
13 เครื่องมือ Big Data ที่ควรทราบในฐานะนักวิทยาศาสตร์ข้อมูล
เผยแพร่แล้ว: 2021-11-30ในยุคข้อมูลข่าวสาร ศูนย์ข้อมูลจะเก็บรวบรวมข้อมูลจำนวนมาก ข้อมูลที่รวบรวมมาจากแหล่งต่างๆ เช่น ธุรกรรมทางการเงิน การโต้ตอบกับลูกค้า โซเชียลมีเดีย และแหล่งอื่นๆ อีกมากมาย และที่สำคัญกว่านั้นคือสะสมได้เร็วขึ้น
ข้อมูลสามารถมีความหลากหลายและละเอียดอ่อนได้ และต้องใช้เครื่องมือที่เหมาะสมในการทำให้มันมีความหมาย เนื่องจากมีศักยภาพไม่จำกัดในการปรับปรุงสถิติทางธุรกิจ ข้อมูล และการเปลี่ยนแปลงชีวิต

เครื่องมือบิ๊กดาต้าและนักวิทยาศาสตร์ด้านข้อมูลมีความโดดเด่นในสถานการณ์ดังกล่าว
ข้อมูลที่หลากหลายจำนวนมากเช่นนี้ทำให้ยากต่อการประมวลผลโดยใช้เครื่องมือและเทคนิคแบบเดิมๆ เช่น Excel Excel ไม่ใช่ฐานข้อมูลจริงๆ และมีการจำกัด (65,536 แถว) สำหรับการจัดเก็บข้อมูล
การวิเคราะห์ข้อมูลใน Excel แสดงให้เห็นถึงความสมบูรณ์ของข้อมูลที่ไม่ดี ในระยะยาว ข้อมูลที่จัดเก็บไว้ใน Excel มีการรักษาความปลอดภัยและการปฏิบัติตามข้อกำหนดที่จำกัด อัตราการกู้คืนจากความเสียหายที่ต่ำมาก และไม่มีการควบคุมเวอร์ชันที่เหมาะสม
ในการประมวลผลชุดข้อมูลที่มีขนาดใหญ่และหลากหลาย จำเป็นต้องมีชุดเครื่องมือเฉพาะที่เรียกว่าเครื่องมือข้อมูลเพื่อตรวจสอบ ประมวลผล และดึงข้อมูลที่มีค่า เครื่องมือเหล่านี้ช่วยให้คุณเจาะลึกข้อมูลของคุณเพื่อค้นหาข้อมูลเชิงลึกและรูปแบบข้อมูลที่มีความหมายมากขึ้น
การจัดการกับเครื่องมือและข้อมูลทางเทคโนโลยีที่ซับซ้อนนั้นจำเป็นต้องมีชุดทักษะเฉพาะตัว และนั่นเป็นสาเหตุที่นักวิทยาศาสตร์ข้อมูลมีบทบาทสำคัญในข้อมูลขนาดใหญ่
ความสำคัญของเครื่องมือบิ๊กดาต้า
ข้อมูลเป็นส่วนประกอบสำคัญขององค์กรใดๆ และใช้เพื่อดึงข้อมูลที่มีค่า ดำเนินการวิเคราะห์โดยละเอียด สร้างโอกาส และวางแผนเหตุการณ์สำคัญและวิสัยทัศน์ของธุรกิจใหม่
มีการสร้างข้อมูลมากขึ้นทุกวันที่ต้องจัดเก็บอย่างมีประสิทธิภาพและปลอดภัย และเรียกคืนเมื่อจำเป็น ขนาด ความหลากหลาย และการเปลี่ยนแปลงอย่างรวดเร็วของข้อมูลนั้นต้องการเครื่องมือบิ๊กดาต้าใหม่ พื้นที่จัดเก็บที่แตกต่างกัน และวิธีการวิเคราะห์
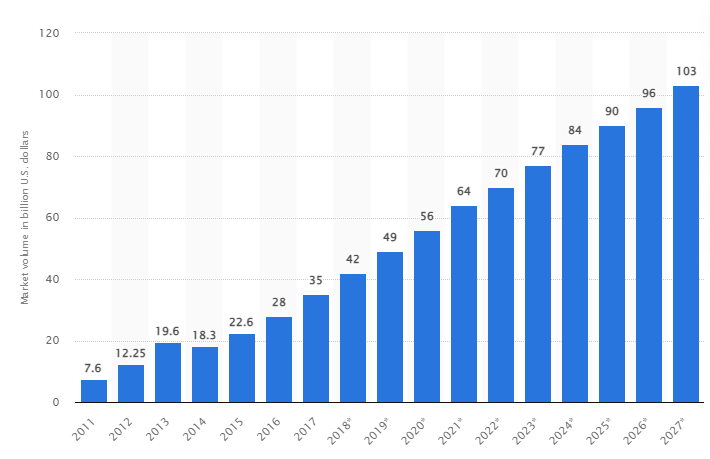
จากการศึกษาวิจัย คาดการณ์ว่าตลาดบิ๊กดาต้าทั่วโลกจะเติบโตเป็น 103 พันล้านดอลลาร์สหรัฐภายในปี 2570 มากกว่าขนาดตลาดที่คาดการณ์ไว้ในปี 2561 ถึงสองเท่า
ความท้าทายของอุตสาหกรรมในปัจจุบัน
คำว่า "ข้อมูลขนาดใหญ่" เพิ่งถูกนำมาใช้เพื่ออ้างถึงชุดข้อมูลที่เติบโตขึ้นอย่างมากจนยากที่จะใช้กับระบบการจัดการฐานข้อมูลแบบเดิม (DBMS)
ขนาดข้อมูลเพิ่มขึ้นอย่างต่อเนื่องและในปัจจุบันมีตั้งแต่สิบเทราไบต์ (TB) ไปจนถึงหลายเพตาไบต์ (PB) ในชุดข้อมูลเดียว ขนาดของชุดข้อมูลเหล่านี้เกินความสามารถของซอฟต์แวร์ทั่วไปในการประมวลผล จัดการ ค้นหา แชร์ และแสดงภาพเมื่อเวลาผ่านไป
