
Cara menggunakan Pencarian Google Dataset untuk Skema Dataset
Diterbitkan: 2019-10-01Pencarian Dataset Google: Cara menggunakan Skema Dataset untuk Kueri
Diperbarui 12.6.2021
Dengan meningkatnya jumlah data digital, ahli strategi pemasaran pencarian menghadapi kebutuhan yang semakin besar untuk memahami data.
Banyak aplikasi database tingkat lanjut mulai mendukung Pencarian Database Google. Selain itu, SEO memiliki laporan baru yang ditambahkan ke Google Search Console pada September 2019 untuk lebih memahami data mereka. Banyak yang diperoleh dengan memasukkan pengetahuan tingkat domain yang dikodekan sebagai ontologi ke dalam kueri atas data relasional. Dengan begitu banyak yang dikatakan tentang SEO, pemasar pencarian merasa lebih sulit untuk menyaring fakta dari fiksi, berbahaya dari taktik SEO yang bermanfaat, dan teruji kebenarannya versus hanya omong kosong.
Mengandalkan sebagian besar pada pengalaman dan intuisi pemasaran pencarian masa lalu itu bagus, tetapi terlalu sering salah. Keputusan yang dipengaruhi data terbukti secara konsisten lebih baik daripada "inti saya mengatakan demikian". Banyak alat wawasan data seperti Google Analytics memberikan bukti pendukung yang sebenarnya, tetapi sekarang lebih mudah untuk menemukan Kumpulan Data Publik Google Cloud.
Apa itu Pencarian Kumpulan Data Google?
Gambaran besar yang cepat adalah bahwa Pencarian Data Google bergantung pada penyedia kumpulan data, besar atau kecil, menambahkan metadata terstruktur dalam situs web mereka menggunakan standar schema.org/Dataset terbuka. Pencarian Kumpulan Data Google memberdayakan pencari untuk menemukan kumpulan data yang disimpan di seluruh web melalui pencarian dengan frasa pencarian tertentu. Menurut Google, alat ini memunculkan informasi tentang kumpulan data yang dihosting di ribuan repositori di seluruh web, membuat kumpulan data ini dapat diakses dan berguna secara universal.
Dengan mengakses kumpulan data publik dengan permintaan tinggi yang terkait dengan niche bisnis Anda, Anda dapat mengungkap wawasan konsumen baru dari data cloud. Dengan menganalisis set data tambahan yang dihosting di BigQuery dan Cloud Storage, lebih mudah untuk merasakan manfaat penuh dari Google Cloud .
Jurnalis data sudah terbiasa memperoleh data pemerintah dan kumpulan data untuk ilmu sosial. Artikel ini akan membantu Anda menetapkan dasar dan menyiapkan kerangka kerja berbasis data untuk mengukur kemajuan digital Anda dan memanfaatkan peluang markup skema Google terbaru.
Pencarian dataset Google diakui sebagai jenis mesin pencari yang diluncurkan oleh Google dengan tujuan membantu para sarjana menemukan data yang mungkin mereka butuhkan. Pemasar penelusuran memanfaatkan lebih banyak kumpulan data.
Apakah Kumpulan Data Menyederhanakan Kecerdasan Data dan Ontologi yang Rumit?
Ya. Kumpulan data lebih mudah ditemukan saat informasi pendukung seperti nama penyedia, deskripsi, pembuat, dan format distribusi ditandai dengan data terstruktur. Google mempermudah penemuan kumpulan data melalui schema.org dan standar metadata lainnya yang dapat ditambahkan ke konten web yang menggambarkan kumpulan data.
Setelah Google membangun indeks perpustakaannya, ia mulai menjawab kueri pengguna — dan menentukan hasil mana yang paling sesuai dengan kueri setiap orang, diucapkan atau diketik.
“Sangat sulit untuk mengekspresikan kueri terhadap ontologi terstruktur grafik dalam bahasa kueri SQL relasional atau ekstensinya. Selain itu, kueri semantik biasanya tidak tepat, terutama ketika data dan ontologi terkaitnya rumit.”
