
作為數據科學家需要了解的 13 個大數據工具
已發表: 2021-11-30在信息時代,數據中心收集了大量數據。 收集的數據來自各種來源,如金融交易、客戶互動、社交媒體和許多其他來源,更重要的是,積累速度更快。
數據可以是多樣化和敏感的,並且需要正確的工具來使其有意義,因為它具有使商業統計、信息和改變生活現代化的無限潛力。

大數據工具和數據科學家在這種情況下非常突出。
如此大量的多樣化數據使得使用 Excel 等傳統工具和技術難以處理。 Excel 並不是真正的數據庫,存儲數據有限制(65,536 行)。
Excel 中的數據分析顯示數據完整性較差。 從長遠來看,存儲在 Excel 中的數據安全性和合規性有限,災難恢復率非常低,並且沒有適當的版本控制。
為了處理如此龐大而多樣的數據集,需要一組獨特的工具,稱為數據工具,來檢查、處理和提取有價值的信息。 這些工具可讓您深入挖掘數據以找到更有意義的見解和數據模式。
處理如此復雜的技術工具和數據自然需要一套獨特的技能,這就是數據科學家在大數據中扮演重要角色的原因。
大數據工具的重要性
數據是任何組織的基石,用於提取有價值的信息、執行詳細分析、創造機會以及規劃新的業務里程碑和願景。
每天都會創建越來越多的數據,這些數據必須高效、安全地存儲,並在需要時進行調用。 這些數據的規模、種類和快速變化需要新的大數據工具、不同的存儲和分析方法。
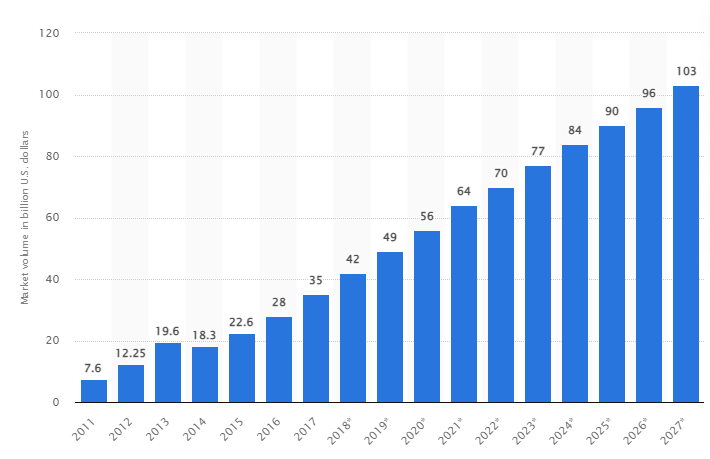
根據一項研究,到 2027 年,全球大數據市場預計將增長到 1030 億美元,是 2018 年市場規模的兩倍多。
當今的行業挑戰
“大數據”一詞最近被用來指代已經變得如此龐大以至於難以與傳統數據庫管理系統 (DBMS) 一起使用的數據集。
數據大小不斷增加,如今單個數據集中的數據范圍從數十兆字節 (TB) 到數 PB (PB)。 隨著時間的推移,這些數據集的大小超過了普通軟件處理、管理、搜索、共享和可視化的能力。
大數據的形成將導致:
- 質量管理與改進
- 供應鍊和效率管理
- 客戶情報
- 數據分析和決策
- 風險管理和欺詐檢測
在本節中,我們將探討最好的大數據工具,以及當公司希望進行更深入的分析以改善和發展業務時,數據科學家如何使用這些技術來過濾、分析、存儲和提取它們。
阿帕奇Hadoop
Apache Hadoop 是一個存儲和處理大量數據的開源 Java 平台。
Hadoop 通過映射大型數據集(從 TB 到 PB)、分析集群之間的任務並將它們分成更小的塊(64MB 到 128MB)來工作,從而加快數據處理速度。
為了存儲和處理數據,數據被發送到 Hadoop 集群,HDFS(Hadoop 分佈式文件系統)存儲數據,MapReduce 處理數據,YARN(Yet another resource negotiator)劃分任務和分配資源。
它適用於來自各種公司和組織的數據科學家、開發人員和分析師進行研究和生產。
特徵
- 數據複製:塊的多個副本存儲在不同的節點中,並在發生錯誤時起到容錯作用。
- 高度可擴展性:提供垂直和水平可擴展性
- 與其他 Apache 模型、Cloudera 和 Hortonworks 集成
考慮參加這個精彩的在線課程,使用 Apache Spark 學習大數據。
快速礦工
Rapidminer 網站聲稱,全球大約有 40,000 家組織使用他們的軟件來增加銷售額、降低成本和規避風險。
該軟件獲得了多個獎項:2021 年 Gartner Vision Awards 的數據科學和機器學習平台、多模式預測分析和機器學習解決方案,來自 Forrester 和 Crowd 在 2021 年春季 G2 報告中最用戶友好的機器學習和數據科學平台。
它是科學生命週期的端到端平台,無縫集成和優化以構建 ML(機器學習)模型。 它會自動記錄準備、建模和驗證的每一步,以實現完全透明。
