
SEO de contenu dupliqué : Comment vérifier le contenu dupliqué
Publié: 2022-06-14Le contenu dupliqué peut avoir un impact sur les pages qui apparaissent dans les résultats de recherche et gaspiller votre budget de crawl. Heureusement, il existe des moyens d'identifier le contenu en double et de le supprimer de votre site Web ou de l'index de Google pour l'empêcher d'affecter négativement votre capacité à vous classer.
Qu'est-ce que le contenu dupliqué ?
Le contenu dupliqué se produit lorsque le même contenu apparaît à plusieurs endroits avec une URL unique.
Le contenu n'a pas besoin d'être une correspondance exacte pour être enregistré comme étant dupliqué - il peut également être ce que Google appelle "sensiblement similaire". Ce contenu est essentiellement "suffisamment proche" pour être considéré comme un contenu en double, même si certains textes peuvent différer.
La plupart des propriétaires de sites travaillent dur pour s'assurer que leur contenu est frais et original, et pourtant il y a encore beaucoup de contenu en double sur le Web. Parfois, les propriétaires de sites n'en sont même pas conscients. Alors, comment cela se passe-t-il ?
Pourquoi le contenu dupliqué se produit-il ?
La plupart des contenus dupliqués sur le Web sont dus à l'indexation d'éléments tels que les versions imprimables des pages, les produits qui se trouvent sur ou sont liés par plusieurs URL différentes et les forums de discussion qui génèrent des versions de bureau et mobiles simplifiées de la même page. .
Mais ce ne sont pas les seules façons de vous retrouver avec du contenu en double sur votre site. Voici quelques exemples supplémentaires de la manière dont le contenu dupliqué peut se produire en interne sur votre site et en externe sur d'autres sites.
Doublons générés en interne
Pages de produits sensiblement similaires
Parfois, il peut être judicieux de créer intentionnellement des pages sensiblement similaires, en particulier dans le commerce électronique. Par exemple, supposons que vous vendiez le même produit dans deux pays différents. Dans ce cas, vous pouvez choisir d'avoir deux pages presque identiques, sauf que l'une peut afficher le prix en dollars américains tandis que l'autre l'affiche en dollars canadiens.
Un autre exemple est celui des pages de produits qui semblent sensiblement similaires car elles présentent la même copie, les seules différences réelles étant une image de produit, un nom de produit et un prix de produit différents.
Systèmes de gestion de contenu
Parfois, les systèmes de gestion de contenu créent du contenu en double dont vous n'êtes peut-être même pas conscient. Certains systèmes ajoutent automatiquement des balises et des paramètres d'URL pour les recherches, ce qui entraîne plusieurs chemins vers exactement le même contenu.
Variantes d'URL
Vous pouvez également vous retrouver avec du contenu en double si vous avez différentes variantes d'URL qui présentent le même contenu. Comme mentionné précédemment, les systèmes de gestion de contenu peuvent le faire eux-mêmes, et vous pouvez vous retrouver avec deux variantes d'URL comme https://www.website.com/blog1 et https://www.website.com/blogs/blog1 . D'autres variantes d'URL telles que les barres obliques finales ou les URL en majuscules peuvent causer le même problème.
Lorsque cela se produit, Google peut ne pas savoir quelle page classer et certaines sources externes peuvent créer un lien vers l'une de ces pages tandis que d'autres renvoient vers le doublon, brisant ainsi l'équité des liens de votre page.
HTTP vs HTTPS et www vs non-www
La plupart des sites Web sont accessibles avec ou sans www ou via des URL HTTP ou HTTPS. Toutefois, si vous n'avez pas correctement configuré votre site, Google peut indexer des pages de plusieurs d'entre eux, ce qui entraînera un contenu en double.
URL compatibles avec les imprimantes et les mobiles
Les pages imprimables ou adaptées aux mobiles hébergées à des URL différentes de la page d'origine entraîneront un contenu dupliqué à moins qu'elles ne soient correctement non indexées.
ID de session
Les identifiants de session peuvent être des outils précieux pour suivre les visiteurs qui consultent votre site. Cela se fait généralement en ajoutant une longue chaîne d'ID de session à l'URL. Étant donné que chaque ID de session est unique, cela crée une nouvelle URL et duplique votre contenu.