Pengguna bahkan tidak perlu mengetahui representasi ontologi. Yang diperlukan hanyalah pengguna memberikan beberapa contoh yang memenuhi permintaan yang ada dalam pikirannya. Selanjutnya, sistem Google secara otomatis menemukan jawaban atas kueri tersebut . Dalam proses ini, semantik, yang merupakan konsep yang biasanya sulit diungkapkan, tetap menjadi konsep di benak pengguna, tanpa harus diungkapkan secara eksplisit dalam bahasa query. – Google Whitepaper: Kueri Semantik dengan Contoh *****
Ini menghadirkan peluang. Model pra-pelatihan pada kumpulan data besar tersedia bagi siapa saja yang membangun pemrosesan bahasa alami. Dari pemahaman bacaan hingga analisis sentimen hingga BERT; tren penelitian utama adalah munculnya transfer learning di NLP.
Evolusi peran pemasar pencarian menjadi lebih kompleks dengan meningkatnya kebutuhan untuk mencerna data. Membuat kumpulan data Anda sendiri adalah bentuk SEO positif yang dapat bersandar pada literatur akademis. Memikirkan kembali tentang bagaimana Anda dapat menerapkan data gambar Anda pada tingkat yang lebih luas, mungkin merupakan tempat untuk memulai. Ini akan membantu sistem yang dapat diskalakan untuk menentukan jalur pendek dalam grafik tautan dan jaringan tautan web Anda. Ini mungkin membantu Google saat merayapi ulang dan menghitung ulang peta tautan situs Anda.
“Saat mendeskripsikan kumpulan data yang dikemas, misalnya seperti yang dipublikasikan dalam repositori “data terbuka” ilmiah, ilmiah, atau pemerintah, tipe Dataset dapat digunakan, bersama DataCatalog untuk menunjukkan koleksi keseluruhan, dan DataDownload untuk representasi spesifik dari kumpulan data.” – Data dan Kumpulan Data – schema.org
Langkah-langkah untuk Menambahkan Skema Dataset
- Pertama, baca markup dokumentasi kumpulan data untuk mempelajari cara menambahkannya ke domain Anda versus satu file DCAT.
- Selanjutnya, tambahkan ke koleksi cuplikan data terstruktur Anda dalam format markup JSON-LD pilihan Google; gunakan skema tipe Dataset.
- Uji implementasi set data Anda dengan Alat Pengujian Data Terstruktur Google.
- Terakhir, kirimkan URL Anda dalam peta situs yang memberi tahu Googlebot untuk mulai merayapi halaman kumpulan data.
CATATAN: Google menerima markup dengan format DCAT. Skema Dataset Google dimaksudkan untuk menunjukkan kumpulan informasi terstruktur yang menjelaskan beberapa informasi yang terorganisir. Ini berfungsi untuk memasukkan data terstruktur JSON baik di badan atau kepala.
Kumpulan Data Google menggunakan kode JSON-LD dan Kosakata Skema
Apa itu mesin telusur kumpulan data Google?
Mesin Telusur Google Dataset adalah saat pengguna menggunakan Google untuk mencoba menemukan data online yang tersedia secara publik untuk sumbernya. Google Dataset Search dimaksudkan untuk bekerja sama dengan Google Cendekia, mesin pencari perusahaan untuk studi akademis, penelitian, dan laporan.
Perubahan terbaru pada halaman dokumentasi kumpulan data Google memperbarui cara peluncuran data terstruktur kumpulan data ke webmaster, SEO, dan penerbit dalam hasil kaya di penelusuran Google. Ini berbeda dari cara umum kita menggunakan Schema.org, skema dataset bisa dalam format arbitrer atau mewakili statistik agregat.
Aaron menjelaskan bahwa Google menjatuhkan ikon cakar di pemberitahuan dengan bintang, yang katanya: "menunjukkan bahwa peluncuran hasil kaya dataset sudah dekat."
Mengapa Anda harus Markup Dataset Anda dengan Skema?
