
13 strumenti per i big data da conoscere come data scientist
Pubblicato: 2021-11-30Nell'era dell'informazione, i data center raccolgono grandi quantità di dati. I dati raccolti provengono da varie fonti come transazioni finanziarie, interazioni con i clienti, social media e molte altre fonti e, soprattutto, si accumulano più velocemente.
I dati possono essere diversi e sensibili e richiedono gli strumenti giusti per renderli significativi poiché hanno un potenziale illimitato per modernizzare le statistiche aziendali, le informazioni e cambiare la vita.

Gli strumenti per i Big Data e gli scienziati dei dati sono importanti in tali scenari.
Una quantità così grande di dati diversi rende difficile l'elaborazione utilizzando strumenti e tecniche tradizionali come Excel. Excel non è in realtà un database e ha un limite (65.536 righe) per la memorizzazione dei dati.
L'analisi dei dati in Excel mostra una scarsa integrità dei dati. A lungo termine, i dati archiviati in Excel presentano sicurezza e conformità limitate, tassi di ripristino di emergenza molto bassi e nessun controllo della versione adeguato.
Per elaborare insiemi di dati così grandi e diversificati, è necessario un insieme unico di strumenti, chiamati strumenti di dati, per esaminare, elaborare ed estrarre informazioni preziose. Questi strumenti ti consentono di approfondire i tuoi dati per trovare informazioni e modelli di dati più significativi.
La gestione di strumenti tecnologici e dati così complessi richiede naturalmente un set di competenze unico, ed è per questo che il data scientist gioca un ruolo fondamentale nei big data.
L'importanza degli strumenti per i big data
I dati sono l'elemento costitutivo di qualsiasi organizzazione e vengono utilizzati per estrarre informazioni preziose, eseguire analisi dettagliate, creare opportunità e pianificare nuovi traguardi e visioni aziendali.
Ogni giorno vengono creati sempre più dati che devono essere archiviati in modo efficiente e sicuro e richiamati quando necessario. La dimensione, la varietà e il rapido cambiamento di tali dati richiedono nuovi strumenti per i big data, diversi metodi di archiviazione e analisi.
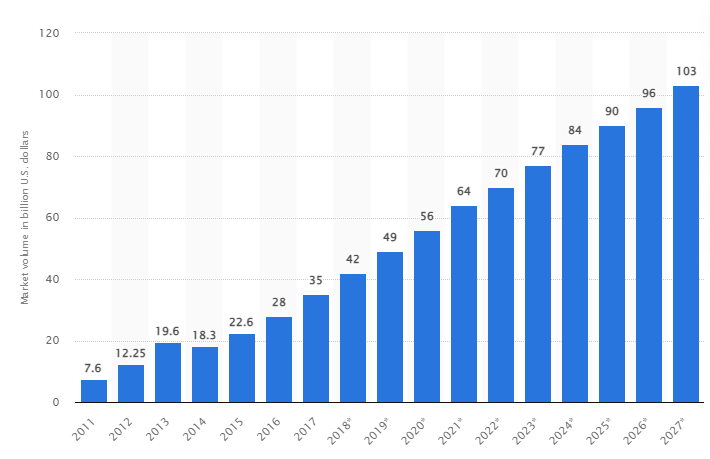
Secondo uno studio, il mercato globale dei big data dovrebbe crescere fino a raggiungere i 103 miliardi di dollari entro il 2027, più del doppio delle dimensioni del mercato previste nel 2018.
Le sfide del settore di oggi
Il termine "big data" è stato recentemente utilizzato per riferirsi a set di dati che sono diventati così grandi da essere difficili da utilizzare con i tradizionali sistemi di gestione di database (DBMS).
Le dimensioni dei dati sono in costante aumento e oggi vanno da decine di terabyte (TB) a molti petabyte (PB) in un unico set di dati. La dimensione di questi set di dati supera la capacità del software comune di elaborare, gestire, cercare, condividere e visualizzare nel tempo.