Paramètres UTM
Les paramètres peuvent suivre les visiteurs entrants provenant de diverses sources. Comme les identifiants de session, ils génèrent des URL uniques bien que le contenu de la page soit le même, créant ainsi un contenu en double s'il est indexé.
Doublons générés en externe
Contenu syndiqué
La syndication de votre contenu sur d'autres sites Web peut être un excellent moyen de générer davantage de trafic vers votre site Web et de faire connaître votre nom. Cependant, ce contenu peut toujours apparaître comme contenu en double s'il n'est pas formaté avec les balises d'en-tête canoniques appropriées. Par exemple, l'utilisation de balises canoniques sur des articles Medium peut empêcher votre contenu d'origine de s'enregistrer en tant que doublon.
Plagiat
Bien que la plupart des contenus dupliqués ne soient pas malveillants par nature, certains webmasters copient délibérément du contenu, cherchant à tirer parti d'un contenu qu'ils n'ont pas produit eux-mêmes.
SEO de contenu dupliqué : pourquoi est-ce important ?
Si le contenu dupliqué se produit si fréquemment, pourquoi est-ce important ? Voici cinq façons dont cela peut avoir un impact sur votre capacité à bien vous classer dans les résultats de recherche.
1. Pénalité de contenu en double de Google
Google ne pénalise pas directement le contenu dupliqué, la plupart du temps. Si Google estime que le contenu dupliqué sur votre site est "trompeur" et "destiné à manipuler les résultats des moteurs de recherche", il peut alors prendre des mesures en appliquant une pénalité pour contenu dupliqué. Ainsi, même si cela n'arrive pas souvent, selon les directives de Google sur le contenu en double, vous pouvez toujours vous retrouver avec une pénalité directe si votre contenu en double est suffisamment flagrant et que vous pensez qu'il a été créé avec une intention malveillante.
Une pénalité de Google pour le contenu dupliqué est rare, donc la préoccupation la plus urgente est la relation entre le contenu dupliqué et le référencement.
2. Ballonnement de l'index
Le gonflement de l'index se produit lorsque les robots des moteurs de recherche accèdent et indexent du contenu sans importance ou de mauvaise qualité, comme ces pages imprimables que j'ai mentionnées. Cela a un impact sur votre capacité à classer vos pages importantes, car les moteurs de recherche ne sauront pas quelle version de votre contenu suggérer aux utilisateurs et peuvent classer une version différente de celle que vous préférez. Cela a également un impact sur le budget de crawl.
3. Budget d'exploration
Google limite le temps qu'il passe à explorer les sites. La quantité de ressources que Google fournit pour explorer et indexer votre site correspond à votre budget d'exploration. Lorsque vous avez beaucoup de contenu dupliqué, vous risquez de gaspiller votre budget de crawl sur des pages moins importantes.
4. Cannibalisation des mots-clés
Si plusieurs copies d'une page sont classées, vos pages seront en concurrence les unes avec les autres pour les mêmes mots clés et la même visibilité. C'est déjà assez difficile de rivaliser avec tout le monde, pourquoi rendre cela plus difficile en rivalisant également avec soi-même ?
En fin de compte, vous ne pouvez pas simplement ignorer les problèmes de contenu en double SEO. Dans la mesure du possible, essayez de consolider ou de supprimer le contenu en double.
5. Diminution de l'équité des liens
Disons que Google décide de classer deux de vos pages sensiblement similaires. Comment savent-ils s'il faut attribuer toute la valeur du contenu à une seule page ou si l'autorité, l'équité du lien et la confiance doivent plutôt être réparties entre les deux pages ? Cette situation peut réduire la valeur SEO de votre contenu, entraînant une sous-performance.
L'équité des liens de vos backlinks sera également répartie entre les deux pages selon que d'autres sites choisissent ou non d'établir un lien.
Comment vérifier le contenu en double sur votre propre site
Trouver du contenu en double sur votre site est gratuit et facile. Utilisez les versions gratuites de Screaming Frog et Siteliner pour explorer méthodiquement votre site et identifier les pages exactes ou presque en double.
