
13 Alat Data Besar yang Perlu Diketahui sebagai Ilmuwan Data
Diterbitkan: 2021-11-30Di era informasi, pusat data mengumpulkan data dalam jumlah besar. Data yang dikumpulkan berasal dari berbagai sumber seperti transaksi keuangan, interaksi pelanggan, media sosial, dan banyak sumber lainnya, dan yang lebih penting, terakumulasi lebih cepat.
Data dapat beragam dan sensitif serta memerlukan alat yang tepat untuk menjadikannya bermakna karena memiliki potensi tak terbatas untuk memodernisasi statistik bisnis, informasi, dan mengubah kehidupan.

Alat Big Data dan ilmuwan Data menonjol dalam skenario seperti itu.
Sejumlah besar data yang beragam membuatnya sulit untuk diproses menggunakan alat dan teknik tradisional seperti Excel. Excel sebenarnya bukan database dan memiliki batas (65.536 baris) untuk menyimpan data.
Analisis data di Excel menunjukkan integritas data yang buruk. Dalam jangka panjang, data yang disimpan di Excel memiliki keamanan dan kepatuhan yang terbatas, tingkat pemulihan bencana yang sangat rendah, dan tidak ada kontrol versi yang tepat.
Untuk memproses kumpulan data yang begitu besar dan beragam, seperangkat alat unik, yang disebut alat data, diperlukan untuk memeriksa, memproses, dan mengekstrak informasi berharga. Alat ini memungkinkan Anda menggali data lebih dalam untuk menemukan wawasan dan pola data yang lebih bermakna.
Berurusan dengan alat teknologi dan data yang kompleks seperti itu secara alami membutuhkan keahlian yang unik, dan itulah mengapa ilmuwan data memainkan peran penting dalam data besar.
Pentingnya alat data besar
Data adalah blok bangunan organisasi mana pun dan digunakan untuk mengekstrak informasi berharga, melakukan analisis terperinci, menciptakan peluang, dan merencanakan pencapaian dan visi bisnis baru.
Semakin banyak data dibuat setiap hari yang harus disimpan secara efisien dan aman dan dipanggil kembali saat dibutuhkan. Ukuran, variasi, dan perubahan cepat dari data tersebut memerlukan alat data besar yang baru, penyimpanan yang berbeda, dan metode analisis.
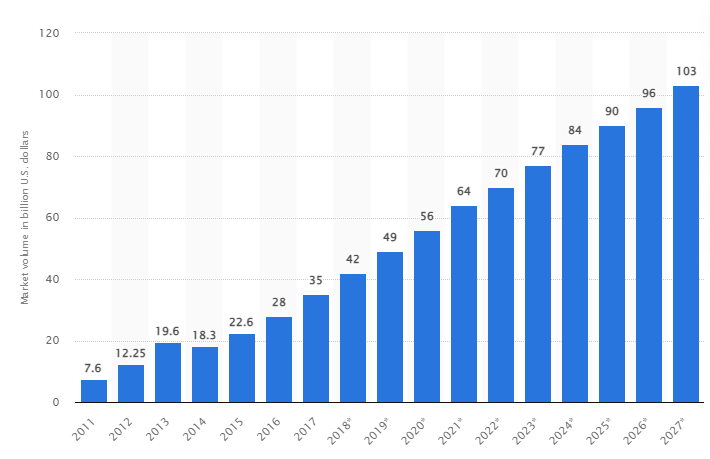
Menurut sebuah penelitian, pasar data besar global diperkirakan akan tumbuh menjadi US$103 miliar pada tahun 2027, lebih dari dua kali lipat ukuran pasar yang diharapkan pada tahun 2018.
Tantangan industri saat ini
Istilah "data besar" baru-baru ini digunakan untuk merujuk pada kumpulan data yang telah tumbuh begitu besar sehingga sulit digunakan dengan sistem manajemen basis data tradisional (DBMS).
Ukuran data terus meningkat dan saat ini berkisar dari puluhan terabyte (TB) hingga banyak petabyte (PB) dalam satu kumpulan data. Ukuran kumpulan data ini melebihi kemampuan perangkat lunak umum untuk memproses, mengelola, mencari, membagikan, dan memvisualisasikan dari waktu ke waktu.
