
データサイエンティストとして知っておくべき13のビッグデータツール
公開: 2021-11-30情報化時代では、データセンターは大量のデータを収集します。 収集されたデータは、金融取引、顧客とのやり取り、ソーシャルメディア、その他の多くのソースから取得され、さらに重要なことに、より速く蓄積されます。
データは多様で機密性が高く、ビジネス統計、情報を最新化し、生活を変える可能性が無限にあるため、データを意味のあるものにするための適切なツールが必要です。

このようなシナリオでは、ビッグデータツールとデータサイエンティストが目立ちます。
このように大量の多様なデータがあるため、Excelなどの従来のツールや手法を使用して処理することは困難です。 Excelは実際にはデータベースではなく、データの保存には制限(65,536行)があります。
Excelでのデータ分析では、データの整合性が低いことが示されています。 長期的には、Excelに保存されたデータのセキュリティとコンプライアンスは制限され、災害復旧率は非常に低く、適切なバージョン管理は行われません。
このように大規模で多様なデータセットを処理するには、データツールと呼ばれる独自のツールセットを使用して、貴重な情報を調べ、処理し、抽出する必要があります。 これらのツールを使用すると、データを深く掘り下げて、より意味のある洞察とデータパターンを見つけることができます。
このような複雑なテクノロジーツールやデータを扱うには、当然、独自のスキルセットが必要です。そのため、データサイエンティストはビッグデータで重要な役割を果たします。
ビッグデータツールの重要性
データはあらゆる組織の構成要素であり、貴重な情報を抽出し、詳細な分析を実行し、機会を創出し、新しいビジネスのマイルストーンとビジョンを計画するために使用されます。
毎日ますます多くのデータが作成され、効率的かつ安全に保存し、必要に応じて呼び出す必要があります。 そのデータのサイズ、多様性、および急速な変化には、新しいビッグデータツール、さまざまなストレージ、および分析方法が必要です。
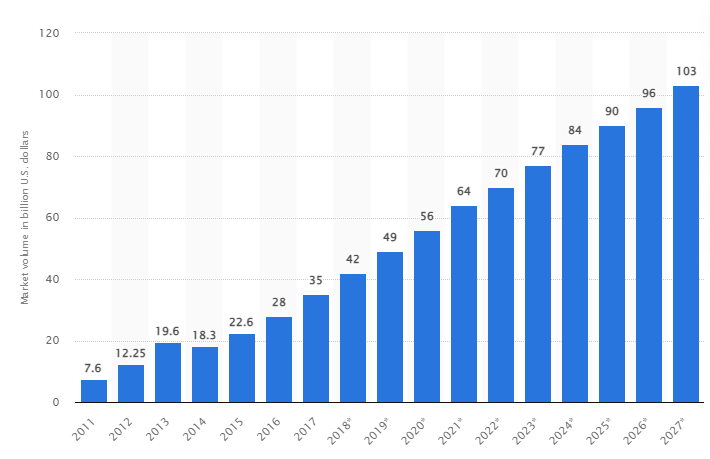
ある調査によると、世界のビッグデータ市場は2027年までに1,030億米ドルに成長すると予想されており、これは2018年に予想される市場規模の2倍以上に相当します。
今日の業界の課題
「ビッグデータ」という用語は、最近、従来のデータベース管理システム(DBMS)では使用が困難になるほど大きくなったデータセットを指すために使用されています。
データサイズは絶えず増加しており、今日では1つのデータセットで数十テラバイト(TB)から数ペタバイト(PB)の範囲になっています。 これらのデータセットのサイズは、時間の経過とともに処理、管理、検索、共有、および視覚化する一般的なソフトウェアの能力を超えています。
ビッグデータの形成は、次のことにつながります。
- 品質管理と改善
- サプライチェーンと効率管理
- カスタマーインテリジェンス
- データ分析と意思決定
- リスク管理と不正検出
このセクションでは、最高のビッグデータツールと、データサイエンティストがこれらのテクノロジーを使用して、企業がビジネスを改善および成長させるためのより詳細な分析を必要とする場合に、それらをフィルタリング、分析、保存、および抽出する方法について説明します。
Apache Hadoop
Apache Hadoopは、大量のデータを格納および処理するオープンソースのJavaプラットフォームです。
Hadoopは、大きなデータセット(テラバイトからペタバイトまで)をマッピングし、クラスター間のタスクを分析し、それらを小さなチャンク(64MBから128MB)に分割することで機能し、データ処理を高速化します。
データを保存および処理するために、データはHadoopクラスターに送信され、HDFS(Hadoop分散ファイルシステム)はデータを保存し、MapReduceはデータを処理し、YARN(さらに別のリソースネゴシエーター)はタスクを分割してリソースを割り当てます。
さまざまな企業や組織のデータサイエンティスト、開発者、アナリストが研究や制作を行うのに適しています。
特徴
- データ複製:ブロックの複数のコピーが異なるノードに保存され、エラーが発生した場合のフォールトトレランスとして機能します。
- 高度にスケーラブル:垂直および水平のスケーラビリティを提供します
- 他のApacheモデル、ClouderaおよびHortonworksとの統合
この素晴らしいオンラインコースを受講して、ApacheSparkでビッグデータを学ぶことを検討してください。
Rapidminer
