einige Beispiele gibt, die die Frage erfüllen, die er im Sinn hat. Als nächstes findet das Google-System automatisch die Antwort auf die Anfrage . Dabei bleibt die Semantik, die normalerweise ein schwer auszudrückendes Konzept ist, als Konzept im Kopf des Benutzers, ohne dass es explizit in einer Abfragesprache ausgedrückt werden muss. – Google Whitepaper: Semantische Abfragen am Beispiel *****
Dies bietet eine Chance. Vortrainierte Modelle auf riesigen Datensätzen stehen jedem zur Verfügung, der die Verarbeitung natürlicher Sprache entwickelt. Vom Leseverständnis über die Sentimentanalyse bis hin zum BERT; Ein wichtiger Forschungstrend ist der Aufstieg des Transferlernens im NLP.
Die Entwicklung der Rolle eines Suchmaschinenmarketingspezialisten ist komplexer geworden, da Daten immer mehr verarbeitet werden müssen. Das Erstellen eines eigenen Datensatzes ist eine Form der positiven SEO, die sich an die wissenschaftliche Literatur anlehnen kann. Überdenken Sie, wie Sie Ihre Bilddaten auf einer breiteren Ebene anwenden können, kann ein Ansatzpunkt sein. Dies unterstützt skalierbare Systeme bei der Bestimmung kurzer Pfade innerhalb Ihres Link-Graphen und Weblink-Netzwerks. Es hilft Google wahrscheinlich beim erneuten Crawlen und Neuberechnen der Link-Map Ihrer Website.
„Bei der Beschreibung von Sammlungen von gepackten Daten, wie sie beispielsweise in wissenschaftlichen, wissenschaftlichen oder staatlichen „Open Data“-Repositorien veröffentlicht werden, kann der Datensatztyp neben DataCatalog verwendet werden, um die Gesamtsammlung anzugeben, und DataDownload für spezifische Darstellungen eines Datensatzes.“ – Daten und Datensätze – schema.org
Schritte zum Hinzufügen eines Dataset-Schemas
- Lesen Sie zuerst das Dataset-Dokumentations-Markup, um zu erfahren, wie Sie es zu Ihrer Domain im Vergleich zu einer einzelnen DCAT-Datei hinzufügen können.
- Als nächstes fügen Sie Ihrer Sammlung strukturierte Datenausschnitte im bevorzugten JSON-LD-Markup-Format von Google hinzu; Verwenden Sie den Schematyp Dataset.
- Testen Sie Ihre Dataset-Implementierung mit dem Testtool für strukturierte Daten von Google.
- Senden Sie zuletzt Ihre URLs in einer Sitemap, die den Googlebot anweist, mit dem Crawlen der Datensatzseiten zu beginnen.
HINWEIS: Google akzeptiert Markup mit DCAT-Formatierung. Das Datensatzschema von Google soll einen Körper strukturierter Informationen anzeigen, die einige organisierte Informationen beschreiben. Es funktioniert, um entweder strukturierte JSON-Daten entweder in den Körper oder den Kopf einzufügen.
Google Datasets mit JSON-LD-Code und Schema-Vokabular
Was ist die Google-Datensatz-Suchmaschine?
Eine Google Dataset-Suchmaschine ist, wenn ein Benutzer Google beauftragt hat, zu versuchen, Online-Daten zu finden, die öffentlich zugänglich sind. Google Dataset Search soll mit Google Scholar, der Suchmaschine der Unternehmen für akademische Studien, Forschung und Berichte, zusammenarbeiten.
Jüngste Änderungen an der Datensatz-Dokumentationsseite von Google aktualisieren den Weg zur Einführung strukturierter Daten von Datensätzen für Webmaster, SEOs und Publisher in den Rich-Suchergebnissen in der Google-Suche. Es unterscheidet sich von der üblichen Art und Weise, wie wir Schema.org verwenden, das Datensatzschema kann in beliebigen Formaten vorliegen oder aggregierte Statistiken darstellen.