Pengalaman pelanggan yang ideal sering kali terasa sulit dipahami. Tidak mudah untuk memetakan perjalanan pelanggan dan memilah-milah gundukan string data digital. Dibutuhkan lebih dari sekadar memiliki penawaran yang tepat untuk pelanggan yang tepat. Dimulai dengan waktu pembelian, saluran digital mana, pengumpulan data dari penawaran sebelumnya, dan terkadang bahkan lebih. Manajemen data telah berubah dari pemikiran pembelian media taktis menjadi bagaimana menerapkan wawasan strategis yang tepat yang merupakan inti dari pengalaman pelanggan perusahaan yang membangun kepercayaan merek.
Konten Anda dapat lebih dipahami, dicocokkan, dan digunakan untuk jawaban dan solusi. Skema kumpulan data memanfaatkan pendekatan pembelajaran mesin untuk memproses kueri semantik dalam database relasional. Dalam pemrosesan kueri semantik, rintangan terbesar adalah menyediakan data ontologis yang akurat dalam bentuk relasional sehingga mesin basis data relasional dapat memanipulasi ontologi dengan cara yang selaras dengan manipulasi data.
Kumpulan data yang ditandai dengan skema lebih mudah diinterpretasikan oleh orang lain, serta mesin telusur untuk memahami data dengan lebih baik. Ini membantu mereka menerjemahkan pemahaman itu ke dalam ilustrasi visual data Anda.
Google mengatakan kumpulan data dapat digunakan untuk kasus ini:
- Tabel atau file CSV dengan beberapa data
- Koleksi tabel yang terorganisir
- File dalam format berpemilik yang berisi data
- Kumpulan file yang bersama-sama membentuk beberapa kumpulan data yang berarti
- Objek terstruktur dengan data dalam beberapa format lain yang mungkin ingin Anda muat ke dalam alat khusus untuk diproses
- Gambar menangkap data
- File yang berkaitan dengan pembelajaran mesin, seperti parameter terlatih atau definisi struktur jaringan saraf
- Apa pun yang terlihat seperti kumpulan data bagi Anda
Kami menemukan beberapa kumpulan data besar. Yang terbaik adalah membuatnya tetap sederhana. Google merekomendasikan “membatasi semua properti tekstual hingga 5.000 karakter atau kurang. Google Dataset Search hanya menggunakan 5000 karakter pertama dari properti tekstual apa pun. Nama dan gelar biasanya terdiri dari beberapa kata atau kalimat pendek”.
Cara Memodernisasi Data Anda dengan Basis Data Relasional yang Aman dan Andal
Sebuah database relasional mengumpulkan dan menyimpan data dalam tabel dan kolom yang mengatur dan menekankan hubungan antara data. Database relasional ditujukan untuk data yang terstruktur dan terhubung. Webopedia mendefinisikan database relasional sebagai kemampuan untuk “mengatur untuk memperbarui data secara otomatis jika satu contoh diedit atau diubah; data terkait lainnya akan menerima pembaruan waktu nyata. Orang sering menggunakan database relasional dan sistem manajemen database relasional (RDBMS) secara bergantian”.
Ini membantu bisnis membangun solusi data dengan arsitektur modern dan mendapatkan wawasan cerdas bisnis secara real-time untuk memenuhi maksud pengguna dengan lebih baik.
Model Tabel-ke-teks mengekstrak Informasi Tekstual dari Data Terstruktur 
Berbasis Data dan Berfokus pada Orang
Mendapatkan mekanisme sekuensial untuk ekstraksi data tingkat lapangan membantu melakukan klasifikasi akhir atau tugas regresi yang mengevaluasi fitur masukan menyeluruh Anda, daripada memetakannya ke tipe data alternatif.
Laporan kumpulan data Google dapat membantu pembelajaran Anda untuk memperkuat pemikiran Anda seputar pencocokan maksud pencarian dengan lebih baik. Telusuri perpustakaan data online untuk menemukan apa yang Anda butuhkan atau pekerjakan ilmuwan data. Hasil kaya kumpulan data berguna untuk alur kerja penelitian dan pengembangan cepat yang membantu merampingkan penyandian data mentah menjadi wawasan yang bermakna. Mereka membantu menciptakan pendekatan terstruktur terhadap data Anda. Bisnis diuntungkan dengan merampingkan proses pengambilan keputusan mereka dan menghasilkan hasil kinerja yang lebih tinggi lebih cepat.