RapidminerのWebサイトによると、世界中の約40,000の組織がソフトウェアを使用して、売り上げを伸ばし、コストを削減し、リスクを回避しています。
このソフトウェアは、いくつかの賞を受賞しています。データサイエンスおよび機械学習プラットフォームに対するGartner Vision Awards 2021、マルチモーダル予測分析、ForresterおよびCrowdの最もユーザーフレンドリーな機械学習およびデータサイエンスプラットフォームからの機械学習ソリューションが、春のG2レポート2021に掲載されました。
これは、科学ライフサイクルのエンドツーエンドプラットフォームであり、ML(機械学習)モデルを構築するためにシームレスに統合および最適化されています。 完全な透明性のために、準備、モデリング、検証のすべてのステップを自動的に文書化します。
これは、データの準備、モデルの作成と検証、モデルの展開の3つのバージョンで利用できる有料ソフトウェアです。 教育機関でも無料で利用でき、RapidMinerは世界中の4,000を超える大学で使用されています。
特徴
- データをチェックしてパターンを特定し、品質の問題を修正します
- 1500以上のアルゴリズムを備えたコードレスワークフローデザイナーを使用しています
- 機械学習モデルを既存のビジネスアプリケーションに統合する
Tableau
Tableauは、プラットフォームを視覚的に分析し、問題を解決し、人々や組織に力を与える柔軟性を提供します。 これは、直感的なユーザーインターフェイスを介してドラッグアンドドロップをデータクエリに変換するVizQLテクノロジ(データベースクエリの視覚言語)に基づいています。
Tableauは2019年にSalesforceに買収されました。これにより、SQLデータベース、スプレッドシート、またはGoogleAnalyticsやSalesforceなどのクラウドアプリケーションなどのソースからのデータをリンクできます。
ユーザーは、それぞれ独自の特性と機能を持っているため、ビジネスまたは個人の好みに基づいて、そのバージョンのCreator、Explorer、およびViewerを購入できます。
アナリスト、データサイエンティスト、教育セクター、およびビジネスユーザーにとって、データ主導の文化を実装してバランスを取り、結果を通じて評価することが理想的です。
特徴
- ダッシュボードは、視覚要素、オブジェクト、およびテキストの形式でデータの完全な概要を提供します。
- データチャートの豊富な選択肢:ヒストグラム、ガントチャート、チャート、モーションチャート、その他多数
- データを安全かつ安定に保つための行レベルのフィルター保護
- そのアーキテクチャは、予測可能な分析と予測を提供します
Tableauの学習は簡単です。
Cloudera
Clouderaは、ビッグデータ管理のためのクラウドおよびデータセンター向けの安全なプラットフォームを提供します。 データ分析と機械学習を使用して、複雑なデータを明確で実用的な洞察に変えます。
Clouderaは、プライベートクラウドとハイブリッドクラウド、データエンジニアリング、データフロー、データストレージ、データサイエンティスト向けのデータサイエンスなどのソリューションとツールを提供します。
統合されたプラットフォームと多機能分析により、データ主導の洞察発見プロセスが強化されます。 そのデータサイエンスは、ClouderaとHortonworks(両方の企業が提携している)だけでなく、組織が使用するすべてのシステムへの接続を提供します。
データサイエンティストは、インタラクティブなデータサイエンスワークシートを介して、分析、計画、監視、電子メール通知などの独自のアクティビティを管理します。 デフォルトでは、これはセキュリティに準拠したプラットフォームであり、データサイエンティストがHadoopデータにアクセスし、Sparkクエリを簡単に実行できるようにします。
このプラットフォームは、病院、金融機関、電気通信など、さまざまな業界のデータエンジニア、データサイエンティスト、ITプロフェッショナルに適しています。
特徴
- データサイエンスワークベンチがオンプレミス展開をサポートしている間、すべての主要なプライベートクラウドとパブリッククラウドをサポートします
- 自動データチャネルは、データを使用可能な形式に変換し、他のソースと統合します。
- 統一されたワークフローにより、モデルの構築、トレーニング、および実装を迅速に行うことができます。
- Hadoopの認証、承認、暗号化のための安全な環境
Apache Hive
Apache Hiveは、ApacheHadoop上で開発されたオープンソースプロジェクトです。 これにより、さまざまなリポジトリで利用可能な大規模なデータセットの読み取り、書き込み、および管理が可能になり、ユーザーは独自の機能を組み合わせてカスタム分析を行うことができます。
