
SEO pentru conținut duplicat: Cum să verificați conținutul duplicat
Publicat: 2022-06-14Conținutul duplicat poate afecta care dintre paginile dvs. apare în rezultatele căutării și vă poate risipi bugetul de accesare cu crawlere. Din fericire, există modalități de a identifica conținutul duplicat și fie de a-l elimina de pe site-ul dvs. web, fie de pe indexul Google, pentru a preveni ca acesta să vă afecteze negativ capacitatea de a vă clasifica.
Ce este conținutul duplicat?
Conținutul duplicat apare atunci când același conținut apare în mai multe locații cu o adresă URL unică.
Conținutul nu trebuie să fie o potrivire exactă pentru a se înregistra ca fiind duplicat - poate fi și ceea ce Google numește „în mod semnificativ similar”. Acest conținut este în esență „suficient de apropiat” pentru a fi considerat conținut duplicat, chiar dacă unele texte pot diferi.
Majoritatea proprietarilor de site-uri lucrează din greu pentru a se asigura că conținutul lor este proaspăt și original și, totuși, există încă o mulțime de conținut duplicat pe web. Uneori, proprietarii de site-uri nici măcar nu sunt conștienți de asta. Deci cum se întâmplă asta?
De ce se întâmplă conținut duplicat?
Cea mai mare parte a conținutului duplicat de pe web apare din cauza indexării unor lucruri precum versiunile de pagini care se pot imprima, produse care sunt sau la care sunt legate prin mai multe adrese URL diferite și forumuri de discuții care generează versiuni desktop și versiuni mobile reduse ale aceleiași pagini. .
Dar acestea nu sunt singurele moduri prin care poți ajunge la conținut duplicat pe site-ul tău. Iată câteva exemple suplimentare despre modul în care conținutul duplicat se poate întâmpla intern pe site-ul dvs. și extern pe alte site-uri.
Duplicate generate intern
Pagini de produse considerabil similare
Uneori poate avea sens să creezi în mod intenționat pagini similare, în special în comerțul electronic. De exemplu, să presupunem că vindeți același produs în două țări diferite. În acest caz, puteți alege să aveți două pagini aproape identice, cu excepția faptului că una ar putea afișa prețul în dolari SUA, în timp ce cealaltă îl afișează în dolari canadieni.
Un alt exemplu sunt paginile de produse care par semnificativ similare, deoarece prezintă aceeași copie, singurele diferențe reale fiind o imagine diferită a produsului, numele produsului și prețul produsului.
Sisteme de management al conținutului
Uneori, sistemele de management al conținutului creează conținut duplicat de care s-ar putea să nu fii conștient. Unele sisteme adaugă automat etichete și parametri URL pentru căutări, rezultând mai multe căi către exact același conținut.
Variante URL
Puteți, de asemenea, să obțineți conținut duplicat dacă aveți diferite variații URL care prezintă același conținut. După cum sa menționat anterior, sistemele de gestionare a conținutului pot face acest lucru singure și puteți ajunge la două variante de adresă URL, cum ar fi https://www.website.com/blog1 și https://www.website.com/blogs/blog1 . Alte variații ale adresei URL, cum ar fi barele oblice finale sau adresele URL cu majuscule, pot cauza aceeași problemă.
Când se întâmplă acest lucru, este posibil ca Google să nu știe ce pagină să clasifice și unele surse externe pot trimite către una dintre aceste pagini, în timp ce altele pot trimite către duplicat, rupând echitatea link-urilor paginii dvs. în acest proces.
HTTP vs HTTPS și www vs non-www
Majoritatea site-urilor web sunt accesibile cu sau fără www sau la ambele adrese URL HTTP sau HTTPS. Cu toate acestea, dacă nu v-ați configurat corect site-ul, Google poate indexa pagini de la mai multe dintre ele, rezultând conținut duplicat.