“Salah satu pendukung utama dari kemajuan penelitian dan pengembangan yang cepat adalah ketersediaan arsitektur jaringan saraf kanonik untuk secara efisien mengkodekan data mentah menjadi representasi yang bermakna. Terintegrasi dengan lapisan pengambilan keputusan sederhana, arsitektur kanonik ini biasanya menghasilkan kinerja tinggi pada kumpulan data baru dan tugas terkait dengan sedikit upaya penyetelan ekstra.” – Pembelajaran Tabular yang Dapat Ditafsirkan dengan Penuh Perhatian di Google Cloud AI
Apa yang Berubah di Pencarian Google Dataset Beta? 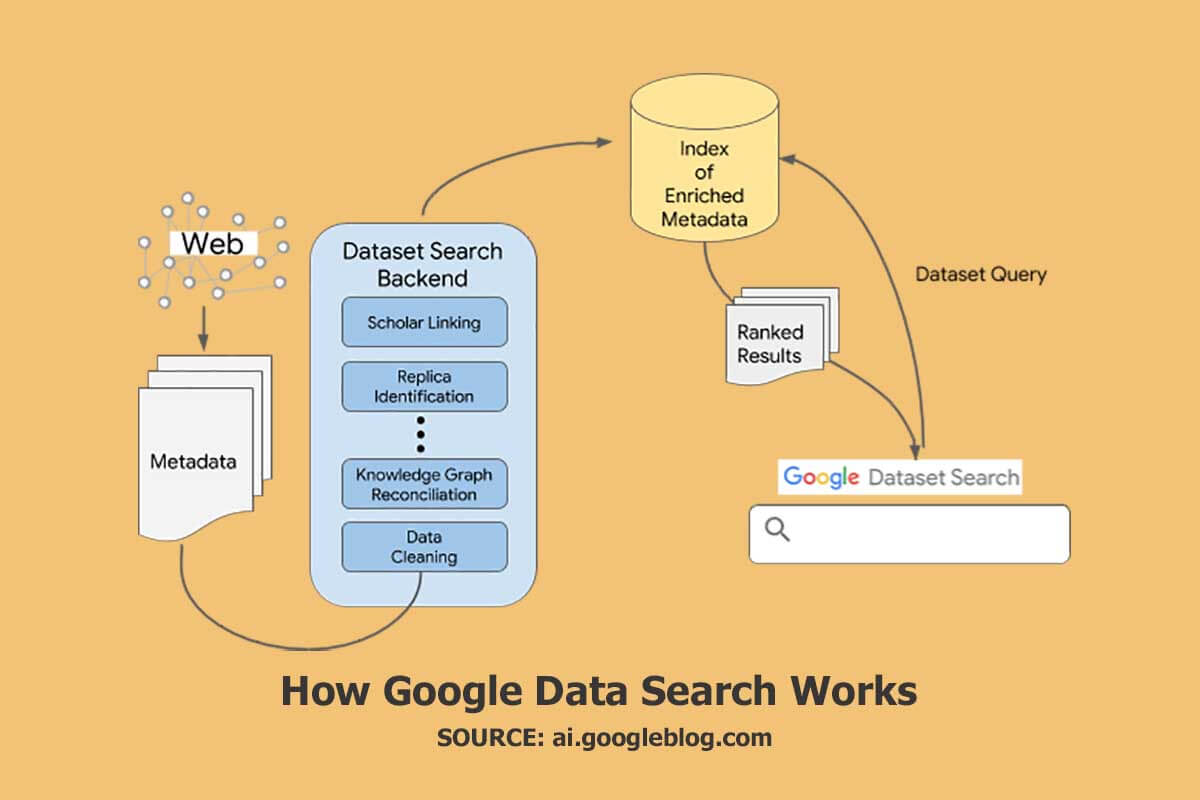
Sebelumnya, dokumen Google menyatakan bahwa: "Markup kumpulan data tersedia bagi Anda untuk bereksperimen sebelum dirilis ke ketersediaan umum" dan memperingatkan bahwa, meskipun Anda dapat menggunakan Alat Pengujian Data Terstruktur untuk validasi, Anda "tidak akan , namun, lihat set data Anda muncul di Penelusuran.” Bagi mereka yang menunggu peluncuran ini, menambahkan data terstruktur set data ke situs Anda dapat membantu mengukur tantangan seluler dan spesifikasi properti. Google Dataset Search mendukung Google Cendekia, mesin pencari perusahaan teknologi untuk studi akademis dan laporan berbasis fakta.
