
13 أداة بيانات ضخمة يجب معرفتها كعالم بيانات
نشرت: 2021-11-30في عصر المعلومات ، تجمع مراكز البيانات كميات كبيرة من البيانات. تأتي البيانات التي تم جمعها من مصادر مختلفة مثل المعاملات المالية وتفاعلات العملاء ووسائل التواصل الاجتماعي والعديد من المصادر الأخرى ، والأهم من ذلك أنها تتراكم بشكل أسرع.
يمكن أن تكون البيانات متنوعة وحساسة وتتطلب الأدوات المناسبة لجعلها ذات مغزى لأنها تتمتع بإمكانيات غير محدودة لتحديث إحصاءات الأعمال والمعلومات وتغيير الحياة.

أدوات البيانات الضخمة وعلماء البيانات بارزون في مثل هذه السيناريوهات.
تجعل هذه الكمية الكبيرة من البيانات المتنوعة من الصعب معالجتها باستخدام الأدوات والتقنيات التقليدية مثل Excel. إن Excel ليس بالفعل قاعدة بيانات ولديه حد (65.536 صفاً) لتخزين البيانات.
يُظهر تحليل البيانات في Excel ضعف تكامل البيانات. على المدى الطويل ، تتمتع البيانات المخزنة في Excel بمحدودية الأمان والامتثال ، ومعدلات التعافي من الكوارث منخفضة للغاية ، ولا يوجد تحكم مناسب في الإصدار.
لمعالجة مثل هذه المجموعات الكبيرة والمتنوعة من البيانات ، هناك حاجة إلى مجموعة فريدة من الأدوات ، تسمى أدوات البيانات ، لفحص ومعالجة واستخراج المعلومات القيمة. تتيح لك هذه الأدوات التعمق في بياناتك للعثور على رؤى وأنماط بيانات أكثر أهمية.
يتطلب التعامل مع مثل هذه الأدوات والبيانات التكنولوجية المعقدة بطبيعة الحال مجموعة مهارات فريدة ، ولهذا السبب يلعب عالم البيانات دورًا حيويًا في البيانات الضخمة.
أهمية أدوات البيانات الضخمة
البيانات هي اللبنة الأساسية لأي مؤسسة وتستخدم لاستخراج معلومات قيمة وإجراء تحليلات مفصلة وخلق الفرص وتخطيط معالم ورؤى أعمال جديدة.
يتم إنشاء المزيد والمزيد من البيانات كل يوم والتي يجب تخزينها بكفاءة وأمان واسترجاعها عند الحاجة. يتطلب حجم تلك البيانات وتنوعها وتغييرها السريع أدوات بيانات ضخمة جديدة وطرق تخزين وتحليل مختلفة.
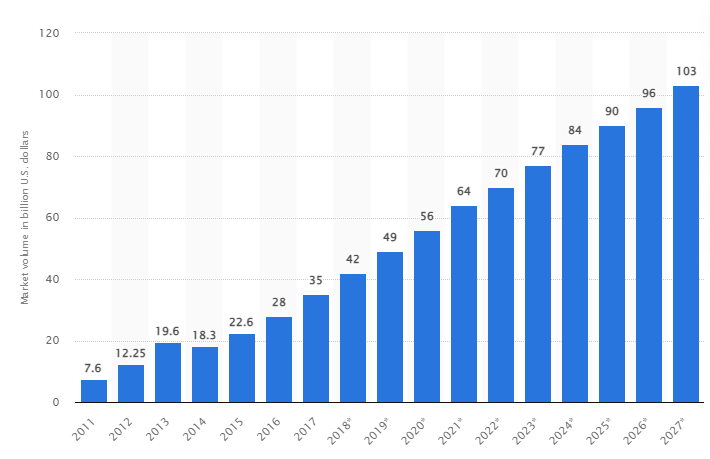
وفقًا لدراسة ، من المتوقع أن ينمو سوق البيانات الضخمة العالمية إلى 103 مليار دولار أمريكي بحلول عام 2027 ، أي أكثر من ضعف حجم السوق المتوقع في عام 2018.