URL-uri compatibile cu imprimantă și mobile
Paginile pentru imprimantă sau pentru dispozitive mobile găzduite la adrese URL diferite decât pagina originală vor avea ca rezultat conținut duplicat, dacă nu sunt corect indexate.
ID-uri de sesiune
ID-urile de sesiune pot fi instrumente valoroase pentru a urmări vizitatorii care vă vizitează site-ul. Acest lucru se face în general prin adăugarea unui șir lung de ID de sesiune la adresa URL. Deoarece fiecare ID de sesiune este unic, aceasta creează o nouă adresă URL și vă dublează conținutul.
Parametrii UTM
Parametrii pot urmări vizitatorii veniți din diverse surse. La fel ca ID-urile de sesiune, acestea generează adrese URL unice, deși conținutul paginii este același, creând astfel conținut duplicat dacă este indexat.
Duplicate generate extern
Conținut sindicalizat
Sindicarea conținutului dvs. către alte site-uri de pe web poate fi o modalitate excelentă de a genera mai mult trafic către site-ul dvs. web și de a vă afișa numele. Cu toate acestea, acest conținut poate apărea în continuare ca conținut duplicat dacă nu este formatat cu etichetele de antet canonice adecvate. De exemplu, utilizarea etichetelor canonice pe articolele Medium vă poate proteja conținutul original de înregistrarea ca duplicat.
Plagiat
În timp ce majoritatea conținutului duplicat nu este de natură rău intenționată, unii webmasteri copiază conținut în mod deliberat, căutând să beneficieze de conținut pe care nu l-au produs ei înșiși.
SEO pentru conținut duplicat: de ce contează?
Dacă conținutul duplicat apare atât de des, de ce contează? Iată cinci moduri în care vă poate afecta capacitatea de a vă clasa bine în rezultatele căutării.
1. Google Penalizare pentru conținut duplicat
Google nu penalizează direct conținutul duplicat - de cele mai multe ori. Dacă Google consideră că conținutul duplicat de pe site-ul dvs. este „înșelător” și „intenționează să manipuleze rezultatele motorului de căutare”, atunci poate lua măsuri prin aplicarea unei penalizări pentru conținutul duplicat. Deci, deși nu se întâmplă des, conform regulilor Google privind conținutul duplicat, este posibil să ajungeți totuși să aveți de-a face cu o penalizare directă dacă conținutul dvs. duplicat este suficient de flagrant și se crede că a fost creat cu intenții rău intenționate.
O penalizare Google pentru conținut duplicat este rară, așa că preocuparea mai presantă este relația dintre conținutul duplicat și SEO.
2. Index Balonare
Balonarea indexului se întâmplă atunci când crawlerele motoarelor de căutare accesează și indexează conținut neimportant sau de calitate scăzută, cum ar fi acele pagini ușor de imprimat pe care le-am menționat. Acest lucru afectează capacitatea dvs. de a face ca paginile dvs. importante să se clasifice, deoarece motoarele de căutare nu vor ști ce versiune a conținutului dvs. să sugereze utilizatorilor și ar putea clasa o altă versiune decât ați prefera dvs. De asemenea, afectează bugetul de accesare cu crawlere.
3. Buget de accesare cu crawlere
Google limitează timpul petrecut cu crawlerea site-urilor. Cantitatea de resurse oferite de Google pentru accesarea cu crawlere și indexarea site-ului dvs. reprezintă bugetul dvs. de accesare cu crawlere. Când aveți mult conținut duplicat, riscați să vă pierdeți bugetul de accesare cu crawlere pe pagini care nu sunt la fel de importante.
4. Canibalizarea cuvintelor cheie
Dacă mai multe copii ale unei pagini sunt clasate, atunci paginile dvs. vor concura între ele pentru aceleași cuvinte cheie și vizibilitate. Este destul de greu să concurezi cu toți ceilalți, de ce să-l faci mai greu concurând și cu tine?
În cele din urmă, nu poți ignora pur și simplu problemele de conținut duplicat SEO. Ori de câte ori este posibil, încercați să consolidați sau să eliminați conținutul duplicat.