การก่อตัวของข้อมูลขนาดใหญ่จะนำไปสู่สิ่งต่อไปนี้:
- การจัดการและการปรับปรุงคุณภาพ
- การจัดการห่วงโซ่อุปทานและประสิทธิภาพ
- ความฉลาดของลูกค้า
- การวิเคราะห์ข้อมูลและการตัดสินใจ
- การจัดการความเสี่ยงและการตรวจจับการฉ้อโกง
ในส่วนนี้ เราจะพิจารณาเครื่องมือบิ๊กดาต้าที่ดีที่สุดและวิธีที่นักวิทยาศาสตร์ข้อมูลใช้เทคโนโลยีเหล่านี้ในการกรอง วิเคราะห์ จัดเก็บ และดึงข้อมูลเมื่อบริษัทต่างๆ ต้องการวิเคราะห์เชิงลึกเพื่อปรับปรุงและทำให้ธุรกิจเติบโต
Apache Hadoop
Apache Hadoop เป็นแพลตฟอร์ม Java แบบโอเพ่นซอร์สที่จัดเก็บและประมวลผลข้อมูลจำนวนมาก
Hadoop ทำงานโดยการจับคู่ชุดข้อมูลขนาดใหญ่ (จากเทราไบต์ถึงเพทาไบต์) วิเคราะห์งานระหว่างคลัสเตอร์ และแบ่งเป็นชิ้นเล็กๆ (64MB ถึง 128MB) ส่งผลให้การประมวลผลข้อมูลเร็วขึ้น
ในการจัดเก็บและประมวลผลข้อมูล ข้อมูลจะถูกส่งไปยังคลัสเตอร์ Hadoop, HDFS (ระบบไฟล์แบบกระจาย Hadoop) เก็บข้อมูล, MapReduce ประมวลผลข้อมูล และ YARN (ยังเป็นผู้เจรจาต่อรองทรัพยากรอีกราย) แบ่งงานและมอบหมายทรัพยากร
เหมาะสำหรับนักวิทยาศาสตร์ข้อมูล นักพัฒนา และนักวิเคราะห์จากบริษัทและองค์กรต่างๆ เพื่อการวิจัยและการผลิต
คุณสมบัติ
- การจำลองข้อมูล: สำเนาหลายชุดของบล็อกถูกเก็บไว้ในโหนดต่างๆ และทำหน้าที่เป็นความทนทานต่อข้อผิดพลาดในกรณีที่เกิดข้อผิดพลาด
- ปรับขนาดได้สูง: ให้ความยืดหยุ่นในแนวตั้งและแนวนอน
- การทำงานร่วมกับ Apache รุ่นอื่นๆ, Cloudera และ Hortonworks
ลองพิจารณาหลักสูตรออนไลน์ที่ยอดเยี่ยมนี้เพื่อเรียนรู้ Big Data ด้วย Apache Spark
Rapidminer
เว็บไซต์ Rapidminer อ้างว่าประมาณ 40,000 องค์กรทั่วโลกใช้ซอฟต์แวร์เพื่อเพิ่มยอดขาย ลดต้นทุน และหลีกเลี่ยงความเสี่ยง
ซอฟต์แวร์ได้รับรางวัลหลายรางวัล: Gartner Vision Awards 2021 สำหรับวิทยาศาสตร์ข้อมูลและแพลตฟอร์มการเรียนรู้ของเครื่อง การวิเคราะห์เชิงคาดการณ์หลายรูปแบบ และโซลูชันการเรียนรู้ของเครื่องจาก Forrester และแพลตฟอร์มการเรียนรู้ของเครื่องและวิทยาศาสตร์ข้อมูลที่เป็นมิตรต่อผู้ใช้ที่สุดของ Crowd ในรายงาน G2 ฤดูใบไม้ผลิปี 2021
เป็นแพลตฟอร์มแบบ end-to-end สำหรับวงจรชีวิตทางวิทยาศาสตร์และได้รับการบูรณาการและปรับให้เหมาะสมสำหรับการสร้างแบบจำลอง ML (การเรียนรู้ของเครื่อง) อย่างราบรื่น โดยจะจัดทำเอกสารทุกขั้นตอนของการจัดเตรียม การสร้างแบบจำลอง และการตรวจสอบความถูกต้องเพื่อความโปร่งใสอย่างสมบูรณ์
เป็นซอฟต์แวร์แบบชำระเงินที่มีอยู่ในสามเวอร์ชัน: Prep Data, Create and Validate และ Deploy Model มันยังเปิดให้สถาบันการศึกษาฟรีอีกด้วย และ RapidMiner ก็มีมหาวิทยาลัยมากกว่า 4,000 แห่งทั่วโลกใช้งาน