Aaron erklärt, dass Google das Pfotensymbol in der Mitteilung mit einem Stern gelöscht hat, was er sagte: „deutet darauf hin, dass die Einführung von Dataset-Rich-Ergebnissen unmittelbar bevorsteht.“
Warum sollten Sie Ihre Datensätze mit Schemas auszeichnen?
Das ideale Kundenerlebnis kann sich oft schwer anfühlen. Es ist nicht einfach, die Customer Journey abzubilden und sich durch Berge von digitalen Datenstrings zu sortieren. Es braucht mehr als nur das richtige Angebot für den richtigen Kunden. Das fängt bei den Kaufzeiten an, welcher digitale Kanal, die Datenerfassung aus vergangenen Angeboten und manchmal noch mehr. Das Datenmanagement hat sich vom taktischen Denken beim Medienkauf hin zur Implementierung der richtigen strategischen Erkenntnisse entwickelt, die das Herzstück von Unternehmenskundenerlebnissen bilden, die Markenvertrauen aufbauen.
Ihre Inhalte können besser verstanden, abgeglichen und für Antworten und Lösungen genutzt werden. Das Datensatzschema nutzt einen maschinellen Lernansatz, um semantische Abfragen in relationalen Datenbanken zu verarbeiten. Bei der semantischen Abfrageverarbeitung besteht die größte Hürde darin, genaue ontologische Daten in relationaler Form bereitzustellen, damit die relationale Datenbank-Engine die Ontologie auf eine Weise manipulieren kann, die mit der Manipulation der Daten übereinstimmt.
Datensätze, die mit Schemas gekennzeichnet sind, sind für andere einfacher zu interpretieren und für Suchmaschinen, um die Daten besser zu verstehen. Dies hilft ihnen, dieses Verständnis in visuelle Illustrationen Ihrer Daten zu übersetzen.
Laut Google können Datensätze für diese Fälle verwendet werden:
- Eine Tabelle oder eine CSV-Datei mit einigen Daten
- Eine organisierte Sammlung von Tabellen
- Eine Datei in einem proprietären Format, die Daten enthält
- Eine Sammlung von Dateien, die zusammen einen aussagekräftigen Datensatz bilden
- Ein strukturiertes Objekt mit Daten in einem anderen Format, das Sie möglicherweise zur Verarbeitung in ein spezielles Tool laden möchten
- Bilder erfassen Daten
- Dateien im Zusammenhang mit maschinellem Lernen, z. B. trainierte Parameter oder Strukturdefinitionen für neuronale Netze
- Alles, was für Sie wie ein Datensatz aussieht
Wir haben einige riesige Datensätze gefunden. Es ist am besten, es einfach zu halten. Google empfiehlt, „alle Texteigenschaften auf 5000 Zeichen oder weniger zu beschränken. Die Google-Datensatzsuche verwendet nur die ersten 5000 Zeichen einer Text-Property. Namen und Titel bestehen in der Regel aus wenigen Wörtern oder einem kurzen Satz.“
So modernisieren Sie Ihre Daten mit sicheren, zuverlässigen relationalen Datenbanken
Eine relationale Datenbank sammelt und beherbergt Daten in Tabellen und Spalten, die die Beziehungen zwischen den Daten organisieren und hervorheben. Relationale Datenbanken sind für strukturierte und verbundene Daten gedacht. Webopedia definiert relationale Datenbanken als in der Lage, „Daten automatisch zu aktualisieren, wenn eine Instanz davon bearbeitet oder geändert wird; die anderen zugehörigen Daten werden in Echtzeit aktualisiert. Menschen verwenden relationale Datenbanken und relationale Datenbankverwaltungssysteme (RDBMS) oft synonym.“
Dies hilft Unternehmen, Datenlösungen mit modernen Architekturen zu erstellen und in Echtzeit geschäftsintelligente Erkenntnisse zu gewinnen, um die Absichten der Benutzer besser zu erfüllen.
