
13 instrumente de Big Data pe care trebuie să le cunoașteți ca om de știință a datelor
Publicat: 2021-11-30În era informațională, centrele de date colectează cantități mari de date. Datele colectate provin din diverse surse, cum ar fi tranzacțiile financiare, interacțiunile cu clienții, rețelele sociale și multe alte surse și, mai important, se acumulează mai rapid.
Datele pot fi diverse și sensibile și necesită instrumentele potrivite pentru a le face semnificative, deoarece au un potențial nelimitat de a moderniza statisticile de afaceri, informațiile și de a schimba vieți.

Instrumentele Big Data și oamenii de știință de date sunt proeminenti în astfel de scenarii.
O cantitate atât de mare de date diverse face dificilă procesarea utilizând instrumente și tehnici tradiționale, cum ar fi Excel. Excel nu este cu adevărat o bază de date și are o limită (65.536 de rânduri) pentru stocarea datelor.
Analiza datelor în Excel arată o integritate slabă a datelor. Pe termen lung, datele stocate în Excel au securitate și conformitate limitate, rate foarte scăzute de recuperare în caz de dezastru și nici un control adecvat al versiunilor.
Pentru a procesa seturi de date atât de mari și diverse, este nevoie de un set unic de instrumente, numite instrumente de date, pentru a examina, procesa și extrage informații valoroase. Aceste instrumente vă permit să explorați în profunzime datele dvs. pentru a găsi informații și modele de date mai semnificative.
Gestionarea unor instrumente și date tehnologice atât de complexe necesită, în mod natural, un set de abilități unice, și de aceea cercetătorul de date joacă un rol vital în big data.
Importanța instrumentelor de date mari
Datele sunt piatra de bază a oricărei organizații și sunt folosite pentru a extrage informații valoroase, pentru a efectua analize detaliate, pentru a crea oportunități și pentru a planifica noi repere și viziuni de afaceri.
Din ce în ce mai multe date sunt create în fiecare zi care trebuie stocate eficient și în siguranță și rechemate atunci când este necesar. Dimensiunea, varietatea și schimbarea rapidă a acestor date necesită noi instrumente de date mari, diferite metode de stocare și analiză.
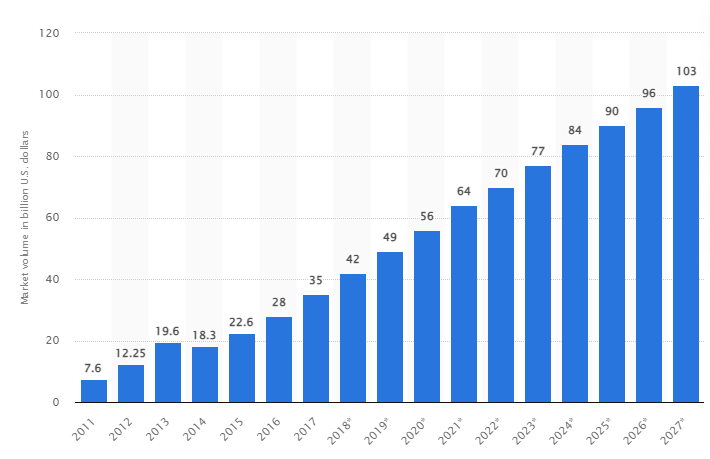
Potrivit unui studiu, piața globală de date mari este de așteptat să crească la 103 miliarde USD până în 2027, mai mult decât dublul dimensiunii pieței estimate în 2018.
Provocările industriei de astăzi
Termenul „big data” a fost folosit recent pentru a se referi la seturi de date care au crescut atât de mari încât sunt dificil de utilizat cu sistemele tradiționale de gestionare a bazelor de date (DBMS).
Dimensiunile datelor cresc constant și astăzi variază de la zeci de terabytes (TB) la mulți petabytes (PB) într-un singur set de date. Dimensiunea acestor seturi de date depășește capacitatea software-ului obișnuit de a procesa, gestiona, căuta, partaja și vizualiza în timp.