คุณสมบัติ
- ตรวจสอบข้อมูลเพื่อระบุรูปแบบและแก้ไขปัญหาด้านคุณภาพ
- ใช้ตัวออกแบบเวิร์กโฟลว์แบบไม่มีโค้ดพร้อมอัลกอริธึมมากกว่า 1,500 ตัว
- การรวมโมเดลการเรียนรู้ของเครื่องเข้ากับแอปพลิเคชันทางธุรกิจที่มีอยู่
ฉาก
Tableau มอบความยืดหยุ่นในการวิเคราะห์แพลตฟอร์มด้วยสายตา แก้ปัญหา และเสริมพลังผู้คนและองค์กร มันใช้เทคโนโลยี VizQL (ภาษาภาพสำหรับการสืบค้นฐานข้อมูล) ซึ่งแปลงการลากและวางเป็นการสืบค้นข้อมูลผ่านส่วนต่อประสานผู้ใช้ที่ใช้งานง่าย
Tableau ถูกซื้อกิจการโดย Salesforce ในปี 2019 ซึ่งช่วยให้สามารถเชื่อมโยงข้อมูลจากแหล่งที่มาต่างๆ เช่น ฐานข้อมูล SQL สเปรดชีต หรือแอปพลิเคชันระบบคลาวด์ เช่น Google Analytics และ Salesforce
ผู้ใช้สามารถซื้อเวอร์ชัน Creator, Explorer และ Viewer ได้ตามความชอบทางธุรกิจหรือส่วนบุคคล เนื่องจากแต่ละเวอร์ชันมีลักษณะและหน้าที่ต่างกันไป
เหมาะอย่างยิ่งสำหรับนักวิเคราะห์ นักวิทยาศาสตร์ด้านข้อมูล ภาคการศึกษา และผู้ใช้ทางธุรกิจ ในการปรับใช้และสร้างสมดุลระหว่างวัฒนธรรมที่ขับเคลื่อนด้วยข้อมูลและประเมินผลผ่านผลลัพธ์
คุณสมบัติ
- แดชบอร์ดให้ภาพรวมที่สมบูรณ์ของข้อมูลในรูปแบบขององค์ประกอบภาพ วัตถุ และข้อความ
- แผนภูมิข้อมูลที่มีให้เลือกมากมาย: ฮิสโตแกรม แผนภูมิแกนต์ แผนภูมิ แผนภูมิแบบเคลื่อนไหว และอื่นๆ อีกมากมาย
- การป้องกันตัวกรองระดับแถวเพื่อให้ข้อมูลปลอดภัยและเสถียร
- สถาปัตยกรรมนำเสนอการวิเคราะห์และการคาดการณ์ที่คาดการณ์ได้
การเรียนรู้ Tableau เป็นเรื่องง่าย
Cloudera
Cloudera นำเสนอแพลตฟอร์มที่ปลอดภัยสำหรับศูนย์ข้อมูลและคลาวด์สำหรับการจัดการข้อมูลขนาดใหญ่ ใช้การวิเคราะห์ข้อมูลและการเรียนรู้ของเครื่องเพื่อเปลี่ยนข้อมูลที่ซับซ้อนให้เป็นข้อมูลเชิงลึกที่ชัดเจนและนำไปใช้ได้จริง
Cloudera นำเสนอโซลูชันและเครื่องมือสำหรับคลาวด์ส่วนตัวและไฮบริด วิศวกรรมข้อมูล การไหลของข้อมูล การจัดเก็บข้อมูล วิทยาศาสตร์ข้อมูลสำหรับนักวิทยาศาสตร์ข้อมูล และอื่นๆ
แพลตฟอร์มแบบครบวงจรและการวิเคราะห์แบบมัลติฟังก์ชั่นช่วยปรับปรุงกระบวนการค้นพบข้อมูลเชิงลึกที่ขับเคลื่อนด้วยข้อมูล วิทยาศาสตร์ข้อมูลช่วยให้สามารถเชื่อมต่อกับระบบต่างๆ ที่องค์กรใช้ ไม่เพียงแต่ Cloudera และ Hortonworks (ทั้งสองบริษัทเป็นพันธมิตรกัน)
นักวิทยาศาสตร์ข้อมูลจัดการกิจกรรมของตนเอง เช่น การวิเคราะห์ การวางแผน การตรวจสอบ และการแจ้งเตือนทางอีเมลผ่านเวิร์กชีตวิทยาศาสตร์ข้อมูลเชิงโต้ตอบ โดยค่าเริ่มต้น เป็นแพลตฟอร์มที่สอดคล้องกับการรักษาความปลอดภัยที่ช่วยให้นักวิทยาศาสตร์ข้อมูลสามารถเข้าถึงข้อมูล Hadoop และเรียกใช้การสืบค้น Spark ได้อย่างง่ายดาย
