
Google Dataset Search for DatasetSchemaの使用方法
公開: 2019-10-01Google Dataset Search:クエリにデータセットスキーマを使用する方法
12.6.2021を更新
デジタルデータの量が増えるにつれ、検索マーケティングストラテジストは、データを理解する必要性が高まっています。
多くの高度なデータベースアプリケーションがGoogleデータベース検索をサポートし始めています。 また、SEOのデータをよりよく理解するために、2019年9月に新しいレポートがGoogle検索コンソールに追加されました。 オントロジーとしてエンコードされたドメインレベルの知識をリレーショナルデータのクエリに組み込むことで、多くのことが得られます。 SEOについて多くのことが語られているため、検索マーケターは、事実をフィクションからふるいにかけること、有用なSEO戦術から有害なこと、そしてテスト済みであることに気づきます。
過去の検索マーケティングの経験と直感に大きく依存することは素晴らしいことですが、あまりにも頻繁に間違っています。 データに影響された決定は、「私の腸が私にそう言った」よりも一貫して優れていることが証明されています。 Google Analyticsのような多くのデータインサイトツールは実際の裏付けとなる証拠を提供しますが、GoogleCloudパブリックデータセットの検索がこれまでになく簡単になりました。
Google Dataset Searchとは何ですか?
簡単に言えば、Google Data Searchは、大小を問わずデータセットプロバイダーに依存しており、オープンなschema.org/Dataset標準を使用してウェブサイト内に構造化メタデータを追加しています。 Google Dataset Searchを使用すると、検索者は特定の検索フレーズを使用した検索を通じて、ウェブ全体に保存されているデータセットを見つけることができます。 Googleによると、このツールはWeb全体の何千ものリポジトリでホストされているデータセットに関する情報を表示し、これらのデータセットをどこからでもアクセスできて便利なものにします。
ビジネスのニッチに関連する需要の高いパブリックデータセットにアクセスすることで、クラウドデータから新しい消費者の洞察を明らかにすることができます。 BigQueryとCloudStorageでホストされている追加のデータセットを分析することで、GoogleCloudの価値を最大限に体験することが容易になります。
データジャーナリストは、政府のデータと社会科学のデータセットの取得にすでに精通しています。 この記事は、ベースラインを確立し、デジタルの進捗状況を測定し、最新のGoogleスキーママークアップの機会を利用するためのデータ駆動型フレームワークを設定するのに役立ちます。
Googleのデータセット検索は、学者が必要なデータを見つけるのを支援する目的でGoogleが立ち上げた検索エンジンの一種として認識されています。 検索マーケターは、データセットをさらに活用することに注目しています。