Comment utiliser Screaming Frog pour découvrir le contenu en double
Screaming Frog est un robot d'exploration de site Web et un outil d'audit SEO qui peut vous aider à identifier les problèmes de contenu en double sur votre site Web. Voici comment utiliser Screaming Frog pour analyser gratuitement jusqu'à 500 URL.
1. Explorez votre site avec SEO Spider
Tout d'abord, téléchargez et ouvrez Screaming Frog. Tapez l'URL du site Web que vous souhaitez explorer dans le champ "Entrez l'URL de Spider", puis cliquez sur "Démarrer".
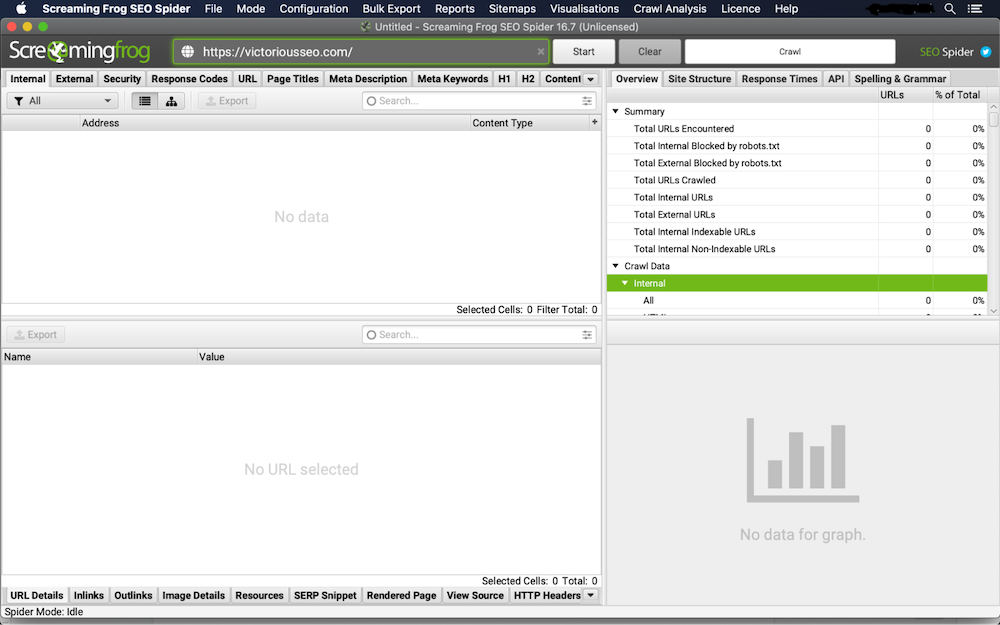
2. Vérifiez les doublons dans l'onglet "Contenu"
Cliquez sur l'onglet "Contenu" pour vérifier les doublons exacts et les quasi-doublons. Vous serez en mesure de voir les doublons exacts en temps réel, mais vous devez effectuer une « analyse d'exploration » pour voir la liste des quasi-doublons.

3. Vérifiez les quasi-doublons
Cliquez sur l'onglet "Crawl Analysis" dans la barre de menu et choisissez "Start" dans le menu déroulant.
Une fois l'analyse de crawl terminée, vous verrez les colonnes remplies presque en double. Vous saurez que c'est terminé car la barre de progression "analyse" affichera 100 % et le filtre quasi-dupliqué n'affichera plus le message "analyse d'exploration requise".
