
13 narzędzi Big Data, które warto znać jako specjalista ds. danych
Opublikowany: 2021-11-30W erze informacji centra danych gromadzą duże ilości danych. Gromadzone dane pochodzą z różnych źródeł, takich jak transakcje finansowe, interakcje z klientami, media społecznościowe i wiele innych, a co ważniejsze, szybciej się gromadzą.
Dane mogą być zróżnicowane i wrażliwe oraz wymagają odpowiednich narzędzi, aby były znaczące, ponieważ mają nieograniczony potencjał w zakresie modernizacji statystyk biznesowych, informacji i zmiany życia.

Narzędzia Big Data i analitycy danych są w takich scenariuszach ważni.
Tak duża ilość różnorodnych danych utrudnia przetwarzanie przy użyciu tradycyjnych narzędzi i technik, takich jak Excel. Excel tak naprawdę nie jest bazą danych i ma limit (65 536 wierszy) przechowywania danych.
Analiza danych w programie Excel pokazuje słabą integralność danych. Na dłuższą metę dane przechowywane w programie Excel mają ograniczone zabezpieczenia i zgodność, bardzo niskie wskaźniki odzyskiwania po awarii i brak odpowiedniej kontroli wersji.
Aby przetworzyć tak duże i zróżnicowane zbiory danych, potrzebny jest unikalny zestaw narzędzi, zwanych narzędziami danych, do badania, przetwarzania i wydobywania cennych informacji. Te narzędzia pozwalają zagłębić się w dane, aby znaleźć bardziej znaczące informacje i wzorce danych.
Radzenie sobie z tak złożonymi narzędziami technologicznymi i danymi w naturalny sposób wymaga wyjątkowego zestawu umiejętności i właśnie dlatego naukowcy zajmujący się danymi odgrywają kluczową rolę w Big Data.
Znaczenie narzędzi big data
Dane są elementem składowym każdej organizacji i służą do wydobywania cennych informacji, wykonywania szczegółowych analiz, tworzenia możliwości oraz planowania nowych kamieni milowych i wizji biznesowych.
Każdego dnia powstaje coraz więcej danych, które muszą być skutecznie i bezpiecznie przechowywane oraz przywoływane w razie potrzeby. Rozmiar, różnorodność i szybka zmiana tych danych wymagają nowych narzędzi do Big Data, różnych metod przechowywania i analizy.
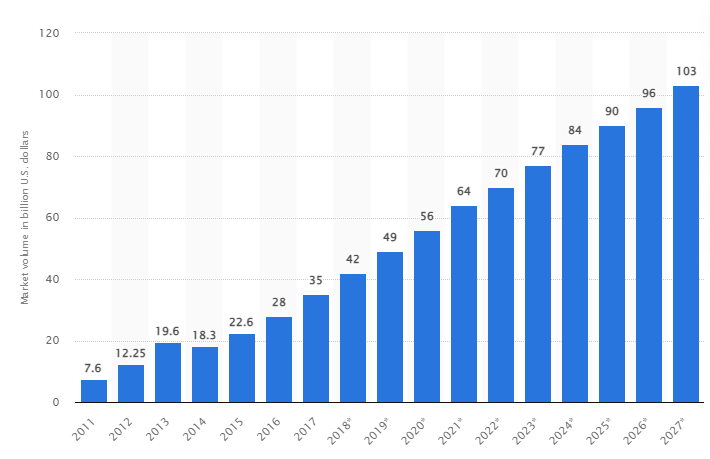
Według badania, globalny rynek Big Data ma wzrosnąć do 103 miliardów dolarów do 2027 roku, czyli ponad dwukrotnie więcej niż oczekiwano w 2018 roku.
Dzisiejsze wyzwania branżowe
Termin „duże zbiory danych” był ostatnio używany w odniesieniu do zestawów danych, które urosły tak duże, że trudno jest ich używać w tradycyjnych systemach zarządzania bazami danych (DBMS).
Rozmiary danych stale rosną i obecnie wahają się od dziesiątek terabajtów (TB) do wielu petabajtów (PB) w pojedynczym zestawie danych. Rozmiar tych zestawów danych przekracza możliwości zwykłego oprogramowania do przetwarzania, zarządzania, wyszukiwania, udostępniania i wizualizacji w czasie.