データセットはデータインテリジェンスと複雑なオントロジーを簡素化しますか?
はい。 プロバイダーの名前、説明、作成者、配布形式などのサポート情報が構造化データでマークアップされている場合、データセットを簡単に見つけることができます。 Googleは、データセットを表すWebコンテンツに追加できるschema.orgやその他のメタデータ標準を通じてデータセットの検出を容易にします。
Googleがライブラリインデックスを作成すると、ユーザーのクエリへの回答を開始します。そして、どの結果が各人のクエリに最もよく対応するかを判断します。
「リレーショナルSQLクエリ言語またはその拡張機能でグラフ構造のオントロジーに対してクエリを表現することは非常に困難です。 さらに、特にデータとそれに関連するオントロジーが複雑な場合、セマンティッククエリは通常正確ではありません。」
ユーザーはオントロジー表現を知る必要さえありません。 必要なのは、ユーザーが念頭に置いているクエリを満たすいくつかの例を示すことだけです。 次に、 Googleのシステムはクエリに対する答えを自動的に見つけます。 このプロセスでは、通常は表現が難しい概念であるセマンティクスが、クエリ言語で明示的に表現されることなく、ユーザーの心の中にある概念として残ります。 – Googleホワイトペーパー:例によるセマンティッククエリ*****
これはチャンスをもたらします。 大規模なデータセットで事前にトレーニングされたモデルは、自然言語処理を構築するすべての人が利用できます。 読解から感情分析、BERTまで。 重要な研究動向は、NLPでの転移学習の台頭です。
検索マーケティング担当者の役割の進化は、データを消化する必要性が高まるにつれて、より複雑になっています。 独自のデータセットを作成することは、学術文献に頼ることができるポジティブなSEOの一形態です。 画像データをより広いレベルで適用する方法を再考することから始めることができます。 これは、リンクグラフおよびWebリンクネットワーク内の短いパスを決定するためのスケーラブルなシステムを支援します。 サイトのリンクマップを再クロールして再計算するときに、Googleを支援する可能性があります。
「たとえば、科学、学術、または政府の「オープンデータ」リポジトリで公開されているパッケージデータのコレクションを説明する場合、コレクション全体を示すDataCatalog、およびデータセットの特定の表現を示すDataDownloadとともに、Datasetタイプを使用できます。」 –データとデータセット– schema.org
データセットスキーマを追加する手順
- まず、データセットのドキュメントマークアップを読んで、単一のDCATファイルではなくドメインに追加する方法を学びます。
- 次に、Googleが推奨するJSON-LDマークアップ形式で構造化データスニペットのコレクションに追加します。 Datasetタイプのスキーマを使用します。