Formarea datelor mari va duce la următoarele:
- Managementul și îmbunătățirea calității
- Lanțul de aprovizionare și managementul eficienței
- Inteligența clienților
- Analiza datelor și luarea deciziilor
- Managementul riscului și detectarea fraudei
În această secțiune, analizăm cele mai bune instrumente de date mari și modul în care oamenii de știință de date folosesc aceste tehnologii pentru a le filtra, analiza, stoca și extrage atunci când companiile doresc o analiză mai profundă pentru a-și îmbunătăți și dezvolta afacerea.
Apache Hadoop
Apache Hadoop este o platformă Java open-source care stochează și procesează cantități mari de date.
Hadoop funcționează prin maparea unor seturi mari de date (de la terabytes la petabytes), analizând sarcinile între clustere și împărțind-le în bucăți mai mici (64MB până la 128MB), rezultând o procesare mai rapidă a datelor.
Pentru a stoca și procesa datele, datele sunt trimise către clusterul Hadoop, HDFS (sistemul de fișiere distribuit Hadoop) stochează date, MapReduce procesează datele și YARN (un alt negociator de resurse) împarte sarcinile și atribuie resurse.
Este potrivit pentru cercetătorii de date, dezvoltatorii și analiștii din diverse companii și organizații pentru cercetare și producție.
Caracteristici
- Replicarea datelor: mai multe copii ale blocului sunt stocate în noduri diferite și servesc drept toleranță la erori în cazul unei erori.
- Foarte scalabil: Oferă scalabilitate verticală și orizontală
- Integrare cu alte modele Apache, Cloudera și Hortonworks
Luați în considerare acest curs online genial pentru a învăța Big Data cu Apache Spark.
Rapidminer
Site-ul Rapidminer susține că aproximativ 40.000 de organizații din întreaga lume își folosesc software-ul pentru a crește vânzările, a reduce costurile și a evita riscurile.
Software-ul a primit mai multe premii: Gartner Vision Awards 2021 pentru platformele de știință a datelor și de învățare automată, analiză predictivă multimodală și soluții de învățare automată de la Forrester și cea mai ușor de utilizat platformă de învățare automată și știința datelor de la Crowd, în raportul G2 de primăvară 2021.
Este o platformă end-to-end pentru ciclul de viață științific și este integrată și optimizată perfect pentru construirea de modele ML (învățare automată). Documentează automat fiecare pas de pregătire, modelare și validare pentru o transparență deplină.
Este un software plătit disponibil în trei versiuni: Prep Data, Create and Validate și Deploy Model. Este chiar disponibil gratuit pentru instituțiile de învățământ, iar RapidMiner este folosit de peste 4.000 de universități din întreaga lume.
Caracteristici
- Verifică datele pentru a identifica modele și pentru a remedia problemele de calitate
- Utilizează un designer de flux de lucru fără cod cu peste 1500 de algoritmi
- Integrarea modelelor de învățare automată în aplicațiile de afaceri existente
Tablou
Tableau oferă flexibilitatea de a analiza vizual platformele, de a rezolva probleme și de a împuternici oamenii și organizațiile. Se bazează pe tehnologia VizQL (limbaj vizual pentru interogări de baze de date), care convertește drag and drop în interogări de date printr-o interfață intuitivă de utilizator.
Tableau a fost achiziționat de Salesforce în 2019. Acesta permite conectarea datelor din surse precum baze de date SQL, foi de calcul sau aplicații cloud precum Google Analytics și Salesforce.
Utilizatorii își pot achiziționa versiunile Creator, Explorer și Viewer în funcție de preferințele de afaceri sau individuale, deoarece fiecare are propriile caracteristici și funcții.
Este ideal pentru analiști, oameni de știință de date, sectorul educațional și utilizatorii de afaceri pentru a implementa și echilibra o cultură bazată pe date și pentru a o evalua prin rezultate.
