
Jak korzystać z wyszukiwania zbiorów danych Google dla schematu zbioru danych
Opublikowany: 2019-10-01Wyszukiwanie zbiorów danych Google: jak używać schematu zbioru danych do zapytań
Zaktualizowano 16.2.2021
Wraz z rosnącą ilością danych cyfrowych stratedzy marketingu w wyszukiwarkach stają w obliczu rosnącej potrzeby nadania sensu danym.
Wiele zaawansowanych aplikacji bazodanowych zaczyna obsługiwać Google Database Search. Ponadto SEO mają nowe raporty dodane do Google Search Console we wrześniu 2019 r., aby lepiej zrozumieć ich dane. Wiele można zyskać przez włączenie wiedzy na poziomie domeny zakodowanej jako ontologie do zapytań dotyczących danych relacyjnych. Mając tak wiele do powiedzenia na temat SEO, marketerzy w wyszukiwarkach uważają, że trudniej jest oddzielić fakty od fikcji, szkodliwe od pomocnych taktyk SEO i przetestować prawdę, a nie tylko mówić.
Poleganie w dużej mierze na wcześniejszych doświadczeniach i intuicjach związanych z marketingiem w wyszukiwarkach jest miłe, ale zbyt często błędne. Decyzje oparte na danych okazują się konsekwentnie lepsze niż „moje przeczucie mi tak podpowiadało”. Wiele narzędzi do analizy danych, takich jak Google Analytics, dostarcza rzeczywistych dowodów, ale teraz łatwiej niż kiedykolwiek można zlokalizować publiczne zbiory danych Google Cloud.
Co to jest wyszukiwanie zbiorów danych Google?
Szybki ogólny obraz jest taki, że wyszukiwanie danych Google zależy od dostawców zbiorów danych, dużych lub małych, którzy dodają ustrukturyzowane metadane w swoich witrynach przy użyciu otwartego standardu schema.org/Dataset. Wyszukiwarka zbiorów danych Google umożliwia wyszukiwarkom lokalizowanie zbiorów danych przechowywanych w internecie za pomocą wyszukiwań przy użyciu określonych wyszukiwanych fraz. Według Google narzędzie udostępnia informacje o zestawach danych przechowywanych w tysiącach repozytoriów w całej sieci, dzięki czemu te zestawy danych są powszechnie dostępne i użyteczne.
Uzyskując dostęp do publicznych zbiorów danych o dużym popycie, które odnoszą się do Twojej niszy biznesowej, możesz odkryć nowe spostrzeżenia konsumentów z danych w chmurze. Analizując dodatkowe zbiory danych hostowane w BigQuery i Cloud Storage, łatwiej jest w pełni wykorzystać zalety Google Cloud .
Dziennikarze danych są już zaznajomieni z pozyskiwaniem danych rządowych i zbiorów danych dla nauk społecznych. Ten artykuł pomoże Ci ustalić punkt odniesienia i skonfigurować opartą na danych platformę do mierzenia postępów cyfrowych i korzystania z najnowszych możliwości oznaczania schematów Google.
Wyszukiwanie zbiorów danych Google jest rozpoznawane jako rodzaj wyszukiwarki, która została uruchomiona przez Google w celu pomocy naukowcom w znajdowaniu potrzebnych im danych. Marketerzy w wyszukiwarkach coraz częściej wykorzystują zbiory danych.
Czy zestawy danych upraszczają analizę danych i skomplikowaną ontologię?
TAk. Zbiory danych są łatwiejsze do zlokalizowania, gdy informacje pomocnicze, takie jak nazwa dostawcy, opis, twórca i formaty dystrybucji, są oznaczane danymi strukturalnymi. Google ułatwia znajdowanie zbiorów danych dzięki schema.org i innym standardom metadanych, które można dodawać do treści internetowych przedstawiających zbiory danych.
Po zbudowaniu indeksu biblioteki Google zaczyna odpowiadać na zapytania użytkowników — i określać, które wyniki najlepiej odpowiadają zapytaniu każdej osoby, wypowiedzianym lub wpisanym.
„Niezwykle trudno jest wyrazić zapytania względem ontologii o strukturze grafowej w relacyjnym języku zapytań SQL lub jego rozszerzeniach. Co więcej, zapytania semantyczne zwykle nie są precyzyjne, zwłaszcza gdy dane i związana z nimi ontologia są skomplikowane”.