- Google構造化データテストツールを使用して、データセットの実装をテストします。
- 最後に、データセットページのクロールを開始するようにGooglebotに指示するサイトマップでURLを送信します。
注:GoogleはDCAT形式のマークアップを受け入れます。 Googleのデータセットスキーマは、いくつかの組織化された情報を説明する構造化された情報の本体を表示することを目的としています。 JSON構造化データを本文または先頭に挿入するために機能します。
JSON-LDコードとスキーマ語彙を使用したGoogleデータセット
Googleデータセット検索エンジンとは何ですか?
Google Dataset Search Engineは、ユーザーがGoogleを利用して、ソースとして公開されているオンラインデータを見つけようとする場合です。 Google Dataset Searchは、企業の学術研究、研究、レポート用の検索エンジンであるGoogleScholarと連携することを目的としています。
Googleのデータセットドキュメントページへの最近の変更により、Google検索の豊富な結果で、ウェブマスター、SEO、およびパブリッシャーへのデータセット構造化データのロールアウトへの道が更新されます。 Schema.orgを使用する一般的な方法とは異なり、データセットスキーマは任意の形式にすることも、集合体統計を表すこともできます。
アーロンは、グーグルがスター付きの通知に足のアイコンを落としたと説明し、「データセットの豊富な結果の展開が差し迫っていることを示唆している」と述べた。
データセットをスキーマでマークアップする必要があるのはなぜですか?
理想的な顧客体験は、しばしばとらえどころのないものに感じることがあります。 カスタマージャーニーをマッピングし、デジタルデータ文字列の山を並べ替えるのは簡単ではありません。 適切な顧客に適切なオファーを提供するだけでは不十分です。 それは購入時間、デジタルチャネル、過去のオファーからのデータ収集、そして時にはそれ以上から始まります。 データ管理は、戦術的なメディア購入の考え方から、ブランドの信頼を構築する企業の顧客体験の中心にある適切な戦略的洞察を実装する方法に移行しました。
あなたのコンテンツをよりよく理解し、一致させ、答えや解決策に使用することができます。 データセットスキーマは、機械学習アプローチを利用して、リレーショナルデータベースのセマンティッククエリを処理します。 セマンティッククエリ処理における最大のハードルは、リレーショナルデータベースエンジンがデータの操作と一致する方法でオントロジーを操作できるように、リレーショナル形式で正確なオントロジーデータを提供することです。
スキーマでマークアップされたデータセットは、他の人が解釈しやすく、検索エンジンがデータをよりよく理解するのに役立ちます。 これは、彼らがその理解をデータの視覚的なイラストに変換するのに役立ちます。
Googleによると、データセットは次のような場合に使用できます。