تحديات الصناعة اليوم
تم استخدام مصطلح "البيانات الضخمة" مؤخرًا للإشارة إلى مجموعات البيانات التي نمت بشكل كبير بحيث يصعب استخدامها مع أنظمة إدارة قواعد البيانات التقليدية (DBMS).
تتزايد أحجام البيانات باستمرار وتتراوح اليوم من عشرات تيرابايت (TB) إلى العديد من البيتابايت (PB) في مجموعة بيانات واحدة. يتجاوز حجم مجموعات البيانات هذه قدرة البرامج الشائعة على المعالجة والإدارة والبحث والمشاركة والتخيل بمرور الوقت.
سيؤدي تكوين البيانات الضخمة إلى ما يلي:
- إدارة الجودة وتحسينها
- سلسلة التوريد وإدارة الكفاءة
- ذكاء العملاء
- تحليل البيانات واتخاذ القرار
- إدارة المخاطر وكشف الاحتيال
في هذا القسم ، نلقي نظرة على أفضل أدوات البيانات الضخمة وكيف يستخدم علماء البيانات هذه التقنيات لتصفية هذه التقنيات وتحليلها وتخزينها واستخراجها عندما تريد الشركات إجراء تحليل أعمق لتحسين أعمالهم وتنميتها.
اباتشي هادوب
Apache Hadoop عبارة عن منصة Java مفتوحة المصدر تقوم بتخزين ومعالجة كميات كبيرة من البيانات.
يعمل Hadoop عن طريق تعيين مجموعات البيانات الكبيرة (من تيرابايت إلى بيتابايت) ، وتحليل المهام بين المجموعات ، وتقسيمها إلى أجزاء أصغر (64 ميجابايت إلى 128 ميجابايت) ، مما يؤدي إلى معالجة البيانات بشكل أسرع.
لتخزين البيانات ومعالجتها ، يتم إرسال البيانات إلى مجموعة Hadoop ، ويقوم HDFS (نظام الملفات الموزعة Hadoop) بتخزين البيانات ، ويقوم MapReduce بمعالجة البيانات ، ويقوم YARN (بعد مفاوض مورد آخر) بتقسيم المهام وتعيين الموارد.
وهي مناسبة لعلماء البيانات والمطورين والمحللين من مختلف الشركات والمؤسسات للبحث والإنتاج.
سمات
- نسخ البيانات: يتم تخزين نسخ متعددة من الكتلة في عقد مختلفة وتكون بمثابة تسامح مع الخطأ في حالة حدوث خطأ.
- قابلية كبيرة للتوسع: توفر قابلية التوسع الرأسي والأفقي
- التكامل مع نماذج Apache الأخرى ، Cloudera و Hortonworks
ضع في اعتبارك أخذ هذه الدورة التدريبية الرائعة عبر الإنترنت لتعلم البيانات الضخمة باستخدام Apache Spark.
سريع
يدعي موقع Rapidminer أن ما يقرب من 40000 مؤسسة في جميع أنحاء العالم تستخدم برامجها لزيادة المبيعات وتقليل التكاليف وتجنب المخاطر.
حصل البرنامج على العديد من الجوائز: جوائز Gartner Vision 2021 لعلوم البيانات ومنصات التعلم الآلي ، والتحليلات التنبؤية متعددة الوسائط ، وحلول التعلم الآلي من منصة Forrester and Crowd للتعلم الآلي وعلوم البيانات الأكثر سهولة في الاستخدام في تقرير ربيع G2 2021.
إنها منصة شاملة لدورة الحياة العلمية ومتكاملة بسلاسة ومحسّنة لبناء نماذج ML (التعلم الآلي). يقوم تلقائيًا بتوثيق كل خطوة من خطوات الإعداد والنمذجة والتحقق من الصحة من أجل الشفافية الكاملة.
إنه برنامج مدفوع متاح في ثلاثة إصدارات: إعداد البيانات وإنشاء النموذج والتحقق منه ونشره. إنه متاح مجانًا للمؤسسات التعليمية ، وتستخدم أكثر من 4000 جامعة في جميع أنحاء العالم RapidMiner.