La formazione di big data porterà a quanto segue:
- Gestione e miglioramento della qualità
- Supply chain e gestione dell'efficienza
- Intelligenza del cliente
- Analisi dei dati e processo decisionale
- Gestione del rischio e rilevamento delle frodi
In questa sezione, esaminiamo i migliori strumenti per big data e come i data scientist utilizzano queste tecnologie per filtrarli, analizzarli, archiviarli ed estrarli quando le aziende desiderano un'analisi più approfondita per migliorare e far crescere il proprio business.
Apache Hadoop
Apache Hadoop è una piattaforma Java open source che archivia ed elabora grandi quantità di dati.
Hadoop funziona mappando grandi set di dati (da terabyte a petabyte), analizzando le attività tra i cluster e suddividendoli in blocchi più piccoli (da 64 MB a 128 MB), con conseguente elaborazione dei dati più rapida.
Per archiviare ed elaborare i dati, i dati vengono inviati al cluster Hadoop, HDFS (Hadoop ha distribuito file system) archivia i dati, MapReduce elabora i dati e YARN (Yet Another Resource Negotiator) divide le attività e assegna le risorse.
È adatto a data scientist, sviluppatori e analisti di varie aziende e organizzazioni per la ricerca e la produzione.
Caratteristiche
- Replica dei dati: più copie del blocco sono memorizzate in nodi diversi e fungono da tolleranza agli errori in caso di errore.
- Altamente scalabile: offre scalabilità verticale e orizzontale
- Integrazione con altri modelli Apache, Cloudera e Hortonworks
Prendi in considerazione questo brillante corso online per imparare i Big Data con Apache Spark.
Minatore rapido
Il sito Web di Rapidminer afferma che circa 40.000 organizzazioni in tutto il mondo utilizzano il loro software per aumentare le vendite, ridurre i costi ed evitare rischi.
Il software ha ricevuto numerosi premi: Gartner Vision Awards 2021 per le piattaforme di data science e machine learning, analisi predittiva multimodale e soluzioni di machine learning dalla piattaforma di machine learning e data science più intuitiva di Forrester e Crowd nel report G2 di primavera 2021.
È una piattaforma end-to-end per il ciclo di vita scientifico ed è perfettamente integrata e ottimizzata per la creazione di modelli ML (machine learning). Documenta automaticamente ogni fase di preparazione, modellazione e convalida per la massima trasparenza.
È un software a pagamento disponibile in tre versioni: Prep Data, Create and Validate e Deploy Model. È anche disponibile gratuitamente per le istituzioni educative e RapidMiner è utilizzato da oltre 4.000 università in tutto il mondo.
Caratteristiche
- Controlla i dati per identificare i modelli e risolvere i problemi di qualità
- Utilizza un designer di flussi di lavoro senza codice con oltre 1500 algoritmi
- Integrazione di modelli di machine learning nelle applicazioni aziendali esistenti
Tavolo
Tableau offre la flessibilità per analizzare visivamente le piattaforme, risolvere problemi e responsabilizzare persone e organizzazioni. Si basa sulla tecnologia VizQL (linguaggio visivo per le query di database), che converte il drag and drop in query di dati attraverso un'interfaccia utente intuitiva.
Tableau è stato acquisito da Salesforce nel 2019. Consente di collegare dati da origini come database SQL, fogli di calcolo o applicazioni cloud come Google Analytics e Salesforce.
Gli utenti possono acquistare le sue versioni Creator, Explorer e Viewer in base alle preferenze aziendali o individuali poiché ognuna ha le proprie caratteristiche e funzioni.
È l'ideale per analisti, data scientist, settore dell'istruzione e utenti aziendali per implementare e bilanciare una cultura basata sui dati e valutarla attraverso i risultati.