- いくつかのデータを含むテーブルまたはCSVファイル
- テーブルの整理されたコレクション
- データを含む独自の形式のファイル
- 一緒にいくつかの意味のあるデータセットを構成するファイルのコレクション
- 処理のために特別なツールにロードしたい他の形式のデータを含む構造化オブジェクト
- データをキャプチャする画像
- トレーニングされたパラメータやニューラルネットワーク構造の定義など、機械学習に関連するファイル
- あなたにとってデータセットのように見えるものは何でも
いくつかの巨大なデータセットが見つかりました。 シンプルに保つのが最善です。 Googleでは、「すべてのテキストプロパティを5000文字以下に制限することをお勧めします。 Google Dataset Searchは、テキストプロパティの最初の5000文字のみを使用します。 名前とタイトルは通常、数語または短い文です。」
安全で信頼性の高いリレーショナルデータベースを使用してデータを最新化する方法
リレーショナルデータベースは、データを収集してテーブルと列に格納し、データ間の関係を整理して強調します。 リレーショナルデータベースは、構造化され接続されたデータを対象としています。 Webopediaは、リレーショナルデータベースを「データの1つのインスタンスが編集または変更された場合にデータを自動的に更新するように設定できる」と定義しています。 他の関連データはリアルタイムの更新を受け取ります。 人々はしばしばリレーショナルデータベースとリレーショナルデータベース管理システム(RDBMS)を同じ意味で使用します。
これにより、企業は最新のアーキテクチャを使用してデータソリューションを構築し、ビジネスのスマートな洞察をリアルタイムで取得して、ユーザーの意図をより適切に満たすことができます。
表からテキストへのモデルは、構造化データからテキスト情報を抽出します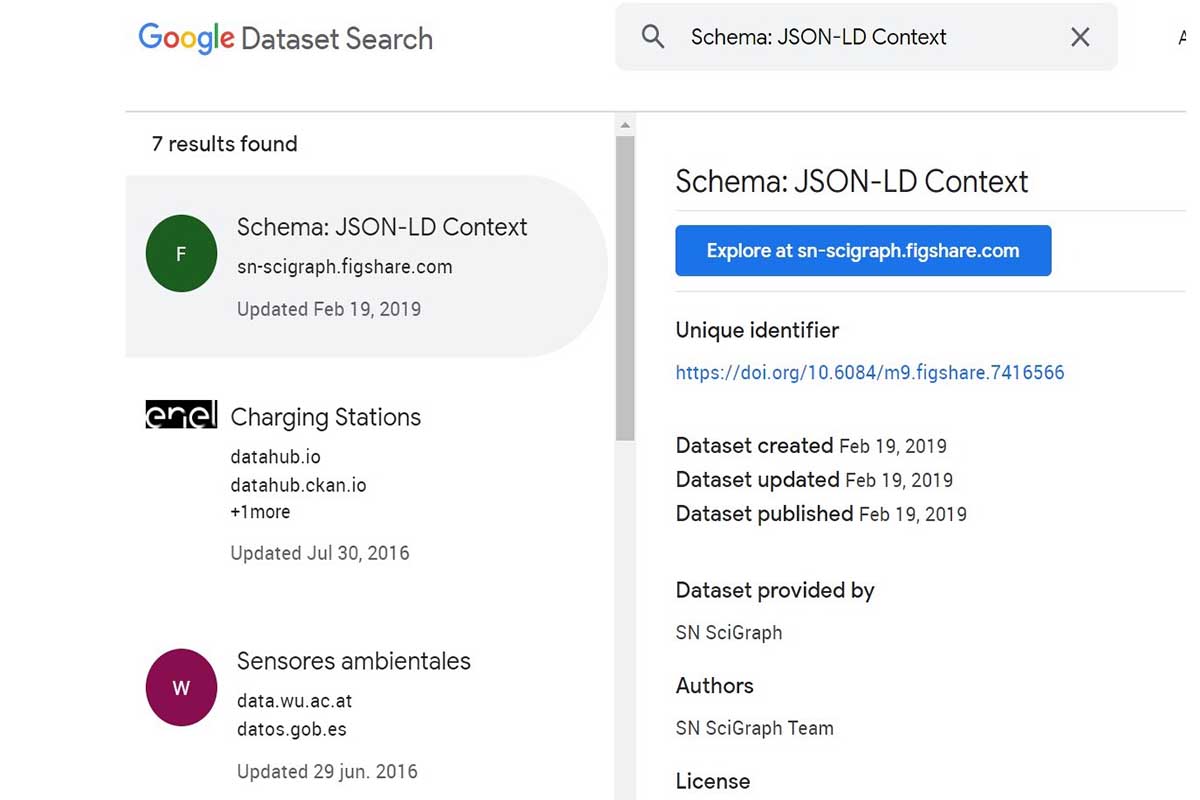
データ駆動型で人に焦点を当てる
フィールドレベルのデータ抽出のシーケンシャルメカニズムを取得すると、包括的な入力フィーチャを評価する最終的な分類または回帰タスクを実行し、それらを代替データタイプにマッピングするのに役立ちます。
Googleのデータセットレポートは、検索の意図を一致させることについての思考を強化するために学習を支援することができます。 オンラインデータライブラリを検索して必要なものを見つけるか、データサイエンティストを雇ってください。 データセットが豊富な結果は、生データを意味のある洞察にエンコードすることを合理化するのに役立つ迅速な研究開発ワークフローに役立ちます。 これらは、データへの構造化されたアプローチを作成するのに役立ちます。 企業は、意思決定プロセスを合理化し、より高いパフォーマンス結果をより早く生み出すことで利益を得ることができます。
