
Bir Veri Bilimcisi Olarak Bilinmesi Gereken 13 Büyük Veri Aracı
Yayınlanan: 2021-11-30Bilgi çağında, veri merkezleri büyük miktarda veri toplar. Toplanan veriler finansal işlemler, müşteri etkileşimleri, sosyal medya ve daha birçok kaynak gibi çeşitli kaynaklardan gelir ve daha da önemlisi daha hızlı birikir.
Veriler çeşitli ve hassas olabilir ve iş istatistiklerini, bilgileri modernize etme ve yaşamları değiştirme konusunda sınırsız bir potansiyele sahip olduğundan onu anlamlı kılmak için doğru araçları gerektirir.

Bu tür senaryolarda Büyük Veri araçları ve Veri bilimcileri öne çıkıyor.
Bu kadar büyük miktarda çeşitli veri, Excel gibi geleneksel araçları ve teknikleri kullanarak işlemeyi zorlaştırıyor. Excel gerçekten bir veritabanı değildir ve veri depolamak için bir limite (65,536 satır) sahiptir.
Excel'deki veri analizi, zayıf veri bütünlüğünü gösterir. Uzun vadede, Excel'de depolanan verilerin güvenliği ve uyumluluğu sınırlıdır, olağanüstü durum kurtarma oranları çok düşüktür ve uygun sürüm denetimi yoktur.
Bu kadar büyük ve çeşitli veri kümelerini işlemek için, değerli bilgileri incelemek, işlemek ve çıkarmak için veri araçları adı verilen benzersiz bir araç kümesine ihtiyaç vardır. Bu araçlar, daha anlamlı içgörüler ve veri kalıpları bulmak için verilerinizi derinlemesine incelemenize olanak tanır.
Bu kadar karmaşık teknoloji araçları ve verileriyle uğraşmak doğal olarak benzersiz bir beceri seti gerektirir ve bu nedenle veri bilimcisi büyük verilerde hayati bir rol oynar.
Büyük veri araçlarının önemi
Veriler, herhangi bir organizasyonun yapı taşıdır ve değerli bilgileri çıkarmak, ayrıntılı analizler yapmak, fırsatlar yaratmak ve yeni iş kilometre taşları ve vizyonları planlamak için kullanılır.
Her gün verimli ve güvenli bir şekilde saklanması ve gerektiğinde geri çağrılması gereken daha fazla veri oluşturuluyor. Bu verilerin boyutu, çeşitliliği ve hızlı değişimi, yeni büyük veri araçları, farklı depolama ve analiz yöntemleri gerektiriyor.
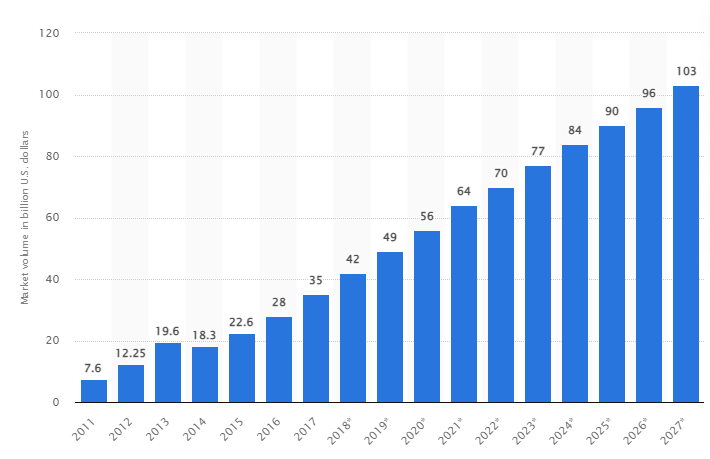
Bir araştırmaya göre, küresel büyük veri pazarının 2027 yılına kadar 103 milyar ABD dolarına, 2018'de beklenen pazar boyutunun iki katından fazla büyümesi bekleniyor.