Table-to-Text-Modelle extrahieren Textinformationen aus strukturierten Daten 
Seien Sie datengesteuert und personenorientiert
Die Bereitstellung eines sequentiellen Mechanismus für die Datenextraktion auf Feldebene hilft bei der Durchführung der ultimativen Klassifizierungs- oder Regressionsaufgabe, bei der Ihre übergreifenden Eingabemerkmale bewertet und einem alternativen Datentyp zugeordnet werden.
Berichte zu Google-Datensätzen können Ihren Erkenntnissen dabei helfen, Ihre Überlegungen zur Übereinstimmung mit der Suchabsicht besser zu unterstützen. Durchsuchen Sie die Online-Datenbibliothek, um das zu finden, was Sie brauchen, oder beauftragen Sie einen Data Scientist. Dataset-Rich-Ergebnisse sind nützlich für schnelle Forschungs- und Entwicklungsworkflows, die dabei helfen, die Codierung der Rohdaten in aussagekräftige Erkenntnisse zu optimieren. Sie helfen dabei, einen strukturierten Umgang mit Ihren Daten zu schaffen. Unternehmen profitieren davon, indem sie ihre Entscheidungsprozesse rationalisieren und schneller zu leistungsfähigeren Ergebnissen kommen.
„Einer der Hauptgründe für den schnellen Forschungs- und Entwicklungsfortschritt ist die Verfügbarkeit kanonischer neuronaler Netzwerkarchitekturen, um die Rohdaten effizient in aussagekräftige Darstellungen zu codieren. Integriert in einfache Entscheidungsebenen bieten diese kanonischen Architekturen in der Regel eine hohe Leistung bei neuen Datensätzen und verwandten Aufgaben mit geringem zusätzlichen Abstimmungsaufwand.“ – Aufmerksames interpretierbares tabellarisches Lernen auf Google Cloud AI
Was hat sich in der Beta-Version der Google-Datensatzsuche geändert? 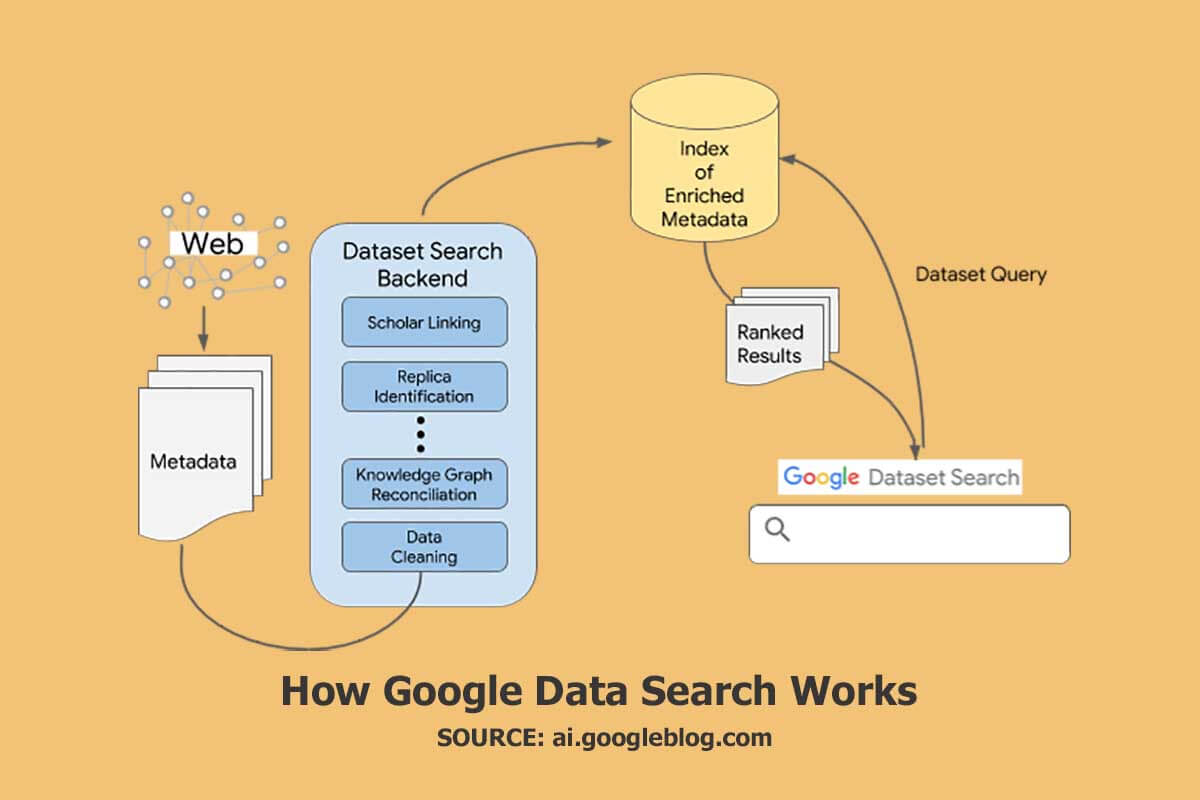
Früher hieß es in den Google-Dokumenten: „Das Datensatz-Markup steht Ihnen zum Experimentieren zur Verfügung, bevor es zur allgemeinen Verfügbarkeit freigegeben wird“, und warnten davor, dass Sie das Testtool für strukturierte Daten zwar zur Validierung verwenden können, dies aber „nicht tun werden , sehen jedoch, dass Ihre Datensätze in der Suche erscheinen.“ Für diejenigen, die auf die Einführung gewartet haben, kann das Hinzufügen von datensatzstrukturierten Daten zu Ihrer Website dabei helfen, mobile Herausforderungen und Eigenschaftenspezifikationen zu messen. Google Dataset Search unterstützt Google Scholar, die Suchmaschine des Technologieunternehmens für wissenschaftliche Studien und faktenbasierte Berichte.