سمات
- يقوم بفحص البيانات لتحديد الأنماط وإصلاح مشاكل الجودة
- يستخدم مصمم سير عمل لا يحتوي على رموز مع أكثر من 1500 خوارزمية
- دمج نماذج التعلم الآلي في تطبيقات الأعمال الحالية
تابلوه
يوفر Tableau المرونة لتحليل المنصات بشكل مرئي وحل المشكلات وتمكين الأشخاص والمؤسسات. يعتمد على تقنية VizQL (لغة مرئية لاستعلامات قاعدة البيانات) ، والتي تحول السحب والإفلات في استعلامات البيانات من خلال واجهة مستخدم سهلة الاستخدام.
تم الحصول على Tableau بواسطة Salesforce في عام 2019. وهو يسمح بربط البيانات من مصادر مثل قواعد بيانات SQL أو جداول البيانات أو التطبيقات السحابية مثل Google Analytics و Salesforce.
يمكن للمستخدمين شراء إصداراتها Creator و Explorer و Viewer بناءً على الأعمال أو التفضيلات الفردية حيث أن لكل منها خصائصه ووظائفه.
إنه مثالي للمحللين وعلماء البيانات وقطاع التعليم ومستخدمي الأعمال لتنفيذ ثقافة قائمة على البيانات وتحقيق التوازن بينها وتقييمها من خلال النتائج.
سمات
- توفر لوحات المعلومات نظرة عامة كاملة على البيانات في شكل عناصر مرئية وكائنات ونص.
- مجموعة كبيرة من مخططات البيانات: الرسوم البيانية ، ومخططات جانت ، والمخططات ، ومخططات الحركة ، وغيرها الكثير
- حماية مرشح على مستوى الصف للحفاظ على البيانات آمنة ومستقرة
- تقدم هندستها المعمارية التحليل والتنبؤ يمكن التنبؤ به
تعلم التابلوه سهل.
كلوديرا
تقدم Cloudera منصة آمنة للسحابة ومراكز البيانات لإدارة البيانات الضخمة. يستخدم تحليلات البيانات والتعلم الآلي لتحويل البيانات المعقدة إلى رؤى واضحة وقابلة للتنفيذ.
تقدم Cloudera حلولاً وأدوات للسحب الخاصة والمختلطة ، وهندسة البيانات ، وتدفق البيانات ، وتخزين البيانات ، وعلوم البيانات لعلماء البيانات ، والمزيد.
تعمل المنصة الموحدة والتحليلات متعددة الوظائف على تحسين عملية اكتشاف الرؤى القائمة على البيانات. يوفر علم البيانات الخاص بها إمكانية الاتصال بأي نظام تستخدمه المؤسسة ، وليس فقط Cloudera و Hortonworks (كلا الشركتين تشاركا).
يدير علماء البيانات أنشطتهم الخاصة مثل التحليل والتخطيط والمراقبة وإشعارات البريد الإلكتروني عبر أوراق عمل علوم البيانات التفاعلية. بشكل افتراضي ، هو نظام أساسي متوافق مع الأمان يسمح لعلماء البيانات بالوصول إلى بيانات Hadoop وتشغيل استعلامات Spark بسهولة.
النظام الأساسي مناسب لمهندسي البيانات وعلماء البيانات ومتخصصي تكنولوجيا المعلومات في مختلف الصناعات مثل المستشفيات والمؤسسات المالية والاتصالات السلكية واللاسلكية وغيرها الكثير.
سمات
- يدعم جميع السحابات الرئيسية الخاصة والعامة ، بينما يدعم منضدة عمل Data Science عمليات النشر في أماكن العمل
- تقوم قنوات البيانات المؤتمتة بتحويل البيانات إلى نماذج قابلة للاستخدام ودمجها مع مصادر أخرى.
- يسمح سير العمل الموحد ببناء النموذج والتدريب والتنفيذ بسرعة.
- بيئة آمنة لمصادقة Hadoop والتفويض والتشفير
اباتشي خلية
Apache Hive هو مشروع مفتوح المصدر تم تطويره على رأس Apache Hadoop. يسمح بقراءة مجموعات البيانات الكبيرة المتوفرة في مستودعات مختلفة وكتابتها وإدارتها ، كما يسمح للمستخدمين بدمج وظائفهم الخاصة لإجراء تحليل مخصص.