Günümüzün endüstri zorlukları
“Büyük veri” terimi, son zamanlarda, geleneksel veritabanı yönetim sistemleri (DBMS) ile kullanılması zor olacak kadar büyümüş veri kümelerini ifade etmek için kullanılmıştır.
Veri boyutları sürekli artmaktadır ve günümüzde tek bir veri setinde onlarca terabayttan (TB) birçok petabayta (PB) kadar değişmektedir. Bu veri kümelerinin boyutu, ortak yazılımın zaman içinde işleme, yönetme, arama, paylaşma ve görselleştirme yeteneğini aşıyor.
Büyük verinin oluşumu aşağıdakilere yol açacaktır:
- Kalite yönetimi ve iyileştirme
- Tedarik zinciri ve verimlilik yönetimi
- Müşteri zekası
- Veri analizi ve karar verme
- Risk yönetimi ve dolandırıcılık tespiti
Bu bölümde, en iyi büyük veri araçlarına ve şirketler işlerini geliştirmek ve büyütmek için daha derin bir analiz istediğinde veri bilimcilerin bu teknolojileri filtrelemek, analiz etmek, depolamak ve ayıklamak için nasıl kullandıklarına bakıyoruz.
Apache Hadoop'u
Apache Hadoop, büyük miktarda veriyi depolayan ve işleyen açık kaynaklı bir Java platformudur.
Hadoop, büyük veri kümelerini (terabayttan petabayta kadar) eşleyerek, kümeler arasındaki görevleri analiz ederek ve bunları daha küçük parçalara (64MB ila 128MB) bölerek çalışır ve bu da daha hızlı veri işleme sağlar.
Verileri depolamak ve işlemek için veriler Hadoop kümesine gönderilir, HDFS (Hadoop dağıtılmış dosya sistemi) verileri depolar, MapReduce verileri işler ve YARN (Yine başka bir kaynak müzakerecisi) görevleri böler ve kaynakları atar.
Araştırma ve üretim için çeşitli şirket ve kuruluşlardan veri bilimcileri, geliştiricileri ve analistler için uygundur.
Özellikler
- Veri çoğaltma: Bloğun birden çok kopyası farklı düğümlerde depolanır ve bir hata durumunda hata toleransı görevi görür.
- Yüksek Ölçeklenebilirlik: Dikey ve yatay ölçeklenebilirlik sunar
- Diğer Apache modelleri, Cloudera ve Hortonworks ile entegrasyon
Apache Spark ile Büyük Veri öğrenmek için bu harika çevrimiçi kursu almayı düşünün.
Rapidminer
Rapidminer web sitesi, dünya çapında yaklaşık 40.000 kuruluşun yazılımlarını satışları artırmak, maliyetleri azaltmak ve riskten kaçınmak için kullandığını iddia ediyor.
Yazılım birkaç ödül aldı: Veri bilimi ve makine öğrenimi platformları için Gartner Vision Awards 2021, çok modlu tahmine dayalı analitik ve Forrester ve Crowd'un 2021 bahar G2 raporundaki en kullanıcı dostu makine öğrenimi ve veri bilimi platformundan makine öğrenimi çözümleri.
Bilimsel yaşam döngüsü için uçtan uca bir platformdur ve ML (makine öğrenimi) modelleri oluşturmak için sorunsuz bir şekilde entegre edilmiş ve optimize edilmiştir. Tam şeffaflık için her hazırlık, modelleme ve doğrulama adımını otomatik olarak belgeler.
Üç versiyonu bulunan ücretli bir yazılımdır: Verileri Hazırla, Oluştur ve Doğrula ve Modeli Dağıt. Hatta eğitim kurumlarına ücretsiz olarak sunulmaktadır ve RapidMiner dünya çapında 4.000'den fazla üniversite tarafından kullanılmaktadır.