Pada 23 Januari 2020, Natasha Noy dari Google menyatakan bahwa “Pencarian Dataset telah mengindeks hampir 25 juta dari kumpulan data ini, memberi Anda satu tempat untuk mencari kumpulan data dan menemukan tautan ke tempat data tersebut berada. Selama setahun terakhir, orang-orang telah mencobanya dan memberikan umpan balik, dan sekarang Pencarian Dataset secara resmi keluar dari versi beta.”
Artikel Discovering jutaan set data di web memberi tahu kami bahwa sebagian besar pemerintah di dunia menerbitkan data mereka dan menandainya dengan schema.org. “Amerika Serikat memimpin dalam jumlah kumpulan data pemerintah terbuka yang tersedia, dengan lebih dari 2 juta.”
Ini berarti bahwa peneliti pasar memiliki akses yang lebih baik ke data daripada sebelumnya dalam sejarah digital kita.
Kumpulan data dapat Mengelola semua Konten Situs Anda
Setelah pengumpulan data yang bersih dan berguna dilakukan, meskipun membutuhkan banyak waktu, ini dapat mendukung dan membantu mengelola semua konten di situs Anda.
Anda dapat mempelajari cara mendapatkan informasi yang lebih faktual menggunakan tugas machine learning yang berbeda dengan kumpulan data yang lebih realistis. Untuk setiap KPI bisnis Anda, Hill Web Marketing dapat membantu Anda memahami metrik mana yang penting, cara menggunakan skema untuk menyelaraskannya dengan sasaran industri Anda, dan merencanakan cara meningkatkan kinerja.

Natasha Noy, seorang Research Scientist untuk Google AI, menerbitkan Membuat lebih mudah untuk menemukan kumpulan data pada 5 Sep 2018, dan menyatakan, “Pencarian Kumpulan Data berfungsi dalam berbagai bahasa dengan dukungan untuk bahasa tambahan segera hadir”.**** Jelas, ini arah web itu pergi; menerapkan tipe-tipe penting dari markup Skema akan membantu bisnis Anda ditemukan.
Menggunakan Dataset Membantu Memastikan Aliran Pendapatan Produk
Bagaimana cara kerja pencarian set data Google?
Kumpulan data dapat ditemukan dengan mudah saat Anda memberikan informasi yang menyertakan sesuatu seperti nama, deskripsi, pembuat, dan format distribusinya sebagai data terstruktur. Google memberdayakan penemuan kumpulan data dan memanfaatkan schema.org dan format data lain yang dapat digabungkan ke dalam halaman web yang menjelaskan kumpulan data. Skema ini dapat mendukung peluang Anda untuk berada di hasil pencarian carousel produk.
Keberhasilan bisnis Anda di masa depan bergantung pada wawasan yang diperlukan untuk mendorong organisasi Anda menuju aliran pendapatan yang berkelanjutan. Pesan tentang produk Anda perlu cukup menginspirasi kepercayaan calon pembeli untuk mengambil tindakan yang diperlukan untuk menyegel kesepakatan. Anda memiliki tingkat kontrol tertentu atas apa yang muncul dalam grafik pengetahuan perusahaan Anda. “Taruhannya tinggi, dengan International Data Corporation memperkirakan bahwa investasi bisnis global dalam D&A akan melampaui $200 miliar per tahun pada tahun 2020”, menurut Harvard Business Review.
“Fungsi D&A (Data dan Analisis) yang kuat dan sukses mencakup lebih dari setumpuk teknologi, atau beberapa orang yang terisolasi di satu lantai gedung. D&A harus menjadi denyut nadi organisasi, dimasukkan ke dalam semua keputusan penting di seluruh penjualan, pemasaran, rantai pasokan, pengalaman pelanggan, dan fungsi inti lainnya.” - Ulasan Bisnis Harvard
Gambar produk dapat menjadi bagian dari Kumpulan Data Gambar Google! Ada 8,4 objek per gambar rata-rata di beberapa dataset. Berikut adalah daftar dataset yang sering diperbarui.