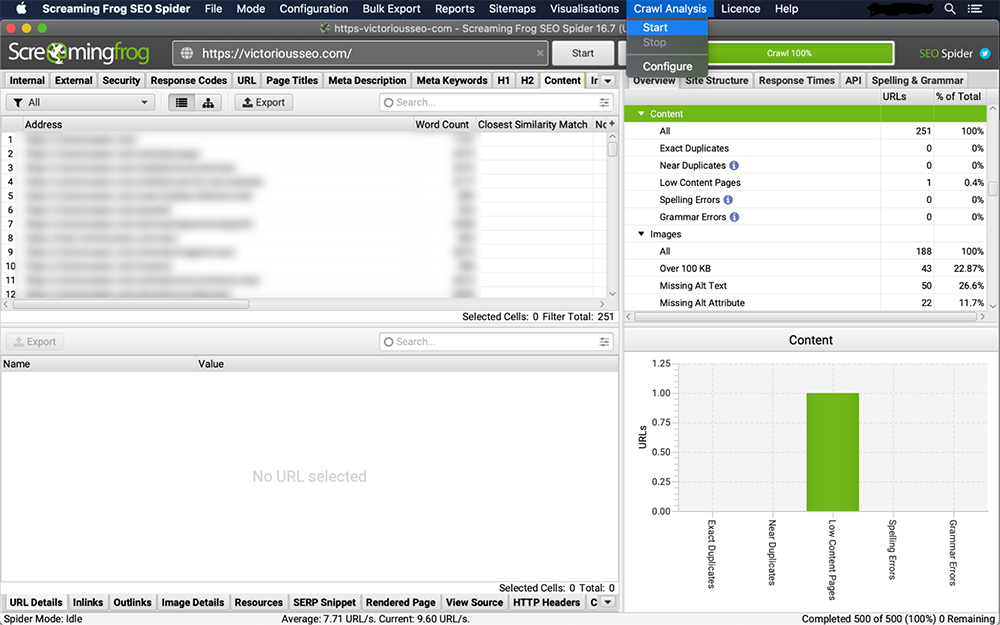
4. Afficher les doublons sous l'onglet "Contenu"
La « correspondance de similarité la plus proche », « Non ». Les colonnes "Near Doublons" et "Adresse" seront renseignées une fois l'analyse d'exploration terminée.

Le filtre 'Exact Duplicates' affichera les pages qui sont identiques les unes aux autres sur la base d'un scan de code HTML. Le seuil de similarité défini détermine ce qui est qualifié de "quasi-doublons". Pour modifier le seuil, allez dans 'Config → Spider → Content. Ce seuil est défini sur 90 % par défaut, mais vous êtes libre de le modifier à votre guise.
Maintenant que l'analyse est terminée, examinez manuellement toute page qui apparaît comme un doublon exact ou presque.
Comment utiliser Siteliner pour découvrir le contenu en double
Siteliner est un autre outil gratuit que vous pouvez utiliser pour analyser votre site Web (ou n'importe quel site Web) à la recherche de contenu dupliqué. Cependant, la version