「研究開発の急速な進歩を可能にする主な要因の1つは、生データを意味のある表現に効率的にエンコードするための標準的なニューラルネットワークアーキテクチャの可用性です。 単純な意思決定レイヤーと統合されたこれらの標準的なアーキテクチャは、通常、わずかな追加の調整作業で、新しいデータセットおよび関連タスクで高いパフォーマンスを実現します。」 – Google CloudAIでの注意深い解釈可能な表形式の学習
Google Dataset Search Betaで何が変更されましたか? 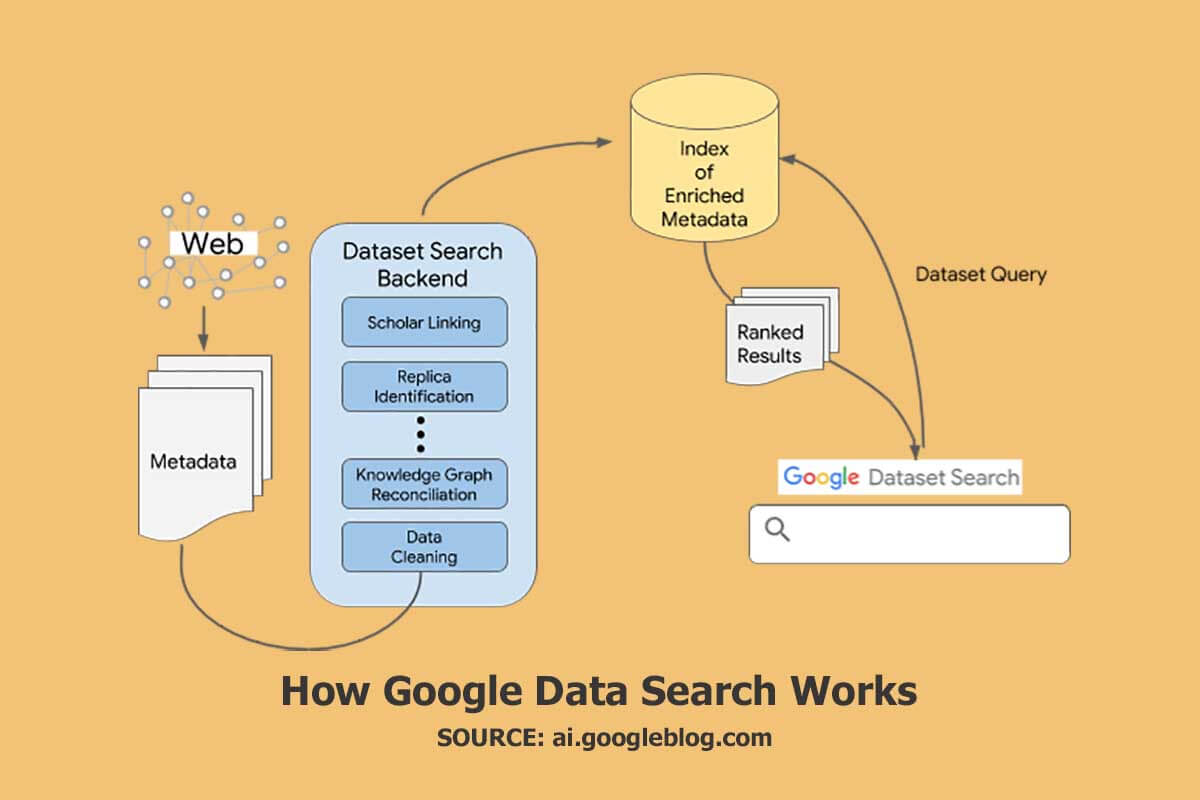
以前、Googleドキュメントには、「データセットマークアップは、一般提供にリリースされる前に試すことができます」と記載されており、構造化データテストツールを検証に使用することはできますが、「使用しない」と警告されていました。ただし、データセットが検索に表示されることを確認してください。」 これが展開されるのを待っていた人にとって、データセット構造化データをサイトに追加すると、モバイルの課題とプロパティの仕様を測定するのに役立ちます。 Google Dataset Searchは、学術研究や事実に基づくレポートを提供するテクノロジー企業の検索エンジンであるGoogleScholarをサポートしています。
2020年1月23日、GoogleのNatasha Noyは、次のように述べています。 過去1年間、人々はそれを試し、フィードバックを提供してきましたが、現在、データセット検索は正式にベータ版ではありません。」
Web記事で数百万のデータセットを発見すると、世界中のほとんどの政府がデータを公開し、schema.orgでマークアップすることがわかります。 「米国は、利用可能なオープンガバメントデータセットの数でリードしており、200万を超えています。」
これは、市場調査担当者がデジタルヒストリーでこれまで以上にデータにアクセスできることを意味します。
データセットはサイトのすべてのコンテンツを管理できます
クリーンで有用なデータの収集が行われると、多くの時間が必要になりますが、サイト上のすべてのコンテンツをサポートおよび管理するのに役立ちます。
より現実的なデータセットを使用したさまざまな機械学習タスクを使用して、より事実に基づいた情報を得る方法を学ぶことができます。 Hill Web Marketingは、ビジネスKPIごとに、重要なメトリックを理解し、スキーマを使用してそれらを業界の目標に合わせる方法を理解し、パフォーマンスを向上させる方法をプロットするのに役立ちます。
GoogleAIのリサーチサイエンティストであるNatashaNoyは、2018年9月5日にデータセットの発見を容易にすることを発表し、「データセット検索は複数の言語で機能し、追加の言語も間もなくサポートされる」と述べています。****明らかにこれはウェブが進む方向。 必須のタイプのスキーママークアップを実装すると、ビジネスを見つけるのに役立ちます。
データセットを使用すると、製品の収益ストリームを確保できます
Googleデータセット検索はどのように機能しますか?