它是一款付費軟件,提供三個版本:準備數據、創建和驗證以及部署模型。 教育機構甚至可以免費使用它,RapidMiner 被全球 4,000 多所大學使用。
特徵
- 它檢查數據以識別模式並修復質量問題
- 它使用具有 1500 多種算法的無代碼工作流設計器
- 將機器學習模型集成到現有的業務應用程序中
畫面
Tableau 提供了對平台進行可視化分析、解決問題以及授權人員和組織的靈活性。 它基於 VizQL 技術(數據庫查詢的可視化語言),通過直觀的用戶界面將拖放轉換為數據查詢。
Tableau 於 2019 年被 Salesforce 收購。它允許鏈接來自 SQL 數據庫、電子表格或 Google Analytics 和 Salesforce 等雲應用程序等來源的數據。
用戶可以根據業務或個人喜好購買其版本的 Creator、Explorer 和 Viewer,因為每個版本都有自己的特點和功能。
它是分析師、數據科學家、教育部門和業務用戶實施和平衡數據驅動文化並通過結果對其進行評估的理想選擇。
特徵
- 儀表板以可視元素、對象和文本的形式提供數據的完整概覽。
- 大量數據圖表選擇:直方圖、甘特圖、圖表、動態圖等等
- 行級過濾保護,保證數據安全穩定
- 其架構提供可預測的分析和預測
學習 Tableau 很容易。
雲時代
Cloudera 為大數據管理的雲和數據中心提供了一個安全平台。 它使用數據分析和機器學習將復雜的數據轉化為清晰、可操作的見解。
Cloudera 為數據科學家提供私有云和混合雲、數據工程、數據流、數據存儲、數據科學等方面的解決方案和工具。
統一平台和多功能分析增強了數據驅動的洞察發現過程。 它的數據科學提供與組織使用的任何系統的連接,不僅是 Cloudera 和 Hortonworks(兩家公司都有合作)。
數據科學家通過交互式數據科學工作表管理他們自己的活動,例如分析、計劃、監控和電子郵件通知。 默認情況下,它是一個安全兼容的平台,允許數據科學家訪問 Hadoop 數據並輕鬆運行 Spark 查詢。
該平台適用於醫院、金融機構、電信等各行各業的數據工程師、數據科學家和 IT 專業人員。
特徵
- 支持所有主要的私有云和公共雲,而數據科學工作台支持本地部署
- 自動化數據通道將數據轉換為可用的形式,並將它們與其他來源集成。
- 統一的工作流程允許快速的模型構建、培訓和實施。
- Hadoop 身份驗證、授權和加密的安全環境
阿帕奇蜂巢
Apache Hive 是一個在 Apache Hadoop 之上開發的開源項目。 它允許讀取、寫入和管理各種存儲庫中可用的大型數據集,並允許用戶組合自己的功能進行自定義分析。
Hive 專為傳統存儲任務而設計,不適用於在線處理任務。 其強大的批處理框架提供可擴展性、性能、可擴展性和容錯性。
它適用於數據提取、預測建模和索引文檔。 不推薦用於查詢實時數據,因為它會在獲取結果時引入延遲。
特徵
- 支持 MapReduce、Tez 和 Spark 計算引擎
- 處理龐大的數據集,數 PB 大小
- 與Java相比非常容易編碼
- 通過將數據存儲在 Apache Hadoop 分佈式文件系統中來提供容錯
阿帕奇風暴
Storm 是一個免費的開源平台,用於處理無限的數據流。 它提供了最小的處理單元集,用於開發可以實時處理大量數據的應用程序。
Storm 的速度足夠快,每個節點每秒可以處理一百萬個元組,並且易於操作。
Apache Storm 允許您向集群添加更多節點並提高應用程序處理能力。 在保持水平可擴展性的情況下,通過添加節點可以使處理能力翻倍。
數據科學家可以使用 Storm 進行 DRPC(分佈式遠程過程調用)、實時 ETL(檢索-轉換-負載)分析、持續計算、在線機器學習等。它的設置是為了滿足 Twitter 的實時處理需求、雅虎和 Flipboard。

特徵
- 易於使用任何編程語言
- 它被集成到每個排隊系統和每個數據庫中。
- Storm 使用 Zookeeper 管理集群並擴展到更大的集群規模
- 如果出現問題,有保證的數據保護會替換丟失的元組