แพลตฟอร์มนี้เหมาะสำหรับวิศวกรข้อมูล นักวิทยาศาสตร์ข้อมูล และผู้เชี่ยวชาญด้านไอทีในอุตสาหกรรมต่างๆ เช่น โรงพยาบาล สถาบันการเงิน โทรคมนาคม และอื่นๆ อีกมากมาย
คุณสมบัติ
- รองรับคลาวด์ส่วนตัวและสาธารณะที่สำคัญทั้งหมด ในขณะที่ข้อมูล Science Workbench รองรับการปรับใช้ในสถานที่
- ช่องข้อมูลอัตโนมัติแปลงข้อมูลเป็นรูปแบบที่ใช้งานได้และรวมเข้ากับแหล่งข้อมูลอื่น
- เวิร์กโฟลว์ที่สม่ำเสมอช่วยให้สร้างแบบจำลอง ฝึกอบรม และนำไปใช้งานได้อย่างรวดเร็ว
- สภาพแวดล้อมที่ปลอดภัยสำหรับการรับรองความถูกต้อง การอนุญาต และการเข้ารหัสของ Hadoop
Apache Hive
Apache Hive เป็นโครงการโอเพ่นซอร์สที่พัฒนาบน Apache Hadoop อนุญาตให้อ่าน เขียน และจัดการชุดข้อมูลขนาดใหญ่ที่มีอยู่ในที่เก็บต่างๆ และอนุญาตให้ผู้ใช้รวมฟังก์ชันของตนเองสำหรับการวิเคราะห์ที่กำหนดเอง
Hive ออกแบบมาสำหรับงานพื้นที่จัดเก็บแบบเดิมๆ และไม่ได้มีไว้สำหรับการประมวลผลแบบออนไลน์ ชุดเฟรมที่ทนทานให้ความสามารถในการปรับขนาด ประสิทธิภาพ ความสามารถในการขยาย และความทนทานต่อข้อผิดพลาด
เหมาะสำหรับการดึงข้อมูล การสร้างแบบจำลองการคาดการณ์ และเอกสารการทำดัชนี ไม่แนะนำสำหรับการสืบค้นข้อมูลตามเวลาจริง เนื่องจากจะทำให้เกิดเวลาในการตอบสนองในการรับผลลัพธ์
คุณสมบัติ
- รองรับกลไกประมวลผล MapReduce, Tez และ Spark
- ประมวลผลชุดข้อมูลขนาดใหญ่หลายเพตาไบต์
- เขียนโค้ดได้ง่ายมากเมื่อเทียบกับ Java
- ให้ความทนทานต่อข้อผิดพลาดโดยการจัดเก็บข้อมูลในระบบไฟล์แบบกระจาย Apache Hadoop
Apache Storm
The Storm เป็นแพลตฟอร์มโอเพ่นซอร์สฟรีที่ใช้ในการประมวลผลสตรีมข้อมูลไม่จำกัด มีชุดหน่วยประมวลผลที่เล็กที่สุดที่ใช้ในการพัฒนาแอปพลิเคชันที่สามารถประมวลผลข้อมูลจำนวนมากในแบบเรียลไทม์
พายุเร็วพอที่จะประมวลผลหนึ่งล้านทูเพิลต่อวินาทีต่อโหนด และใช้งานง่าย
Apache Storm ช่วยให้คุณเพิ่มโหนดเพิ่มเติมในคลัสเตอร์ของคุณ และเพิ่มพลังการประมวลผลแอปพลิเคชัน ความสามารถในการประมวลผลสามารถเพิ่มขึ้นเป็นสองเท่าโดยการเพิ่มโหนดเนื่องจากความสามารถในการปรับขยายในแนวนอนจะยังคงอยู่
นักวิทยาศาสตร์ด้านข้อมูลสามารถใช้ Storm สำหรับ DRPC (การเรียกขั้นตอนระยะไกลแบบกระจาย) การวิเคราะห์ ETL แบบเรียลไทม์ (การดึงข้อมูล-การแปลง-โหลด) การคำนวณแบบต่อเนื่อง การเรียนรู้ของเครื่องออนไลน์ ฯลฯ มันถูกตั้งค่าให้ตอบสนองความต้องการการประมวลผลแบบเรียลไทม์ของ Twitter , Yahoo และ Flipboard
คุณสมบัติ
- ใช้งานง่ายด้วยภาษาการเขียนโปรแกรมใด ๆ
- มันถูกรวมเข้ากับทุกระบบการเข้าคิวและทุกฐานข้อมูล
- Storm ใช้ Zookeeper เพื่อจัดการคลัสเตอร์และปรับขนาดเป็นคลัสเตอร์ที่ใหญ่ขึ้น
- การปกป้องข้อมูลที่รับประกันจะแทนที่ tuples ที่สูญหายหากมีสิ่งผิดปกติเกิดขึ้น
วิทยาศาสตร์ข้อมูลเกล็ดหิมะ