Powstawanie big data doprowadzi do:
- Zarządzanie jakością i doskonalenie
- Zarządzanie łańcuchem dostaw i wydajnością
- Inteligencja klienta
- Analiza danych i podejmowanie decyzji
- Zarządzanie ryzykiem i wykrywanie oszustw
W tej sekcji przyjrzymy się najlepszym narzędziom Big Data oraz sposobom wykorzystywania tych technologii przez analityków danych do ich filtrowania, analizowania, przechowywania i wyodrębniania, gdy firmy chcą pogłębić analizę w celu poprawy i rozwoju ich działalności.
Apache Hadoop
Apache Hadoop to platforma Java typu open source, która przechowuje i przetwarza duże ilości danych.
Hadoop działa poprzez mapowanie dużych zestawów danych (od terabajtów do petabajtów), analizowanie zadań między klastrami i dzielenie ich na mniejsze porcje (od 64 MB do 128 MB), co skutkuje szybszym przetwarzaniem danych.
Aby przechowywać i przetwarzać dane, dane są wysyłane do klastra Hadoop, HDFS (rozproszony system plików Hadoop) przechowuje dane, MapReduce przetwarza dane, a YARN (kolejny negocjator zasobów) dzieli zadania i przypisuje zasoby.
Jest odpowiedni dla naukowców zajmujących się danymi, programistów i analityków z różnych firm i organizacji do badań i produkcji.
Cechy
- Replikacja danych: wiele kopii bloku jest przechowywanych w różnych węzłach i służy jako odporność na awarie w przypadku błędu.
- Wysoce skalowalny: oferuje skalowalność w pionie i poziomie
- Integracja z innymi modelami Apache, Cloudera i Hortonworks
Rozważ udział w tym genialnym kursie online, aby nauczyć się Big Data z Apache Spark.
Rapidminer
Witryna Rapidminer twierdzi, że około 40 000 organizacji na całym świecie wykorzystuje swoje oprogramowanie do zwiększania sprzedaży, obniżania kosztów i unikania ryzyka.
Oprogramowanie otrzymało kilka nagród: Gartner Vision Awards 2021 za platformy nauki danych i uczenia maszynowego, multimodalną analizę predykcyjną oraz rozwiązania do uczenia maszynowego od najbardziej przyjaznej dla użytkownika platformy uczenia maszynowego i nauki danych firmy Forrester i Crowd w wiosennym raporcie G2 2021.
Jest to kompleksowa platforma dla naukowego cyklu życia i jest bezproblemowo zintegrowana i zoptymalizowana pod kątem budowania modeli ML (uczenia maszynowego). Automatycznie dokumentuje każdy etap przygotowania, modelowania i walidacji, zapewniając pełną przejrzystość.
Jest to płatne oprogramowanie dostępne w trzech wersjach: Prep Data, Create and Validate oraz Deploy Model. Jest nawet dostępny bezpłatnie dla instytucji edukacyjnych, a RapidMiner jest używany przez ponad 4000 uniwersytetów na całym świecie.
Cechy
- Sprawdza dane, aby zidentyfikować wzorce i naprawić problemy z jakością
- Używa bezkodowego projektanta przepływu pracy z ponad 1500 algorytmami
- Integracja modeli uczenia maszynowego z istniejącymi aplikacjami biznesowymi
Żywy obraz
Tableau zapewnia elastyczność wizualnej analizy platform, rozwiązywania problemów oraz wzmacniania pozycji ludzi i organizacji. Opiera się na technologii VizQL (wizualny język zapytań do bazy danych), która za pomocą intuicyjnego interfejsu użytkownika przekształca przeciąganie i upuszczanie na zapytania danych.
Tableau zostało przejęte przez Salesforce w 2019 roku. Umożliwia łączenie danych ze źródeł takich jak bazy danych SQL, arkusze kalkulacyjne czy aplikacje chmurowe, takie jak Google Analytics i Salesforce.
Użytkownicy mogą kupować jego wersje Creator, Explorer i Viewer w oparciu o preferencje biznesowe lub indywidualne, ponieważ każda z nich ma swoje własne cechy i funkcje.
Jest to idealne rozwiązanie dla analityków, naukowców zajmujących się danymi, sektora edukacji i użytkowników biznesowych, aby wdrożyć i zrównoważyć kulturę opartą na danych oraz ocenić ją na podstawie wyników.
Cechy
- Pulpity nawigacyjne zapewniają pełny przegląd danych w postaci elementów wizualnych, obiektów i tekstu.