Am 23. Januar 2020 erklärte Natasha Noy von Google: „Die Datensatzsuche hat fast 25 Millionen dieser Datensätze indiziert, sodass Sie an einem einzigen Ort nach Datensätzen suchen und Links zu den Daten finden können. Im Laufe des letzten Jahres haben die Leute es ausprobiert und Feedback gegeben, und jetzt ist Dataset Search offiziell aus der Betaphase heraus.“
Der Artikel Discovering millions of datasets on the web informiert uns darüber, dass die meisten Regierungen weltweit ihre Daten veröffentlichen und mit schema.org auszeichnen. „Die Vereinigten Staaten sind mit mehr als 2 Millionen führend in der Anzahl der verfügbaren offenen Regierungsdatensätze.“
Damit haben Marktforscher einen besseren Zugriff auf Daten als je zuvor in unserer digitalen Geschichte.
Datensätze können den gesamten Inhalt Ihrer Website verwalten
Sobald das Sammeln sauberer und nützlicher Daten erfolgt ist, kann es, auch wenn es viel Zeit in Anspruch nimmt, all diese Inhalte auf Ihrer Website unterstützen und dabei helfen, diese zu verwalten.
Sie können lernen, wie Sie sachlicher informiert sind, indem Sie verschiedene maschinelle Lernaufgaben mit realistischeren Datensätzen verwenden. Für jeden Ihrer geschäftlichen KPIs kann Hill Web Marketing Ihnen helfen zu verstehen, welche Metriken wichtig sind, wie Sie Schemata verwenden, um sie an Ihren Branchenzielen auszurichten, und darstellen, wie Sie eine verbesserte Leistung erzielen können.

Natasha Noy, Research Scientist für Google AI, veröffentlichte am 5. September 2018 " Making it better to discover datasets " und erklärt: "Die Datensatzsuche funktioniert in mehreren Sprachen, weitere Sprachen werden in Kürze unterstützt."**** Das ist ganz klar die Richtung, in die das Web geht; Die Implementierung der wesentlichen Arten von Schema-Markup hilft Ihrem Unternehmen, gefunden zu werden.