Terbentuknya big data akan mengarah pada hal-hal berikut:
- Manajemen dan peningkatan kualitas
- Rantai pasokan dan manajemen efisiensi
- Kecerdasan pelanggan
- Analisis data dan pengambilan keputusan
- Manajemen risiko dan deteksi penipuan
Di bagian ini, kita melihat alat big data terbaik dan bagaimana ilmuwan data menggunakan teknologi ini untuk memfilter, menganalisis, menyimpan, dan mengekstraknya ketika perusahaan menginginkan analisis yang lebih dalam untuk meningkatkan dan mengembangkan bisnis mereka.
Apache Hadoop
Apache Hadoop adalah platform Java open-source yang menyimpan dan memproses data dalam jumlah besar.
Hadoop bekerja dengan memetakan kumpulan data besar (dari terabyte hingga petabyte), menganalisis tugas antar cluster, dan memecahnya menjadi potongan yang lebih kecil (64MB hingga 128MB), menghasilkan pemrosesan data yang lebih cepat.
Untuk menyimpan dan memproses data, data dikirim ke cluster Hadoop, HDFS (Hadoop distributed file system) menyimpan data, MapReduce memproses data, dan YARN (Yet another resource negotiator) membagi tugas dan menetapkan sumber daya.
Sangat cocok untuk ilmuwan data, pengembang, dan analis dari berbagai perusahaan dan organisasi untuk penelitian dan produksi.
Fitur
- Replikasi data: Beberapa salinan blok disimpan di node yang berbeda dan berfungsi sebagai toleransi kesalahan jika terjadi kesalahan.
- Sangat Terukur: Menawarkan skalabilitas vertikal dan horizontal
- Integrasi dengan model Apache lainnya, Cloudera dan Hortonworks
Pertimbangkan untuk mengikuti kursus online yang brilian ini untuk mempelajari Big Data dengan Apache Spark.
Rapidminer
Situs web Rapidminer mengklaim bahwa sekitar 40.000 organisasi di seluruh dunia menggunakan perangkat lunak mereka untuk meningkatkan penjualan, mengurangi biaya, dan menghindari risiko.
Perangkat lunak ini telah menerima beberapa penghargaan: Gartner Vision Awards 2021 untuk ilmu data dan platform pembelajaran mesin, analitik prediktif multimodal, dan solusi pembelajaran mesin dari platform pembelajaran mesin dan ilmu data paling ramah pengguna Forrester dan Crowd dalam laporan musim semi G2 2021.
Ini adalah platform ujung ke ujung untuk siklus hidup ilmiah dan terintegrasi dengan mulus serta dioptimalkan untuk membangun model ML (pembelajaran mesin). Ini secara otomatis mendokumentasikan setiap langkah persiapan, pemodelan, dan validasi untuk transparansi penuh.
Ini adalah perangkat lunak berbayar yang tersedia dalam tiga versi: Prep Data, Create and Validate, dan Deploy Model. Bahkan tersedia gratis untuk institusi pendidikan, dan RapidMiner digunakan oleh lebih dari 4.000 universitas di seluruh dunia.
Fitur
- Ini memeriksa data untuk mengidentifikasi pola dan memperbaiki masalah kualitas
- Ini menggunakan perancang alur kerja tanpa kode dengan 1500+ algoritme
- Mengintegrasikan model pembelajaran mesin ke dalam aplikasi bisnis yang ada
Tablo
Tableau memberikan fleksibilitas untuk menganalisis platform secara visual, memecahkan masalah, dan memberdayakan orang dan organisasi. Ini didasarkan pada teknologi VizQL (bahasa visual untuk kueri basis data), yang mengubah seret dan lepas menjadi kueri data melalui antarmuka pengguna yang intuitif.
Tableau diakuisisi oleh Salesforce pada tahun 2019. Ini memungkinkan penautan data dari sumber seperti database SQL, spreadsheet, atau aplikasi cloud seperti Google Analytics dan Salesforce.
Pengguna dapat membeli versi Creator, Explorer, dan Viewer berdasarkan preferensi bisnis atau individu karena masing-masing memiliki karakteristik dan fungsinya sendiri.
Ini sangat ideal bagi analis, ilmuwan data, sektor pendidikan, dan pengguna bisnis untuk menerapkan dan menyeimbangkan budaya berbasis data dan mengevaluasinya melalui hasil.