- Duży wybór wykresów danych: histogramy, wykresy Gantta, wykresy, wykresy ruchome i wiele innych
- Ochrona filtra na poziomie rzędu w celu zapewnienia bezpieczeństwa i stabilności danych
- Jego architektura zapewnia przewidywalną analizę i prognozowanie
Nauka Tableau jest łatwa.
Cloudera
Cloudera oferuje bezpieczną platformę dla chmury i centrów danych do zarządzania dużymi danymi. Wykorzystuje analitykę danych i uczenie maszynowe, aby przekształcać złożone dane w jasne, praktyczne spostrzeżenia.
Cloudera oferuje rozwiązania i narzędzia dla chmur prywatnych i hybrydowych, inżynierii danych, przepływu danych, przechowywania danych, nauki o danych dla naukowców zajmujących się danymi i nie tylko.
Ujednolicona platforma i wielofunkcyjne narzędzia analityczne usprawniają oparty na danych proces odkrywania wglądu. Jej nauka o danych zapewnia łączność z dowolnym systemem, z którego korzysta organizacja, nie tylko Cloudera i Hortonworks (obie firmy nawiązały współpracę).
Analitycy danych zarządzają własnymi działaniami, takimi jak analiza, planowanie, monitorowanie i powiadomienia e-mail za pomocą interaktywnych arkuszy analizy danych. Domyślnie jest to platforma zgodna z zabezpieczeniami, która umożliwia analitykom danych dostęp do danych Hadoop i łatwe uruchamianie zapytań Spark.
Platforma jest odpowiednia dla inżynierów danych, naukowców zajmujących się danymi i specjalistów IT w różnych branżach, takich jak szpitale, instytucje finansowe, telekomunikacja i wiele innych.
Cechy
- Obsługuje wszystkie główne chmury prywatne i publiczne, a środowisko pracy Data Science obsługuje wdrożenia lokalne
- Zautomatyzowane kanały danych przekształcają dane w użyteczne formularze i integrują je z innymi źródłami.
- Jednolity przepływ pracy pozwala na szybkie tworzenie, szkolenie i wdrażanie modeli.
- Bezpieczne środowisko do uwierzytelniania, autoryzacji i szyfrowania Hadoop
Ula Apache
Apache Hive to projekt open-source opracowany na bazie Apache Hadoop. Umożliwia odczytywanie, zapisywanie i zarządzanie dużymi zestawami danych dostępnymi w różnych repozytoriach oraz umożliwia użytkownikom łączenie własnych funkcji w celu niestandardowej analizy.
Hive jest przeznaczony do tradycyjnych zadań związanych z przechowywaniem i nie jest przeznaczony do zadań przetwarzania online. Jego solidne ramki wsadowe zapewniają skalowalność, wydajność, skalowalność i odporność na błędy.
Nadaje się do ekstrakcji danych, modelowania predykcyjnego i indeksowania dokumentów. Niezalecane do wykonywania zapytań o dane w czasie rzeczywistym, ponieważ wprowadza opóźnienia w uzyskiwaniu wyników.
Cechy
- Obsługuje silnik obliczeniowy MapReduce, Tez i Spark
- Przetwarzaj ogromne zbiory danych o rozmiarze kilku petabajtów
- Bardzo łatwy do kodowania w porównaniu do Javy
- Zapewnia odporność na błędy dzięki przechowywaniu danych w rozproszonym systemie plików Apache Hadoop
Burza Apaczów
The Storm to bezpłatna platforma typu open source służąca do przetwarzania nieograniczonej liczby strumieni danych. Zapewnia najmniejszy zestaw jednostek przetwarzania używanych do tworzenia aplikacji, które mogą przetwarzać bardzo duże ilości danych w czasie rzeczywistym.
Burza jest wystarczająco szybka, aby przetworzyć milion krotek na sekundę na węzeł, i jest łatwa w obsłudze.
Apache Storm umożliwia dodanie większej liczby węzłów do klastra i zwiększenie mocy przetwarzania aplikacji. Wydajność przetwarzania można podwoić, dodając węzły, gdy zachowana jest skalowalność pozioma.
Analitycy danych mogą używać Storm do DRPC (Distributed Remote Procedure Calls), analizy ETL w czasie rzeczywistym (Retrieval-Conversion-Load), ciągłych obliczeń, uczenia maszynowego online itp. Jest on skonfigurowany tak, aby sprostać wymaganiom Twittera w zakresie przetwarzania w czasie rzeczywistym , Yahoo i Flipboard.