5. Diminuarea Link Equity
Să presupunem că Google decide să clasifice două dintre paginile dvs. considerabil similare. De unde știu dacă să atribuie toată valoarea conținutului unei singure pagini sau dacă autoritatea, echitatea linkurilor și încrederea ar trebui împărțite între ambele pagini? Această situație poate reduce valoarea SEO a conținutului dvs., determinându-l să aibă performanțe slabe.
Echitatea link-urilor backlink-urilor dvs. va fi, de asemenea, împărțită între cele două pagini, în funcție de dacă alte site-uri aleg să facă linkuri.
Cum să verificați dacă există conținut duplicat pe propriul dvs. site
Găsirea conținutului duplicat pe site-ul dvs. este gratuită și ușoară. Utilizați versiuni gratuite de Screaming Frog și Siteliner pentru a vă accesa cu crawlere metodic site-ul și a identifica orice pagini exacte sau aproape duplicate.
Cum să utilizați Screaming Frog pentru a descoperi conținut duplicat
Screaming Frog este un crawler de site-uri web și un instrument de audit SEO care vă poate ajuta să identificați problemele de conținut duplicat de pe site-ul dvs. Iată cum să utilizați Screaming Frog pentru a scana gratuit până la 500 de adrese URL.
1. Accesați cu crawlere site-ul dvs. cu SEO Spider
Mai întâi, descărcați și deschideți Screaming Frog. Introduceți adresa URL a site-ului web pe care doriți să îl accesați cu crawlere în câmpul „Introduceți adresa URL la Spider” și faceți clic pe „Începeți”.
2. Verificați dacă există duplicate în fila „Conținut”.
Faceți clic pe fila „Conținut” pentru a verifica dacă există duplicate exacte și aproape duplicate. Veți putea vedea duplicatele exacte în timp real, dar trebuie să efectuați o „Analiză cu crawlere” pentru a vedea lista aproape duplicate.

3. Verificați dacă există aproape duplicate
Faceți clic pe fila „Analiză cu crawlere” din bara de meniu și alegeți „Start” din meniul derulant.
Când se termină analiza accesării cu crawlere, veți vedea coloanele populate aproape duplicate. Veți ști că s-a terminat, deoarece bara de progres „analiza” va citi 100%, iar filtrul aproape duplicat nu va mai afișa un mesaj „analiză cu crawlere necesară”.