Fitur
- Dashboard memberikan gambaran lengkap tentang data berupa elemen visual, objek, dan teks.
- Banyak pilihan bagan data: histogram, bagan Gantt, bagan, bagan gerak, dan banyak lagi lainnya
- Perlindungan filter tingkat baris untuk menjaga data tetap aman dan stabil
- Arsitekturnya menawarkan analisis dan perkiraan yang dapat diprediksi
Belajar Tableau itu mudah.
Cloudera
Cloudera menawarkan platform yang aman untuk cloud dan pusat data untuk manajemen data besar. Ini menggunakan analitik data dan pembelajaran mesin untuk mengubah data kompleks menjadi wawasan yang jelas dan dapat ditindaklanjuti.
Cloudera menawarkan solusi dan alat untuk cloud pribadi dan hybrid, rekayasa data, aliran data, penyimpanan data, ilmu data untuk ilmuwan data, dan banyak lagi.
Platform terpadu dan analitik multifungsi meningkatkan proses penemuan wawasan berbasis data. Ilmu datanya menyediakan konektivitas ke sistem apa pun yang digunakan organisasi, tidak hanya Cloudera dan Hortonworks (kedua perusahaan telah bermitra).
Ilmuwan data mengelola aktivitas mereka sendiri seperti analisis, perencanaan, pemantauan, dan pemberitahuan email melalui lembar kerja ilmu data interaktif. Secara default, ini adalah platform yang sesuai dengan keamanan yang memungkinkan ilmuwan data mengakses data Hadoop dan menjalankan kueri Spark dengan mudah.
Platform ini cocok untuk para insinyur data, ilmuwan data, dan profesional TI di berbagai industri seperti rumah sakit, lembaga keuangan, telekomunikasi, dan banyak lainnya.
Fitur
- Mendukung semua cloud pribadi dan publik utama, sedangkan meja kerja Ilmu data mendukung penerapan di tempat
- Saluran data otomatis mengubah data menjadi bentuk yang dapat digunakan dan mengintegrasikannya dengan sumber lain.
- Alur kerja yang seragam memungkinkan konstruksi, pelatihan, dan implementasi model yang cepat.
- Lingkungan aman untuk otentikasi, otorisasi, dan enkripsi Hadoop
Sarang Apache
Apache Hive adalah proyek sumber terbuka yang dikembangkan di atas Apache Hadoop. Ini memungkinkan membaca, menulis, dan mengelola kumpulan data besar yang tersedia di berbagai repositori dan memungkinkan pengguna untuk menggabungkan fungsi mereka sendiri untuk analisis khusus.
Hive dirancang untuk tugas penyimpanan tradisional dan tidak dimaksudkan untuk tugas pemrosesan online. Bingkai batch yang kuat menawarkan skalabilitas, kinerja, skalabilitas, dan toleransi kesalahan.
Sangat cocok untuk ekstraksi data, pemodelan prediktif, dan pengindeksan dokumen. Tidak disarankan untuk melakukan kueri data waktu-nyata karena memperkenalkan latensi dalam mendapatkan hasil.
Fitur
- Mendukung mesin komputasi MapReduce, Tez, dan Spark
- Memproses kumpulan data yang sangat besar, berukuran beberapa petabyte
- Sangat mudah untuk dikodekan dibandingkan dengan Java
- Memberikan toleransi kesalahan dengan menyimpan data dalam sistem file terdistribusi Apache Hadoop
Badai Apache
Storm adalah platform sumber terbuka gratis yang digunakan untuk memproses aliran data tanpa batas. Ini menyediakan set terkecil dari unit pemrosesan yang digunakan untuk mengembangkan aplikasi yang dapat memproses data dalam jumlah yang sangat besar secara real-time.
Badai cukup cepat untuk memproses satu juta tupel per detik per node, dan mudah dioperasikan.
Apache Storm memungkinkan Anda untuk menambahkan lebih banyak node ke cluster Anda dan meningkatkan kekuatan pemrosesan aplikasi. Kapasitas pemrosesan dapat digandakan dengan menambahkan node karena skalabilitas horizontal dipertahankan.