Cechy
- Łatwy w użyciu z dowolnym językiem programowania
- Jest zintegrowany z każdym systemem kolejkowym i każdą bazą danych.
- Storm używa Zookeeper do zarządzania klastrami i skalowania do większych rozmiarów klastrów
- Gwarantowana ochrona danych zastępuje utracone krotki, jeśli coś pójdzie nie tak
Nauka o danych płatków śniegu
Największym wyzwaniem dla analityków danych jest przygotowywanie danych z różnych zasobów, ponieważ maksymalny czas poświęca się na pobieranie, konsolidację, czyszczenie i przygotowywanie danych. Jest adresowany przez Snowflake.

Oferuje pojedynczą platformę o wysokiej wydajności, która eliminuje problemy i opóźnienia spowodowane przez ETL (Load Transformation and Extraction). Można go również zintegrować z najnowszymi narzędziami i bibliotekami uczenia maszynowego (ML), takimi jak Dask i Saturn Cloud.
Snowflake oferuje unikalną architekturę dedykowanych klastrów obliczeniowych dla każdego obciążenia w celu wykonywania takich czynności obliczeniowych na wysokim poziomie, dzięki czemu nie ma współdzielenia zasobów między obciążeniami związanymi z analizą danych i analizą biznesową (Business Intelligence).
Obsługuje typy danych z ustrukturyzowanych, częściowo ustrukturyzowanych (JSON, Avro, ORC, Parquet lub XML) i nieustrukturyzowanych. Wykorzystuje strategię jeziora danych w celu poprawy dostępu do danych, wydajności i bezpieczeństwa.
Naukowcy i analitycy danych wykorzystują płatki śniegu w różnych branżach, w tym w finansach, mediach i rozrywce, handlu detalicznym, naukach o zdrowiu i naukach przyrodniczych, technologii i sektorze publicznym.
Cechy
- Wysoka kompresja danych w celu obniżenia kosztów przechowywania
- Zapewnia szyfrowanie danych w spoczynku i podczas przesyłania
- Szybki silnik przetwarzania o niskiej złożoności operacyjnej
- Zintegrowane profilowanie danych z widokami tabeli, wykresu i histogramu
Datarobot
Datarobot to światowy lider w chmurze z AI (sztuczną inteligencją). Jego unikalna platforma jest przeznaczona do obsługi wszystkich branż, w tym użytkowników i różnych rodzajów danych.
Firma twierdzi, że oprogramowanie jest używane przez jedną trzecią firm z listy Fortune 50 i dostarcza ponad bilion szacunków w różnych branżach.
Dataroabot wykorzystuje zautomatyzowane uczenie maszynowe (ML) i jest przeznaczony dla specjalistów ds. danych w przedsiębiorstwach, aby szybko tworzyć, dostosowywać i wdrażać dokładne modele prognoz.
Zapewnia naukowcom łatwy dostęp do wielu najnowszych algorytmów uczenia maszynowego z pełną przejrzystością w celu zautomatyzowania wstępnego przetwarzania danych. Oprogramowanie opracowało dedykowanych klientów R i Python dla naukowców do rozwiązywania złożonych problemów związanych z nauką o danych.
Pomaga zautomatyzować jakość danych, inżynierię funkcji i procesy wdrożeniowe, aby ułatwić pracę naukowcom zajmującym się danymi. Jest to produkt premium, a cena dostępna na zamówienie.
Cechy
- Zwiększa wartość biznesową pod względem rentowności, uproszczone prognozowanie
- Procesy wdrożeniowe i automatyzacja
- Obsługuje algorytmy z Python, Spark, TensorFlow i innych źródeł.
- Integracja API pozwala wybierać spośród setek modeli
Przepływ Tensora
TensorFlow to biblioteka oparta na społeczności AI (sztucznej inteligencji), która wykorzystuje diagramy przepływu danych do tworzenia, trenowania i wdrażania aplikacji uczenia maszynowego (ML). Pozwala to programistom na tworzenie dużych warstwowych sieci neuronowych.
Obejmuje trzy modele – TensorFlow.js, TensorFlow Lite i TensorFlow Extended (TFX). Jego tryb javascript jest używany do uczenia i wdrażania modeli jednocześnie w przeglądarce i na Node.js. Jego tryb lite służy do wdrażania modeli na urządzeniach mobilnych i wbudowanych, a model TFX służy do przygotowywania danych, walidacji i wdrażania modeli.