Özellikler
- Kalıpları belirlemek ve kalite sorunlarını gidermek için verileri kontrol eder
- 1500'den fazla algoritmaya sahip kodsuz bir iş akışı tasarımcısı kullanır
- Makine öğrenimi modellerini mevcut iş uygulamalarına entegre etme
tablo
Tableau, platformları görsel olarak analiz etme, sorunları çözme ve insanları ve kuruluşları güçlendirme esnekliği sağlar. Sürükle ve bırak işlemlerini sezgisel bir kullanıcı arayüzü aracılığıyla veri sorgularına dönüştüren VizQL teknolojisine (veritabanı sorguları için görsel dil) dayanmaktadır.
Tableau, 2019 yılında Salesforce tarafından satın alındı. SQL veritabanları, elektronik tablolar veya Google Analytics ve Salesforce gibi bulut uygulamaları gibi kaynaklardan gelen verilerin bağlanmasına olanak tanır.
Kullanıcılar, her birinin kendine has özellikleri ve işlevleri olduğundan, iş veya bireysel tercihlere göre Creator, Explorer ve Viewer sürümlerini satın alabilir.
Analistler, veri bilimcileri, eğitim sektörü ve iş kullanıcıları için veriye dayalı bir kültürü uygulamak ve dengelemek ve sonuçlar aracılığıyla değerlendirmek için idealdir.
Özellikler
- Gösterge tabloları, görsel öğeler, nesneler ve metin biçimindeki verilere eksiksiz bir genel bakış sağlar.
- Geniş veri grafiği seçenekleri: histogramlar, Gantt çizelgeleri, çizelgeler, hareket çizelgeleri ve daha fazlası
- Verileri güvenli ve istikrarlı tutmak için satır düzeyinde filtre koruması
- Mimarisi öngörülebilir analiz ve tahmin sunar
Öğrenme Tablosu kolaydır.
bulutlar
Cloudera, büyük veri yönetimi için bulut ve veri merkezleri için güvenli bir platform sunar. Karmaşık verileri net, eyleme geçirilebilir içgörülere dönüştürmek için veri analitiğini ve makine öğrenimini kullanır.
Cloudera, özel ve hibrit bulutlar, veri mühendisliği, veri akışı, veri depolama, veri bilimciler için veri bilimi ve daha fazlası için çözümler ve araçlar sunar.
Birleşik bir platform ve çok işlevli analitik, veriye dayalı içgörü keşif sürecini geliştirir. Veri bilimi, yalnızca Cloudera ve Hortonworks'e değil (her iki şirket de ortaktır) kuruluşun kullandığı herhangi bir sisteme bağlantı sağlar.
Veri bilimcileri, etkileşimli veri bilimi çalışma sayfaları aracılığıyla analiz, planlama, izleme ve e-posta bildirimleri gibi kendi etkinliklerini yönetir. Varsayılan olarak, veri bilimcilerinin Hadoop verilerine erişmesine ve Spark sorgularını kolayca çalıştırmasına olanak tanıyan, güvenlikle uyumlu bir platformdur.
Platform, hastaneler, finans kurumları, telekomünikasyon ve diğerleri gibi çeşitli sektörlerdeki veri mühendisleri, veri bilimcileri ve BT uzmanları için uygundur.
Özellikler
- Veri Bilimi tezgahı, şirket içi dağıtımları desteklerken, tüm büyük özel ve genel bulutları destekler
- Otomatik veri kanalları, verileri kullanılabilir formlara dönüştürür ve diğer kaynaklarla entegre eder.
- Tek tip iş akışı, hızlı model oluşturma, eğitim ve uygulamaya olanak tanır.
- Hadoop kimlik doğrulaması, yetkilendirme ve şifreleme için güvenli ortam
Apaçi Kovanı
Apache Hive, Apache Hadoop üzerine geliştirilmiş açık kaynaklı bir projedir. Çeşitli depolarda bulunan büyük veri kümelerinin okunmasına, yazılmasına ve yönetilmesine olanak tanır ve kullanıcıların özel analiz için kendi işlevlerini birleştirmelerine olanak tanır.