Caracteristici
- Tablourile de bord oferă o imagine de ansamblu completă a datelor sub formă de elemente vizuale, obiecte și text.
- O gamă largă de diagrame de date: histograme, diagrame Gantt, diagrame, diagrame de mișcare și multe altele
- Filtru de protecție la nivel de rând pentru a menține datele în siguranță și stabile
- Arhitectura sa oferă analize și prognoze previzibile
Învățarea Tableau este ușor.
Cloudera
Cloudera oferă o platformă sigură pentru cloud și centre de date pentru gestionarea datelor mari. Folosește analiza datelor și învățarea automată pentru a transforma datele complexe în informații clare și acționabile.
Cloudera oferă soluții și instrumente pentru cloud-uri private și hibride, ingineria datelor, fluxul de date, stocarea datelor, știința datelor pentru oamenii de știință ai datelor și multe altele.
O platformă unificată și analize multifuncționale îmbunătățesc procesul de descoperire a informațiilor bazate pe date. Știința sa de date oferă conectivitate la orice sistem pe care îl folosește organizația, nu doar Cloudera și Hortonworks (ambele companii au colaborat).
Oamenii de știință de date își gestionează propriile activități, cum ar fi analiza, planificarea, monitorizarea și notificările prin e-mail prin foi de lucru interactive pentru știința datelor. În mod implicit, este o platformă conformă cu securitatea, care permite oamenilor de știință să acceseze datele Hadoop și să execute cu ușurință interogări Spark.
Platforma este potrivită pentru inginerii de date, oamenii de știință de date și profesioniștii IT din diverse industrii, cum ar fi spitale, instituții financiare, telecomunicații și multe altele.
Caracteristici
- Acceptă toate cloud-urile publice și private majore, în timp ce bancul de lucru Data Science acceptă implementări on-premise
- Canalele automate de date convertesc datele în forme utilizabile și le integrează cu alte surse.
- Fluxul de lucru uniform permite construirea, instruirea și implementarea rapidă a modelului.
- Mediu securizat pentru autentificare, autorizare și criptare Hadoop
Apache Hive
Apache Hive este un proiect open-source dezvoltat pe baza Apache Hadoop. Permite citirea, scrierea și gestionarea seturilor mari de date disponibile în diferite depozite și permite utilizatorilor să-și combine propriile funcții pentru o analiză personalizată.
Hive este conceput pentru sarcinile tradiționale de stocare și nu este destinat sarcinilor de procesare online. Cadrele sale robuste de lot oferă scalabilitate, performanță, scalabilitate și toleranță la erori.
Este potrivit pentru extragerea datelor, modelarea predictivă și indexarea documentelor. Nu este recomandat pentru interogarea datelor în timp real, deoarece introduce latență în obținerea rezultatelor.
Caracteristici
- Acceptă motorul de calcul MapReduce, Tez și Spark
- Procesați seturi uriașe de date, de câțiva petaocteți
- Foarte ușor de codificat în comparație cu Java
- Oferă toleranță la erori prin stocarea datelor în sistemul de fișiere distribuit Apache Hadoop
Apache Storm
The Storm este o platformă gratuită, open-source, folosită pentru a procesa fluxuri de date nelimitate. Acesta oferă cel mai mic set de unități de procesare utilizate pentru a dezvolta aplicații care pot procesa cantități foarte mari de date în timp real.
O furtună este suficient de rapidă pentru a procesa un milion de tupli pe secundă pe nod și este ușor de operat.
Apache Storm vă permite să adăugați mai multe noduri în cluster și să creșteți puterea de procesare a aplicațiilor. Capacitatea de procesare poate fi dublată prin adăugarea de noduri pe măsură ce se menține scalabilitatea orizontală.
Oamenii de știință de date pot folosi Storm pentru DRPC (Distributed Remote Procedure Calls), analiza ETL (Retrieval-Conversion-Load) în timp real, calculul continuu, învățarea automată online etc. Este configurat pentru a satisface nevoile de procesare în timp real ale Twitter , Yahoo și Flipboard.