gratuite vous limitera à une utilisation tous les 30 jours et limitera le nombre de résultats à 250 pages. Si vous devez effectuer plusieurs recherches ou souhaitez voir plus de résultats, inscrivez-vous à la version premium.
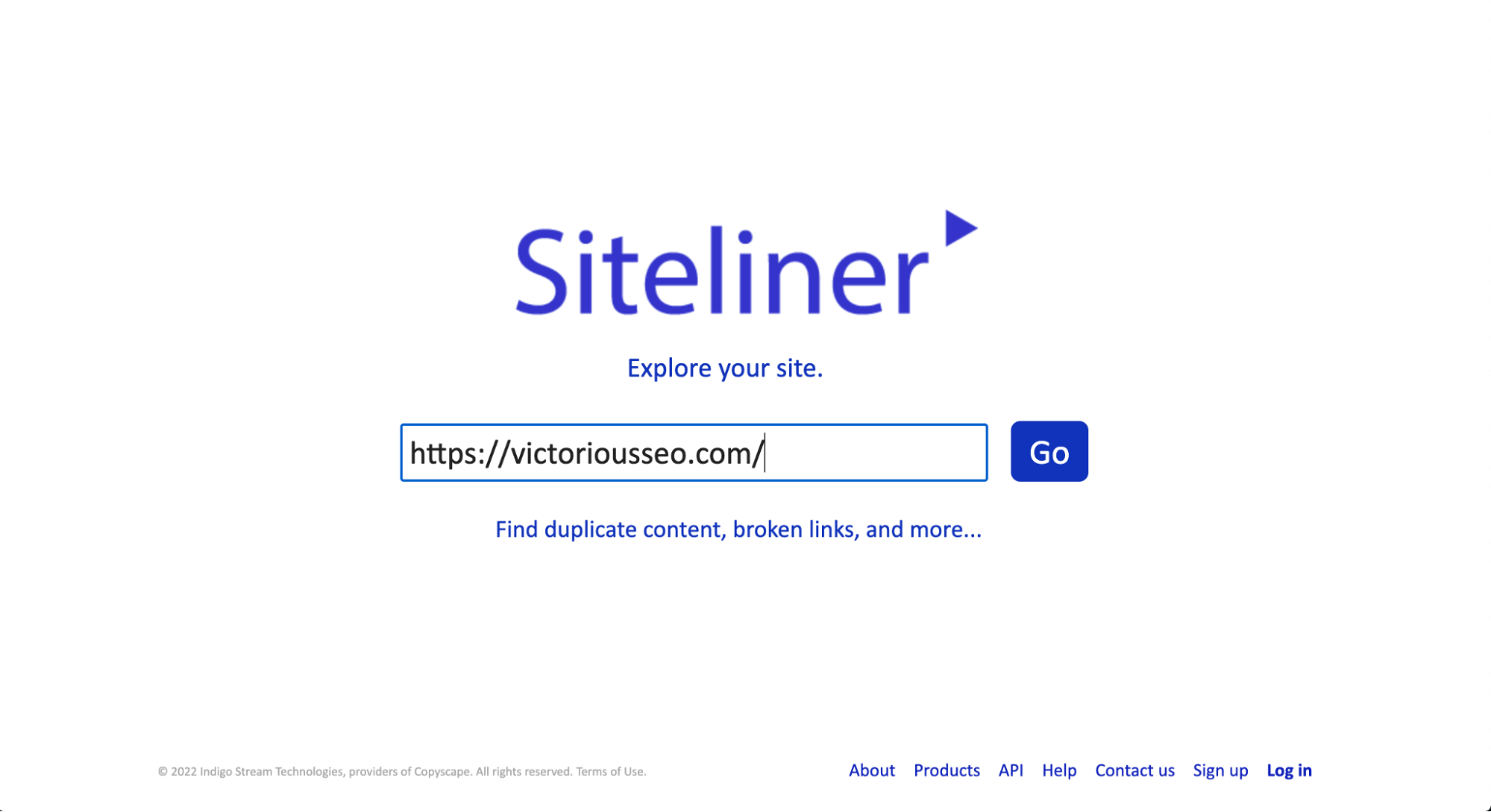
Pour vérifier le contenu en double avec Siteliner, entrez simplement l'URL que vous souhaitez rechercher dans la zone de recherche sur leur page d'accueil.
Siteliner effectuera ensuite un balayage du site et vous dira combien de contenu en double a été trouvé et mettra en évidence ce qu'il pense être vos principaux problèmes. Il affichera également plusieurs autres mesures, dont certaines peuvent être utiles pour le référencement, comme le temps de chargement moyen des pages, les liens internes et externes et les liens entrants.
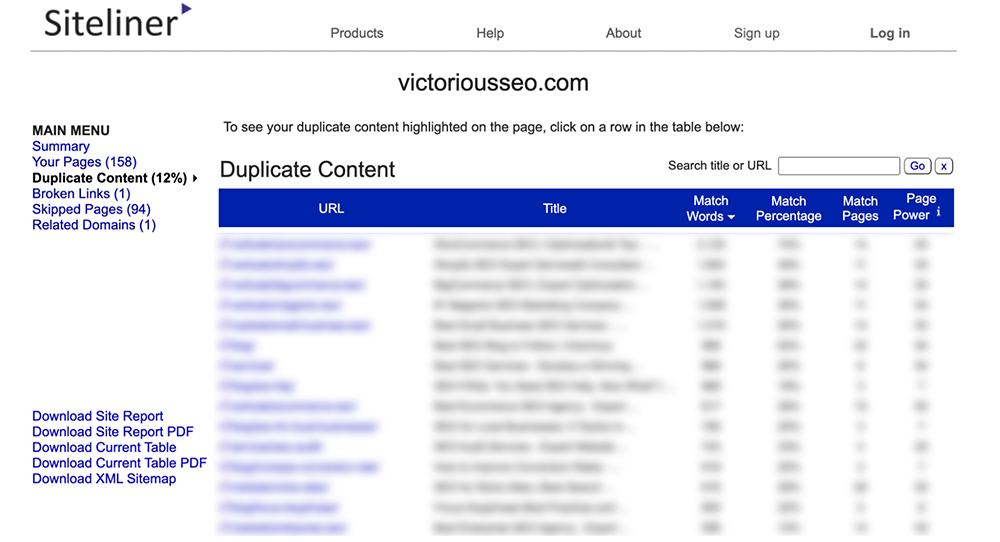
Dans le menu principal, cliquez sur "Contenu en double" pour voir quelles pages Siteline identifie comme ayant un contenu en double.