ความท้าทายที่ใหญ่ที่สุดสำหรับนักวิทยาศาสตร์ด้านข้อมูลคือการเตรียมข้อมูลจากแหล่งข้อมูลต่างๆ เนื่องจากใช้เวลาสูงสุดในการดึง รวบรวม ทำความสะอาด และเตรียมข้อมูล มันถูกกล่าวถึงโดย Snowflake

มีแพลตฟอร์มประสิทธิภาพสูงเพียงแพลตฟอร์มเดียวที่ช่วยขจัดความยุ่งยากและความล่าช้าที่เกิดจาก ETL (การแปลงโหลดและการดึงข้อมูล) นอกจากนี้ยังสามารถรวมเข้ากับเครื่องมือและไลบรารีล่าสุดของแมชชีนเลิร์นนิง (ML) เช่น Dask และ Saturn Cloud
Snowflake นำเสนอสถาปัตยกรรมเฉพาะของคลัสเตอร์การประมวลผลเฉพาะสำหรับปริมาณงานแต่ละรายการเพื่อดำเนินกิจกรรมการประมวลผลระดับสูงดังกล่าว ดังนั้นจึงไม่มีการแบ่งปันทรัพยากรระหว่างปริมาณงานด้านวิทยาศาสตร์ข้อมูลและ BI (ข่าวกรองธุรกิจ)
รองรับประเภทข้อมูลจากแบบมีโครงสร้าง กึ่งโครงสร้าง (JSON, Avro, ORC, Parquet หรือ XML) และข้อมูลที่ไม่มีโครงสร้าง ใช้กลยุทธ์ Data Lake เพื่อปรับปรุงการเข้าถึงข้อมูล ประสิทธิภาพ และความปลอดภัย
นักวิทยาศาสตร์ข้อมูลและนักวิเคราะห์ใช้เกล็ดหิมะในอุตสาหกรรมต่างๆ รวมถึงการเงิน สื่อและความบันเทิง การค้าปลีก วิทยาศาสตร์สุขภาพและชีวิต เทคโนโลยี และภาครัฐ
คุณสมบัติ
- การบีบอัดข้อมูลสูงเพื่อลดต้นทุนการจัดเก็บ
- ให้การเข้ารหัสข้อมูลที่หยุดนิ่งและอยู่ระหว่างการส่ง
- เอ็นจิ้นการประมวลผลที่รวดเร็วพร้อมความซับซ้อนในการปฏิบัติงานต่ำ
- การทำโปรไฟล์ข้อมูลแบบบูรณาการพร้อมมุมมองตาราง แผนภูมิ และฮิสโตแกรม
ดาต้าโรบอท
Datarobot เป็นผู้นำระดับโลกในระบบคลาวด์ด้วย AI (ปัญญาประดิษฐ์) แพลตฟอร์มที่เป็นเอกลักษณ์ได้รับการออกแบบเพื่อรองรับทุกอุตสาหกรรม รวมถึงผู้ใช้และข้อมูลประเภทต่างๆ
บริษัทอ้างว่าซอฟต์แวร์นี้ถูกใช้โดยหนึ่งในสามของบริษัทที่ติดอันดับ Fortune 50 และให้ค่าประมาณมากกว่าหนึ่งล้านล้านในอุตสาหกรรมต่างๆ
Dataroabot ใช้แมชชีนเลิร์นนิงอัตโนมัติ (ML) และออกแบบมาสำหรับผู้เชี่ยวชาญด้านข้อมูลระดับองค์กร เพื่อสร้าง ปรับเปลี่ยน และปรับใช้โมเดลการคาดการณ์ที่แม่นยำอย่างรวดเร็ว
ช่วยให้นักวิทยาศาสตร์เข้าถึงอัลกอริธึมการเรียนรู้ของเครื่องล่าสุดได้อย่างง่ายดายด้วยความโปร่งใสอย่างสมบูรณ์ในการประมวลผลข้อมูลล่วงหน้าโดยอัตโนมัติ ซอฟต์แวร์ได้พัฒนาไคลเอนต์ R และ Python โดยเฉพาะสำหรับนักวิทยาศาสตร์ในการแก้ปัญหาด้านวิทยาศาสตร์ข้อมูลที่ซับซ้อน
ช่วยให้คุณภาพข้อมูล วิศวกรรมคุณลักษณะ และขั้นตอนการใช้งานเป็นไปโดยอัตโนมัติ เพื่อความสะดวกในกิจกรรมของนักวิทยาศาสตร์ข้อมูล เป็นผลิตภัณฑ์ระดับพรีเมียมและสามารถขอราคาได้
คุณสมบัติ
- เพิ่มมูลค่าทางธุรกิจในแง่ของความสามารถในการทำกำไร การคาดการณ์ที่ง่ายขึ้น
- กระบวนการดำเนินการและระบบอัตโนมัติ
- รองรับอัลกอริธึมจาก Python, Spark, TensorFlow และแหล่งอื่นๆ
- การรวม API ให้คุณเลือกจากหลายร้อยรุ่น