Użytkownicy nie muszą nawet znać reprezentacji ontologicznej. Wystarczy, że użytkownik poda kilka przykładów, które spełnią zapytanie, które ma na myśli. Następnie system Google automatycznie znajduje odpowiedź na zapytanie . W tym procesie semantyka, która jest pojęciem zwykle trudnym do wyrażenia, pozostaje pojęciem w umyśle użytkownika, bez konieczności wyrażenia jej wprost w języku zapytań. – Oficjalny dokument Google: zapytania semantyczne według przykładów *****
To stwarza okazję. Wstępnie wytrenowane modele na ogromnych zestawach danych są dostępne dla każdego, kto tworzy przetwarzanie języka naturalnego. Od czytania ze zrozumieniem do analizy sentymentów do BERT; kluczowym trendem badawczym jest wzrost transferu uczenia się w NLP.
Ewolucja roli marketera w wyszukiwarkach stała się bardziej złożona wraz z rosnącą potrzebą trawienia danych. Tworzenie własnego zbioru danych to forma pozytywnego SEO, która może opierać się na literaturze naukowej. Ponowne przemyślenie, jak zastosować dane obrazu na szerszym poziomie, może być miejscem, od którego warto zacząć. Pomoże to skalowalnym systemom w określaniu krótkich ścieżek na wykresie linków i sieci linków. Prawdopodobnie pomoże Google w ponownym zindeksowaniu i obliczeniu mapy linków w Twojej witrynie.
„Opisując zbiory danych w pakietach, na przykład publikowanych w naukowych, naukowych lub rządowych repozytoriach „otwartych danych”, można użyć typu Dataset wraz z DataCatalog w celu wskazania ogólnego zbioru, a DataDownload w przypadku konkretnych reprezentacji zestawu danych”. – Dane i zbiory danych – schema.org
Kroki dodawania schematu zestawu danych
- Najpierw przeczytaj znaczniki dokumentacji zestawu danych, aby dowiedzieć się, jak dodać go do domeny w porównaniu z pojedynczym plikiem DCAT.
- Następnie dodaj do swojej kolekcji fragmentów danych strukturalnych w preferowanym przez Google formacie znaczników JSON-LD; użyj schematu typu Dataset.
- Przetestuj implementację swojego zbioru danych za pomocą narzędzia do testowania uporządkowanych danych Google.
- Na koniec prześlij swoje adresy URL w mapie witryny, która informuje Googlebota, aby zaczął indeksować strony zbioru danych.
UWAGA: Google akceptuje znaczniki z formatowaniem DCAT. Schemat zbioru danych Google ma na celu pokazanie treści uporządkowanych informacji opisujących niektóre zorganizowane informacje. Działa w celu wstawienia uporządkowanych danych JSON w treści lub nagłówku.
Zbiory danych Google korzystające z kodu JSON-LD i słownika schematów
Co to jest wyszukiwarka zbiorów danych Google?
Wyszukiwarka zbiorów danych Google ma miejsce wtedy, gdy użytkownik angażuje Google do znalezienia danych online, które są publicznie dostępne dla źródła. Wyszukiwarka zbiorów danych Google ma współpracować z Google Scholar, firmową wyszukiwarką studiów akademickich, badań i raportów.
Ostatnie zmiany na stronie dokumentacji zbiorów danych Google aktualizują sposób udostępniania uporządkowanych danych zbiorów danych webmasterom, pozycjonerom i wydawcom w wynikach rozszerzonych w wyszukiwarce Google. Różni się od zwykłego sposobu, w jaki używamy Schema.org, schemat zestawu danych może mieć dowolne formaty lub przedstawiać statystyki zbiorcze.
Aaron wyjaśnia, że Google upuścił ikonę łapy w ogłoszeniu z gwiazdką, która, jak powiedział: „sugeruje, że wprowadzenie bogatych wyników zestawu danych jest nieuchronne”.
Dlaczego powinieneś oznaczać swoje zbiory danych za pomocą schematu?