Hive, geleneksel depolama görevleri için tasarlanmıştır ve çevrimiçi işleme görevleri için tasarlanmamıştır. Sağlam toplu çerçeveleri ölçeklenebilirlik, performans, ölçeklenebilirlik ve hata toleransı sunar.
Veri çıkarma, tahmine dayalı modelleme ve belgeleri indeksleme için uygundur. Sonuç almada gecikmeye neden olduğu için gerçek zamanlı verileri sorgulamak için önerilmez.
Özellikler
- MapReduce, Tez ve Spark bilgi işlem motorunu destekler
- Birkaç petabayt boyutunda büyük veri kümelerini işleyin
- Java'ya kıyasla kodlaması çok kolay
- Verileri Apache Hadoop dağıtılmış dosya sisteminde depolayarak hata toleransı sağlar
Apaçi Fırtınası
Storm, sınırsız veri akışını işlemek için kullanılan ücretsiz, açık kaynaklı bir platformdur. Çok büyük miktarda veriyi gerçek zamanlı olarak işleyebilen uygulamalar geliştirmek için kullanılan en küçük işlem birimleri kümesini sağlar.
Bir fırtına, düğüm başına saniyede bir milyon demeti işleyecek kadar hızlıdır ve kullanımı kolaydır.
Apache Storm, kümenize daha fazla düğüm eklemenize ve uygulama işleme gücünü artırmanıza olanak tanır. Yatay ölçeklenebilirlik korunduğu için düğümler eklenerek işleme kapasitesi iki katına çıkarılabilir.
Veri bilimcileri, DRPC (Dağıtılmış Uzaktan Yordam Çağrıları), gerçek zamanlı ETL (Alma-Dönüşüm-Yükleme) analizi, sürekli hesaplama, çevrimiçi makine öğrenimi vb. için Storm'u kullanabilir. Twitter'ın gerçek zamanlı işleme ihtiyaçlarını karşılamak üzere ayarlanmıştır. , Yahoo ve Flipboard.
Özellikler
- Herhangi bir programlama dili ile kullanımı kolay
- Her kuyruk sistemine ve her veri tabanına entegre edilmiştir.
- Storm, kümeleri yönetmek için Zookeeper'ı kullanıyor ve daha büyük küme boyutlarına ölçekleniyor
- Garantili veri koruması, bir şeyler ters giderse kaybolan demetlerin yerini alır
Kar Tanesi Veri Bilimi
Verileri almak, birleştirmek, temizlemek ve hazırlamak için maksimum zaman harcandığından, veri bilimcileri için en büyük zorluk farklı kaynaklardan veri hazırlamaktır. Snowflake tarafından ele alınmaktadır.

ETL'nin (Yük Dönüşümü ve Çıkarma) neden olduğu güçlük ve gecikmeyi ortadan kaldıran tek bir yüksek performanslı platform sunar. Ayrıca Dask ve Saturn Cloud gibi en yeni makine öğrenimi (ML) araçları ve kitaplıklarıyla da entegre edilebilir.
Snowflake, bu tür üst düzey bilgi işlem etkinliklerini gerçekleştirmek için her iş yükü için benzersiz bir özel işlem kümeleri mimarisi sunar, bu nedenle veri bilimi ve BI (iş zekası) iş yükleri arasında kaynak paylaşımı yoktur.
Yapılandırılmış, yarı yapılandırılmış (JSON, Avro, ORC, Parquet veya XML) ve yapılandırılmamış verilerden veri türlerini destekler. Veri erişimini, performansı ve güvenliği iyileştirmek için bir veri gölü stratejisi kullanır.
Veri bilimcileri ve analistleri, finans, medya ve eğlence, perakende, sağlık ve yaşam bilimleri, teknoloji ve kamu sektörü dahil olmak üzere çeşitli sektörlerde kar taneleri kullanır.