データセットは、名前、説明、作成者、配布形式などの情報を構造化データとして提供すると、簡単に見つけることができます。 Googleはデータセットの検出を強化しており、データセットを説明するWebページに組み込むことができるschema.orgやその他のデータ形式を利用しています。 このスキーマは、製品カルーセルの検索結果に表示される可能性をサポートできます。

ビジネスの将来の成功は、組織を持続的な収益源に向けて推進するために必要な洞察にかかっています。 あなたの製品についてのメッセージは、取引を成立させるために必要な行動をとるのに十分な見込みのある買い手の自信を刺激する必要があります。 会社の知識グラフに表示される内容をある程度制御できます。 Harvard Business Reviewによると、「International Data Corporationは、D&Aへのグローバルな事業投資が2020年までに年間2,000億ドルを超えると予測しており、そのリスクは高いです」と述べています。
「堅牢で成功したD&A(データおよび分析)機能には、テクノロジーのスタック以上のもの、または建物の1つのフロアに孤立した数人の人々が含まれます。 D&Aは組織の鼓動であり、販売、マーケティング、サプライチェーン、カスタマーエクスペリエンス、およびその他のコア機能にわたるすべての重要な決定に組み込まれる必要があります。」 - ハーバードビジネスレビュー
商品画像はGoogle画像データセットの一部にすることができます。 一部のデータセットでは、画像ごとに平均8.4個のオブジェクトがあります。 これは頻繁に更新されるデータセットリストです。
Googleのドキュメントページには、schema.org / Datasetを実装するためのJSON-LDの例が含まれています。 管状データセットはベータ版であるため、データセットの説明と使用に関するベストプラクティスが明らかになります。 コード要件が変更されたら、技術的なSEO監査を実施して、更新が必要な場所を見つけます。
商品と画像のデータセットをGoogleBigQueryにアップロードするにはどうすればよいですか?
Google BigQuery(GBQ)を使用すると、検索マーケターはさまざまなソースからデータを収集できます。 Google Merchant Center、Cloud Storage、BigQueryを使用することをお勧めします。または、リクエストを行うときにデータをインラインで指定することもできます。 データをアップロードする前に、まずGoogle BigQueryでデータセットとテーブルを作成します。このデータセットとテーブルには、画像の詳細などの商品情報が含まれています。 ***
製品アイテムのJSON-LDデータ形式を使用することをお勧めします。 完全なオブジェクトの例を次に示します。
{
"name": "projects/[PROJECT_NUMBER]/locations/global/catalogs/default_catalog/branches/0/products/1234",
"id": "1234",
"categories": "Apparel & Accessories > Shoes",
"title": "ABC sneakers",
"description": "Sneakers for the rest of us",
"attributes": { "vendor": {"text": ["vendor123", "vendor456"]} },
"language_code": "en",
"tags": [ "black-friday" ],
"priceInfo": {"currencyCode": "USD", "price":100, "originalPrice":200, "cost": 50},
"availableTime": "2020-01-01T03:33:33.000001Z",
"availableQuantity": "1",
"uri":"http://foobar",
"images": [{"uri": "http://foobar/img1", "height": 320, "width": 320 }]
}
製品カタログを最新の状態に保ちます。 Googleは品質に関心があり、その人工知能は高品質の予測を行うために高品質のデータを必要とします。 販売されなくなった製品を監視し、サイトのeコマース製品スキーママークアップでデータを最新の状態に保ちます。
「表形式のデータセットは、主に行と列のグリッドの観点から編成されたデータセットです。 表形式のデータセットを埋め込んだページの場合、上記の基本的なアプローチに基づいて、より明示的なマークアップを作成することもできます。 現時点では、CSVW(「CSVon the Web」、W3Cを参照)のバリエーションを理解しています。これは、HTMLページのユーザー指向の表形式のコンテンツと並行して提供されます。」と記載されています。2019年9月30日現在。