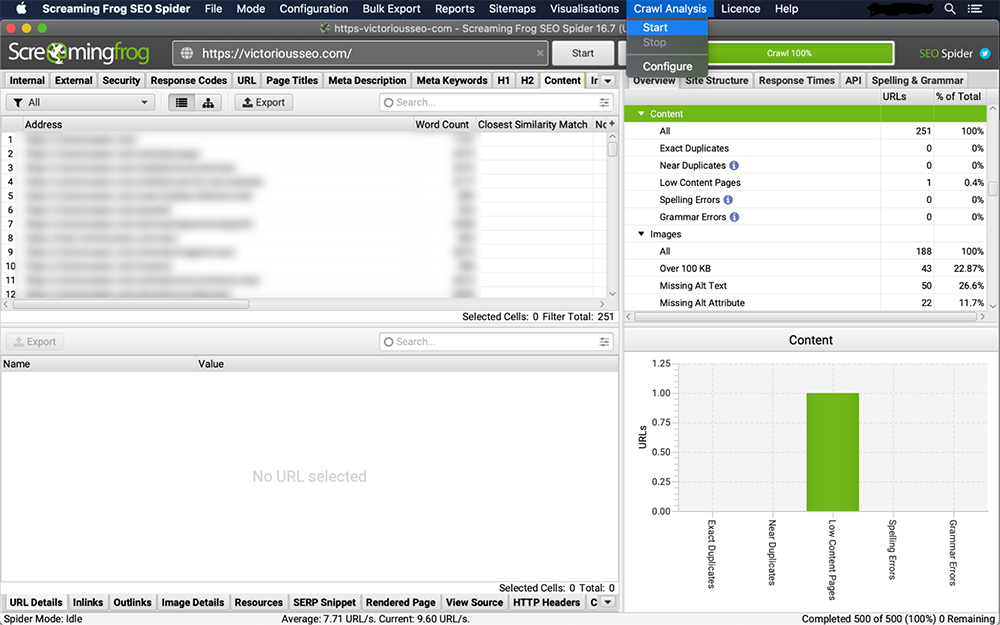
4. Vizualizați duplicatele în fila „Conținut”.
„Cea mai apropiată potrivire de similaritate”, „Nu. Coloanele Aproape Duplicate” și „Adresă” vor fi populate după ce analiza accesării cu crawlere este finalizată.

Filtrul „Duplicate exacte” va afișa pagini care sunt identice între ele pe baza unei scanări a codului HTML. Pragul de similaritate setat determină ceea ce se califică drept „Aproape duplicate”. Pentru a modifica pragul, accesați „Configurare → Păianjen → Conținut. Acest prag este setat la 90% în mod implicit, dar sunteți liber să îl schimbați în ceea ce doriți.
Acum că scanarea este finalizată, examinați manual orice pagină care apare ca o copie exactă sau aproape duplicată.
Cum să utilizați Siteliner pentru a descoperi conținut duplicat
Siteliner este un alt instrument gratuit pe care îl puteți folosi pentru a vă scana site-ul web (sau orice site) pentru conținut duplicat. Cu toate acestea, versiunea gratuită vă va limita la o utilizare la fiecare 30 de zile și va limita numărul de rezultate la 250 de pagini. Dacă trebuie să efectuați mai multe căutări sau doriți să vedeți mai multe rezultate, înscrieți-vă pentru versiunea premium.
Pentru a verifica dacă există conținut duplicat cu Siteliner, trebuie doar să introduceți adresa URL pe care doriți să o căutați în caseta de căutare de pe pagina de pornire.
Siteliner va analiza apoi site-ul și vă va spune cât de mult conținut duplicat a fost găsit și va evidenția ceea ce consideră că sunt principalele probleme. De asemenea, va afișa mai multe valori, inclusiv unele care pot fi utile pentru SEO, cum ar fi timpul mediu de încărcare a paginii, linkurile interne și externe și linkurile de intrare.
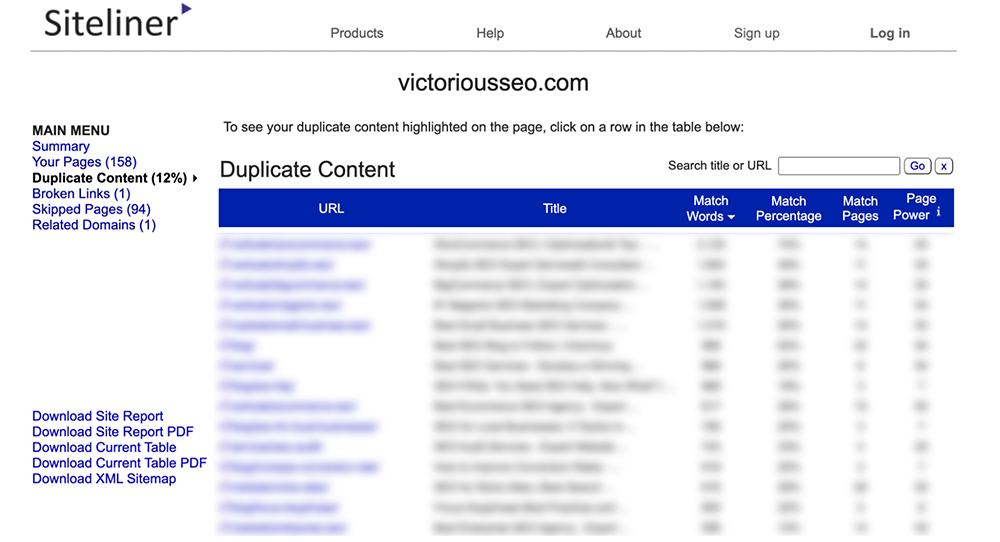
În meniul principal, faceți clic pe „Conținut duplicat” pentru a vedea ce pagini Siteline identifică ca având conținut duplicat.