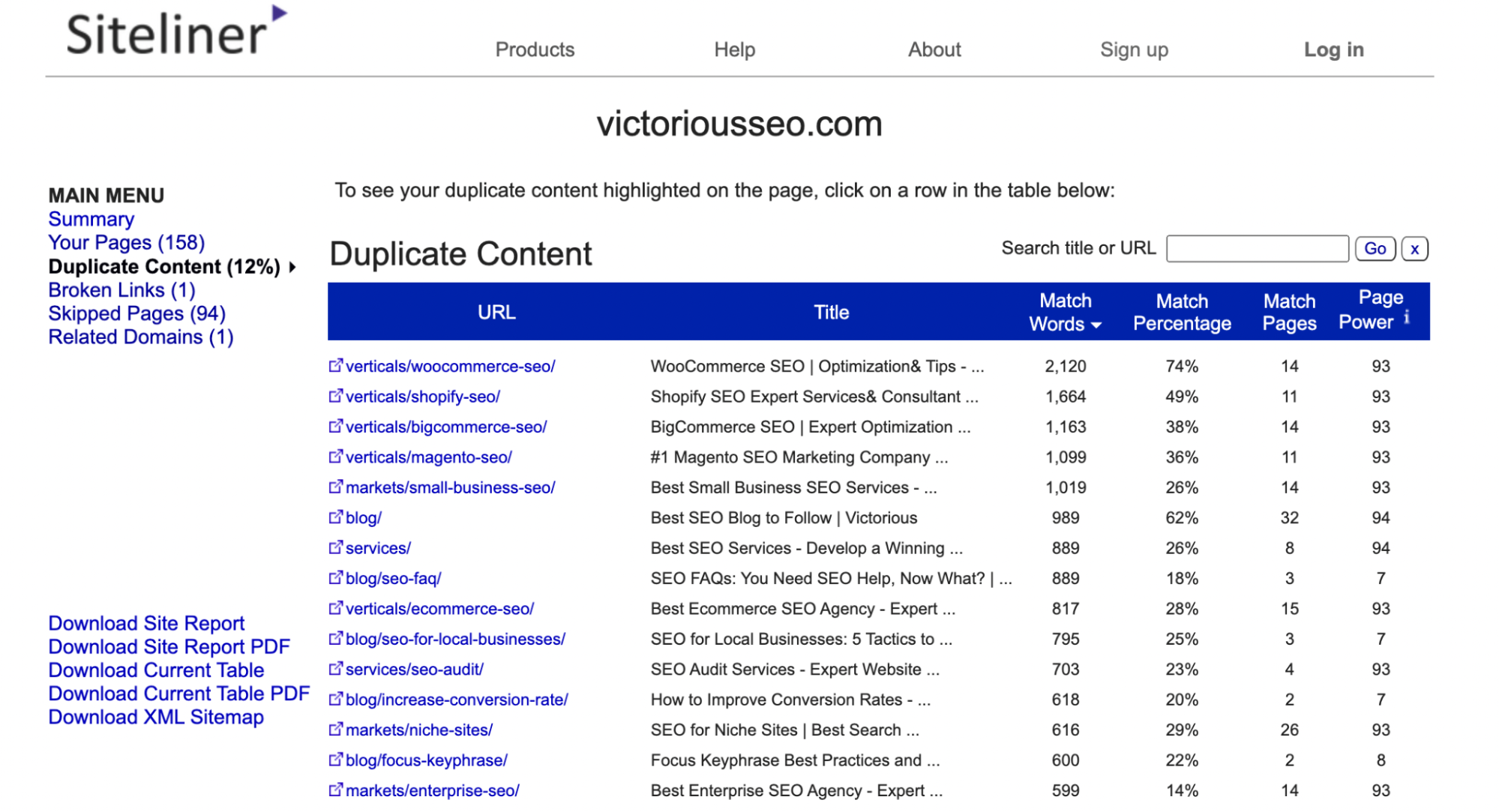
Cliquez sur chaque ligne pour voir quel texte est marqué comme dupliqué.