Halaman dokumentasi Google menyertakan contoh JSON-LD untuk menerapkan schema.org/Dataset. Karena kumpulan data tubular masih dalam versi beta, praktik terbaik untuk deskripsi dan penggunaan kumpulan data akan muncul. Saat persyaratan kode berubah, lakukan audit SEO teknis untuk menemukan di mana pembaruan diperlukan.
Bagaimana cara mengunggah set data Produk dan Gambar ke Google BigQuery?
Google BigQuery (GBQ) mengizinkan pemasar penelusuran untuk mengumpulkan data dari berbagai sumber. Sebaiknya gunakan Google Merchant Center, Cloud Storage, BigQuery, atau Anda dapat menentukan data sebaris saat membuat permintaan. Sebelum Anda mengupload data apa pun, terlebih dahulu buat set data dan tabel di Google BigQuery yang menyertakan informasi produk Anda, termasuk detail gambar. ***
Kami lebih suka menggunakan format data JSON-LD item Produk. Berikut adalah contoh Objek Lengkap:
{
"name": "projects/[PROJECT_NUMBER]/locations/global/catalogs/default_catalog/branches/0/products/1234",
"id": "1234",
"categories": "Apparel & Accessories > Shoes",
"title": "ABC sneakers",
"description": "Sneakers for the rest of us",
"attributes": { "vendor": {"text": ["vendor123", "vendor456"]} },
"language_code": "en",
"tags": [ "black-friday" ],
"priceInfo": {"currencyCode": "USD", "price":100, "originalPrice":200, "cost": 50},
"availableTime": "2020-01-01T03:33:33.000001Z",
"availableQuantity": "1",
"uri":"http://foobar",
"images": [{"uri": "http://foobar/img1", "height": 320, "width": 320 }]
}
Selalu perbarui katalog Produk Anda. Google peduli dengan kualitas, dan Kecerdasan Buatannya membutuhkan data berkualitas tinggi untuk membuat prediksi berkualitas tinggi. Perhatikan produk yang tidak lagi dijual dan perbarui data di markup skema Produk e-Commerce situs Anda.
“Dataset tabular adalah yang diatur terutama dalam hal kisi baris dan kolom. Untuk laman yang menyematkan kumpulan data tabular, Anda juga dapat membuat markup yang lebih eksplisit, berdasarkan pendekatan dasar yang dijelaskan di atas. Saat ini kami memahami variasi CSVW (“CSV di Web”, lihat W3C), yang disediakan secara paralel dengan konten tabular berorientasi pengguna pada halaman HTML.”, dinyatakan pada 9.30.2019.
Pantau terus halaman dokumentasi Google untuk pembaruan jika properti yang terdaftar untuk Dataset, DataCatalog, atau DataDownload berubah. Dokumentasi saat ini telah memperbarui aspek organisasi; spesifikasi properti sekarang dikonsolidasikan di bawah jenis yang dimiliki masing-masing (sebelumnya mereka diatur secara tematis). Properti baru ini adalah salah satu cara untuk meningkatkan atribut situs web Anda.
Cara membuat dataset dari gambar untuk klasifikasi objek.
Dalam konsol manajemen klaster IBM, pilih (1) Beban Kerja, (2) Percikan, lalu (3) Pembelajaran Mendalam. **
* Klik pada tab "Dataset".
* Pilih “Baru”.
* Buat kumpulan data dari "Gambar untuk Klasifikasi Objek".
* Masukkan nama kumpulan data.
* Tunjukkan grup instance Spark mana yang Anda inginkan.
* Tentukan format penyimpanan gambar pilihan Anda (Kami lebih memilih TFRecords untuk TensorFlow).
* Jika TFRecords dipilih, navigasikan ke cara menghasilkan catatan, baik menurut pecahan atau kelas. Jika pecahan dipilih, masukkan nomor pecahan.
* Tentukan bagaimana gambar pelatihan dipilih.