Caratteristiche
- I dashboard forniscono una panoramica completa dei dati sotto forma di elementi visivi, oggetti e testo.
- Ampia selezione di grafici di dati: istogrammi, diagrammi di Gantt, grafici, grafici di movimento e molti altri
- Protezione del filtro a livello di riga per mantenere i dati sicuri e stabili
- La sua architettura offre analisi e previsioni prevedibili
Imparare Tableau è facile.
Cloudera
Cloudera offre una piattaforma sicura per cloud e data center per la gestione dei big data. Utilizza l'analisi dei dati e l'apprendimento automatico per trasformare dati complessi in informazioni chiare e fruibili.
Cloudera offre soluzioni e strumenti per cloud privati e ibridi, ingegneria dei dati, flusso di dati, archiviazione dei dati, scienza dei dati per i data scientist e altro ancora.
Una piattaforma unificata e un'analisi multifunzionale migliorano il processo di individuazione delle informazioni basate sui dati. La sua data science fornisce connettività a qualsiasi sistema utilizzato dall'organizzazione, non solo Cloudera e Hortonworks (entrambe le società hanno collaborato).
I data scientist gestiscono le proprie attività come analisi, pianificazione, monitoraggio e notifiche e-mail tramite fogli di lavoro interattivi di data science. Per impostazione predefinita, è una piattaforma conforme alla sicurezza che consente ai data scientist di accedere ai dati Hadoop ed eseguire facilmente query Spark.
La piattaforma è adatta a ingegneri di dati, scienziati di dati e professionisti IT in vari settori come ospedali, istituzioni finanziarie, telecomunicazioni e molti altri.
Caratteristiche
- Supporta tutti i principali cloud privati e pubblici, mentre il workbench di Data Science supporta le distribuzioni in locale
- I canali dati automatizzati convertono i dati in moduli utilizzabili e li integrano con altre fonti.
- Un flusso di lavoro uniforme consente una rapida costruzione, formazione e implementazione del modello.
- Ambiente sicuro per autenticazione, autorizzazione e crittografia Hadoop
Alveare di Apache
Apache Hive è un progetto open source sviluppato su Apache Hadoop. Consente di leggere, scrivere e gestire grandi set di dati disponibili in vari repository e consente agli utenti di combinare le proprie funzioni per analisi personalizzate.
Hive è progettato per le attività di archiviazione tradizionali e non per le attività di elaborazione online. I suoi robusti frame batch offrono scalabilità, prestazioni, scalabilità e tolleranza agli errori.
È adatto per l'estrazione di dati, la modellazione predittiva e l'indicizzazione di documenti. Non consigliato per eseguire query sui dati in tempo reale poiché introduce latenza nell'ottenimento dei risultati.
Caratteristiche
- Supporta il motore di calcolo MapReduce, Tez e Spark
- Elabora enormi set di dati, di dimensioni di diversi petabyte
- Molto facile da codificare rispetto a Java
- Fornisce tolleranza agli errori memorizzando i dati nel file system distribuito Apache Hadoop
Tempesta Apache
The Storm è una piattaforma open source gratuita utilizzata per elaborare flussi di dati illimitati. Fornisce il più piccolo insieme di unità di elaborazione utilizzate per sviluppare applicazioni in grado di elaborare grandi quantità di dati in tempo reale.
Una tempesta è abbastanza veloce da elaborare un milione di tuple al secondo per nodo ed è facile da usare.
Apache Storm ti consente di aggiungere più nodi al tuo cluster e aumentare la potenza di elaborazione delle applicazioni. La capacità di elaborazione può essere raddoppiata aggiungendo nodi man mano che viene mantenuta la scalabilità orizzontale.
I data scientist possono utilizzare Storm per DRPC (Distributed Remote Procedure Calls), analisi ETL (Retrieval-Conversion-Load) in tempo reale, calcolo continuo, apprendimento automatico online, ecc. È configurato per soddisfare le esigenze di elaborazione in tempo reale di Twitter , Yahoo e Flipboard.