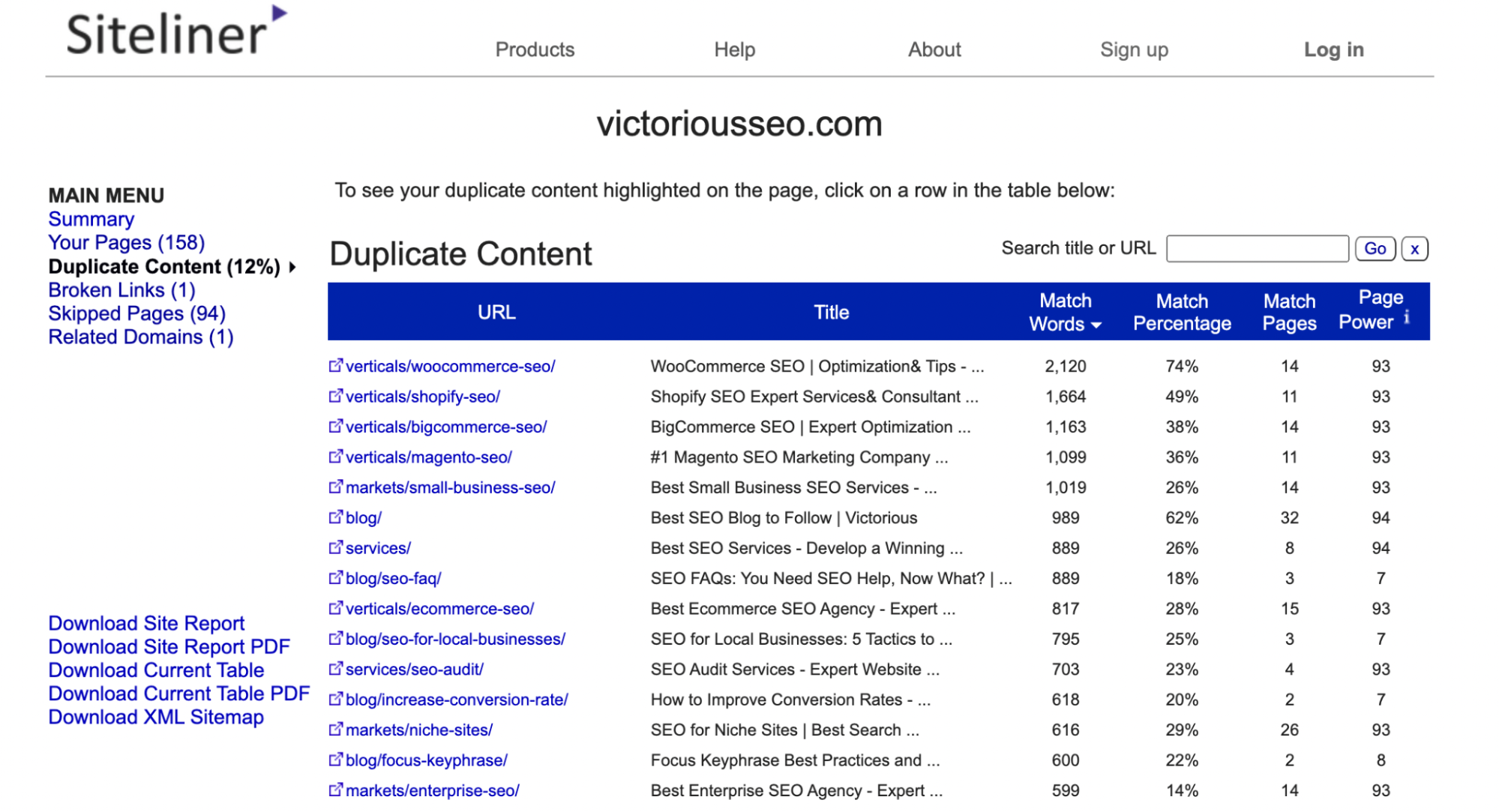
Faceți clic pe fiecare linie individuală pentru a vedea ce text este marcat ca duplicat.