Dengan mematuhi Pedoman Gambar Google dan persyaratan gambar AMP, produk Anda memiliki peluang yang lebih baik untuk muncul di cuplikan unggulan terkait produk.
Properti Data Terstruktur Kumpulan Data
Sungguh, ada beberapa properti yang dibutuhkan saat ini. Untuk mendorong penggunaannya, raksasa teknologi itu mungkin akan menerapkan strategi "tetap sederhana" dalam hal menyediakan konten yang ditujukan untuk konsumen data mesin. Tujuan akhirnya adalah memiliki kecocokan yang lebih banyak dan lebih baik di perpustakaan datanya untuk memenuhi maksud pencarian pengguna.
Properti yang diperlukan:
- nama
- deskripsi
Properti yang direkomendasikan:
- nama alternatif
- pencipta
- kutipan
- pengenal
- kata kunci
- lisensi
- sama dengan
- liputan spasial
- liputan sementara
- variabelDiukur
- Versi: kapan
- url
Anda mungkin belum memiliki kumpulan data yang dipublikasikan di web, tetapi pemasaran penelusuran dengan cepat bergerak ke arah yang lebih mendekati pendekatan ilmu data untuk penelusuran. Saat individu dan orang membuat semakin banyak kumpulan data yang dapat diakses, Pencarian Kumpulan Data akan meningkat. Yang mengejutkan adalah siapa pun yang memublikasikan data dapat mendeskripsikan kumpulan data mereka menggunakan standar terbuka schema.org untuk mendeskripsikan informasi.
Saat menguji data Anda di Laporan Indeks Search Console, bacalah bagian “Kesalahan dan Peringatan yang Diketahui”, “kesalahan atau peringatan di Alat Pengujian Data Terstruktur Google, dan sistem validasi Linter Data Terstruktur. Pekerjakan pakar implementasi data skema atau gunakan formulir untuk membantu menyaring peringatan apa yang dapat Anda biarkan dengan aman.
Karena ini berkaitan dengan penguraian konten web – terlepas dari apakah itu sudah berisi data terstruktur – yang terbaik adalah membuat data tersedia dalam format yang dipahami oleh persentase tertinggi dari konsumen data (terutama, mesin pencari).
Kumpulan Data Menyediakan Peta Jalan untuk Membangun Grafik Pengetahuan
Temukan temukan kumpulan data dan manfaatkan penelusuran akademis dari sumber data terbuka dan https schema.org.
Para peneliti menghargai kejelasan pada analisis tepat dari ilmu Data Global dan solusi pembelajaran mesin yang mengungkapkan dinamika pasar. Cari pemasar dengan pencarian untuk mengukur tren pemasaran berkelanjutan mengandalkan data besar untuk mendukung pertumbuhan pasar di masa depan. Setelah Google Dataset Search keluar dari versi beta, Google mungkin memiliki kemampuan baru untuk melakukan penelitian data yang dapat mengurangi risiko dan tantangan saat ini di depan bisnis. Penelitian ekstensif tentang detail dalam data Anda dapat meningkatkan pendekatan penjualan Anda.
Kami terus mencari pendekatan praktis untuk membangun grafik pengetahuan klien dan peluang untuk memanfaatkannya untuk aplikasi bisnis. Cobalah tangan Anda dalam hal ini.
Setelah Anda menggunakan skema kumpulan data di situs Anda, Anda akan menemukan laporan baru di GSC Anda di bawah penyempurnaan. Kami menggunakannya untuk meningkatkan strategi pemasaran konten seluler kami untuk pengguna yang datang dari beberapa perangkat.
Fitur Kumpulan Data dan Laporan Penyempurnaan Google baru
Seperti halnya implementasi data terstruktur lainnya, hanya karena Anda memasukkan data terstruktur skema, Anda menjadi memenuhi syarat . Namun, itu tidak menjamin untuk muncul di pencarian Google. Prioritaskan penggunaan kumpulan data yang mendukung penjualan dan laman landas ritel Anda.