تم تصميم Hive لمهام التخزين التقليدية وليس مخصصًا لمهام المعالجة عبر الإنترنت. توفر إطارات الدُفعات القوية الخاصة بها قابلية التوسع والأداء وقابلية التوسع والتسامح مع الأخطاء.
وهي مناسبة لاستخراج البيانات والنمذجة التنبؤية وفهرسة المستندات. لا يوصى به للاستعلام عن بيانات الوقت الفعلي لأنه يقدم زمن انتقال في الحصول على النتائج.
سمات
- يدعم محرك الحوسبة MapReduce و Tez و Spark
- معالجة مجموعات البيانات الضخمة ، التي يبلغ حجمها عدة بيتابايت
- من السهل جدًا كتابة التعليمات البرمجية مقارنةً بجافا
- يوفر التسامح مع الخطأ من خلال تخزين البيانات في نظام الملفات الموزعة Apache Hadoop
اباتشي ستورم
The Storm عبارة عن منصة مجانية مفتوحة المصدر تُستخدم لمعالجة تدفقات البيانات غير المحدودة. يوفر أصغر مجموعة من وحدات المعالجة المستخدمة لتطوير التطبيقات التي يمكنها معالجة كميات كبيرة جدًا من البيانات في الوقت الفعلي.
العاصفة سريعة بما يكفي لمعالجة مليون وحدة في الثانية لكل عقدة ، ومن السهل تشغيلها.
يسمح لك Apache Storm بإضافة المزيد من العقد إلى مجموعتك وزيادة قوة معالجة التطبيق. يمكن مضاعفة سعة المعالجة عن طريق إضافة العقد مع الحفاظ على قابلية التوسع الأفقي.
يمكن لعلماء البيانات استخدام Storm لـ DRPC (مكالمات الإجراءات عن بُعد الموزعة) ، وتحليل ETL في الوقت الفعلي (استرداد وتحويل-تحميل) ، والحساب المستمر ، والتعلم الآلي عبر الإنترنت ، وما إلى ذلك ، وقد تم إعداده لتلبية احتياجات المعالجة في الوقت الفعلي لتويتر وياهو و Flipboard.
سمات
- سهل الاستخدام مع أي لغة برمجة
- تم دمجها في كل نظام انتظار وفي كل قاعدة بيانات.
- يستخدم Storm Zookeeper لإدارة المجموعات والمقاييس لأحجام الكتلة الأكبر
- تحل الحماية المضمونة للبيانات محل المجموعات المفقودة إذا حدث خطأ ما
علم بيانات ندفة الثلج
يتمثل التحدي الأكبر لعلماء البيانات في إعداد البيانات من مصادر مختلفة ، حيث يتم قضاء أقصى وقت في استرداد البيانات وتوحيدها وتنظيفها وإعدادها. يتم تناوله من قبل ندفة الثلج.

إنه يوفر منصة واحدة عالية الأداء تقضي على المتاعب والتأخير الناجم عن ETL (تحويل واستخراج الأحمال). يمكن أيضًا دمجها مع أحدث أدوات التعلم الآلي (ML) والمكتبات مثل Dask و Saturn Cloud.
تقدم Snowflake بنية فريدة لمجموعات الحوسبة المخصصة لكل حمل عمل لأداء أنشطة الحوسبة عالية المستوى ، لذلك لا توجد مشاركة للموارد بين علم البيانات وأعباء عمل BI (ذكاء الأعمال).
وهو يدعم أنواع البيانات من البيانات المهيكلة وشبه المهيكلة (JSON أو Avro أو ORC أو Parquet أو XML) والبيانات غير المنظمة. يستخدم استراتيجية بحيرة البيانات لتحسين الوصول إلى البيانات والأداء والأمان.
يستخدم علماء البيانات والمحللون رقاقات الثلج في صناعات مختلفة ، بما في ذلك التمويل والإعلام والترفيه وتجارة التجزئة وعلوم الصحة والحياة والتكنولوجيا والقطاع العام.