Idealne doświadczenie klienta często może wydawać się nieuchwytne. Nie jest łatwo mapować podróż klienta i sortować stosy cyfrowych ciągów danych. Potrzeba czegoś więcej niż tylko odpowiedniej oferty dla właściwego klienta. Zaczyna się od czasów zakupu, jaki kanał cyfrowy, zbierania danych z poprzednich ofert, a czasem nawet więcej. Zarządzanie danymi przeszło od taktycznego myślenia o kupowaniu mediów do sposobu wdrażania właściwych strategicznych spostrzeżeń, które są podstawą doświadczeń klientów korporacyjnych i budują zaufanie do marki.
Twoje treści mogą być lepiej zrozumiane, dopasowane i wykorzystane do odpowiedzi i rozwiązań. Schemat zestawu danych wykorzystuje podejście uczenia maszynowego do przetwarzania zapytań semantycznych w relacyjnych bazach danych. W semantycznym przetwarzaniu zapytań największą przeszkodą jest dostarczenie dokładnych danych ontologicznych w formie relacyjnej, tak aby silnik relacyjnej bazy danych mógł manipulować ontologią w sposób zgodny z manipulowaniem danymi.
Zestawy danych oznaczone schematem są łatwiejsze do interpretacji przez inne osoby, a także lepsze zrozumienie danych przez wyszukiwarki. Pomaga im to przełożyć to zrozumienie na wizualne ilustracje Twoich danych.
Google twierdzi, że zbiory danych mogą być używane w następujących przypadkach:
- Tabela lub plik CSV z pewnymi danymi
- Zorganizowana kolekcja stołów
- Plik w zastrzeżonym formacie, który zawiera dane
- Zbiór plików, które razem tworzą jakiś znaczący zbiór danych
- Obiekt strukturalny z danymi w innym formacie, który możesz chcieć załadować do specjalnego narzędzia do przetwarzania
- Obrazy przechwytywania danych
- Pliki związane z uczeniem maszynowym, takie jak wytrenowane parametry lub definicje struktury sieci neuronowej
- Wszystko, co dla Ciebie wygląda jak zbiór danych
Znaleźliśmy ogromne zbiory danych. Najlepiej zachować prostotę. Google zaleca „ograniczenie wszystkich właściwości tekstowych do 5000 znaków lub mniej. Wyszukiwanie zbiorów danych Google używa tylko pierwszych 5000 znaków dowolnej właściwości tekstowej. Nazwy i tytuły to zazwyczaj kilka słów lub krótkie zdanie”.
Jak zmodernizować swoje dane za pomocą bezpiecznych, niezawodnych relacyjnych baz danych
Relacyjna baza danych gromadzi i przechowuje dane w tabelach i kolumnach, które porządkują i podkreślają relacje między danymi. Relacyjne bazy danych są przeznaczone dla danych, które są ustrukturyzowane i połączone. Webopedia definiuje relacyjne bazy danych jako zdolne do „ustawienia automatycznej aktualizacji danych, jeśli jedno z nich jest edytowane lub zmieniane; pozostałe powiązane dane będą otrzymywać aktualizacje w czasie rzeczywistym. Ludzie często używają zamiennie relacyjnych baz danych i relacyjnych systemów zarządzania bazami danych (RDBMS)”.
Pomaga to firmom tworzyć rozwiązania do przetwarzania danych o nowoczesnej architekturze i uzyskiwać inteligentne informacje biznesowe w czasie rzeczywistym, aby lepiej spełniać intencje użytkowników.
Modele typu tabela do tekstu wyodrębniają informacje tekstowe z danych strukturalnych 
Opieraj się na danych i skoncentruj się na ludziach
Uzyskanie sekwencyjnego mechanizmu wyodrębniania danych na poziomie pola pomaga w przeprowadzeniu ostatecznej klasyfikacji lub zadania regresji oceniającego nadrzędne cechy wejściowe, poprzez mapowanie ich na alternatywny typ danych.
Raporty dotyczące zbiorów danych Google mogą pomóc w zdobywaniu wiedzy, aby lepiej myśleć o dopasowaniu intencji wyszukiwania. Przeszukaj bibliotekę danych online, aby znaleźć to, czego potrzebujesz, lub zatrudnij analityka danych. Bogate w zestawy danych wyniki są przydatne w szybkich przepływach pracy badawczo-rozwojowej, które pomagają usprawnić kodowanie nieprzetworzonych danych w celu uzyskania znaczących informacji. Pomagają stworzyć ustrukturyzowane podejście do Twoich danych. Firmy odnoszą korzyści, usprawniając procesy decyzyjne i szybciej osiągając lepsze wyniki.