Özellikler
- Depolama maliyetlerini azaltmak için yüksek veri sıkıştırma
- Beklemede ve aktarım sırasında veri şifreleme sağlar
- Düşük operasyonel karmaşıklığa sahip hızlı işleme motoru
- Tablo, grafik ve histogram görünümleriyle entegre veri profili oluşturma
veri robotu
Datarobot, AI (Yapay Zeka) ile bulutta bir dünya lideridir. Benzersiz platformu, kullanıcılar ve farklı veri türleri dahil olmak üzere tüm sektörlere hizmet verecek şekilde tasarlanmıştır.
Şirket, yazılımın Fortune 50 şirketlerinin üçte biri tarafından kullanıldığını ve çeşitli endüstrilerde bir trilyondan fazla tahmin sağladığını iddia ediyor.
Dataroabot, otomatikleştirilmiş makine öğrenimi (ML) kullanır ve kurumsal veri uzmanlarının doğru tahmin modellerini hızla oluşturması, uyarlaması ve devreye alması için tasarlanmıştır.
Bilim adamlarına, veri ön işlemeyi otomatikleştirmek için tam şeffaflık ile en yeni makine öğrenimi algoritmalarının çoğuna kolay erişim sağlar. Yazılım, bilim adamlarının karmaşık veri bilimi sorunlarını çözmeleri için özel R ve Python istemcileri geliştirdi.
Veri bilimcisi faaliyetlerini kolaylaştırmak için veri kalitesini, özellik mühendisliğini ve uygulama süreçlerini otomatikleştirmeye yardımcı olur. Birinci sınıf bir üründür ve fiyat talep üzerine mevcuttur.
Özellikler
- Karlılık açısından iş değerini artırır, basitleştirilmiş tahmin
- Uygulama süreçleri ve otomasyon
- Python, Spark, TensorFlow ve diğer kaynaklardan gelen algoritmaları destekler.
- API entegrasyonu, yüzlerce model arasından seçim yapmanızı sağlar
TensorFlow
TensorFlow, makine öğrenimi (ML) uygulamaları oluşturmak, eğitmek ve dağıtmak için veri akış diyagramlarını kullanan bir topluluk AI (yapay zeka) tabanlı kitaplıktır. Bu, geliştiricilerin büyük katmanlı sinir ağları oluşturmasına olanak tanır.
Üç model içerir – TensorFlow.js, TensorFlow Lite ve TensorFlow Extended (TFX). Javascript modu, modelleri aynı anda hem tarayıcıda hem de Node.js'de eğitmek ve dağıtmak için kullanılır. Basit modu, modelleri mobil ve gömülü cihazlarda dağıtmak içindir ve TFX modeli, verileri hazırlamak, modelleri doğrulamak ve dağıtmak içindir.
Güçlü platformu sayesinde, programlama dilinden bağımsız olarak sunuculara, uç cihazlara veya web'e dağıtılabilir.
TFX, yükseltilebilir ve sağlam genel performans görevleri sağlayan ML işlem hatlarını zorlamak için mekanizmalar içerir. Kubeflow ve Apache Airflow gibi Veri mühendisliği işlem hatları TFX'i destekler.
Tensorflow platformu Yeni Başlayanlar için uygundur. Keras kullanarak el yazısı rakamların görüntülerini oluşturmak için üretken bir düşman ağı eğitmek için orta ve uzmanlar için.
Özellikler
- ML modellerini şirket içinde, bulutta ve tarayıcıda ve dilden bağımsız olarak dağıtabilir
- Hızlı model tekrarı için doğuştan gelen API'leri kullanarak kolay model oluşturma
- Çeşitli eklenti kitaplıkları ve modelleri, deney yapmak için araştırma faaliyetlerini destekler
- Birden fazla soyutlama seviyesi kullanarak kolay model oluşturma
matplotlib
Matplotlib, Python programlama dili için animasyonlu verileri ve grafik grafikleri görselleştirmek için kapsamlı bir topluluk yazılımıdır. Benzersiz tasarımı, birkaç satır kod kullanılarak görsel bir veri grafiği oluşturulacak şekilde yapılandırılmıştır.