Dataset、DataCatalog、またはDataDownloadにリストされているプロパティが変更された場合の更新については、Googleのドキュメントページにご注目ください。 現在のドキュメントは組織的な側面を更新しました。 プロパティ仕様は、それぞれが属するタイプに統合されました(以前はテーマ別に編成されていました)。 これらの新しいプロパティは、Webサイトの属性を強化する1つの方法です。
オブジェクト分類のために画像からデータセットを作成する方法。
IBMクラスター管理コンソール内で、(1)ワークロード、(2)Spark、(3)ディープラーニングの順に選択します。 ****
*「データセット」タブをクリックします。
※「新規」を選択してください。
*「オブジェクト分類用の画像」からデータセットを作成します。
*データセット名を入力します。
*必要なSparkインスタンスグループを指定します。
*ご希望の画像保存形式を指定してください(TensorFlowにはTFRecordsをお勧めします)。
* TFRecordsが選択された場合は、シャードまたはクラスのいずれかによってレコードを生成する方法に移動します。 シャードを選択した場合は、シャード番号を入力します。
*トレーニング画像の選択方法を指定します。
Google画像ガイドラインとAMP画像の要件を順守することで、商品が商品関連の注目スニペットに表示される可能性が高くなります。
データセットの構造化データのプロパティ
実際、現時点で必要なプロパティはほとんどありません。 テクノロジーの巨人は、その使用を促進するために、マシンデータの消費者向けのコンテンツを提供することに関して、「シンプルに保つ」戦略を採用している可能性があります。 最終的な目標は、ユーザーの検索意図を満たすために、データライブラリにますます多くの一致を持たせることです。
必要なプロパティ:
- 名前
- descritiopn
推奨されるプロパティ:
- 代替名
- クリエーター
- 引用
- 識別子
- キーワード
- ライセンス
- と同じ
- SpatialCoverage
- 一時的なカバレッジ
- variableMeasured
- バージョン
- url
ウェブ上にまだ公開されたデータセットを持っていないかもしれませんが、検索マーケティングは急速に検索へのデータサイエンスアプローチに移行しています。 個人や人々がますます多くのデータセットにアクセスできるようになるにつれて、データセット検索は増加します。 驚くべきことは、データを公開する人は誰でも、情報を記述するためのschema.orgのオープンスタンダードを使用してデータセットを記述することができるということです。
検索コンソールのインデックスレポートでデータをテストするときは、「既知のエラーと警告」セクション、「Googleの構造化データテストツールのエラーまたは警告、および構造化データリンター検証システム」をお読みください。 スキーマデータ実装の専門家を雇うか、フォームを使用して、安全に休ませることができる警告をふるいにかけます。
これはWebコンテンツの解析に関連しているため、構造化データが既に含まれているかどうかに関係なく、データコンシューマー(ほとんどの場合、検索エンジン)の最も高い割合が理解できる形式でデータを利用できるようにするのが最善です。
データセットは、知識グラフを構築するためのロードマップを提供します
検索データセットを検索し、オープンデータソースとhttpsschema.orgからの学術検索を活用します。
研究者は、市場のダイナミクスを明らかにするグローバルデータサイエンスおよび機械学習ソリューションのピンポイント分析の明確さを高く評価しています。 持続可能なマーケティングトレンドを測定するための探求をしている検索マーケターは、将来の市場成長をサポートするためにビッグデータに依存しています。 Google Dataset Searchのベータ版が終了すると、データ調査を実施するための新しい機能が追加され、ビジネスの前にある現在のリスクと課題を軽減できる可能性があります。 データの詳細に関する広範な調査により、販売アプローチを改善できます。
私たちは、クライアントの知識グラフを構築するための実用的なアプローチと、それらをビジネスアプリケーションに活用する機会を引き続き模索しています。 これであなたの手を試してみてください。
サイトでデータセットスキーマを使用すると、GSCの拡張機能の下に新しいレポートが表示されます。 これらを使用して、複数のデバイスからアクセスするユーザー向けのモバイルコンテンツマーケティング戦略を改善します。
データセットの機能と新しいGoogle拡張レポート