سمات
- ضغط بيانات مرتفع لتقليل تكاليف التخزين
- يوفر تشفير البيانات في حالة التخزين والعبور
- محرك معالجة سريع مع تعقيد تشغيلي منخفض
- تشكيل جانبي متكامل للبيانات مع طرق عرض الجدول والرسم البياني والمدرج التكراري
داتاروبوت
Datarobot هي شركة رائدة عالميًا في السحابة باستخدام الذكاء الاصطناعي (AI). تم تصميم منصتها الفريدة لخدمة جميع الصناعات ، بما في ذلك المستخدمين وأنواع مختلفة من البيانات.
تدعي الشركة أن البرنامج يستخدمه ثلث شركات Fortune 50 ويقدم أكثر من تريليون تقدير عبر مختلف الصناعات.
يستخدم Dataroabot التعلم الآلي (ML) وهو مصمم لمحترفي بيانات المؤسسات لإنشاء نماذج تنبؤ دقيقة وتكييفها ونشرها بسرعة.
إنه يمنح العلماء وصولاً سهلاً إلى العديد من خوارزميات التعلم الآلي الحديثة بشفافية كاملة لأتمتة المعالجة المسبقة للبيانات. طور البرنامج عملاء R و Python مخصصين للعلماء لحل مشاكل علوم البيانات المعقدة.
يساعد في أتمتة جودة البيانات وهندسة الميزات وعمليات التنفيذ لتسهيل أنشطة علماء البيانات. إنه منتج ممتاز ، والسعر متاح عند الطلب.
سمات
- يزيد من قيمة الأعمال من حيث الربحية ، والتنبؤ مبسط
- عمليات التنفيذ والأتمتة
- يدعم الخوارزميات من Python و Spark و TensorFlow ومصادر أخرى.
- يتيح لك تكامل واجهة برمجة التطبيقات الاختيار من بين مئات النماذج
TensorFlow
TensorFlow هي مكتبة مجتمعية قائمة على الذكاء الاصطناعي (AI) والتي تستخدم مخططات تدفق البيانات لبناء وتدريب ونشر تطبيقات التعلم الآلي (ML). يتيح ذلك للمطورين إنشاء شبكات عصبية كبيرة ذات طبقات.
يتضمن ثلاثة نماذج - TensorFlow.js و TensorFlow Lite و TensorFlow Extended (TFX). يتم استخدام وضع جافا سكريبت الخاص به للتدريب ونشر النماذج في المتصفح وعلى Node.js في نفس الوقت. وضع لايت الخاص به مخصص لنشر النماذج على الأجهزة المحمولة والمدمجة ، ونموذج TFX مخصص لإعداد البيانات والتحقق من صحة النماذج ونشرها.
نظرًا لمنصته القوية ، يمكن نشره على الخوادم أو الأجهزة المتطورة أو الويب بغض النظر عن لغة البرمجة.
يحتوي TFX على آليات لفرض خطوط ML التي يمكن أن تكون قابلة للضبط وتوفر واجبات أداء شاملة قوية. تدعم خطوط أنابيب هندسة البيانات مثل Kubeflow و Apache Airflow TFX.
منصة Tensorflow مناسبة للمبتدئين. وسيط وللخبراء لتدريب شبكة خصومة توليدية لتوليد صور لأرقام مكتوبة بخط اليد باستخدام Keras.
سمات
- يمكن نشر نماذج ML في مكان العمل والسحابة وفي المستعرض وبغض النظر عن اللغة
- بناء نموذج سهل باستخدام واجهات برمجة التطبيقات الفطرية لتكرار النموذج بسرعة
- تدعم مكتباتها ونماذجها الإضافية المتنوعة أنشطة البحث للتجربة
- بناء نموذج سهل باستخدام مستويات متعددة من التجريد
ماتبلوتليب
Matplotlib هو برنامج مجتمعي شامل لتصور البيانات المتحركة والرسومات الرسومية للغة برمجة Python. تم تصميم تصميمه الفريد بحيث يتم إنشاء رسم بياني للبيانات المرئية باستخدام بضعة أسطر من التعليمات البرمجية.