Caratteristiche
- Facile da usare con qualsiasi linguaggio di programmazione
- È integrato in ogni sistema di accodamento e in ogni database.
- Storm utilizza Zookeeper per gestire i cluster e scalare a dimensioni di cluster più grandi
- La protezione dei dati garantita sostituisce le tuple perse se qualcosa va storto
Scienza dei dati del fiocco di neve
La sfida più grande per i data scientist è la preparazione dei dati da diverse risorse, poiché viene impiegato il massimo del tempo per recuperare, consolidare, pulire e preparare i dati. È affrontato da Snowflake.

Offre un'unica piattaforma ad alte prestazioni che elimina i problemi e i ritardi causati da ETL (Load Transformation and Extraction). Può anche essere integrato con gli strumenti e le librerie di machine learning (ML) più recenti come Dask e Saturn Cloud.
Snowflake offre un'architettura unica di cluster di calcolo dedicati per ogni carico di lavoro per eseguire attività di elaborazione di alto livello, quindi non c'è condivisione di risorse tra data science e carichi di lavoro BI (business intelligence).
Supporta tipi di dati da dati strutturati, semi-strutturati (JSON, Avro, ORC, Parquet o XML) e non strutturati. Utilizza una strategia di data lake per migliorare l'accesso ai dati, le prestazioni e la sicurezza.
Data scientist e analisti utilizzano i fiocchi di neve in vari settori, tra cui finanza, media e intrattenimento, vendita al dettaglio, salute e scienze della vita, tecnologia e settore pubblico.
Caratteristiche
- Elevata compressione dei dati per ridurre i costi di archiviazione
- Fornisce la crittografia dei dati inattivi e in transito
- Motore di elaborazione veloce con bassa complessità operativa
- Profilazione dei dati integrata con viste di tabelle, grafici e istogrammi
Datarobot
Datarobot è leader mondiale nel cloud con AI (Artificial Intelligence). La sua piattaforma unica è progettata per servire tutti i settori, inclusi utenti e diversi tipi di dati.
La società afferma che il software è utilizzato da un terzo delle società Fortune 50 e fornisce oltre un trilione di stime in vari settori.
Dataroabot utilizza il machine learning (ML) automatizzato ed è progettato per i professionisti dei dati aziendali per creare, adattare e distribuire rapidamente modelli di previsione accurati.
Offre agli scienziati un facile accesso a molti dei più recenti algoritmi di apprendimento automatico con completa trasparenza per automatizzare la preelaborazione dei dati. Il software ha sviluppato client R e Python dedicati per consentire agli scienziati di risolvere problemi complessi di scienza dei dati.
Aiuta ad automatizzare la qualità dei dati, l'ingegneria delle funzionalità e i processi di implementazione per facilitare le attività dei data scientist. È un prodotto premium e il prezzo è disponibile su richiesta.
Caratteristiche
- Aumenta il valore aziendale in termini di redditività, previsione semplificata
- Processi di implementazione e automazione
- Supporta algoritmi da Python, Spark, TensorFlow e altre fonti.
- L'integrazione API ti consente di scegliere tra centinaia di modelli
TensorFlow
TensorFlow è una libreria basata sull'intelligenza artificiale (intelligenza artificiale) della comunità che utilizza diagrammi di flusso di dati per creare, addestrare e distribuire applicazioni di machine learning (ML). Ciò consente agli sviluppatori di creare reti neurali a più livelli di grandi dimensioni.
Include tre modelli: TensorFlow.js, TensorFlow Lite e TensorFlow Extended (TFX). La sua modalità javascript viene utilizzata per il training e la distribuzione di modelli nel browser e su Node.js contemporaneamente. La sua modalità lite è per la distribuzione di modelli su dispositivi mobili e incorporati e il modello TFX è per la preparazione dei dati, la convalida e la distribuzione di modelli.