Die Verwendung von Datensätzen trägt dazu bei, Produkteinnahmeströme sicherzustellen
Wie funktioniert die Google-Datensatzsuche?
Datensätze können leicht gefunden werden, wenn Sie Informationen wie Name, Beschreibung, Ersteller und Verteilungsformate als strukturierte Daten bereitstellen. Google ermöglicht die Datensatzerkennung und nutzt schema.org und andere Datenformate, die in Webseiten integriert werden können, die Datensätze beschreiben. Dieses Schema kann Ihre Chancen unterstützen, in den Suchergebnissen des Produktkarussells zu erscheinen.
Der zukünftige Erfolg Ihres Unternehmens hängt von den Erkenntnissen ab, die erforderlich sind, um Ihr Unternehmen zu nachhaltigen Einnahmequellen zu führen. Nachrichten über Ihre Produkte müssen das Vertrauen eines potenziellen Käufers genug wecken, um die erforderlichen Maßnahmen zu ergreifen, um das Geschäft abzuschließen. Sie haben ein gewisses Maß an Kontrolle darüber, was im Knowledge Graph Ihres Unternehmens angezeigt wird. „Es steht viel auf dem Spiel, denn die International Data Corporation schätzt, dass die weltweiten Unternehmensinvestitionen in D&A bis 2020 200 Milliarden US-Dollar pro Jahr übersteigen werden“, so Harvard Business Review.
„Eine robuste, erfolgreiche D&A-Funktion (Data and Analytics) umfasst mehr als einen Stapel von Technologien oder ein paar Personen, die isoliert auf einer Etage des Gebäudes sitzen. D&A sollte der Puls der Organisation sein und in alle wichtigen Entscheidungen über Vertrieb, Marketing, Lieferkette, Kundenerlebnis und andere Kernfunktionen einbezogen werden.“ – Harvard Business Review
Produktbilder können Teil eines Google-Bilddatensatzes sein! In einigen Datensätzen gibt es durchschnittlich 8,4 Objekte pro Bild. Hier ist eine Datensatzliste, die häufig aktualisiert wird.
Die Dokumentationsseite von Google enthält ein JSON-LD-Beispiel für die Implementierung von schema.org/Dataset. Da sich der röhrenförmige Datensatz in der Beta-Phase befindet, werden sich Best Practices für die Beschreibung und Verwendung von Datensätzen herausbilden. Wenn sich die Codeanforderungen ändern, führen Sie ein technisches SEO-Audit durch, um festzustellen, wo Aktualisierungen erforderlich sind.
Wie lade ich Produkt- und Bilddatensätze in Google BigQuery hoch?
Google BigQuery (GBQ) ermöglicht es Suchmaschinenvermarktern, Daten aus verschiedenen Quellen zu sammeln. Wir empfehlen die Verwendung von Google Merchant Center, Cloud Storage, BigQuery oder Sie können die Daten bei der Anfrage inline angeben. Erstellen Sie vor dem Hochladen von Daten zunächst einen Datensatz und eine Tabelle in Google BigQuery, die Ihre Produktinformationen einschließlich Bilddetails enthalten. ***
Wir bevorzugen das JSON-LD-Datenformat für Produktartikel. Hier ist ein Beispiel für ein vollständiges Objekt:
{
"name": "projects/[PROJECT_NUMBER]/locations/global/catalogs/default_catalog/branches/0/products/1234",
"id": "1234",
"categories": "Apparel & Accessories > Shoes",
"title": "ABC sneakers",
"description": "Sneakers for the rest of us",
"attributes": { "vendor": {"text": ["vendor123", "vendor456"]} },
"language_code": "en",
"tags": [ "black-friday" ],
"priceInfo": {"currencyCode": "USD", "price":100, "originalPrice":200, "cost": 50},
"availableTime": "2020-01-01T03:33:33.000001Z",
"availableQuantity": "1",
"uri":"http://foobar",
"images": [{"uri": "http://foobar/img1", "height": 320, "width": 320 }]
}
Halten Sie Ihren Produktkatalog auf dem neuesten Stand. Google kümmert sich um Qualität, und seine künstliche Intelligenz benötigt hochwertige Daten, um qualitativ hochwertige Vorhersagen treffen zu können. Achten Sie auf Produkte, die nicht mehr zum Verkauf stehen, und halten Sie die Daten im E-Commerce-Produktschema-Markup Ihrer Website auf dem neuesten Stand.