Bersamaan dengan pengumuman fitur data terstruktur, laporan Penyempurnaan set data baru di Google Search Console muncul. Ini memberi tahu ahli strategi pemasaran penelusuran apakah Google telah mempelajari dan mengenali data terstruktur Anda untuk skema kumpulan data Anda atau belum. Baca dan perbaiki kesalahan data terstruktur apa pun setelah Anda memahami spesifikasi Dokumentasi Data Terstruktur Dataset. Ini akan memberi makan data Asisten Google Anda.
Beberapa pemilik bisnis atau pembuat konten memiliki waktu luang untuk memikirkan apakah metadata Anda diformat dengan benar. Namun itu harus memungkinkan GoogleBot merayapi situs Anda, menemukan data Anda, dan mengindeksnya. Untungnya, kami menyukainya dan ada di sudut Anda.
Izin Pembuatan Kumpulan Data
Izin build relevan untuk set data. Saat pengguna diberikan Izin Pembuatan, mereka dapat membuat konten baru pada kumpulan data yang ada. Ini umum untuk laporan, dasbor, ubin yang disematkan dari QandA, dan Insights Discovery. Mereka juga dapat membuat entri data baru pada kumpulan data di luar Power BI, biasanya lembar Excel melalui Analisis di Excel, XMLA, dan mengekspor data pokok. Ini membantu bisnis melakukan analisis pelanggan.
Meskipun deep learning baru dan komprehensif, Google dan mesin telusur lainnya masih menghadapi tantangan pengelolaan data yang muncul dalam konteks alur pembelajaran mesin yang diterapkan dalam produksi. Upaya baru untuk memahami kueri penelusuran semantik dimaksudkan untuk mendukung pemahaman, validasi, pembersihan, dan pengayaan data pelatihan. Dari sini, pertumbuhan sumber database terpercaya diharapkan akan berkembang dan lebih bermanfaat untuk mendorong lalu lintas toko.
Pemasaran Digital terikat oleh kebutuhan akan data dan penggunaannya sebagai pendekatan ilmiah.
“Alat pencarian seperti ini hanya sebagus metadata yang bersedia disediakan oleh penerbit data. Kami berharap banyak dari Anda menggunakan standar terbuka untuk mendeskripsikan data Anda, memungkinkan pengguna kami menemukan data yang mereka cari. Jika Anda memublikasikan data dan tidak melihatnya di hasil, kunjungi instruksi kami di situs pengembang kami yang juga menyertakan tautan untuk mengajukan pertanyaan dan memberikan umpan balik.” – Google *
“Kami dapat memahami data terstruktur di halaman Web tentang kumpulan data, baik menggunakan http://schema.org Markup Dataset, atau struktur setara yang diwakili dalam format Data Catalog Vocabulary (DCAT) W3C.” – Komentar Alan Morrison di Twitter
Ringkasan Skema Google Dataset
Menggunakan kumpulan data untuk melayani kebutuhan pengguna situs lebih terfokus pada pengalaman pengguna dan menambahkan entitas yang menjawab dan menginformasikan. Meskipun mungkin berasal dari komunitas ilmu data, bisnis apa pun dapat menggunakannya. Kami juga merekomendasikan untuk mencari masukan yang ditinjau sejawat dari pakar tingkat tinggi yang berpengalaman dalam markup data terstruktur untuk kumpulan data.
Hill Web Marketing sangat ingin berpartisipasi dalam prakarsa ini dan berharap dapat mendorong pembaca kami untuk memperluas jumlah kumpulan data yang tersedia saat ini. Meskipun mungkin berasal dari komunitas ilmu data, bisnis apa pun dapat menggunakannya.
Hubungi Jeannie Hill, pemilik Hill Web Marketing, ahli strategi pemasaran digital, untuk bermitra: 651-206-2410. Jadwalkan Konsultasi Anda untuk Mendapatkan Keunggulan Kompetitif
* https://arxiv.org/pdf/1908.07442.pdf
** https://www.ibm.com/support/knowledgecenter/SSWQ2D_1.1.0/us/create-dataset-image-object-classification.html
*** https://cloud.google.com/retail/recommendations-ai/docs/upload-catalog
**** https://www.blog.google/products/search/making-it-easier-discover-datasets/
***** https://storage.googleapis.com/pub-tools-public-publication-data/pdf/40761.pdf