Hiveは、従来のストレージタスク用に設計されており、オンライン処理タスク用には設計されていません。 その堅牢なバッチフレームは、スケーラビリティ、パフォーマンス、スケーラビリティ、およびフォールトトレランスを提供します。
データ抽出、予測モデリング、およびドキュメントのインデックス作成に適しています。 結果の取得に遅延が発生するため、リアルタイムデータのクエリにはお勧めしません。
特徴
- MapReduce、Tez、およびSparkコンピューティングエンジンをサポートします
- サイズが数ペタバイトの巨大なデータセットを処理する
- Javaと比較して非常に簡単にコーディングできます
- Apache Hadoop分散ファイルシステムにデータを保存することにより、フォールトトレランスを提供します
Apache Storm
Stormは、無制限のデータストリームを処理するために使用される無料のオープンソースプラットフォームです。 非常に大量のデータをリアルタイムで処理できるアプリケーションの開発に使用される最小の処理ユニットのセットを提供します。
ストームは、ノードごとに1秒あたり100万タプルを処理するのに十分な速度であり、操作は簡単です。
Apache Stormを使用すると、クラスターにノードを追加して、アプリケーションの処理能力を向上させることができます。 水平方向のスケーラビリティが維持されるため、ノードを追加することで処理能力を2倍にすることができます。
データサイエンティストは、Storm for DRPC(Distributed Remote Procedure Calls)、リアルタイムETL(Retrieval-Conversion-Load)分析、連続計算、オンライン機械学習などを使用できます。これは、Twitterのリアルタイム処理のニーズを満たすように設定されています。 、Yahoo、およびFlipboard。
特徴
- あらゆるプログラミング言語で簡単に使用できます
- これは、すべてのキューイングシステムとすべてのデータベースに統合されています。
- StormはZookeeperを使用してクラスターを管理し、より大きなクラスターサイズに拡張します
- 何かがうまくいかない場合、保証されたデータ保護が失われたタプルを置き換えます
スノーフレークデータサイエンス
データサイエンティストにとっての最大の課題は、さまざまなリソースからデータを準備することです。これは、データの取得、統合、クリーニング、および準備に最大の時間が費やされるためです。 Snowflakeが対応しています。

ETL(Load Transformation and Extraction)によって引き起こされる煩わしさと遅延を排除する単一の高性能プラットフォームを提供します。 また、DaskやSaturn Cloudなどの最新の機械学習(ML)ツールやライブラリと統合することもできます。
Snowflakeは、このような高レベルのコンピューティングアクティビティを実行するために、ワークロードごとに専用のコンピューティングクラスターの独自のアーキテクチャを提供するため、データサイエンスとBI(ビジネスインテリジェンス)ワークロード間でリソースを共有することはありません。
構造化データ、半構造化データ(JSON、Avro、ORC、Parquet、またはXML)および非構造化データのデータ型をサポートします。 データレイク戦略を使用して、データアクセス、パフォーマンス、およびセキュリティを向上させます。
データサイエンティストとアナリストは、金融、メディアとエンターテインメント、小売、健康とライフサイエンス、テクノロジー、公共部門など、さまざまな業界で雪片を使用しています。
特徴
- ストレージコストを削減するための高データ圧縮
- 保管中および転送中のデータ暗号化を提供します
- 運用の複雑さが少ない高速処理エンジン
- 表、グラフ、およびヒストグラムビューを使用した統合データプロファイリング
Datarobot
Datarobotは、AI(Artificial Intelligence)を使用したクラウドの世界的リーダーです。 その独自のプラットフォームは、ユーザーやさまざまな種類のデータを含むすべての業界にサービスを提供するように設計されています。
同社は、このソフトウェアがFortune 50企業の3分の1で使用されており、さまざまな業界で1兆を超える見積もりを提供していると主張しています。
Dataroabotは自動機械学習(ML)を使用しており、エンタープライズデータの専門家が正確な予測モデルをすばやく作成、適応、展開できるように設計されています。