雪花數據科學
數據科學家面臨的最大挑戰是準備來自不同資源的數據,因為檢索、整合、清理和準備數據需要花費最多的時間。 它由雪花解決。
它提供了一個單一的高性能平台,消除了由 ETL(負載轉換和提取)引起的麻煩和延遲。 它還可以與最新的機器學習 (ML) 工具和庫(例如 Dask 和 Saturn Cloud)集成。
Snowflake 為每個工作負載提供了獨特的專用計算集群架構來執行此類高級計算活動,因此數據科學和 BI(商業智能)工作負載之間沒有資源共享。
它支持結構化、半結構化(JSON、Avro、ORC、Parquet 或 XML)和非結構化數據的數據類型。 它使用數據湖策略來改進數據訪問、性能和安全性。
數據科學家和分析師在各個行業使用雪花,包括金融、媒體和娛樂、零售、健康和生命科學、技術和公共部門。
特徵
- 高數據壓縮以降低存儲成本
- 提供靜態和傳輸中的數據加密
- 運算複雜度低的快速處理引擎
- 具有表格、圖表和直方圖視圖的集成數據分析
數據機器人
Datarobot 是 AI(人工智能)雲計算領域的全球領導者。 其獨特的平台旨在服務於所有行業,包括用戶和不同類型的數據。
該公司聲稱該軟件被三分之一的財富 50 強公司使用,並為各個行業提供超過一萬億的估計。
Dataroabot 使用自動化機器學習 (ML),專為企業數據專業人員快速創建、調整和部署準確的預測模型而設計。
它使科學家可以輕鬆訪問許多具有完全透明性的最新機器學習算法,以自動化數據預處理。 該軟件為科學家開發了專用的 R 和 Python 客戶端,以解決複雜的數據科學問題。
它有助於自動化數據質量、特徵工程和實施過程,以簡化數據科學家的活動。 它是一種優質產品,價格可根據要求提供。
特徵
- 在盈利能力方面增加業務價值,簡化預測
- 實施流程和自動化
- 支持來自 Python、Spark、TensorFlow 和其他來源的算法。
- API 集成讓您可以從數百種模型中進行選擇
TensorFlow
TensorFlow 是一個基於社區 AI(人工智能)的庫,它使用數據流圖來構建、訓練和部署機器學習 (ML) 應用程序。 這允許開發人員創建大型分層神經網絡。
它包括三個模型——TensorFlow.js、TensorFlow Lite 和 TensorFlow Extended (TFX)。 它的 javascript 模式用於同時在瀏覽器和 Node.js 上訓練和部署模型。 它的 lite 模式用於在移動和嵌入式設備上部署模型,而 TFX 模型用於準備數據、驗證和部署模型。
由於其強大的平台,無論編程語言如何,它都可以部署在服務器、邊緣設備或網絡上。
TFX 包含強制執行 ML 管道的機制,這些管道可以提升並提供強大的整體性能職責。 Kubeflow 和 Apache Airflow 等數據工程管道支持 TFX。
Tensorflow 平台適合初學者。 中級和專家訓練生成對抗網絡以使用 Keras 生成手寫數字圖像。
特徵
- 可以在本地、雲端和瀏覽器中部署 ML 模型,無需考慮語言
- 使用固有 API 輕鬆構建模型,以實現快速模型重複
- 它的各種附加庫和模型支持研究活動進行實驗
- 使用多個抽象級別輕鬆構建模型
Matplotlib
Matplotlib 是一個綜合性的社區軟件,用於可視化 Python 編程語言的動畫數據和圖形圖形。 其獨特的設計是結構化的,因此使用幾行代碼即可生成可視數據圖。
有各種第三方應用程序,如繪圖程序、GUI、彩色地圖、動畫等等,旨在與 Matplotlib 集成。
它的功能可以通過許多工具進行擴展,例如 Basemap、Cartopy、GTK-Tools、Natgrid、Seaborn 等。
它的最佳功能包括使用結構化和非結構化數據繪製圖形和地圖。
比格
Bigml 是一個面向工程師、數據科學家、開發人員和分析師的集體透明平台。 它將端到端的數據轉換為可操作的模型。