Caracteristici
- Ușor de utilizat cu orice limbaj de programare
- Este integrat în fiecare sistem de așteptare și în fiecare bază de date.
- Storm folosește Zookeeper pentru a gestiona clustere și se extinde la dimensiuni mai mari ale clusterelor
- Protecția garantată a datelor înlocuiește tuplurile pierdute dacă ceva nu merge bine
Știința datelor despre fulgi de zăpadă
Cea mai mare provocare pentru oamenii de știință de date este pregătirea datelor din diferite resurse, deoarece se petrece timp maxim pentru extragerea, consolidarea, curățarea și pregătirea datelor. Acesta este adresat de Snowflake.

Oferă o singură platformă de înaltă performanță care elimină problemele și întârzierile cauzate de ETL (Load Transformation and Extraction). De asemenea, poate fi integrat cu cele mai recente instrumente și biblioteci de învățare automată (ML), precum Dask și Saturn Cloud.
Snowflake oferă o arhitectură unică de clustere de calcul dedicate pentru fiecare sarcină de lucru pentru a efectua astfel de activități de calcul la nivel înalt, astfel încât nu există nicio partajare a resurselor între știința datelor și încărcăturile de lucru BI (intelligence de afaceri).
Acceptă tipuri de date din date structurate, semi-structurate (JSON, Avro, ORC, Parquet sau XML) și nestructurate. Utilizează o strategie de lac de date pentru a îmbunătăți accesul la date, performanța și securitatea.
Oamenii de știință și analiștii de date folosesc fulgi de zăpadă în diverse industrii, inclusiv finanțe, media și divertisment, retail, sănătate și științe ale vieții, tehnologie și sectorul public.
Caracteristici
- Compresie ridicată a datelor pentru a reduce costurile de stocare
- Oferă criptarea datelor în repaus și în tranzit
- Motor de procesare rapidă cu complexitate operațională scăzută
- Profilarea datelor integrată cu vizualizări de tabel, diagramă și histogramă
Datarobot
Datarobot este lider mondial în cloud cu AI (Inteligenta Artificiala). Platforma sa unică este concepută pentru a deservi toate industriile, inclusiv utilizatorii și diferitele tipuri de date.
Compania susține că software-ul este utilizat de o treime din companiile Fortune 50 și oferă mai mult de un trilion de estimări în diverse industrii.
Dataroabot folosește învățarea automată a mașinilor (ML) și este proiectat pentru profesioniștii de date pentru întreprinderi pentru a crea, adapta și implementa rapid modele de prognoză precise.
Oferă oamenilor de știință acces ușor la mulți dintre cei mai noi algoritmi de învățare automată cu transparență completă pentru a automatiza preprocesarea datelor. Software-ul a dezvoltat clienți R și Python dedicati pentru oamenii de știință pentru a rezolva probleme complexe de știință a datelor.
Ajută la automatizarea calității datelor, a ingineriei caracteristicilor și a proceselor de implementare pentru a ușura activitățile cercetătorilor de date. Este un produs premium, iar prețul este disponibil la cerere.
Caracteristici
- Creste valoarea afacerii din punct de vedere al profitabilitatii, prognoza simplificata
- Procese de implementare și automatizare
- Acceptă algoritmi de la Python, Spark, TensorFlow și alte surse.
- Integrarea API vă permite să alegeți dintre sute de modele
TensorFlow
TensorFlow este o bibliotecă bazată pe AI (inteligență artificială) comunitară care utilizează diagrame de flux de date pentru a construi, antrena și implementa aplicații de învățare automată (ML). Acest lucru le permite dezvoltatorilor să creeze rețele neuronale mari stratificate.
Include trei modele – TensorFlow.js, TensorFlow Lite și TensorFlow Extended (TFX). Modul său javascript este folosit pentru antrenarea și implementarea modelelor în browser și pe Node.js în același timp. Modul său simplificat este pentru implementarea modelelor pe dispozitive mobile și încorporate, iar modelul TFX este pentru pregătirea datelor, validarea și implementarea modelelor.