Matplotlib ile entegre edilmek üzere tasarlanmış çizim programları, GUI'ler, renkli haritalar, animasyonlar ve daha pek çok çeşitli üçüncü taraf uygulamaları vardır.
Basemap, Cartopy, GTK-Tools, Natgrid, Seaborn ve diğerleri gibi birçok araçla işlevselliği genişletilebilir.
En iyi özellikleri, yapılandırılmış ve yapılandırılmamış verilerle grafikler ve haritalar çizmeyi içerir.
Bigml
Bigml, Mühendisler, veri bilimciler, geliştiriciler ve analistler için toplu ve şeffaf bir platformdur. İşlem yapılabilir modellere uçtan uca veri dönüşümü gerçekleştirir.
Çok çeşitli endüstrilerde akıllı uygulamalara katkıda bulunarak ml iş akışlarını etkin bir şekilde oluşturur, deneyler, otomatikleştirir ve yönetir.
Bu programlanabilir ML (makine öğrenimi) platformu, sıralama, zaman serisi tahmini, ilişki tespiti, regresyon, küme analizi ve daha pek çok konuda yardımcı olur.
Tekli ve çoklu kiracılı tamamen yönetilebilir sürümü ve herhangi bir bulut sağlayıcısı için olası bir dağıtım, işletmelerin herkesin büyük verilere erişmesini kolaylaştırır.
Fiyatı 30 dolardan başlar ve küçük veri kümeleri ve eğitim amaçlı ücretsizdir ve 600'den fazla üniversitede kullanılmaktadır.
Sağlam mühendislik ürünü makine öğrenimi algoritmaları sayesinde ilaç, eğlence, otomotiv, havacılık, sağlık, IoT ve daha pek çok sektör için uygundur.
Özellikler
- Tek bir API çağrısında zaman alan ve karmaşık iş akışlarını otomatikleştirin.
- Büyük miktarda veriyi işleyebilir ve paralel görevler gerçekleştirebilir.
- Kütüphane Python, Node.js, Ruby, Java, Swift gibi popüler programlama dilleri tarafından desteklenmektedir.
- Ayrıntılı ayrıntıları, denetim ve düzenleyici gereksinimlerin işini kolaylaştırır
Apaçi Kıvılcımı
Büyük şirketler tarafından yaygın olarak kullanılan en büyük açık kaynaklı motorlardan biridir. Web sitesine göre Spark, Fortune 500 şirketlerinin %80'i tarafından kullanılıyor. Büyük veri ve makine öğrenimi için tek düğümler ve kümelerle uyumludur.
Büyük miktarda veriyi desteklemek ve yapılandırılmış tablolar ve yapılandırılmamış verilerle çalışmak için gelişmiş SQL'e (Yapılandırılmış Sorgu Dili) dayanmaktadır.
Spark platformu, kullanım kolaylığı, geniş topluluğu ve yıldırım hızıyla bilinir. Geliştiriciler, Java, Scala, Python, R ve SQL'de uygulamalar oluşturmak ve sorguları çalıştırmak için Spark'ı kullanır.
Özellikler
- Verileri hem toplu hem de gerçek zamanlı olarak işler
- Altörnekleme olmadan büyük miktarda petabayt veriyi destekler
- SQL, MLib, Graphx ve Stream gibi birden çok kitaplığı tek bir iş akışında birleştirmeyi kolaylaştırır.
- Hadoop YARN, Apache Mesos, Kubernetes ve hatta bulutta çalışır ve birden çok veri kaynağına erişimi vardır
bıçak
Konstanz Information Miner, veri bilimi uygulamaları için sezgisel bir açık kaynaklı platformdur. Bir veri bilimcisi ve analisti, basit sürükle ve bırak işleviyle kodlama yapmadan görsel iş akışları oluşturabilir.