Notă: Siteline va identifica anteturile și subsolurile care apar pe mai multe pagini ca conținut duplicat, astfel încât este posibil să obțineți multe pagini care au un procent de potrivire scăzut, deoarece au fiecare același conținut de meniu sau subsol.
Cum să verificați dacă altcineva v-a copiat conținutul
Există, de asemenea, instrumente de căutare a conținutului duplicat pe care le puteți utiliza pentru a verifica dacă altcineva de pe web v-a copiat conținutul. Copyscape este un instrument gratuit de verificare a conținutului site-ului web, care este eficient și ușor de utilizat.
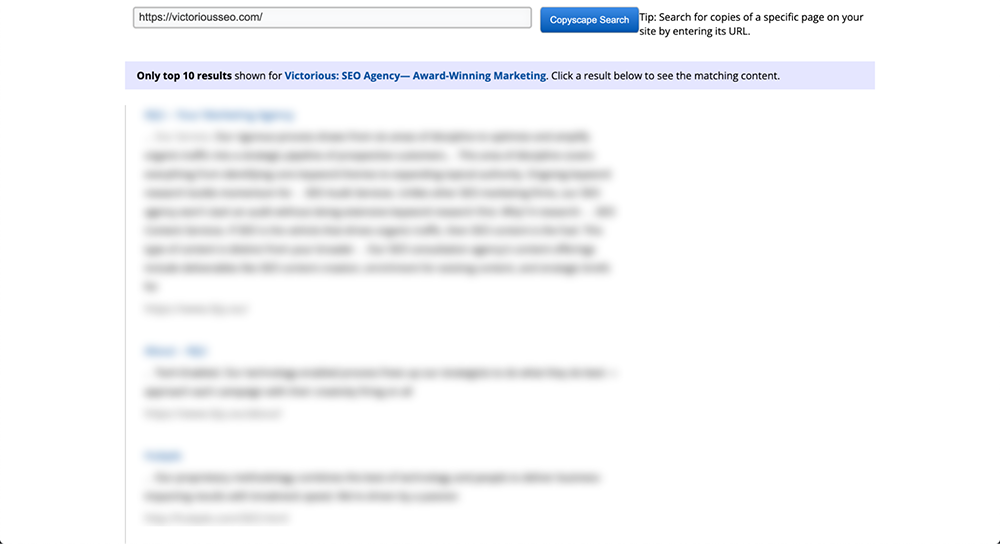
Trebuie doar să inserați o adresă URL în caseta de căutare și să faceți clic pe butonul „Go” de lângă ea. Copyscape va efectua apoi o căutare pe întregul web pentru a vedea dacă există conținut text similar în altă parte.

Dacă găsește ceva, Copyscape va returna rezultatele și le va organiza într-o listă care seamănă cu rezultatele căutării Google. Acest lucru vă permite să parcurgeți cu ușurință prin ele și să vedeți cât de mult din conținutul dvs. a fost copiat. Vă puteți gândi la asta ca la un verificator de conținut duplicat Google.
Ce poți face dacă descoperi că altcineva ți-a plagiat conținutul?
Mai întâi, contactați proprietarul site-ului și cereți-i fie să elimine conținutul, fie să adauge un link canonic la conținutul original de pe site-ul dvs. Dacă acest lucru nu funcționează, trimiteți o solicitare de eliminare DMCA la Google.