„Jednym z głównych czynników umożliwiających szybki postęp w badaniach i rozwoju jest dostępność kanonicznych architektur sieci neuronowych do wydajnego kodowania nieprzetworzonych danych w znaczące reprezentacje. Zintegrowane z prostymi warstwami podejmowania decyzji, te kanoniczne architektury zazwyczaj zapewniają wysoką wydajność w przypadku nowych zestawów danych i powiązanych zadań przy niewielkim dodatkowym nakładzie pracy”. – Uważne, zinterpretowane tabelaryczne uczenie się w Google Cloud AI
Co się zmieniło w wersji beta wyszukiwania zbiorów danych Google? 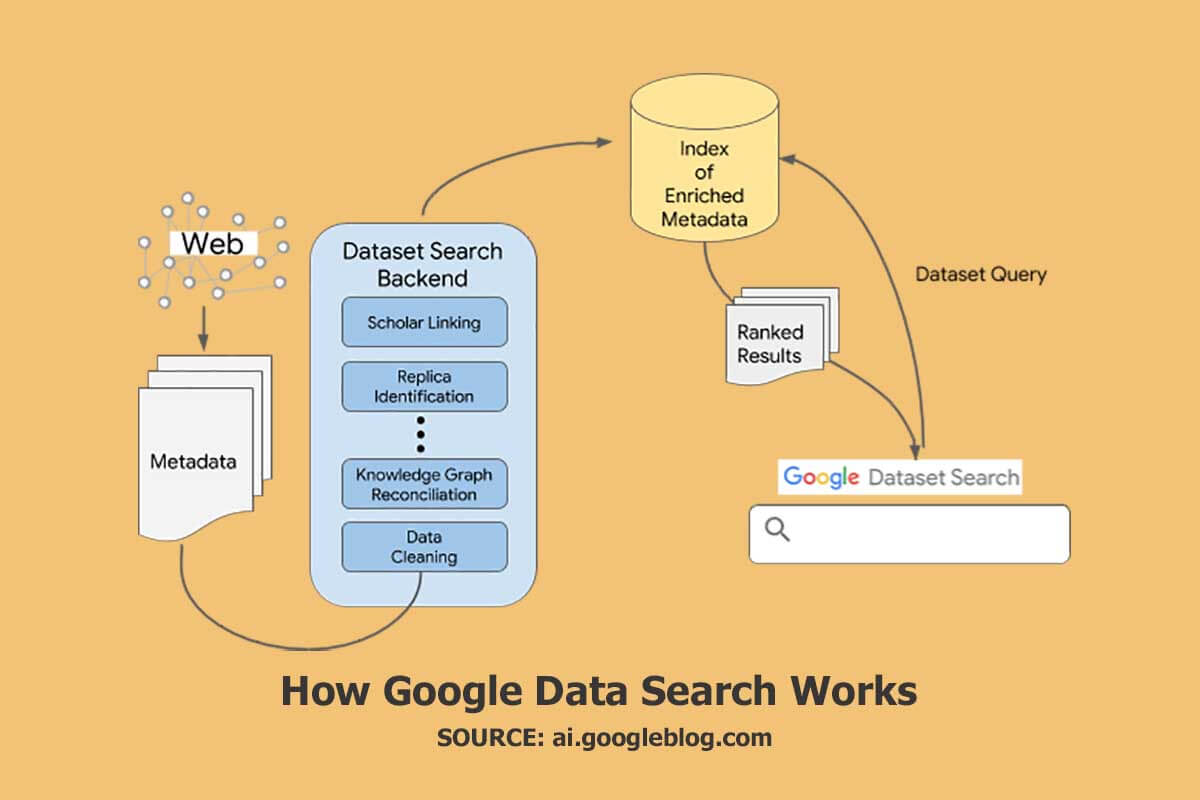
Wcześniej w dokumentach Google stwierdzono, że: „Znaczniki zbioru danych są dostępne do eksperymentowania, zanim zostaną udostępnione do powszechnej dostępności” i ostrzegały, że chociaż można używać narzędzia do testowania danych strukturalnych do walidacji, „nie , jednak zobacz, jak Twoje zbiory danych pojawiają się w wyszukiwarce”. Dla tych, którzy czekali na wprowadzenie tej funkcji, dodanie do witryny uporządkowanych danych zbioru danych może pomóc w mierzeniu wyzwań związanych z urządzeniami mobilnymi i specyfikacji usług. Wyszukiwarka zbiorów danych Google obsługuje Google Scholar, firmę technologiczną, wyszukiwarkę studiów akademickich i raportów opartych na faktach.