科学者は、データの前処理を自動化するための完全な透過性を備えた最新の機械学習アルゴリズムの多くに簡単にアクセスできます。 このソフトウェアは、科学者が複雑なデータサイエンスの問題を解決するための専用のRおよびPythonクライアントを開発しました。
データ品質、特徴エンジニアリング、および実装プロセスを自動化して、データサイエンティストの活動を容易にします。 プレミアム製品であり、価格はお問い合わせください。
特徴
- 収益性の観点からビジネス価値を高め、予測を簡素化
- 実装プロセスと自動化
- Python、Spark、TensorFlow、およびその他のソースからのアルゴリズムをサポートします。
- API統合により、数百のモデルから選択できます
TensorFlow
TensorFlowは、コミュニティAI(人工知能)ベースのライブラリであり、データフロー図を使用して機械学習(ML)アプリケーションを構築、トレーニング、デプロイします。 これにより、開発者は大規模な層状ニューラルネットワークを作成できます。
TensorFlow.js、TensorFlow Lite、TensorFlow Extended(TFX)の3つのモデルが含まれています。 そのjavascriptモードは、ブラウザーとNode.jsで同時にモデルのトレーニングとデプロイに使用されます。 そのライトモードは、モバイルおよび組み込みデバイスにモデルをデプロイするためのものであり、TFXモデルは、データを準備し、モデルを検証し、デプロイするためのものです。
その堅牢なプラットフォームにより、プログラミング言語に関係なく、サーバー、エッジデバイス、またはWebに展開できます。
TFXには、上昇可能で堅牢な全体的なパフォーマンスの義務を提供できるMLパイプラインを適用するメカニズムが含まれています。 KubeflowやApacheAirflowなどのデータエンジニアリングパイプラインはTFXをサポートしています。
Tensorflowプラットフォームは初心者に適しています。 中級者および専門家が、Kerasを使用して手書きの数字の画像を生成するための敵対的生成ネットワークをトレーニングします。
特徴
- MLモデルをオンプレミス、クラウド、ブラウザに、言語に関係なくデプロイできます
- 固有のAPIを使用した簡単なモデル構築により、モデルを迅速に繰り返すことができます
- そのさまざまなアドオンライブラリとモデルは、実験のための研究活動をサポートします
- 複数レベルの抽象化を使用した簡単なモデル構築
Matplotlib
Matplotlibは、Pythonプログラミング言語のアニメーションデータとグラフィックグラフィックスを視覚化するための包括的なコミュニティソフトウェアです。 その独自の設計は、数行のコードを使用して視覚的なデータグラフが生成されるように構成されています。
描画プログラム、GUI、カラーマップ、アニメーションなど、Matplotlibと統合するように設計されたさまざまなサードパーティアプリケーションがあります。
その機能は、Basemap、Cartopy、GTK-Tools、Natgrid、Seabornなどの多くのツールで拡張できます。
その最高の機能には、構造化データと非構造化データを使用したグラフとマップの描画が含まれます。
Bigml
Bigmlは、エンジニア、データサイエンティスト、開発者、およびアナリスト向けの集合的で透過的なプラットフォームです。 実用的なモデルへのエンドツーエンドのデータ変換を実行します。
mlワークフローを効果的に作成、実験、自動化、および管理し、幅広い業界にわたるインテリジェントなアプリケーションに貢献します。
このプログラム可能なML(機械学習)プラットフォームは、シーケンス、時系列予測、関連性の検出、回帰、クラスター分析などに役立ちます。
単一および複数のテナントを備えた完全に管理可能なバージョンと、クラウドプロバイダー向けの1つの可能な展開により、企業は誰もがビッグデータに簡単にアクセスできるようになります。
価格は30ドルからで、小さなデータセットや教育目的では無料で、600を超える大学で使用されています。
堅牢に設計されたMLアルゴリズムにより、製薬、エンターテインメント、自動車、航空宇宙、ヘルスケア、IoTなどのさまざまな業界に適しています。
特徴
- 1回のAPI呼び出しで、時間のかかる複雑なワークフローを自動化します。
- 大量のデータを処理し、並列タスクを実行できます
- このライブラリは、Python、Node.js、Ruby、Java、Swiftなどの一般的なプログラミング言語でサポートされています。
- その詳細な詳細により、監査および規制要件の作業が容易になります
Apache Spark