Ilmuwan data dapat menggunakan Storm for DRPC (Distributed Remote Procedure Calls), analisis ETL (Retrieval-Conversion-Load) real-time, komputasi berkelanjutan, pembelajaran mesin online, dll. Ini diatur untuk memenuhi kebutuhan pemrosesan real-time Twitter , Yahoo, dan Flipboard.
Fitur
- Mudah digunakan dengan bahasa pemrograman apa pun
- Hal ini terintegrasi ke dalam setiap sistem antrian dan setiap database.
- Storm menggunakan Zookeeper untuk mengelola cluster dan menskalakan ke ukuran cluster yang lebih besar
- Perlindungan data terjamin menggantikan tupel yang hilang jika terjadi kesalahan
Ilmu Data Kepingan Salju
Tantangan terbesar bagi ilmuwan data adalah menyiapkan data dari sumber yang berbeda, karena waktu maksimum dihabiskan untuk mengambil, mengkonsolidasikan, membersihkan, dan menyiapkan data. Hal ini ditangani oleh Snowflake.

Ia menawarkan satu platform berkinerja tinggi yang menghilangkan kerumitan dan penundaan yang disebabkan oleh ETL (Load Transformation and Extraction). Itu juga dapat diintegrasikan dengan alat dan perpustakaan pembelajaran mesin (ML) terbaru seperti Dask dan Saturn Cloud.
Snowflake menawarkan arsitektur unik dari cluster komputasi khusus untuk setiap beban kerja untuk melakukan aktivitas komputasi tingkat tinggi tersebut, sehingga tidak ada pembagian sumber daya antara beban kerja ilmu data dan BI (kecerdasan bisnis).
Ini mendukung tipe data dari terstruktur, semi-terstruktur (JSON, Avro, ORC, Parket, atau XML) dan data tidak terstruktur. Ini menggunakan strategi data lake untuk meningkatkan akses data, kinerja, dan keamanan.
Ilmuwan dan analis data menggunakan kepingan salju di berbagai industri, termasuk keuangan, media dan hiburan, ritel, ilmu kesehatan dan kehidupan, teknologi, dan sektor publik.
Fitur
- Kompresi data tinggi untuk mengurangi biaya penyimpanan
- Menyediakan enkripsi data saat istirahat dan dalam perjalanan
- Mesin pemrosesan cepat dengan kompleksitas operasional rendah
- Pembuatan profil data terintegrasi dengan tampilan tabel, bagan, dan histogram
robot data
Datarobot adalah pemimpin dunia dalam cloud dengan AI (Kecerdasan Buatan). Platform uniknya dirancang untuk melayani semua industri, termasuk pengguna dan berbagai jenis data.
Perusahaan mengklaim perangkat lunak digunakan oleh sepertiga dari perusahaan Fortune 50 dan memberikan lebih dari satu triliun perkiraan di berbagai industri.
Dataroabot menggunakan pembelajaran mesin otomatis (ML) dan dirancang bagi para profesional data perusahaan untuk dengan cepat membuat, mengadaptasi, dan menerapkan model perkiraan yang akurat.
Ini memberi para ilmuwan akses mudah ke banyak algoritme pembelajaran mesin terbaru dengan transparansi lengkap untuk mengotomatiskan pra-pemrosesan data. Perangkat lunak ini telah mengembangkan klien R dan Python khusus bagi para ilmuwan untuk memecahkan masalah ilmu data yang kompleks.
Ini membantu mengotomatiskan kualitas data, rekayasa fitur, dan proses implementasi untuk memudahkan aktivitas ilmuwan data. Ini adalah produk premium, dan harganya tersedia berdasarkan permintaan.
Fitur
- Meningkatkan nilai bisnis dalam hal profitabilitas, peramalan disederhanakan
- Proses implementasi dan otomatisasi
- Mendukung algoritme dari Python, Spark, TensorFlow, dan sumber lainnya.
- Integrasi API memungkinkan Anda memilih dari ratusan model
TensorFlow
TensorFlow adalah library berbasis AI (kecerdasan buatan) komunitas yang menggunakan diagram aliran data untuk membuat, melatih, dan menerapkan aplikasi machine learning (ML). Ini memungkinkan pengembang untuk membuat jaringan saraf berlapis besar.