23 stycznia 2020 r. Natasha Noy z Google stwierdziła, że „Wyszukiwarka zestawów danych zindeksowała prawie 25 milionów tych zestawów danych, zapewniając jedno miejsce do wyszukiwania zestawów danych i znajdowania linków do miejsc, w których znajdują się dane. W ciągu ostatniego roku ludzie wypróbowali to i przekazali opinie, a teraz wyszukiwanie zestawów danych oficjalnie nie jest dostępne w wersji beta”.
Artykuł Odkrywanie milionów zbiorów danych w sieci informuje nas, że większość rządów na świecie publikuje swoje dane i oznacza je w schema.org. „Stany Zjednoczone prowadzą pod względem liczby dostępnych otwartych zbiorów danych rządowych, z ponad 2 milionami”.
Oznacza to, że badacze rynku mają lepszy dostęp do danych niż kiedykolwiek w naszej cyfrowej historii.
Zbiory danych mogą zarządzać całą zawartością witryny
Po zebraniu czystych i użytecznych danych, mimo że wymaga to dużo czasu, może wspierać i pomagać w zarządzaniu całą zawartością w Twojej witrynie.
Możesz dowiedzieć się, jak uzyskać bardziej merytoryczne informacje, korzystając z różnych zadań uczenia maszynowego z bardziej realistycznymi zestawami danych. W przypadku każdego biznesowego wskaźnika KPI Hill Web Marketing może pomóc w zrozumieniu, które metryki są ważne, jak korzystać ze schematu, aby dopasować je do celów branżowych, i wykreślić, jak uzyskać lepszą wydajność.

Natasha Noy, naukowiec ds. Google AI, opublikowała artykuł Ułatwianie odkrywania zbiorów danych 5 września 2018 r. i stwierdza: „Wyszukiwanie zbiorów danych działa w wielu językach z obsługą dodatkowych języków już wkrótce”.**** Oczywiście jest to kierunek, w jakim zmierza sieć; wdrożenie podstawowych typów znaczników schematu pomoże znaleźć Twoją firmę.
Korzystanie z zestawów danych pomaga zapewnić strumienie przychodów z produktów
Jak działa wyszukiwanie zbiorów danych Google?
Zestawy danych można łatwo wykryć, gdy jako dane strukturalne podasz informacje, które zawierają informacje, takie jak ich nazwa, opis, twórca i formaty dystrybucji. Google usprawnia wykrywanie zbiorów danych i wykorzystuje standard schema.org oraz inne formaty danych, które można umieszczać na stronach internetowych opisujących zbiory danych. Ten schemat może zwiększyć Twoje szanse na znalezienie się w wynikach wyszukiwania produktów w karuzeli.
Przyszły sukces Twojej firmy zależy od spostrzeżeń potrzebnych do kierowania Twojej organizacji w kierunku trwałych strumieni przychodów. Wiadomości o Twoich produktach muszą wzbudzać zaufanie potencjalnego nabywcy na tyle, aby podjąć działania wymagane do zawarcia transakcji. Masz pewien poziom kontroli nad tym, co pojawia się na wykresie wiedzy Twojej firmy. „Stawka jest wysoka, a International Data Corporation szacuje, że globalne inwestycje biznesowe w D&A przekroczą 200 miliardów dolarów rocznie do 2020 roku”, według Harvard Business Review.
„Solidna, skuteczna funkcja D&A (dane i analityka) obejmuje więcej niż stos technologii lub kilka osób odizolowanych na jednym piętrze budynku. D&A powinno być pulsem organizacji, uwzględnianym we wszystkich kluczowych decyzjach dotyczących sprzedaży, marketingu, łańcucha dostaw, obsługi klienta i innych podstawowych funkcji”. – Harvard Business Review
Zdjęcia produktów mogą być częścią zbioru danych obrazu Google! W niektórych zbiorach danych na obraz przypada średnio 8,4 obiektów. Oto lista zestawów danych, która jest często aktualizowana.