Notă: dacă ați sindicalizat în mod intenționat conținutul și ați permis altor site-uri web să-l publice, acesta va apărea în continuare ca duplicat. De aceea, este important să solicitați site-ului de publicare să includă un link canonic sau o etichetă noindex pe pagină, pentru a o împiedica să concureze cu propria pagină în clasamentele motoarelor de căutare.
Cum să remediați conținutul duplicat
Pentru a remedia problemele de conținut duplicat, identificați ce copie doriți să recunoască Google ca versiune originală. De asemenea, va trebui să decideți dacă doriți să eliminați cu totul paginile duplicat sau dacă doriți pur și simplu să spuneți Google să nu le indexeze. În funcție de ceea ce decideți, există câteva moduri diferite de a vă curăța conținutul duplicat.
Noindex cu etichete Meta Robots și Robots.txt
O modalitate de a minimiza impactul conținutului duplicat asupra SEO este să deindexați manual orice pagini duplicate modificând etichetele meta roboti. Pentru a face acest lucru, utilizați eticheta meta robots și setați-i valorile la „noindex, follow”. Aplicați această etichetă la antetul HTML al fiecărei pagini pe care doriți să o excludeți din rezultatele căutării.
Eticheta meta-roboți permite motoarelor de căutare să acceseze cu crawlere legăturile de pe pagina pe care este aplicată, dar împiedică crawlerii de căutare să le includă în indici.
De ce permiteți Google să acceseze cu crawlere pagina dacă nu doriți să fie indexată? Deoarece Google a avertizat în mod explicit împotriva restricționării accesului cu crawlere la orice conținut duplicat de pe site-ul dvs. Vor să știe că este acolo, chiar dacă nu vrei să-l indexeze.
O etichetă noindex ar trebui să arate astfel atunci când este aplicată codului dvs. HTML:
<head> [cod] <meta name=”roboți” content=”noindex, follow”> [alt cod dacă este necesar] </head>
Eticheta meta roboți este o modalitate simplă și eficientă de a deindexa conținutul duplicat și de a evita posibilele probleme de SEO de la a avea pagini considerabil similare sau duplicate exacte pe site-ul dvs.
Dacă aveți directoare întregi pe care doriți să blocați Google și alte motoare de căutare de la indexare, editați fișierul robots.txt.
301 Redirecționări
O altă modalitate de a gestiona o problemă de conținut duplicat este cu o redirecționare 301. 301 sunt redirecționări permanente care redirecționează traficul dinspre pagina duplicată și către o altă adresă URL. Redirecționările 301 sunt prietenoase cu SEO și vă ajută să combinați mai multe pagini într-o singură adresă URL, astfel încât să își consolideze echitatea link-urilor.
Când utilizați o redirecționare 301, pagina duplicată sau similară nu va mai accepta niciun trafic, așa că utilizați-o numai atunci când sunteți de acord că pagina duplicată nu mai este accesibilă, cum ar fi atunci când tăiați conținutul. Dacă tot doriți ca pagina să fie accesibilă, utilizați o etichetă meta robots pentru a nu o indexa.
Rel Canonical
O altă modalitate de a gestiona conținutul duplicat este să folosești atributul rel=canonic pentru a prioritiza paginile. Plasați atributul rel=canonical în interiorul etichetei HTML <head> pentru a spune motoarelor de căutare că o anumită pagină există ca o copie a altei pagini și că toate linkurile și puterea de clasare care aparțin acestei pagini ar trebui de fapt atribuite canonicului. pagină.
O etichetă rel=canonical arată cam așa când este aplicată codului dvs. HTML:
<head> [cod] <link href=”Adresa URL a paginii prioritare” rel="canonical” /> </head>
De asemenea, puteți utiliza o etichetă canonică autoreferențială pentru a indica că doriți ca o anumită pagină să fie tratată ca versiune originală.