Ini mencakup tiga model – TensorFlow.js, TensorFlow Lite, dan TensorFlow Extended (TFX). Mode javascriptnya digunakan untuk melatih dan menerapkan model di browser dan di Node.js secara bersamaan. Mode ringannya adalah untuk menerapkan model pada perangkat seluler dan tertanam, dan model TFX untuk menyiapkan data, memvalidasi, dan menerapkan model.
Karena platformnya yang kuat, itu dapat digunakan di server, perangkat edge, atau web apa pun bahasa pemrogramannya.
TFX berisi mekanisme untuk menerapkan pipeline ML yang dapat ditingkatkan dan memberikan tugas kinerja keseluruhan yang kuat. Pipeline rekayasa data seperti Kubeflow dan Apache Airflow mendukung TFX.
Platform Tensorflow cocok untuk Pemula. Menengah dan bagi para ahli untuk melatih jaringan permusuhan generatif untuk menghasilkan gambar angka tulisan tangan menggunakan Keras.
Fitur
- Dapat menerapkan model ML di tempat, cloud, dan di browser dan apa pun bahasanya
- Pembuatan model yang mudah menggunakan API bawaan untuk pengulangan model yang cepat
- Berbagai perpustakaan dan model tambahannya mendukung kegiatan penelitian untuk bereksperimen
- Pembuatan model yang mudah menggunakan berbagai tingkat abstraksi
Matplotlib
Matplotlib adalah perangkat lunak komunitas yang komprehensif untuk memvisualisasikan data animasi dan grafik grafis untuk bahasa pemrograman Python. Desain uniknya terstruktur sehingga grafik data visual dihasilkan menggunakan beberapa baris kode.
Ada berbagai aplikasi pihak ketiga seperti program menggambar, GUI, peta warna, animasi, dan banyak lagi yang dirancang untuk diintegrasikan dengan Matplotlib.
Fungsinya dapat diperluas dengan banyak alat seperti Basemap, Cartopy, GTK-Tools, Natgrid, Seaborn, dan lainnya.
Fitur terbaiknya termasuk menggambar grafik dan peta dengan data terstruktur dan tidak terstruktur.
besar
Bigml adalah platform kolektif dan transparan untuk Insinyur, ilmuwan data, pengembang, dan analis. Ini melakukan transformasi data ujung ke ujung menjadi model yang dapat ditindaklanjuti.
Ini secara efektif membuat, bereksperimen, mengotomatiskan, dan mengelola alur kerja ml, berkontribusi pada aplikasi cerdas di berbagai industri.
Platform ML (pembelajaran mesin) yang dapat diprogram ini membantu pengurutan, prediksi deret waktu, deteksi asosiasi, regresi, analisis cluster, dan banyak lagi.
Versinya yang sepenuhnya dapat dikelola dengan satu dan beberapa penyewa dan satu kemungkinan penerapan untuk penyedia cloud mana pun memudahkan perusahaan untuk memberi semua orang akses ke data besar.
Harganya mulai dari $30 dan gratis untuk kumpulan data kecil dan tujuan pendidikan, dan digunakan di lebih dari 600 universitas.
Karena algoritme ML rekayasanya yang kuat, ia cocok di berbagai industri seperti farmasi, hiburan, otomotif, aerospace, perawatan kesehatan, IoT, dan banyak lagi.
Fitur
- Mengotomatiskan alur kerja yang memakan waktu dan kompleks dalam satu panggilan API.
- Itu dapat memproses data dalam jumlah besar dan melakukan tugas paralel
- Pustaka ini didukung oleh bahasa pemrograman populer seperti Python, Node.js, Ruby, Java, Swift, dll.
- Detail granularnya memudahkan pekerjaan audit dan persyaratan peraturan
Apache Spark
Ini adalah salah satu mesin open-source terbesar yang banyak digunakan oleh perusahaan besar. Spark digunakan oleh 80% perusahaan Fortune 500, menurut situs web. Ini kompatibel dengan node dan cluster tunggal untuk data besar dan ML.
Ini didasarkan pada SQL (Bahasa Kueri Terstruktur) tingkat lanjut untuk mendukung sejumlah besar data dan bekerja dengan tabel terstruktur dan data tidak terstruktur.
Platform Spark dikenal karena kemudahan penggunaannya, komunitas besar, dan kecepatan kilat. Pengembang menggunakan Spark untuk membangun aplikasi dan menjalankan kueri di Java, Scala, Python, R, dan SQL.