Strona dokumentacji Google zawiera przykład JSON-LD do implementacji schema.org/Dataset. Ponieważ zestaw danych cylindrycznych jest w wersji beta, pojawią się najlepsze praktyki dotyczące opisu i używania zestawu danych. Gdy zmieniają się wymagania dotyczące kodu, przeprowadź audyt techniczny SEO, aby zlokalizować, gdzie potrzebne są aktualizacje.
Jak przesłać zbiory danych produktów i obrazów do Google BigQuery?
Google BigQuery (GBQ) umożliwia marketerom wyszukiwania zbieranie danych z różnych źródeł. Zalecamy korzystanie z Google Merchant Center, Cloud Storage, BigQuery lub możesz określić dane bezpośrednio podczas składania prośby. Zanim prześlesz jakiekolwiek dane, najpierw utwórz zbiór danych i tabelę w Google BigQuery, które zawierają informacje o Twoich produktach, w tym szczegóły obrazu. ***
Wolimy używać formatu danych produktu JSON-LD. Oto przykład kompletnego obiektu:
{
"name": "projects/[PROJECT_NUMBER]/locations/global/catalogs/default_catalog/branches/0/products/1234",
"id": "1234",
"categories": "Apparel & Accessories > Shoes",
"title": "ABC sneakers",
"description": "Sneakers for the rest of us",
"attributes": { "vendor": {"text": ["vendor123", "vendor456"]} },
"language_code": "en",
"tags": [ "black-friday" ],
"priceInfo": {"currencyCode": "USD", "price":100, "originalPrice":200, "cost": 50},
"availableTime": "2020-01-01T03:33:33.000001Z",
"availableQuantity": "1",
"uri":"http://foobar",
"images": [{"uri": "http://foobar/img1", "height": 320, "width": 320 }]
}
Aktualizuj swój katalog produktów. Google dba o jakość, a jego sztuczna inteligencja wymaga wysokiej jakości danych, aby tworzyć wysokiej jakości prognozy. Obserwuj produkty, których nie ma już w sprzedaży, i aktualizuj dane w znacznikach schematu produktu e-commerce w Twojej witrynie.
„Tabelaryczny zestaw danych jest zorganizowany głównie w postaci siatki wierszy i kolumn. W przypadku stron z osadzonymi tabelarycznymi zestawami danych można również utworzyć bardziej jednoznaczne znaczniki, opierając się na podstawowym podejściu opisanym powyżej. W tej chwili rozumiemy odmianę CSVW („CSV w sieci”, patrz W3C), dostarczaną równolegle z treścią tabelaryczną zorientowaną na użytkownika na stronie HTML.”, stwierdza stan na 9.30.2019.
Zaglądaj na stronę dokumentacji Google, aby uzyskać aktualizacje na wypadek zmiany właściwości wymienionych dla Dataset, DataCatalog lub DataDownload. Aktualna dokumentacja zaktualizowała aspekt organizacyjny; specyfikacje nieruchomości są teraz konsolidowane w ramach typu, do którego należy każda (wcześniej były zorganizowane tematycznie). Te nowe właściwości to jeden ze sposobów na ulepszenie atrybutów Twojej witryny.
Jak utworzyć zestaw danych z obrazów do klasyfikacji obiektów.
W konsoli zarządzania klastrem IBM wybierz (1) Obciążenie, (2) Spark, a następnie (3) Głębokie uczenie. **
* Kliknij zakładkę „Zbiory danych”.
* Wybierz „Nowy”.
* Utwórz zbiór danych z „Obrazy do klasyfikacji obiektów”.
* Wprowadź nazwę zbioru danych.
* Wskaż wybraną grupę instancji Spark.
* Określ preferowany format przechowywania obrazów (preferujemy TFRecords dla TensorFlow).
* Jeśli wybrano TFRecords, przejdź do sposobu generowania rekordów według fragmentu lub klasy. Jeśli wybrany jest fragment, wprowadź numer fragmentu.
* Określ, w jaki sposób wybierane są obrazy treningowe.
Przestrzegając wytycznych Google dotyczących grafiki i wymagań dotyczących obrazów AMP, Twoje produkty mają większą szansę na wyświetlenie we fragmentach opisów związanych z produktami.