هناك العديد من تطبيقات الطرف الثالث مثل برامج الرسم وواجهات المستخدم الرسومية وخرائط الألوان والرسوم المتحركة وغيرها الكثير التي تم تصميمها لتتكامل مع Matplotlib.
يمكن توسيع وظائفها باستخدام العديد من الأدوات مثل Basemap و Cartopy و GTK-Tools و Natgrid و Seaborn وغيرها.
تشمل أفضل ميزاته رسم الرسوم البيانية والخرائط ببيانات منظمة وغير منظمة.
بيجمل
Bigml عبارة عن نظام أساسي جماعي وشفاف للمهندسين وعلماء البيانات والمطورين والمحللين. يقوم بتحويل البيانات من طرف إلى طرف إلى نماذج قابلة للتنفيذ.
يقوم بإنشاء وتجربة وأتمتة وإدارة تدفقات عمل ml بشكل فعال ، مما يساهم في التطبيقات الذكية عبر مجموعة واسعة من الصناعات.
تساعد منصة ML (التعلم الآلي) القابلة للبرمجة في التسلسل ، وتنبؤ السلاسل الزمنية ، واكتشاف الارتباط ، والانحدار ، وتحليل الكتلة ، والمزيد.
نسخته التي يمكن إدارتها بالكامل مع مستأجرين فرديين ومتعددين ونشر محتمل واحد لأي مزود خدمة سحابية تجعل من السهل على المؤسسات منح الجميع حق الوصول إلى البيانات الضخمة.
يبدأ سعره من 30 دولارًا وهو مجاني لمجموعات البيانات الصغيرة والأغراض التعليمية ، ويستخدم في أكثر من 600 جامعة.
نظرًا لخوارزميات ML الهندسية القوية ، فهي مناسبة في العديد من الصناعات مثل الأدوية ، والترفيه ، والسيارات ، والفضاء ، والرعاية الصحية ، وإنترنت الأشياء ، وغيرها الكثير.
سمات
- قم بأتمتة عمليات سير العمل المعقدة والمستهلكة للوقت في استدعاء واحد لواجهة برمجة التطبيقات.
- يمكنه معالجة كميات كبيرة من البيانات وتنفيذ مهام متوازية
- المكتبة مدعومة من قبل لغات البرمجة الشائعة مثل Python و Node.js و Ruby و Java و Swift وما إلى ذلك.
- تفاصيلها الدقيقة تسهل مهمة التدقيق والمتطلبات التنظيمية
اباتشي سبارك
إنه أحد أكبر المحركات مفتوحة المصدر المستخدمة على نطاق واسع من قبل الشركات الكبيرة. يستخدم Spark من قبل 80٪ من شركات Fortune 500 ، وفقًا لموقع الويب. وهو متوافق مع العقد الفردية والمجموعات للبيانات الضخمة و ML.
يعتمد على لغة الاستعلامات الهيكلية (SQL) المتقدمة لدعم كميات كبيرة من البيانات والعمل مع الجداول المنظمة والبيانات غير المنظمة.
تشتهر منصة Spark بسهولة الاستخدام ومجتمعها الكبير وسرعة البرق. يستخدم المطورون Spark لبناء التطبيقات وتشغيل الاستعلامات في Java و Scala و Python و R و SQL.
سمات
- يعالج البيانات دفعة واحدة وكذلك في الوقت الفعلي
- يدعم كميات كبيرة من بيتابايت من البيانات دون الاختزال
- يسهل دمج مكتبات متعددة مثل SQL و MLib و Graphx و Stream في سير عمل واحد.
- يعمل على Hadoop YARN و Apache Mesos و Kubernetes وحتى في السحابة ولديه حق الوصول إلى مصادر بيانات متعددة
كنيم
Konstanz Information Miner هي منصة بديهية مفتوحة المصدر لتطبيقات علوم البيانات. يمكن لعالم البيانات والمحلل إنشاء مهام سير عمل مرئية بدون تشفير باستخدام وظيفة السحب والإفلات البسيطة.
إصدار الخادم هو عبارة عن منصة تداول تستخدم للأتمتة وإدارة علوم البيانات وتحليل الإدارة. تجعل KNIME عمليات سير عمل علوم البيانات والمكونات القابلة لإعادة الاستخدام في متناول الجميع.