Grazie alla sua solida piattaforma, può essere distribuito su server, dispositivi perimetrali o sul Web indipendentemente dal linguaggio di programmazione.
TFX contiene meccanismi per rafforzare le pipeline di ML che possono essere ascendenti e fornire solide prestazioni complessive. Le pipeline di ingegneria dei dati come Kubeflow e Apache Airflow supportano TFX.
La piattaforma Tensorflow è adatta per i principianti. Intermedio e per esperti per formare una rete contraddittoria generativa per generare immagini di cifre scritte a mano utilizzando Keras.
Caratteristiche
- Può distribuire modelli di machine learning in locale, nel cloud e nel browser e indipendentemente dalla lingua
- Facile creazione di modelli utilizzando API innate per una rapida ripetizione del modello
- Le sue varie librerie e modelli aggiuntivi supportano le attività di ricerca da sperimentare
- Facile costruzione di modelli utilizzando più livelli di astrazione
Matplotlib
Matplotlib è un software comunitario completo per la visualizzazione di dati animati e grafica grafica per il linguaggio di programmazione Python. Il suo design unico è strutturato in modo da generare un grafico di dati visivi utilizzando poche righe di codice.
Esistono varie applicazioni di terze parti come programmi di disegno, GUI, mappe dei colori, animazioni e molte altre progettate per essere integrate con Matplotlib.
La sua funzionalità può essere estesa con molti strumenti come Basemap, Cartopy, GTK-Tools, Natgrid, Seaborn e altri.
Le sue migliori caratteristiche includono il disegno di grafici e mappe con dati strutturati e non strutturati.
Bigml
Bigml è una piattaforma collettiva e trasparente per ingegneri, data scientist, sviluppatori e analisti. Esegue la trasformazione dei dati end-to-end in modelli utilizzabili.
Crea, sperimenta, automatizza e gestisce in modo efficace flussi di lavoro ml, contribuendo ad applicazioni intelligenti in un'ampia gamma di settori.
Questa piattaforma ML programmabile (apprendimento automatico) aiuta con il sequenziamento, la previsione di serie temporali, il rilevamento di associazioni, la regressione, l'analisi dei cluster e altro ancora.
La sua versione completamente gestibile con tenant singoli e multipli e una possibile implementazione per qualsiasi provider cloud rende facile per le aziende consentire a tutti l'accesso ai big data.
Il suo prezzo parte da $ 30 ed è gratuito per piccoli set di dati e scopi educativi ed è utilizzato in oltre 600 università.
Grazie ai suoi robusti algoritmi ML ingegnerizzati, è adatto in vari settori come farmaceutico, dell'intrattenimento, automobilistico, aerospaziale, sanitario, IoT e molti altri.
Caratteristiche
- Automatizza flussi di lavoro complessi e dispendiosi in termini di tempo in un'unica chiamata API.
- Può elaborare grandi quantità di dati ed eseguire attività parallele
- La libreria è supportata da popolari linguaggi di programmazione come Python, Node.js, Ruby, Java, Swift, ecc.
- I suoi dettagli granulari facilitano il lavoro di revisione e requisiti normativi
Apache Scintilla
È uno dei più grandi motori open source ampiamente utilizzati dalle grandi aziende. Spark è utilizzato dall'80% delle aziende Fortune 500, secondo il sito web. È compatibile con nodi singoli e cluster per big data e ML.
Si basa su SQL avanzato (Structured Query Language) per supportare grandi quantità di dati e lavorare con tabelle strutturate e dati non strutturati.
La piattaforma Spark è nota per la sua facilità d'uso, la vasta community e la velocità della luce. Gli sviluppatori utilizzano Spark per creare applicazioni ed eseguire query in Java, Scala, Python, R e SQL.