它有效地創建、試驗、自動化和管理機器學習工作流,為各行各業的智能應用做出貢獻。
這個可編程的 ML(機器學習)平台有助於測序、時間序列預測、關聯檢測、回歸、聚類分析等。
其具有單個和多個租戶的完全可管理的版本以及適用於任何云提供商的一種可能的部署方式,使企業可以輕鬆地讓每個人都可以訪問大數據。
它的起價為 30 美元,可免費用於小型數據集和教育目的,並在 600 多所大學中使用。
由於其強大的工程 ML 算法,它適用於製藥、娛樂、汽車、航空航天、醫療保健、物聯網等各個行業。
特徵
- 在單個 API 調用中自動化耗時且複雜的工作流程。
- 它可以處理大量數據並執行並行任務
- 該庫受到 Python、Node.js、Ruby、Java、Swift 等流行編程語言的支持。
- 其精細的細節簡化了審計和監管要求的工作
阿帕奇星火
它是大公司廣泛使用的最大的開源引擎之一。 據該網站稱,80% 的財富 500 強公司都在使用 Spark。 它與大數據和機器學習的單節點和集群兼容。
它基於高級 SQL(結構化查詢語言)來支持大量數據並處理結構化表和非結構化數據。
Spark 平台以其易用性、龐大的社區和閃電般的速度而聞名。 開發人員使用 Spark 在 Java、Scala、Python、R 和 SQL 中構建應用程序和運行查詢。
特徵
- 批量和實時處理數據
- 無需下採樣即可支持大量 PB 級數據
- 它可以輕鬆地將 SQL、MLib、Graphx 和 Stream 等多個庫組合到一個工作流中。
- 適用於 Hadoop YARN、Apache Mesos、Kubernetes,甚至在雲中,並且可以訪問多個數據源
刀
Konstanz Information Miner 是一個直觀的數據科學應用開源平台。 數據科學家和分析師無需使用簡單的拖放功能進行編碼即可創建可視化工作流程。
服務器版是用於自動化、數據科學管理和管理分析的交易平台。 KNIME 使每個人都可以訪問數據科學工作流程和可重用組件。
特徵
- 高度靈活地集成來自 Oracle、SQL、Hive 等的數據
- 從 SharePoint、Amazon Cloud、Salesforce、Twitter 等多個來源訪問數據
- 機器學習的使用形式是模型構建、性能調優和模型驗證。
- 可視化、統計、處理和報告形式的數據洞察
大數據5V的重要性是什麼?
大數據的 5 V 幫助數據科學家理解和分析大數據以獲得更多見解。 它還有助於提供更多有助於企業做出明智決策並獲得競爭優勢的統計數據。
體積:大數據基於體積。 量子量決定了數據有多大。 通常包含以 TB、PB 等為單位的大量數據。數據科學家根據卷大小,為數據集分析計劃各種工具和集成。
速度:數據收集的速度至關重要,因為一些公司需要實時數據信息,而另一些公司更喜歡以數據包的形式處理數據。 數據流越快,數據科學家就越能評估並向公司提供相關信息。
多樣性:數據來自不同的來源,重要的是,不是固定格式。 數據有結構化(數據庫格式)、半結構化(XML/RDF)和非結構化(二進制數據)格式。 基於數據結構,大數據工具用於創建、組織、過濾和處理數據。
準確性:數據準確性和可信來源定義了大數據上下文。 數據集來自各種來源,例如計算機、網絡設備、移動設備、社交媒體等。因此,必須對數據進行分析才能將其發送到其目的地。
價值:最後,一個公司的大數據值多少錢? 數據科學家的角色是充分利用數據來展示數據洞察力如何為企業增加價值。
結論
上面的大數據列表包括付費工具和開源工具。 為每個工具提供了簡要信息和功能。 如果您正在尋找描述性信息,您可以訪問相關網站。
希望獲得競爭優勢的公司使用大數據和相關工具,如 AI(人工智能)、ML(機器學習)和其他技術,採取戰術行動來改善客戶服務、研究、營銷、未來規劃等。
大多數行業都使用大數據工具,因為生產力的微小變化可以轉化為顯著的節省和巨額利潤。 我們希望上面的文章能讓您大致了解大數據工具及其意義。
你也許也喜歡:
學習數據工程基礎知識的在線課程。