سمات
- مرن للغاية لتكامل البيانات من Oracle و SQL و Hive والمزيد
- الوصول إلى البيانات من مصادر متعددة مثل SharePoint و Amazon Cloud و Salesforce و Twitter والمزيد
- يتم استخدام ml في شكل بناء نموذج وضبط الأداء والتحقق من صحة النموذج.
- رؤى البيانات في شكل التصور والإحصاءات والمعالجة وإعداد التقارير
ما هي أهمية القيم الخمسة للبيانات الضخمة؟
تساعد القيم الخمسة للبيانات الضخمة علماء البيانات على فهم وتحليل البيانات الضخمة لاكتساب المزيد من الأفكار. كما أنه يساعد في توفير المزيد من الإحصائيات المفيدة للشركات لاتخاذ قرارات مستنيرة واكتساب ميزة تنافسية.
الحجم: تعتمد البيانات الضخمة على الحجم. يحدد الحجم الكمي حجم البيانات. عادةً ما يحتوي على كمية كبيرة من البيانات في تيرابايت ، بيتابايت ، إلخ. بناءً على حجم الحجم ، يخطط علماء البيانات لأدوات وتكاملات متنوعة لتحليل مجموعة البيانات.
السرعة: تعد سرعة جمع البيانات أمرًا بالغ الأهمية لأن بعض الشركات تتطلب معلومات بيانات في الوقت الفعلي ، ويفضل البعض الآخر معالجة البيانات في حزم. كلما كان تدفق البيانات أسرع ، زاد عدد علماء البيانات الذين يستطيعون تقييم وتقديم المعلومات ذات الصلة للشركة.
التنوع: تأتي البيانات من مصادر مختلفة ، والأهم من ذلك أنها ليست بتنسيق ثابت. تتوفر البيانات في شكل منظم (تنسيق قاعدة بيانات) ، وشبه منظم (XML / RDF) وتنسيقات غير منظمة (بيانات ثنائية). استنادًا إلى هياكل البيانات ، تُستخدم أدوات البيانات الضخمة لإنشاء البيانات وتنظيمها وتصفيتها ومعالجتها.
الصدق: تحدد دقة البيانات والمصادر الموثوقة سياق البيانات الضخمة. تأتي مجموعة البيانات من مصادر مختلفة مثل أجهزة الكمبيوتر وأجهزة الشبكة والأجهزة المحمولة ووسائل التواصل الاجتماعي وما إلى ذلك. وبناءً عليه ، يجب تحليل البيانات لإرسالها إلى وجهتها.
القيمة: أخيرًا ، ما هي قيمة البيانات الضخمة للشركة؟ يتمثل دور عالم البيانات في تحقيق أقصى استفادة من البيانات لتوضيح كيف يمكن لرؤى البيانات أن تضيف قيمة إلى الأعمال التجارية.
استنتاج
تتضمن قائمة البيانات الضخمة أعلاه الأدوات المدفوعة وأدوات مفتوحة المصدر. يتم توفير معلومات ووظائف موجزة لكل أداة. إذا كنت تبحث عن معلومات وصفية ، يمكنك زيارة المواقع ذات الصلة.
تستخدم الشركات التي تتطلع إلى اكتساب ميزة تنافسية البيانات الضخمة والأدوات ذات الصلة مثل AI (الذكاء الاصطناعي) و ML (التعلم الآلي) وغيرها من التقنيات لاتخاذ إجراءات تكتيكية لتحسين خدمة العملاء والبحث والتسويق والتخطيط المستقبلي ، إلخ.
تُستخدم أدوات البيانات الضخمة في معظم الصناعات نظرًا لأن التغييرات الصغيرة في الإنتاجية يمكن أن تترجم إلى مدخرات كبيرة وأرباح كبيرة. نأمل أن تقدم لك المقالة أعلاه نظرة عامة على أدوات البيانات الضخمة وأهميتها.
ربما يعجبك أيضا:
دورات عبر الإنترنت لتعلم أساسيات هندسة البيانات.