Sunucu sürümü, otomasyon, veri bilimi yönetimi ve yönetim analizi için kullanılan bir ticaret platformudur. KNIME, veri bilimi iş akışlarını ve yeniden kullanılabilir bileşenleri herkes için erişilebilir hale getirir.
Özellikler
- Oracle, SQL, Hive ve daha fazlasından veri entegrasyonu için son derece esnek
- SharePoint, Amazon Cloud, Salesforce, Twitter ve daha fazlası gibi birden çok kaynaktan verilere erişin
- ml kullanımı model oluşturma, performans ayarlama ve model doğrulama şeklindedir.
- Görselleştirme, istatistik, işleme ve raporlama şeklinde veri içgörüleri
Büyük verinin 5 V'sinin önemi nedir?
Büyük verilerin 5 V'si, veri bilimcilerin daha fazla içgörü elde etmek için büyük verileri anlamasına ve analiz etmesine yardımcı olur. Ayrıca, işletmelerin bilinçli kararlar vermeleri ve rekabet avantajı elde etmeleri için yararlı olan daha fazla istatistik sağlamaya yardımcı olur.
Hacim: Büyük veri, hacme dayalıdır. Kuantum hacmi, verilerin ne kadar büyük olduğunu belirler. Genellikle terabayt, petabayt vb. cinsinden büyük miktarda veri içerir. Hacim boyutuna bağlı olarak veri bilimcileri, veri seti analizi için çeşitli araçlar ve entegrasyonlar planlar.
Hız: Veri toplama hızı çok önemlidir çünkü bazı şirketler gerçek zamanlı veri bilgilerine ihtiyaç duyar ve diğerleri verileri paketler halinde işlemeyi tercih eder. Veri akışı ne kadar hızlı olursa, veri bilimcileri o kadar çok değerlendirebilir ve şirkete ilgili bilgileri sağlayabilir.
Çeşitlilik: Veriler farklı kaynaklardan gelir ve daha da önemlisi sabit bir biçimde değil. Veriler yapılandırılmış (veritabanı formatı), yarı yapılandırılmış (XML/RDF) ve yapılandırılmamış (ikili veri) formatlarında mevcuttur. Veri yapılarına dayalı olarak, verileri oluşturmak, düzenlemek, filtrelemek ve işlemek için büyük veri araçları kullanılır.
Doğruluk : Veri doğruluğu ve güvenilir kaynaklar, büyük veri bağlamını tanımlar. Veri seti bilgisayarlar, ağ cihazları, mobil cihazlar, sosyal medya vb. çeşitli kaynaklardan gelmektedir. Buna göre verinin hedefine gönderilebilmesi için analiz edilmesi gerekmektedir.
Değer: Son olarak, bir şirketin büyük verilerinin değeri nedir? Veri bilimcisinin rolü, veri içgörülerinin bir işletmeye nasıl değer katabileceğini göstermek için verileri en iyi şekilde kullanmaktır.
Çözüm
Yukarıdaki büyük veri listesi, ücretli araçları ve açık kaynak araçlarını içerir. Her araç için kısa bilgiler ve işlevler sağlanmıştır. Açıklayıcı bilgi arıyorsanız, ilgili web sitelerini ziyaret edebilirsiniz.
Rekabet avantajı elde etmek isteyen şirketler, müşteri hizmetlerini, araştırmayı, pazarlamayı, gelecek planlamasını vb. iyileştirmek için taktiksel eylemlerde bulunmak için AI (yapay zeka), ML (makine öğrenimi) ve diğer teknolojiler gibi büyük verileri ve ilgili araçları kullanır.
Verimlilikteki küçük değişiklikler önemli tasarruflara ve büyük kârlara dönüşebileceğinden, büyük veri araçları çoğu sektörde kullanılmaktadır. Yukarıdaki makalenin size büyük veri araçlarına ve bunların önemine ilişkin bir genel bakış sağladığını umuyoruz.
Şunlar da hoşunuza gidebilir:
Veri Mühendisliğinin temellerini öğrenmek için çevrimiçi kurslar.