TensorFlow
TensorFlow เป็นไลบรารีที่ใช้ AI ของชุมชน (ปัญญาประดิษฐ์) ที่ใช้ไดอะแกรมโฟลว์ข้อมูลเพื่อสร้าง ฝึกอบรม และปรับใช้แอปพลิเคชันการเรียนรู้ของเครื่อง (ML) ซึ่งช่วยให้นักพัฒนาสามารถสร้างโครงข่ายประสาทเทียมขนาดใหญ่ได้
ประกอบด้วยสามรุ่น ได้แก่ TensorFlow.js, TensorFlow Lite และ TensorFlow Extended (TFX) โหมดจาวาสคริปต์ใช้สำหรับการฝึกอบรมและปรับใช้โมเดลในเบราว์เซอร์และบน Node.js พร้อมกัน โหมด lite ใช้สำหรับปรับใช้โมเดลบนอุปกรณ์พกพาและอุปกรณ์ฝังตัว และโมเดล TFX ใช้สำหรับเตรียมข้อมูล ตรวจสอบ และปรับใช้โมเดล
เนื่องจากแพลตฟอร์มที่แข็งแกร่ง จึงสามารถปรับใช้บนเซิร์ฟเวอร์ อุปกรณ์ Edge หรือเว็บโดยไม่คำนึงถึงภาษาการเขียนโปรแกรม
TFX มีกลไกในการบังคับใช้ไปป์ไลน์ ML ที่สามารถขึ้นไปได้และมีหน้าที่ด้านประสิทธิภาพโดยรวมที่แข็งแกร่ง ไปป์ไลน์วิศวกรรมข้อมูล เช่น Kubeflow และ Apache Airflow รองรับ TFX
แพลตฟอร์ม Tensorflow เหมาะสำหรับมือใหม่ ระดับกลางและสำหรับผู้เชี่ยวชาญในการฝึกอบรมเครือข่ายปฏิปักษ์ generative เพื่อสร้างภาพตัวเลขที่เขียนด้วยลายมือโดยใช้ Keras
คุณสมบัติ
- ปรับใช้โมเดล ML ในสถานที่ คลาวด์ และในเบราว์เซอร์ได้โดยไม่คำนึงถึงภาษา
- การสร้างแบบจำลองอย่างง่ายโดยใช้ API ดั้งเดิมเพื่อการทำซ้ำของแบบจำลองอย่างรวดเร็ว
- ไลบรารีและโมเดลเสริมต่างๆ ที่สนับสนุนกิจกรรมการวิจัยเพื่อการทดลอง
- การสร้างแบบจำลองอย่างง่ายโดยใช้นามธรรมหลายระดับ
Matplotlib
Matplotlib เป็นซอฟต์แวร์ชุมชนที่ครอบคลุมสำหรับการแสดงข้อมูลภาพเคลื่อนไหวและกราฟิกกราฟิกสำหรับภาษาการเขียนโปรแกรม Python การออกแบบที่เป็นเอกลักษณ์มีโครงสร้างเพื่อให้สร้างกราฟข้อมูลภาพโดยใช้โค้ดไม่กี่บรรทัด
มีแอปพลิเคชั่นของบริษัทอื่นมากมาย เช่น โปรแกรมวาดภาพ GUI แผนที่สี แอนิเมชั่น และอื่นๆ อีกมากมายที่ออกแบบมาเพื่อผสานรวมกับ Matplotlib
สามารถขยายฟังก์ชันการทำงานด้วยเครื่องมือมากมาย เช่น Basemap, Cartopy, GTK-Tools, Natgrid, Seaborn และอื่นๆ
คุณสมบัติที่ดีที่สุด ได้แก่ การวาดกราฟและแผนที่ด้วยข้อมูลที่มีโครงสร้างและไม่มีโครงสร้าง
Bigml
Bigml เป็นแพลตฟอร์มที่โปร่งใสสำหรับวิศวกร นักวิทยาศาสตร์ข้อมูล นักพัฒนา และนักวิเคราะห์ มันทำการแปลงข้อมูลแบบ end-to-end เป็นแบบจำลองที่สามารถดำเนินการได้
มันสร้าง ทดลอง ทำให้เป็นอัตโนมัติ และจัดการเวิร์กโฟลว์ ml อย่างมีประสิทธิภาพ ซึ่งเอื้อต่อการใช้งานอัจฉริยะในอุตสาหกรรมที่หลากหลาย
แพลตฟอร์ม ML (แมชชีนเลิร์นนิง) ที่ตั้งโปรแกรมได้นี้ช่วยในการจัดลำดับ การทำนายอนุกรมเวลา การตรวจจับการเชื่อมโยง การถดถอย การวิเคราะห์คลัสเตอร์ และอื่นๆ