Remarque : Siteline identifiera les en-têtes et les pieds de page qui apparaissent sur plusieurs pages comme du contenu en double. Vous pouvez donc obtenir de nombreuses pages qui ont un faible pourcentage de correspondance, car elles partagent chacune le même contenu de menu ou de pied de page.
Comment vérifier si quelqu'un d'autre a copié votre contenu
Il existe également des outils de recherche de contenu en double que vous pouvez utiliser pour vérifier si quelqu'un d'autre sur le Web a copié votre contenu. Copyscape est un outil de vérification de contenu de site Web gratuit, efficace et facile à utiliser.
Insérez simplement une URL dans le champ de recherche et cliquez sur le bouton "Aller" juste à côté. Copyscape effectuera ensuite une recherche sur l'ensemble du Web pour voir si un contenu textuel similaire existe ailleurs.

S'il trouve quelque chose, Copyscape renverra les résultats et les organisera dans une liste qui ressemble un peu aux résultats de recherche de Google. Cela vous permet de les parcourir facilement et de voir à quel point votre contenu a été copié. Vous pouvez le considérer comme un vérificateur de contenu en double de Google.
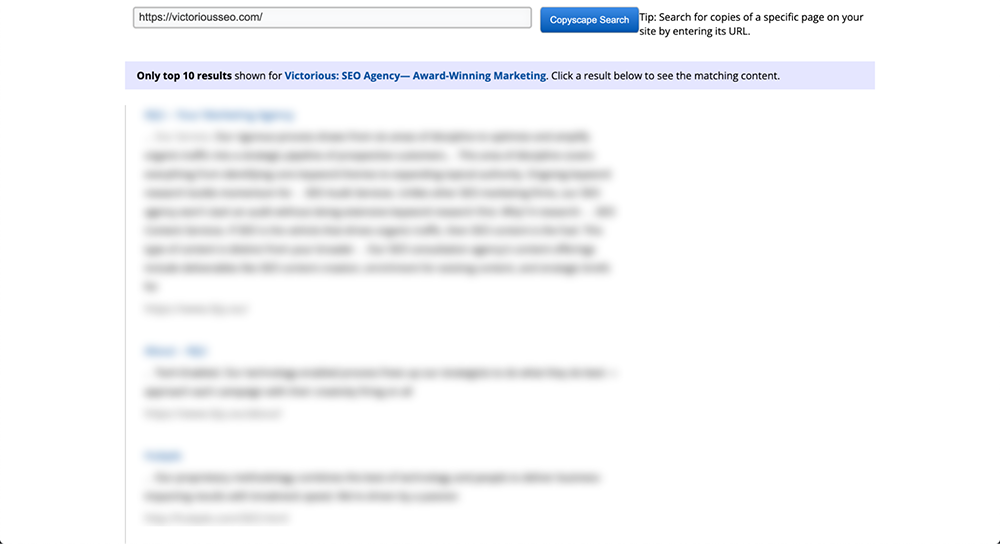
Que pouvez-vous faire si vous découvrez que quelqu'un d'autre a plagié votre contenu ?
Tout d'abord, contactez le propriétaire du site Web et demandez-lui de supprimer le contenu ou d'ajouter un lien canonique vers le contenu original de votre site Web. Si cela ne fonctionne pas, envoyez une demande de retrait DMCA à Google.
Remarque : Si vous avez intentionnellement syndiqué votre contenu et autorisé d'autres sites Web à le publier, il apparaîtra toujours comme un doublon. C'est pourquoi il est important d'exiger que le site de publication inclue un lien canonique ou une balise noindex sur la page afin de l'empêcher de concurrencer votre propre page dans les classements des moteurs de recherche.