Dzięki solidnej platformie może być wdrażany na serwerach, urządzeniach brzegowych lub w sieci, niezależnie od języka programowania.
TFX zawiera mechanizmy wymuszające potoki ML, które można wznosić i zapewniać solidne ogólne obowiązki związane z wydajnością. Potoki inżynierii danych, takie jak Kubeflow i Apache Airflow, obsługują TFX.
Platforma Tensorflow jest odpowiednia dla początkujących. Średniozaawansowany i dla ekspertów, aby wyszkolić generatywną sieć przeciwników w celu generowania obrazów odręcznych cyfr za pomocą Keras.
Cechy
- Może wdrażać modele ML lokalnie, w chmurze i w przeglądarce, niezależnie od języka
- Łatwe budowanie modelu przy użyciu wbudowanych interfejsów API do szybkiego powtarzania modelu
- Różne dodatkowe biblioteki i modele wspierają działania badawcze w celu eksperymentowania
- Łatwe budowanie modelu przy użyciu wielu poziomów abstrakcji
Matplotlib
Matplotlib to kompleksowe oprogramowanie społecznościowe do wizualizacji animowanych danych i grafiki dla języka programowania Python. Jego unikalny projekt jest skonstruowany tak, że wizualny wykres danych jest generowany za pomocą kilku linijek kodu.
Istnieją różne aplikacje innych firm, takie jak programy do rysowania, GUI, mapy kolorów, animacje i wiele innych, które zostały zaprojektowane do integracji z Matplotlib.
Jego funkcjonalność można rozszerzyć o wiele narzędzi, takich jak Basemap, Cartopy, GTK-Tools, Natgrid, Seaborn i inne.
Jego najlepsze cechy to rysowanie wykresów i map z ustrukturyzowanymi i nieustrukturyzowanymi danymi.
Bigml
Bigml to zbiorowa i przejrzysta platforma dla inżynierów, naukowców zajmujących się danymi, programistów i analityków. Wykonuje transformację danych od końca do końca w modele umożliwiające działanie.
Skutecznie tworzy, eksperymentuje, automatyzuje i zarządza przepływami pracy ml, przyczyniając się do inteligentnych aplikacji w wielu branżach.
Ta programowalna platforma ML (uczenia maszynowego) pomaga w sekwencjonowaniu, przewidywaniu szeregów czasowych, wykrywaniu asocjacji, regresji, analizie skupień i nie tylko.
Jego w pełni zarządzalna wersja z jednym i wieloma dzierżawcami oraz jednym możliwym wdrożeniem dla dowolnego dostawcy chmury ułatwia przedsiębiorstwom zapewnienie wszystkim dostępu do dużych zbiorów danych.
Jego cena zaczyna się od 30 USD i jest bezpłatna dla małych zbiorów danych i celów edukacyjnych i jest używana na ponad 600 uniwersytetach.
Dzięki solidnym, opracowanym algorytmom ML jest odpowiedni w różnych branżach, takich jak farmaceutyczna, rozrywkowa, motoryzacyjna, lotnicza, zdrowotna, IoT i wielu innych.
Cechy
- Zautomatyzuj czasochłonne i złożone przepływy pracy w jednym wywołaniu interfejsu API.
- Może przetwarzać duże ilości danych i wykonywać równoległe zadania
- Biblioteka jest obsługiwana przez popularne języki programowania takie jak Python, Node.js, Ruby, Java, Swift itp.
- Jego szczegółowe szczegóły ułatwiają pracę w zakresie audytu i wymagań regulacyjnych
Apache Spark
Jest to jeden z największych silników typu open source szeroko wykorzystywanych przez duże firmy. Według strony internetowej Spark jest używany przez 80% firm z listy Fortune 500. Jest kompatybilny z pojedynczymi węzłami i klastrami dla Big Data i ML.
Opiera się na zaawansowanym języku SQL (Structured Query Language) do obsługi dużych ilości danych i pracy z tabelami strukturalnymi i danymi niestrukturalnymi.
Platforma Spark jest znana z łatwości obsługi, dużej społeczności i błyskawicznej szybkości. Deweloperzy używają platformy Spark do tworzenia aplikacji i uruchamiania zapytań w językach Java, Scala, Python, R i SQL.