เวอร์ชันที่จัดการได้อย่างสมบูรณ์พร้อมผู้เช่ารายเดียวและหลายราย และการปรับใช้ที่เป็นไปได้ครั้งเดียวสำหรับผู้ให้บริการระบบคลาวด์ใดๆ ทำให้องค์กรต่างๆ เข้าถึงข้อมูลขนาดใหญ่ได้ง่ายสำหรับองค์กร
ราคาเริ่มต้นที่ $30 และฟรีสำหรับชุดข้อมูลขนาดเล็กและเพื่อการศึกษา และใช้ในมหาวิทยาลัยมากกว่า 600 แห่ง
เนื่องจากอัลกอริธึม ML ที่ออกแบบทางวิศวกรรมที่แข็งแกร่ง จึงเหมาะสำหรับอุตสาหกรรมต่างๆ เช่น เภสัชกรรม ความบันเทิง ยานยนต์ อวกาศ การดูแลสุขภาพ IoT และอื่นๆ อีกมากมาย
คุณสมบัติ
- ทำให้เวิร์กโฟลว์ที่ใช้เวลานานและซับซ้อนเป็นอัตโนมัติในการเรียก API ครั้งเดียว
- สามารถประมวลผลข้อมูลจำนวนมากและทำงานแบบคู่ขนาน
- ไลบรารี่ได้รับการสนับสนุนโดยภาษาโปรแกรมยอดนิยม เช่น Python, Node.js, Ruby, Java, Swift เป็นต้น
- รายละเอียดปลีกย่อยช่วยให้งานตรวจสอบและข้อกำหนดด้านกฎระเบียบง่ายขึ้น
Apache Spark
เป็นหนึ่งในเอ็นจิ้นโอเพนซอร์ซที่ใหญ่ที่สุดที่บริษัทขนาดใหญ่ใช้กันอย่างแพร่หลาย Spark ถูกใช้โดย 80% ของ Fortune 500 บริษัท ตามเว็บไซต์ เข้ากันได้กับโหนดเดียวและคลัสเตอร์สำหรับข้อมูลขนาดใหญ่และ ML
มันใช้ SQL ขั้นสูง (Structured Query Language) เพื่อรองรับข้อมูลจำนวนมากและทำงานกับตารางที่มีโครงสร้างและข้อมูลที่ไม่มีโครงสร้าง
แพลตฟอร์ม Spark ขึ้นชื่อเรื่องความง่ายในการใช้งาน ชุมชนขนาดใหญ่ และความเร็วสูง นักพัฒนาใช้ Spark เพื่อสร้างแอปพลิเคชันและเรียกใช้การสืบค้นใน Java, Scala, Python, R และ SQL
คุณสมบัติ
- ประมวลผลข้อมูลเป็นชุดและแบบเรียลไทม์
- รองรับข้อมูลจำนวนมหาศาลโดยไม่ต้องสุ่มตัวอย่าง
- ทำให้ง่ายต่อการรวมหลายไลบรารี เช่น SQL, MLib, Graphx และ Stream ไว้ในเวิร์กโฟลว์เดียว
- ทำงานบน Hadoop YARN, Apache Mesos, Kubernetes และแม้แต่ในระบบคลาวด์และสามารถเข้าถึงแหล่งข้อมูลได้หลายแหล่ง
ไนม์
Konstanz Information Miner เป็นแพลตฟอร์มโอเพ่นซอร์สที่ใช้งานง่ายสำหรับแอปพลิเคชันวิทยาศาสตร์ข้อมูล นักวิทยาศาสตร์ข้อมูลและนักวิเคราะห์สามารถสร้างเวิร์กโฟลว์แบบเห็นภาพโดยไม่ต้องเขียนโค้ดด้วยฟังก์ชันการลากแล้ววางที่เรียบง่าย
เวอร์ชันเซิร์ฟเวอร์เป็นแพลตฟอร์มการซื้อขายที่ใช้สำหรับระบบอัตโนมัติ การจัดการวิทยาศาสตร์ข้อมูล และการวิเคราะห์การจัดการ KNIME ทำให้ทุกคนสามารถเข้าถึงเวิร์กโฟลว์วิทยาศาสตร์ข้อมูลและส่วนประกอบที่นำกลับมาใช้ใหม่ได้
คุณสมบัติ
- มีความยืดหยุ่นสูงสำหรับการรวมข้อมูลจาก Oracle, SQL, Hive และอื่นๆ
- เข้าถึงข้อมูลจากหลายแหล่ง เช่น SharePoint, Amazon Cloud, Salesforce, Twitter และอื่นๆ
- การใช้ ml อยู่ในรูปแบบของการสร้างแบบจำลอง การปรับแต่งประสิทธิภาพ และการตรวจสอบแบบจำลอง
- ข้อมูลเชิงลึกในรูปแบบของการแสดงภาพ สถิติ การประมวลผล และการรายงาน
ความสำคัญของ 5 V ของข้อมูลขนาดใหญ่คืออะไร?