„Ein tabellarischer Datensatz ist hauptsächlich in Form eines Rasters aus Zeilen und Spalten organisiert. Für Seiten, die tabellarische Datensätze einbetten, können Sie auch ein expliziteres Markup erstellen, das auf dem oben beschriebenen grundlegenden Ansatz aufbaut. Wir verstehen derzeit eine Variante von CSVW („CSV on the Web“, siehe W3C), die parallel zu nutzerorientierten tabellarischen Inhalten auf der HTML-Seite bereitgestellt wird“, heißt es am 30.09.2019.
Bleiben Sie auf der Dokumentationsseite von Google auf dem Laufenden, um Updates zu erhalten, falls sich die für Dataset, DataCatalog oder DataDownload aufgeführten Eigenschaften ändern. Die aktuelle Dokumentation hat den organisatorischen Aspekt aktualisiert; Eigenschaftsspezifikationen sind jetzt unter dem Typ konsolidiert, zu dem sie gehören (früher waren sie thematisch organisiert). Diese neuen Eigenschaften sind eine Möglichkeit, Ihre Website-Attribute zu verbessern.
So erstellen Sie einen Datensatz aus Bildern für die Objektklassifizierung.
Wählen Sie in der IBM Cluster-Verwaltungskonsole (1) Workload, (2) Spark und dann (3) Deep Learning aus. **
* Klicken Sie auf die Registerkarte „Datensätze“.
* Wählen Sie „Neu“.
* Erstellen Sie einen Datensatz aus „Bilder zur Objektklassifizierung“.
* Geben Sie einen Datensatznamen ein.
* Geben Sie an, welche Spark-Instanzgruppe Sie möchten.
* Geben Sie Ihr bevorzugtes Bildspeicherformat an (wir bevorzugen TFRecords für TensorFlow).
* Wenn TFRecords ausgewählt wurde, navigieren Sie zum Generieren von Datensätzen, entweder nach Shard oder Klasse. Wenn Shard ausgewählt ist, geben Sie die Shard-Nummer ein.
* Geben Sie an, wie Trainingsbilder ausgewählt werden.
Durch die Einhaltung der Google-Bildrichtlinien und AMP-Bildanforderungen haben Ihre Produkte eine bessere Chance, in produktbezogenen Featured Snippets zu erscheinen.
Eigenschaften strukturierter Dataset-Daten
Wirklich, es gibt derzeit nur wenige erforderliche Eigenschaften. Um seine Nutzung zu fördern, verfolgt der Technologieriese möglicherweise eine „Keep it simple“-Strategie, wenn es darum geht, Inhalte bereitzustellen, die für Verbraucher von Maschinendaten bestimmt sind. Das Endziel ist es, mehr und bessere Übereinstimmungen in der Datenbibliothek zu haben, um die Suchabsicht der Benutzer zu erfüllen.