Właściwości uporządkowanych danych zbioru danych
Naprawdę, w tej chwili jest niewiele wymaganych właściwości. Aby zachęcić do jego używania, gigant technologiczny może obrać strategię „zachowaj prostotę”, jeśli chodzi o dostarczanie treści przeznaczonych dla konsumentów danych maszynowych. Ostatecznym celem jest posiadanie większej liczby i lepszych dopasowań w bibliotece danych, aby zaspokoić zamiary wyszukiwania użytkowników.
Wymagane właściwości:
- imię
- opis
Zalecane właściwości:
- Alternatywna nazwa
- twórca
- cytat
- identyfikator
- słowa kluczowe
- licencja
- taki sam jak
- Zasięg przestrzenny
- Zasięg czasowy
- zmienna mierzona
- wersja
- adres URL
Być może nie masz jeszcze opublikowanego zestawu danych w sieci, ale marketing w wyszukiwarkach szybko zmierza w kierunku podejścia opartego na analizie danych w wyszukiwaniu. Ponieważ osoby i ludzie będą udostępniać coraz więcej zbiorów danych, wyszukiwanie zbiorów danych będzie się zwiększać. Zaskakujące jest to, że każdy , kto publikuje dane, może opisać swój zbiór danych za pomocą otwartego standardu opisywania informacji schema.org.
Podczas testowania danych w raporcie indeksu Search Console zapoznaj się z sekcją „Znane błędy i ostrzeżenia”, „błędami lub ostrzeżeniami w narzędziu Google do testowania danych strukturalnych” oraz systemem weryfikacji Linter danych strukturalnych. Zatrudnij eksperta od implementacji danych schematu lub skorzystaj z formularzy, aby określić, jakie ostrzeżenia możesz bezpiecznie zostawić.
Ponieważ dotyczy to parsowania treści internetowych – niezależnie od tego, czy zawierają one już ustrukturyzowane dane – najlepiej jest udostępnić dane w formacie zrozumiałym dla największego odsetka konsumentów danych (przede wszystkim wyszukiwarek).
Zestawy danych zapewniają mapę drogową tworzenia wykresów wiedzy
Znajduj zbiory danych i korzystaj z wyszukiwania akademickiego z otwartych źródeł danych i https schema.org.
Badacze cenią jasność w precyzyjnej analizie rozwiązań z zakresu nauki o globalnych danych i uczenia maszynowego, które ujawniają dynamikę rynku. Marketerzy w wyszukiwarkach, którzy chcą mierzyć zrównoważone trendy marketingowe, polegają na dużych zbiorach danych, aby wspierać przyszły wzrost rynku. Gdy Google Dataset Search wyjdzie z wersji beta, może mieć nowe możliwości prowadzenia badań danych, które mogą zmniejszyć obecne ryzyko i wyzwania stojące przed firmami. Szeroko zakrojone badania szczegółów zawartych w Twoich danych mogą poprawić Twoje podejście do sprzedaży.
Nieustannie poszukujemy praktycznych podejść do budowania grafów wiedzy o klientach i możliwości wykorzystania ich w zastosowaniach biznesowych. Spróbuj w tym swoich sił.
Po użyciu schematu zbioru danych w witrynie w ramach ulepszeń w GSC pojawi się nowy raport. Używamy ich do ulepszania naszej strategii marketingu treści mobilnych dla użytkowników korzystających z wielu urządzeń.
Funkcje zbioru danych i nowy raport ulepszeń Google
Podobnie jak w przypadku innych implementacji danych strukturalnych tylko dlatego, że zostały włączone dane strukturalne schematu, kwalifikujesz się . Nie gwarantuje jednak, że pojawi się w wyszukiwarce Google. Ustalaj priorytety, korzystając z zestawów danych, które wspierają sprzedaż i strony docelowe sprzedaży detalicznej.
Równolegle z ogłoszeniem funkcji danych strukturalnych pojawił się nowy raport Ulepszenia zbioru danych w Google Search Console. Informuje to strategów marketingu w wyszukiwarkach, czy Google poznało i rozpoznaje Twoje dane strukturalne dla schematu zbioru danych. Przeczytaj i napraw wszelkie błędy dotyczące uporządkowanych danych, gdy zrozumiesz specyfikacje dokumentacji dotyczącej danych strukturalnych zestawu danych. Przekaże dane Asystenta Google.