Cechy
- Przetwarza dane zarówno wsadowo, jak i w czasie rzeczywistym
- Obsługuje duże ilości petabajtów danych bez próbkowania w dół
- Ułatwia łączenie wielu bibliotek, takich jak SQL, MLib, Graphx i Stream, w jeden przepływ pracy.
- Działa na Hadoop YARN, Apache Mesos, Kubernetes, a nawet w chmurze i ma dostęp do wielu źródeł danych
Knime
Konstanz Information Miner to intuicyjna platforma typu open source dla aplikacji do analizy danych. Naukowiec i analityk danych może tworzyć wizualne przepływy pracy bez kodowania, korzystając z prostej funkcji przeciągania i upuszczania.
Wersja serwerowa to platforma handlowa używana do automatyzacji, zarządzania nauką o danych i analizy zarządzania. KNIME sprawia, że przepływy pracy związane z nauką danych i komponenty wielokrotnego użytku są dostępne dla wszystkich.
Cechy
- Wysoce elastyczny w integracji danych z Oracle, SQL, Hive i nie tylko
- Uzyskaj dostęp do danych z wielu źródeł, takich jak SharePoint, Amazon Cloud, Salesforce, Twitter i nie tylko
- Użycie ml ma postać budowania modelu, dostrajania wydajności i walidacji modelu.
- Spostrzeżenia danych w postaci wizualizacji, statystyk, przetwarzania i raportowania
Jakie jest znaczenie 5 V big data?
Pięć V Big Data pomaga analitykom danych zrozumieć i przeanalizować duże zbiory danych, aby uzyskać więcej informacji. Pomaga również dostarczać więcej statystyk przydatnych dla firm do podejmowania świadomych decyzji i zdobywania przewagi konkurencyjnej.
Objętość: Big data opiera się na objętości. Objętość kwantowa określa, jak duże są dane. Zwykle zawiera dużą ilość danych w terabajtach, petabajtach itp. Na podstawie rozmiaru woluminu analitycy danych planują różne narzędzia i integracje do analizy zbioru danych.
Szybkość: Szybkość zbierania danych ma kluczowe znaczenie, ponieważ niektóre firmy wymagają informacji o danych w czasie rzeczywistym, a inne wolą przetwarzać dane w pakietach. Im szybszy przepływ danych, tym więcej analityków danych może ocenić i dostarczyć firmie odpowiednich informacji.
Różnorodność: Dane pochodzą z różnych źródeł i, co ważne, nie mają ustalonego formatu. Dane są dostępne w formatach ustrukturyzowanych (format bazy danych), częściowo ustrukturyzowanych (XML/RDF) i nieustrukturyzowanych (dane binarne). W oparciu o struktury danych narzędzia Big Data służą do tworzenia, organizowania, filtrowania i przetwarzania danych.
Wiarygodność: Dokładność danych i wiarygodne źródła definiują kontekst big data. Zbiór danych pochodzi z różnych źródeł, takich jak komputery, urządzenia sieciowe, urządzenia mobilne, media społecznościowe itp. W związku z tym dane muszą zostać przeanalizowane, aby mogły zostać wysłane do miejsca przeznaczenia.
Wartość: Ile są warte big data firmy? Rolą analityka danych jest jak najlepsze wykorzystanie danych w celu wykazania, w jaki sposób wgląd w dane może zwiększyć wartość firmy.
Wniosek
Powyższa lista Big Data zawiera płatne narzędzia i narzędzia open source. Dla każdego narzędzia dostępne są krótkie informacje i funkcje. Jeśli szukasz informacji opisowych, możesz odwiedzić odpowiednie strony internetowe.
Firmy chcące zdobyć przewagę konkurencyjną wykorzystują big data i powiązane narzędzia, takie jak sztuczna inteligencja (sztuczna inteligencja), ML (uczenie maszynowe) i inne technologie, aby podejmować taktyczne działania w celu poprawy obsługi klienta, badań, marketingu, planowania przyszłości itp.
Narzędzia Big Data są wykorzystywane w większości branż, ponieważ niewielkie zmiany w produktywności mogą przełożyć się na znaczne oszczędności i duże zyski. Mamy nadzieję, że powyższy artykuł zawiera przegląd narzędzi Big Data i ich znaczenia.
Może Ci się spodobać:
Kursy online umożliwiające poznanie podstaw inżynierii danych.