Erforderliche Eigenschaften:
- Name
- Beschreibung
Empfohlene Eigenschaften:
- anderer Name
- Schöpfer
- Zitat
- Kennung
- Schlüsselwörter
- Lizenz
- gleich wie
- räumlicheAbdeckung
- zeitliche Abdeckung
- VariableGemessen
- Ausführung
- URL
Möglicherweise haben Sie noch keinen veröffentlichten Datensatz im Web, aber das Suchmaschinenmarketing bewegt sich schnell in Richtung eines datenwissenschaftlichen Ansatzes für die Suche. Da Einzelpersonen und Personen immer mehr Datensätze zugänglich machen, wird die Datensatzsuche zunehmen. Überraschend ist, dass jeder , der Daten veröffentlicht, seinen Datensatz mithilfe des offenen Standards von schema.org zur Beschreibung von Informationen beschreiben kann.
Lesen Sie beim Testen Ihrer Daten im Indexbericht der Search Console den Abschnitt "Bekannte Fehler und Warnungen", die "Fehler oder Warnungen im Testtool für strukturierte Daten von Google und das Validierungssystem für strukturierte Daten Linter". Beauftragen Sie einen Experten für die Schemadatenimplementierung oder verwenden Sie die Formulare, um herauszufinden, welche Warnungen Sie bedenkenlos ruhen lassen können.
Da es sich um das Parsen von Webinhalten handelt – unabhängig davon, ob diese bereits strukturierte Daten enthalten – ist es am besten, die Daten in einem Format bereitzustellen, das der größte Prozentsatz der Datenkonsumenten (vor allem Suchmaschinen) versteht.
Datensätze bieten eine Roadmap zum Erstellen von Knowledge Graphs
Finden Sie Datensätze und nutzen Sie die akademische Suche aus offenen Datenquellen und https schema.org.
Forscher schätzen Klarheit bei der punktgenauen Analyse von Lösungen für globale Datenwissenschaft und maschinelles Lernen, die die Marktdynamik aufzeigen. Suchmaschinenvermarkter mit dem Bestreben, nachhaltige Marketingtrends zu messen, verlassen sich auf Big Data, um das zukünftige Marktwachstum zu unterstützen. Sobald die Google-Datensatzsuche aus der Betaphase herauskommt, verfügt sie möglicherweise über neue Funktionen zur Durchführung von Datenrecherchen, die die aktuellen Risiken und Herausforderungen für Unternehmen verringern können. Umfangreiche Recherchen zu den Details in Ihren Daten können Ihre Verkaufsansätze verbessern.
Wir suchen weiterhin nach praktischen Ansätzen zum Erstellen von Kundenwissensgraphen und nach Möglichkeiten, sie für Geschäftsanwendungen zu nutzen. Versuchen Sie sich daran.
Sobald Sie das Datensatzschema auf Ihrer Website verwendet haben, finden Sie in Ihrem GSC unter Erweiterungen einen neuen Bericht. Wir verwenden sie, um unsere Marketingstrategie für mobile Inhalte für Benutzer zu verbessern, die von mehreren Geräten kommen.
Datensatzfunktionen und neuer Google-Verbesserungsbericht
Wie bei anderen strukturierten Datenimplementierungen sind Sie berechtigt , nur weil Sie schemastrukturierte Daten integriert haben. Es garantiert jedoch nicht, dass es in der Google-Suche erscheint. Priorisieren Sie die Verwendung von Datensätzen, die den Verkauf und Ihre Einzelhandels-Landingpages unterstützen.
Gleichzeitig mit der Ankündigung der Funktion für strukturierte Daten erschien ein neuer Datensatzverbesserungsbericht in der Google Search Console. Dies informiert Suchmaschinenmarketing-Strategen darüber, ob Google Ihre strukturierten Daten für Ihr Datensatzschema gelernt hat und erkennt. Lesen Sie alle strukturierten Datenfehler durch und beheben Sie sie, sobald Sie die Dokumentationsspezifikationen für Datensätze mit strukturierten Daten verstanden haben. Es wird Ihre Google Assistant-Daten füttern.
Nur wenige Geschäftsinhaber oder Ersteller von Inhalten haben Zeit, um darüber nachzudenken, ob Ihre Metadaten richtig formatiert sind. Es muss jedoch sein, damit der GoogleBot Ihre Website crawlen, Ihre Daten finden und indizieren kann. Glücklicherweise lieben wir es und sind in Ihrer Ecke.