Caratteristiche
- Elabora i dati in batch e in tempo reale
- Supporta grandi quantità di petabyte di dati senza downsampling
- Semplifica la combinazione di più librerie come SQL, MLib, Graphx e Stream in un unico flusso di lavoro.
- Funziona su Hadoop YARN, Apache Mesos, Kubernetes e persino nel cloud e ha accesso a più origini dati
Coltello
Konstanz Information Miner è una piattaforma open source intuitiva per applicazioni di data science. Un data scientist e un analista possono creare flussi di lavoro visivi senza codificare con una semplice funzionalità di trascinamento della selezione.
La versione server è una piattaforma di trading utilizzata per l'automazione, la gestione della scienza dei dati e l'analisi della gestione. KNIME rende i flussi di lavoro di data science e i componenti riutilizzabili accessibili a tutti.
Caratteristiche
- Altamente flessibile per l'integrazione dei dati da Oracle, SQL, Hive e altro
- Accedi ai dati da più origini come SharePoint, Amazon Cloud, Salesforce, Twitter e altro ancora
- L'uso di ml è sotto forma di costruzione di modelli, ottimizzazione delle prestazioni e convalida del modello.
- Insight sui dati sotto forma di visualizzazione, statistiche, elaborazione e reporting
Qual è l'importanza delle 5 V dei big data?
Le 5 V dei big data aiutano i data scientist a comprendere e analizzare i big data per ottenere maggiori informazioni. Aiuta anche a fornire più statistiche utili alle aziende per prendere decisioni informate e ottenere un vantaggio competitivo.
Volume: i big data si basano sul volume. Il volume quantico determina quanto sono grandi i dati. Di solito contiene una grande quantità di dati in terabyte, petabyte, ecc. In base alla dimensione del volume, i data scientist pianificano vari strumenti e integrazioni per l'analisi dei set di dati.
Velocità: la velocità di raccolta dei dati è fondamentale perché alcune aziende richiedono informazioni sui dati in tempo reale e altre preferiscono elaborare i dati in pacchetti. Più veloce è il flusso di dati, più data scientist possono valutare e fornire informazioni rilevanti all'azienda.
Varietà: i dati provengono da fonti diverse e, soprattutto, non in un formato fisso. I dati sono disponibili in formato strutturato (formato database), semistrutturato (XML/RDF) e non strutturato (dati binari). Basati su strutture di dati, gli strumenti Big Data vengono utilizzati per creare, organizzare, filtrare ed elaborare i dati.
Vericità: l'accuratezza dei dati e le fonti credibili definiscono il contesto dei big data. Il set di dati proviene da varie fonti come computer, dispositivi di rete, dispositivi mobili, social media, ecc. Di conseguenza, i dati devono essere analizzati per essere inviati a destinazione.
Valore: infine, quanto valgono i big data di un'azienda? Il ruolo del data scientist è quello di utilizzare al meglio i dati per dimostrare in che modo le informazioni dettagliate sui dati possono aggiungere valore a un'azienda.
Conclusione
L'elenco dei big data sopra include gli strumenti a pagamento e gli strumenti open source. Brevi informazioni e funzioni sono fornite per ogni strumento. Se stai cercando informazioni descrittive, puoi visitare i siti Web pertinenti.
Le aziende che cercano di ottenere un vantaggio competitivo utilizzano big data e strumenti correlati come AI (intelligenza artificiale), ML (apprendimento automatico) e altre tecnologie per intraprendere azioni tattiche per migliorare il servizio clienti, la ricerca, il marketing, la pianificazione futura, ecc.
Gli strumenti per i big data sono utilizzati nella maggior parte dei settori poiché piccoli cambiamenti nella produttività possono tradursi in risparmi significativi e grandi profitti. Ci auguriamo che l'articolo sopra ti abbia fornito una panoramica degli strumenti per i big data e del loro significato.
Potrebbe piacerti anche:
Corsi online per apprendere le basi della Data Engineering.