他の構造化データの実装の場合と同様に、スキーマ構造化データを組み込んだという理由だけで、資格が得られます。 ただし、Google検索に表示されることを保証するものではありません。 販売と小売のランディングページをサポートするデータセットの使用を優先します。
構造化データ機能の発表と同時に、Google検索コンソールに新しいデータセット拡張レポートが表示されました。 これは、Googleがデータセットスキーマの構造化データを学習して認識したかどうかについて、検索マーケティングストラテジストに通知します。 データセットの構造化データのドキュメントの仕様を理解したら、構造化データのエラーを読み、修正してください。 Googleアシスタントのデータをフィードします。
メタデータが正しくフォーマットされているかどうかを考える時間があるビジネスオーナーやコンテンツクリエーターはほとんどいません。 それでも、GoogleBotがサイトをクロールし、データを見つけてインデックスを作成できるようにする必要があります。 幸いなことに、私たちはそれが大好きで、あなたの隅にいます。
データセットビルドのアクセス許可
ビルド権限はデータセットに関連しています。 ユーザーにビルド権限が付与されると、既存のデータセットに新しいコンテンツをビルドできます。 これは、レポート、ダッシュボード、QandAの固定タイル、およびInsightsDiscoveryで一般的です。 また、Power BIの外部のデータセット(通常はExcel、XMLAでの分析を介したExcelシート)に新しいデータエントリを作成し、基になるデータをエクスポートすることもできます。 これは、企業が顧客分析を行うのに役立ちます。
ディープラーニングと同様に新しく包括的なものですが、Googleやその他の検索エンジンは、本番環境に導入された機械学習パイプラインのコンテキストで表面化するデータ管理の課題に依然として直面しています。 セマンティック検索クエリを理解するための新しい取り組みは、トレーニングデータの理解、検証、クリーニング、および強化をサポートすることを目的としています。 このことから、信頼できるデータベースソースの成長が拡大し、店舗のトラフィックを促進するのに役立つことを願っています。
デジタルマーケティングは、データの必要性と科学的アプローチとしてのデータの使用に縛られています。
「このような検索ツールは、データ発行者が喜んで提供するメタデータと同じくらい優れています。 多くの皆さんがオープンスタンダードを使用してデータを記述し、ユーザーが探しているデータを見つけられるようになることを願っています。 データを公開しても結果に表示されない場合は、開発者サイトの手順にアクセスしてください。このサイトには、質問をしたりフィードバックを提供したりするためのリンクも含まれています。」 - グーグル *
「http://schema.orgデータセットマークアップ、またはW3Cのデータカタログ語彙(DCAT)形式で表される同等の構造を使用して、データセットに関するWebページの構造化データを理解できます。」 –TwitterでのAlanMorrisonのコメント
Googleデータセットスキーマの概要
データセットを使用してサイトユーザーのニーズに対応することは、ユーザーエクスペリエンスと、回答および通知するエンティティの追加に重点を置いています。 データサイエンスコミュニティから発信された可能性がありますが、どの企業でも使用できます。 また、データセットの構造化データマークアップの経験がある高レベルの専門家からピアレビューされた入力を求めることをお勧めします。
Hill Web Marketingはこのイニシアチブに積極的に参加しており、読者が現在利用可能なデータセットの数を増やすことを奨励することを望んでいます。 データサイエンスコミュニティから発信された可能性がありますが、どの企業でも使用できます。
デジタルマーケティングストラテジストであるHillWebMarketingの所有者であるJeannieHillに、パートナーに電話してください:651-206-2410。 競争力を獲得するためにあなたの相談をスケジュールする
* https://arxiv.org/pdf/1908.07442.pdf
** https://www.ibm.com/support/knowledgecenter/SSWQ2D_1.1.0/us/create-dataset-image-object-classification.html
*** https://cloud.google.com/retail/recommendations-ai/docs/upload-catalog
**** https://www.blog.google/products/search/making-it-easier-discover-datasets/
***** https://storage.googleapis.com/pub-tools-public-publication-data/pdf/40761.pdf