Fitur
- Memproses data secara batch maupun real-time
- Mendukung sejumlah besar petabyte data tanpa downsampling
- Itu memudahkan untuk menggabungkan beberapa perpustakaan seperti SQL, MLib, Graphx, dan Stream ke dalam satu alur kerja.
- Bekerja di Hadoop YARN, Apache Mesos, Kubernetes, dan bahkan di cloud dan memiliki akses ke berbagai sumber data
pisau
Konstanz Information Miner adalah platform open-source intuitif untuk aplikasi ilmu data. Seorang ilmuwan data dan analis dapat membuat alur kerja visual tanpa coding dengan fungsionalitas drag-and-drop sederhana.
Versi server adalah platform perdagangan yang digunakan untuk otomatisasi, manajemen ilmu data, dan analisis manajemen. KNIME membuat alur kerja ilmu data dan komponen yang dapat digunakan kembali dapat diakses oleh semua orang.
Fitur
- Sangat fleksibel untuk integrasi data dari Oracle, SQL, Hive, dan lainnya
- Akses data dari berbagai sumber seperti SharePoint, Amazon Cloud, Salesforce, Twitter, dan lainnya
- Penggunaan ml berupa pembangunan model, performance tuning, dan validasi model.
- Wawasan data dalam bentuk visualisasi, statistik, pemrosesan, dan pelaporan
Apa pentingnya 5 V data besar?
Data besar 5 V membantu ilmuwan data memahami dan menganalisis data besar untuk mendapatkan lebih banyak wawasan. Ini juga membantu memberikan lebih banyak statistik yang berguna bagi bisnis untuk membuat keputusan yang tepat dan mendapatkan keunggulan kompetitif.
Volume: Data besar didasarkan pada volume. Volume kuantum menentukan seberapa besar data tersebut. Biasanya berisi sejumlah besar data dalam terabyte, petabyte, dll. Berdasarkan ukuran volume, ilmuwan data merencanakan berbagai alat dan integrasi untuk analisis kumpulan data.
Kecepatan: Kecepatan pengumpulan data sangat penting karena beberapa perusahaan memerlukan informasi data waktu nyata, dan yang lain lebih suka memproses data dalam bentuk paket. Semakin cepat aliran data, semakin banyak ilmuwan data yang dapat mengevaluasi dan memberikan informasi yang relevan kepada perusahaan.
Variasi: Data berasal dari sumber yang berbeda dan, yang penting, tidak dalam format tetap. Data tersedia dalam format terstruktur (format database), semi terstruktur (XML/RDF) dan tidak terstruktur (data biner). Berdasarkan struktur data, alat big data digunakan untuk membuat, mengatur, memfilter, dan memproses data.
Kebenaran: Keakuratan data dan sumber yang kredibel menentukan konteks data besar. Kumpulan data berasal dari berbagai sumber seperti komputer, perangkat jaringan, perangkat seluler, media sosial, dll. Oleh karena itu, data harus dianalisis untuk dikirim ke tujuannya.
Nilai: Terakhir, berapa nilai data besar perusahaan? Peran ilmuwan data adalah memanfaatkan data sebaik mungkin untuk menunjukkan bagaimana wawasan data dapat menambah nilai bagi bisnis.
Kesimpulan
Daftar data besar di atas termasuk alat berbayar dan alat sumber terbuka. Informasi singkat dan fungsi disediakan untuk setiap alat. Jika Anda mencari informasi deskriptif, Anda dapat mengunjungi situs web yang relevan.
Perusahaan yang ingin mendapatkan keunggulan kompetitif menggunakan data besar dan alat terkait seperti AI (kecerdasan buatan), ML (pembelajaran mesin), dan teknologi lainnya untuk mengambil tindakan taktis guna meningkatkan layanan pelanggan, penelitian, pemasaran, perencanaan masa depan, dll.
Alat data besar digunakan di sebagian besar industri karena perubahan kecil dalam produktivitas dapat menghasilkan penghematan yang signifikan dan keuntungan besar. Kami harap artikel di atas memberi Anda gambaran umum tentang alat data besar dan signifikansinya.
Anda mungkin juga menyukai:
Kursus online untuk mempelajari dasar-dasar Teknik Data.