Eliminați adresele URL din Sitemap-ul dvs. XML
Sitemap-ul dvs. XML ar trebui să includă numai adresele URL pe care doriți să le indexați. Dacă nu utilizați o adresă URL dinamică care vă actualizează automat harta site-ului, va trebui să editați manual harta și să eliminați orice URL pe care nu le indexați sau le redirecționați.
Eliminați adresa URL din Google Search Console
Dacă alegeți să redirecționați o pagină sau să restricționați indexarea, solicitați Google să elimine acea adresă URL din indexul acesteia.
Conectați-vă la Google Search Console și selectați „Eliminări” din meniul din stânga.
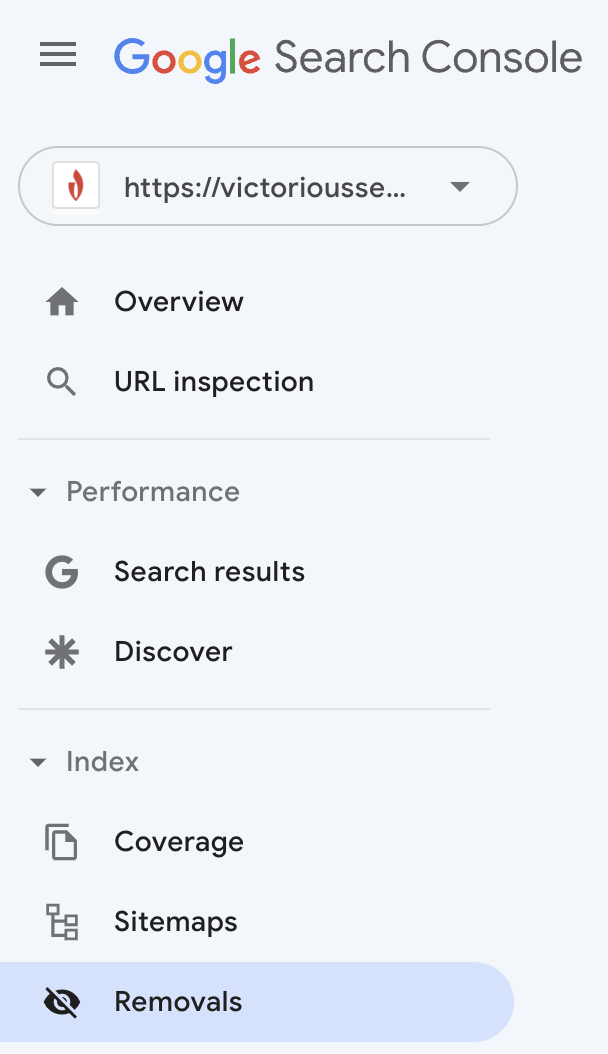
Va apărea o casetă care vă va anunța că trimiterea unei adrese URL o va elimina din indexul Google pentru doar șase luni. După acest timp, dacă Google accesează cu crawlere site-ul dvs. și întâlnește adresa URL, aceasta va fi reindexată, cu excepția cazului în care a fost redirecționată sau blocată de o etichetă robots. Dacă aveți mai multe adrese URL care au în comun un prefix, puteți trimite și prefixul pentru a elimina temporar toate adresele URL din indexul Google.

După șase luni, Google va încerca să acceseze cu crawlere adresele URL din nou. Dacă le-ați redirecționat sau nu le-ați indexat corect, acestea nu vor mai apărea pe pagina cu rezultatele motorului de căutare (SERP).
Aveți nevoie de ajutor pentru a identifica problemele tehnice SEO?
Doriți să îmbunătățiți capacitatea site-ului dvs. de a se clasa? Colaborați cu o agenție SEO cu date care va lucra cu dvs. pentru a identifica problemele tehnice SEO pe site-ul dvs. și pentru a dezvolta o strategie SEO câștigătoare care să vă ajute să urcați în SERP-urile. Rezervă o consultație SEO gratuită astăzi și vezi ce putem face pentru tine!