これは、大企業で広く使用されている最大のオープンソースエンジンの1つです。 ウェブサイトによると、Sparkはフォーチュン500企業の80%で使用されています。 ビッグデータとMLのシングルノードとクラスターと互換性があります。
高度なSQL(Structured Query Language)に基づいており、大量のデータをサポートし、構造化テーブルと非構造化データを処理します。
Sparkプラットフォームは、その使いやすさ、大規模なコミュニティ、および超高速で知られています。 開発者はSparkを使用してアプリケーションを構築し、Java、Scala、Python、R、およびSQLでクエリを実行します。
特徴
- データをバッチおよびリアルタイムで処理します
- ダウンサンプリングせずに大量のペタバイトのデータをサポート
- SQL、MLib、Graphx、Streamなどの複数のライブラリを1つのワークフローに簡単に組み合わせることができます。
- Hadoop YARN、Apache Mesos、Kubernetes、さらにはクラウドでも動作し、複数のデータソースにアクセスできます
Knime
Konstanz Information Minerは、データサイエンスアプリケーション向けの直感的なオープンソースプラットフォームです。 データサイエンティストとアナリストは、単純なドラッグアンドドロップ機能を使用して、コーディングせずに視覚的なワークフローを作成できます。
サーバーバージョンは、自動化、データサイエンス管理、および管理分析に使用される取引プラットフォームです。 KNIMEは、データサイエンスワークフローと再利用可能なコンポーネントに誰もがアクセスできるようにします。
特徴
- Oracle、SQL、Hiveなどからのデータ統合に高い柔軟性
- SharePoint、Amazon Cloud、Salesforce、Twitterなどの複数のソースからのデータにアクセスする
- mlの使用は、モデル構築、パフォーマンスチューニング、およびモデル検証の形で行われます。
- 視覚化、統計、処理、およびレポートの形式でのデータ洞察
ビッグデータの5Vの重要性は何ですか?
ビッグデータの5Vは、データサイエンティストがビッグデータを理解および分析して、より多くの洞察を得るのに役立ちます。 また、企業が十分な情報に基づいて決定を下し、競争上の優位性を獲得するのに役立つ統計を提供するのにも役立ちます。
ボリューム:ビッグデータはボリュームに基づいています。 量子ボリュームは、データの大きさを決定します。 通常、テラバイト、ペタバイトなどの大量のデータが含まれています。データサイエンティストは、ボリュームサイズに基づいて、データセット分析のためのさまざまなツールと統合を計画します。
速度:リアルタイムのデータ情報を必要とする企業もあれば、パケットでデータを処理することを好む企業もあるため、データ収集の速度は非常に重要です。 データフローが高速であるほど、より多くのデータサイエンティストが評価し、関連情報を会社に提供できます。
多様性:データはさまざまなソースから取得され、重要なことに、固定形式ではありません。 データは、構造化(データベース形式)、半構造化(XML / RDF)、および非構造化(バイナリデータ)形式で利用できます。 データ構造に基づいて、ビッグデータツールを使用してデータを作成、整理、フィルタリング、および処理します。
正確性:データの正確性と信頼できるソースは、ビッグデータのコンテキストを定義します。 データセットは、コンピューター、ネットワークデバイス、モバイルデバイス、ソーシャルメディアなど、さまざまなソースから取得されます。したがって、データを分析して宛先に送信する必要があります。
価値:最後に、企業のビッグデータはどのくらいの価値がありますか? データサイエンティストの役割は、データを最大限に活用して、データインサイトがビジネスにどのように価値を付加できるかを実証することです。
結論
上記のビッグデータリストには、有料ツールとオープンソースツールが含まれています。 ツールごとに簡単な情報と機能が提供されています。 説明的な情報をお探しの場合は、関連するWebサイトにアクセスしてください。
競争上の優位性を獲得しようとしている企業は、ビッグデータやAI(人工知能)、ML(機械学習)などの関連ツールを使用して、顧客サービス、調査、マーケティング、将来の計画などを改善するための戦術的な行動を取ります。
生産性のわずかな変化が大幅な節約と大きな利益につながる可能性があるため、ビッグデータツールはほとんどの業界で使用されています。 上記の記事がビッグデータツールの概要とその重要性を示してくれることを願っています。
あなたも好きかも:
データエンジニアリングの基礎を学ぶためのオンラインコース。