Datorită platformei sale robuste, ar putea fi implementat pe servere, dispozitive edge sau web, indiferent de limbajul de programare.
TFX conține mecanisme pentru a impune conductele ML care pot fi ascendente și oferă sarcini de performanță generală robuste. Conductele de inginerie de date precum Kubeflow și Apache Airflow acceptă TFX.
Platforma Tensorflow este potrivită pentru începători. Intermediar și pentru experți să antreneze o rețea generativă adversară pentru a genera imagini ale cifrelor scrise de mână folosind Keras.
Caracteristici
- Poate implementa modele ML on-premise, cloud și în browser și indiferent de limbă
- Construire ușoară de model folosind API-uri înnăscute pentru repetarea rapidă a modelului
- Diversele biblioteci și modele suplimentare susțin activități de cercetare pentru a experimenta
- Construire ușoară a modelului folosind mai multe niveluri de abstractizare
Matplotlib
Matplotlib este un software comunitar cuprinzător pentru vizualizarea datelor animate și a graficelor pentru limbajul de programare Python. Designul său unic este structurat astfel încât un grafic de date vizuale este generat folosind câteva linii de cod.
Există diverse aplicații terță parte, cum ar fi programe de desen, interfețe grafice, hărți de culori, animații și multe altele care sunt concepute pentru a fi integrate cu Matplotlib.
Funcționalitatea sa poate fi extinsă cu multe instrumente, cum ar fi Basemap, Cartopy, GTK-Tools, Natgrid, Seaborn și altele.
Cele mai bune caracteristici ale sale includ desenarea de grafice și hărți cu date structurate și nestructurate.
Bigml
Bigml este o platformă colectivă și transparentă pentru ingineri, cercetători, dezvoltatori și analiști. Efectuează transformarea datelor de la capăt la capăt în modele acționabile.
Acesta creează, experimentează, automatizează și gestionează în mod eficient fluxurile de lucru ml, contribuind la aplicații inteligente într-o gamă largă de industrii.
Această platformă programabilă ML (învățare automată) ajută la secvențierea, predicția serii cronologice, detectarea asocierilor, regresia, analiza clusterului și multe altele.
Versiunea sa complet gestionabilă, cu chiriași unici și mai mulți și o posibilă implementare pentru orice furnizor de cloud, facilitează ca întreprinderile să ofere tuturor acces la date mari.
Prețul său începe de la 30 USD și este gratuit pentru seturi de date mici și în scopuri educaționale și este folosit în peste 600 de universități.
Datorită algoritmilor săi robusti ML proiectați, este potrivit în diverse industrii, cum ar fi farmaceutică, divertisment, auto, aerospațială, asistență medicală, IoT și multe altele.
Caracteristici
- Automatizați fluxurile de lucru complexe și consumatoare de timp într-un singur apel API.
- Poate procesa cantități mari de date și poate efectua sarcini paralele
- Biblioteca este acceptată de limbaje de programare populare, cum ar fi Python, Node.js, Ruby, Java, Swift etc.
- Detaliile sale granulare ușurează munca de audit și cerințele de reglementare
Apache Spark
Este unul dintre cele mai mari motoare open-source utilizate pe scară largă de companiile mari. Spark este folosit de 80% dintre companiile Fortune 500, potrivit site-ului. Este compatibil cu noduri și clustere unice pentru date mari și ML.
Se bazează pe SQL (Structured Query Language) avansat pentru a suporta cantități mari de date și pentru a lucra cu tabele structurate și date nestructurate.
Platforma Spark este cunoscută pentru ușurința în utilizare, comunitatea mare și viteza fulgerului. Dezvoltatorii folosesc Spark pentru a construi aplicații și a rula interogări în Java, Scala, Python, R și SQL.