Niewielu właścicieli firm lub twórców treści ma wolne godziny na zastanowienie się, czy Twoje metadane są poprawnie sformatowane. Jednak musi tak być, aby umożliwić GoogleBotowi indeksowanie Twojej witryny, znajdowanie danych i ich indeksowanie. Na szczęście to kochamy i jesteśmy w Twoim narożniku.
Uprawnienia do tworzenia zbioru danych
Uprawnienie do kompilacji dotyczy zestawów danych. Gdy użytkownicy otrzymają uprawnienia do kompilacji, mogą tworzyć nową zawartość na istniejącym zestawie danych. Jest to typowe dla raportów, pulpitów nawigacyjnych, przypiętych kafelków z QandA i Insights Discovery. Mogą również tworzyć nowe wpisy danych w zestawie danych poza usługą Power BI, zazwyczaj arkusze programu Excel, za pomocą funkcji Analizuj w programie Excel, XMLA i eksportować dane bazowe. Pomaga firmom przeprowadzać analizę klientów.
Choć głębokie uczenie jest nowe i wszechstronne, Google i inne wyszukiwarki wciąż borykają się z wyzwaniami związanymi z zarządzaniem danymi, które pojawiają się w kontekście potoków uczenia maszynowego wdrożonych w środowisku produkcyjnym. Nowe próby zrozumienia semantycznych zapytań wyszukiwania mają na celu wspieranie zrozumienia, walidacji, czyszczenia i wzbogacania danych szkoleniowych. Miejmy nadzieję, że dzięki temu wzrost liczby zaufanych źródeł baz danych rozszerzy się i będzie bardziej przydatny do napędzania ruchu w sklepie.
Marketing cyfrowy wiąże się z potrzebą danych i wykorzystaniem ich jako naukowego podejścia.
„Narzędzie wyszukiwania takie jak to jest tak dobre, jak metadane, które wydawcy danych są gotowi dostarczyć. Mamy nadzieję, że wielu z Was wykorzysta otwarte standardy do opisania swoich danych, umożliwiając naszym użytkownikom znalezienie danych, których szukają. Jeśli publikujesz dane i nie widzisz ich w wynikach, odwiedź nasze instrukcje w naszej witrynie dla programistów, która zawiera również link do zadawania pytań i przekazywania opinii”. - Google *
„Możemy zrozumieć uporządkowane dane na stronach internetowych dotyczących zestawów danych, używając znaczników zestawu danych http://schema.org lub równoważnych struktur reprezentowanych w formacie Data Catalog Vocabulary (DCAT) W3C”. – komentarz Alana Morrisona na Twitterze
Podsumowanie schematu zbioru danych Google
Korzystanie z zestawów danych do obsługi potrzeb użytkowników witryny jest bardziej skoncentrowane na doświadczeniu użytkownika i dodawaniu jednostek, które odpowiadają i informują. Chociaż może pochodzić od społeczności naukowców zajmujących się danymi, każda firma może z niego korzystać. Zalecamy również zasięgnięcie opinii recenzentów od ekspertów wysokiego szczebla, którzy mają doświadczenie w oznaczaniu ustrukturyzowanych danych dla zestawów danych.
Hill Web Marketing chętnie uczestniczy w tej inicjatywie i ma nadzieję, że zachęci ona naszych czytelników do zwiększenia liczby dostępnych obecnie zbiorów danych. Chociaż może pochodzić od społeczności naukowców zajmujących się danymi, każda firma może z niego korzystać.
Zadzwoń do Jeannie Hill, właściciela firmy Hill Web Marketing, stratega marketingu cyfrowego, do partnera: 651-206-2410. Umów się na konsultacje, aby uzyskać przewagę konkurencyjną
* https://arxiv.org/pdf/1908.07442.pdf
** https://www.ibm.com/support/knowledgecenter/SSWQ2D_1.1.0/us/create-dataset-image-object-classification.html
*** https://cloud.google.com/retail/recommendations-ai/docs/upload-catalog
**** https://www.blog.google/products/search/making-it-easier-discover-datasets/
***** https://storage.googleapis.com/pub-tools-public-publication-data/pdf/40761.pdf