บิ๊กดาต้า 5 V ช่วยให้นักวิทยาศาสตร์ข้อมูลเข้าใจและวิเคราะห์ข้อมูลขนาดใหญ่เพื่อให้ได้ข้อมูลเชิงลึกมากขึ้น นอกจากนี้ยังช่วยให้สถิติมีประโยชน์มากขึ้นสำหรับธุรกิจในการตัดสินใจอย่างมีข้อมูลและได้เปรียบในการแข่งขัน
ปริมาณ: ข้อมูลขนาดใหญ่ขึ้นอยู่กับปริมาณ ปริมาณควอนตัมกำหนดขนาดของข้อมูล โดยปกติแล้วจะมีข้อมูลจำนวนมากในหน่วยเทราไบต์ เพทาไบต์ ฯลฯ นักวิทยาศาสตร์ข้อมูลจะวางแผนเครื่องมือและการผสานรวมต่างๆ สำหรับการวิเคราะห์ชุดข้อมูลโดยอิงจากขนาดไดรฟ์ข้อมูล
ความเร็ว: ความเร็วในการรวบรวมข้อมูลมีความสำคัญเนื่องจากบางบริษัทต้องการข้อมูลข้อมูลแบบเรียลไทม์ และบริษัทอื่นๆ ต้องการประมวลผลข้อมูลในแพ็คเก็ต ยิ่งการไหลของข้อมูลเร็วเท่าใด นักวิทยาศาสตร์ด้านข้อมูลก็สามารถประเมินและให้ข้อมูลที่เกี่ยวข้องแก่บริษัทได้มากขึ้นเท่านั้น
ความ หลากหลาย: ข้อมูลมาจากแหล่งต่างๆ และที่สำคัญ ไม่ใช่ในรูปแบบตายตัว ข้อมูลมีอยู่ในรูปแบบที่มีโครงสร้าง (รูปแบบฐานข้อมูล) กึ่งโครงสร้าง (XML/RDF) และไม่มีโครงสร้าง (ข้อมูลไบนารี) ตามโครงสร้างข้อมูล เครื่องมือบิ๊กดาต้าถูกใช้เพื่อสร้าง จัดระเบียบ กรอง และประมวลผลข้อมูล
ความถูกต้อง : ความถูกต้องของข้อมูลและแหล่งข้อมูลที่น่าเชื่อถือจะกำหนดบริบทของข้อมูลขนาดใหญ่ ชุดข้อมูลมาจากแหล่งต่างๆ เช่น คอมพิวเตอร์ อุปกรณ์เครือข่าย อุปกรณ์เคลื่อนที่ โซเชียลมีเดีย เป็นต้น ดังนั้น ข้อมูลจึงต้องวิเคราะห์เพื่อส่งข้อมูลไปยังปลายทาง
ความ คุ้มค่า: สุดท้ายนี้ Big Data ของบริษัทมีมูลค่าเท่าไร? บทบาทของนักวิทยาศาสตร์ข้อมูลคือการใช้ข้อมูลให้เกิดประโยชน์สูงสุดเพื่อแสดงให้เห็นว่าข้อมูลเชิงลึกสามารถเพิ่มมูลค่าให้กับธุรกิจได้อย่างไร
บทสรุป
รายการข้อมูลขนาดใหญ่ด้านบนรวมถึงเครื่องมือที่ต้องชำระเงินและเครื่องมือโอเพ่นซอร์ส มีข้อมูลโดยย่อและฟังก์ชันสำหรับแต่ละเครื่องมือ หากคุณกำลังมองหาข้อมูลเชิงพรรณนา คุณสามารถเยี่ยมชมเว็บไซต์ที่เกี่ยวข้อง
บริษัทต่างๆ ที่ต้องการความได้เปรียบในการแข่งขันจะใช้บิ๊กดาต้าและเครื่องมือที่เกี่ยวข้อง เช่น AI (ปัญญาประดิษฐ์), ML (การเรียนรู้ของเครื่อง) และเทคโนโลยีอื่นๆ เพื่อดำเนินการทางยุทธวิธีเพื่อปรับปรุงการบริการลูกค้า การวิจัย การตลาด การวางแผนในอนาคต ฯลฯ
เครื่องมือบิ๊กดาต้าถูกใช้ในอุตสาหกรรมส่วนใหญ่ เนื่องจากการเปลี่ยนแปลงเล็กๆ น้อยๆ ในด้านผลิตภาพสามารถแปลเป็นการประหยัดที่สำคัญและผลกำไรมหาศาล เราหวังว่าบทความข้างต้นจะให้ภาพรวมของเครื่องมือข้อมูลขนาดใหญ่และความสำคัญของเครื่องมือเหล่านี้แก่คุณ
คุณอาจชอบ:
หลักสูตรออนไลน์เพื่อเรียนรู้พื้นฐานของ Data Engineering