Dataset-Build-Berechtigungen
Die Build-Berechtigung ist für Datasets relevant. Wenn Benutzern die Build-Berechtigung erteilt wird, können sie neue Inhalte auf einem vorhandenen Dataset erstellen. Dies ist üblich für Berichte, Dashboards, angeheftete Kacheln von QandA und Insights Discovery. Sie können auch außerhalb von Power BI neue Dateneinträge im Dataset erstellen, typischerweise Excel-Tabellen über In Excel analysieren, XMLA, und zugrunde liegende Daten exportieren. Es hilft Unternehmen bei der Durchführung von Kundenanalysen.
So neu und umfassend Deep Learning auch ist, Google und andere Suchmaschinen stehen immer noch vor Herausforderungen beim Datenmanagement, die im Zusammenhang mit in der Produktion eingesetzten Pipelines für maschinelles Lernen auftauchen. Neue Bemühungen zum Verständnis semantischer Suchanfragen sollen das Verstehen, Validieren, Bereinigen und Anreichern von Trainingsdaten unterstützen. Dadurch wird sich das Wachstum vertrauenswürdiger Datenbankquellen hoffentlich ausweiten und nützlicher sein, um den Ladenverkehr zu steigern.
Digitales Marketing ist an die Notwendigkeit von Daten und deren Nutzung als wissenschaftlicher Ansatz gebunden.
„Ein Suchtool wie dieses ist nur so gut wie die Metadaten, die Datenherausgeber bereit sind bereitzustellen. Wir hoffen, dass viele von Ihnen die offenen Standards verwenden, um Ihre Daten zu beschreiben, damit unsere Benutzer die gesuchten Daten finden können. Wenn Sie Daten veröffentlichen und sie nicht in den Ergebnissen sehen, besuchen Sie unsere Anweisungen auf unserer Entwicklerseite, die auch einen Link enthält, um Fragen zu stellen und Feedback zu geben.“ - Google *
„Wir können strukturierte Daten auf Webseiten über Datensätze verstehen, indem wir entweder http://schema.org Dataset Markup oder äquivalente Strukturen verwenden, die im Data Catalog Vocabulary (DCAT)-Format des W3C dargestellt werden.“ – Kommentar von Alan Morrison auf Twitter
Zusammenfassung des Google Dataset-Schemas
Die Verwendung von Datensätzen zur Erfüllung der Bedürfnisse der Website-Benutzer konzentriert sich mehr auf die Benutzererfahrung und das Hinzufügen von Entitäten, die antworten und informieren. Obwohl es aus der Data-Science-Community stammen mag, kann es von jedem Unternehmen verwendet werden. Wir empfehlen außerdem, von Experten begutachtete Beiträge von hochrangigen Experten einzuholen, die Erfahrung im Markup von strukturierten Daten für Datensätze haben.
Hill Web Marketing möchte gerne an dieser Initiative teilnehmen und hofft, dass es unsere Leser ermutigt, die Anzahl der derzeit verfügbaren Datensätze zu erweitern. Obwohl es aus der Data-Science-Community stammen mag, kann es von jedem Unternehmen verwendet werden.
Rufen Sie Jeannie Hill, Inhaberin von Hill Web Marketing, eine Strategin für digitales Marketing, als Partner an: 651-206-2410. Planen Sie Ihre Beratung, um einen Wettbewerbsvorteil zu erlangen
* https://arxiv.org/pdf/1908.07442.pdf
** https://www.ibm.com/support/knowledgecenter/SSWQ2D_1.1.0/us/create-dataset-image-object-classification.html
*** https://cloud.google.com/retail/recommendations-ai/docs/upload-catalog
**** https://www.blog.google/products/search/making-it-easier-discover-datasets/
***** https://storage.googleapis.com/pub-tools-public-publication-data/pdf/40761.pdf