Caracteristici
- Prelucrează datele în lot, precum și în timp real
- Acceptă cantități mari de petaocteți de date fără eșantionare
- Facilitează combinarea mai multor biblioteci precum SQL, MLib, Graphx și Stream într-un singur flux de lucru.
- Funcționează pe Hadoop YARN, Apache Mesos, Kubernetes și chiar și în cloud și are acces la mai multe surse de date
Knime
Konstanz Information Miner este o platformă open-source intuitivă pentru aplicații de știință a datelor. Un om de știință de date și un analist pot crea fluxuri de lucru vizuale fără codare, cu o simplă funcționalitate de glisare și plasare.
Versiunea de server este o platformă de tranzacționare utilizată pentru automatizare, managementul științei datelor și analiza managementului. KNIME face ca fluxurile de lucru din știința datelor și componentele reutilizabile să fie accesibile tuturor.
Caracteristici
- Foarte flexibil pentru integrarea datelor de la Oracle, SQL, Hive și multe altele
- Accesați date din mai multe surse, cum ar fi SharePoint, Amazon Cloud, Salesforce, Twitter și multe altele
- Utilizarea ml este sub formă de construire a modelului, reglare a performanței și validare a modelului.
- Informații despre date sub formă de vizualizare, statistici, procesare și raportare
Care este importanța celor 5 V-uri ale datelor mari?
Cele 5 V-uri ale datelor mari îi ajută pe oamenii de știință de date să înțeleagă și să analizeze datele mari pentru a obține mai multe informații. De asemenea, ajută la furnizarea de mai multe statistici utile pentru companii pentru a lua decizii informate și pentru a obține un avantaj competitiv.
Volum: Big data se bazează pe volum. Volumul cuantic determină cât de mari sunt datele. De obicei, conține o cantitate mare de date în terabytes, petabytes etc. În funcție de dimensiunea volumului, oamenii de știință de date planifică diverse instrumente și integrări pentru analiza setului de date.
Viteza: Viteza de colectare a datelor este critică, deoarece unele companii au nevoie de informații despre date în timp real, iar altele preferă să proceseze datele în pachete. Cu cât fluxul de date este mai rapid, cu atât oamenii de știință de date pot evalua și furniza informații relevante companiei.
Varietate: Datele provin din surse diferite și, cel mai important, nu într-un format fix. Datele sunt disponibile în formate structurate (format bază de date), semistructurate (XML/RDF) și nestructurate (date binare). Pe baza structurilor de date, instrumentele de date mari sunt folosite pentru a crea, organiza, filtra și procesa datele.
Veracitatea: acuratețea datelor și sursele credibile definesc contextul de date mari. Setul de date provine din diverse surse precum computere, dispozitive de rețea, dispozitive mobile, social media etc. În consecință, datele trebuie analizate pentru a fi trimise la destinație.
Valoare: În sfârșit, cât valorează datele mari ale unei companii? Rolul cercetătorului de date este de a folosi cât mai bine datele pentru a demonstra modul în care informațiile despre date pot adăuga valoare unei afaceri.
Concluzie
Lista de date mari de mai sus include instrumentele plătite și instrumentele open source. Pentru fiecare instrument sunt furnizate scurte informații și funcții. Dacă căutați informații descriptive, puteți vizita site-urile web relevante.
Companiile care doresc să obțină un avantaj competitiv folosesc big data și instrumente conexe precum AI (inteligență artificială), ML (învățare automată) și alte tehnologii pentru a întreprinde acțiuni tactice pentru a îmbunătăți serviciile pentru clienți, cercetarea, marketingul, planificarea viitoare etc.
Instrumentele de date mari sunt folosite în majoritatea industriilor, deoarece micile modificări ale productivității se pot traduce în economii semnificative și profituri mari. Sperăm că articolul de mai sus v-a oferit o privire de ansamblu asupra instrumentelor de date mari și a semnificației acestora.
Ați putea dori, de asemenea:
Cursuri online pentru a învăța elementele de bază ale ingineriei datelor.