Comment réparer le contenu dupliqué
Pour résoudre les problèmes de contenu en double, identifiez la copie que vous souhaitez que Google reconnaisse comme la version d'origine. Vous devrez également décider si vous souhaitez supprimer complètement les pages en double ou si vous souhaitez simplement dire à Google de ne pas les indexer. Selon ce que vous décidez, il existe plusieurs façons de nettoyer votre contenu en double.
Noindex avec balises Meta Robots et Robots.txt
Une façon de minimiser l'impact du contenu dupliqué sur votre référencement consiste à désindexer manuellement toutes les pages en double en modifiant vos balises meta robots. Pour ce faire, utilisez la balise meta robots et définissez ses valeurs sur "noindex, follow". Appliquez cette balise à l'en-tête HTML de chaque page que vous souhaitez exclure des résultats de recherche.
La balise meta robots permet aux moteurs de recherche d'explorer les liens de la page sur laquelle elle est appliquée, mais empêche les robots de recherche de les inclure dans leurs index.
Pourquoi autoriser Google à explorer la page si vous ne voulez pas qu'elle soit indexée ? Parce que Google a explicitement mis en garde contre la restriction de l'accès d'exploration à tout contenu en double sur votre site. Ils veulent savoir que c'est là, même si vous ne voulez pas qu'ils l'indexent.
Une balise noindex devrait ressembler à ceci lorsqu'elle est appliquée à votre code HTML :
<head> [code] <meta name="robots" content=”noindex, follow”> [autre code si nécessaire] </head>
La balise meta robots est un moyen simple et efficace de désindexer le contenu dupliqué et d'éviter d'éventuels problèmes de référencement liés à la présence de pages en double sensiblement similaires ou exactes sur votre site Web.
Si vous avez des répertoires entiers dont vous souhaitez bloquer l'indexation par Google et d'autres moteurs de recherche, modifiez votre fichier robots.txt.
Redirections 301
Une autre façon de gérer un problème de contenu dupliqué consiste à utiliser une redirection 301. Les 301 sont des redirections permanentes qui redirigent le trafic de la page dupliquée vers une autre URL. Les redirections 301 sont optimisées pour le référencement et vous aident à combiner plusieurs pages en une seule URL afin de consolider leur équité en matière de liens.
Lorsque vous utilisez une redirection 301, la page en double ou sensiblement similaire n'acceptera plus de trafic, alors utilisez-la uniquement lorsque vous êtes d'accord avec la page en double qui n'est plus accessible, comme lors de l'élagage du contenu. Si vous souhaitez toujours que la page soit accessible, utilisez une balise meta robots pour la noindexer.
Rel canonique
Une autre façon de gérer votre contenu dupliqué consiste à utiliser l'attribut rel=canonical pour hiérarchiser les pages. Placez l'attribut rel=canonical à l'intérieur de la balise HTML <head> pour indiquer aux moteurs de recherche qu'une page spécifique existe en tant que copie d'une autre page et que tous les liens et la puissance de classement qui appartiennent à cette page doivent en fait être attribués à la balise canonique page.
Une balise rel=canonical ressemble à ceci lorsqu'elle est appliquée à votre code HTML :
<head> [code] <link href=”URL DE LA PAGE PRIORISÉE” rel=”canonical” /> </head>
Vous pouvez également utiliser une balise canonique auto-référentielle pour indiquer que vous souhaitez qu'une page particulière soit traitée comme la version originale.
Supprimer les URL de votre sitemap XML
Votre sitemap XML ne doit inclure que les URL que vous souhaitez indexer. Si vous n'utilisez pas d'URL dynamique qui met automatiquement à jour votre sitemap, vous devrez modifier manuellement votre sitemap et supprimer toutes les URL que vous n'indexez pas ou redirigez.
Supprimer l'URL dans Google Search Console
Si vous choisissez de rediriger une page ou de restreindre l'indexation, demandez à Google de supprimer cette URL de son index.
Connectez-vous à votre console de recherche Google et sélectionnez "Suppressions" dans le menu de gauche.
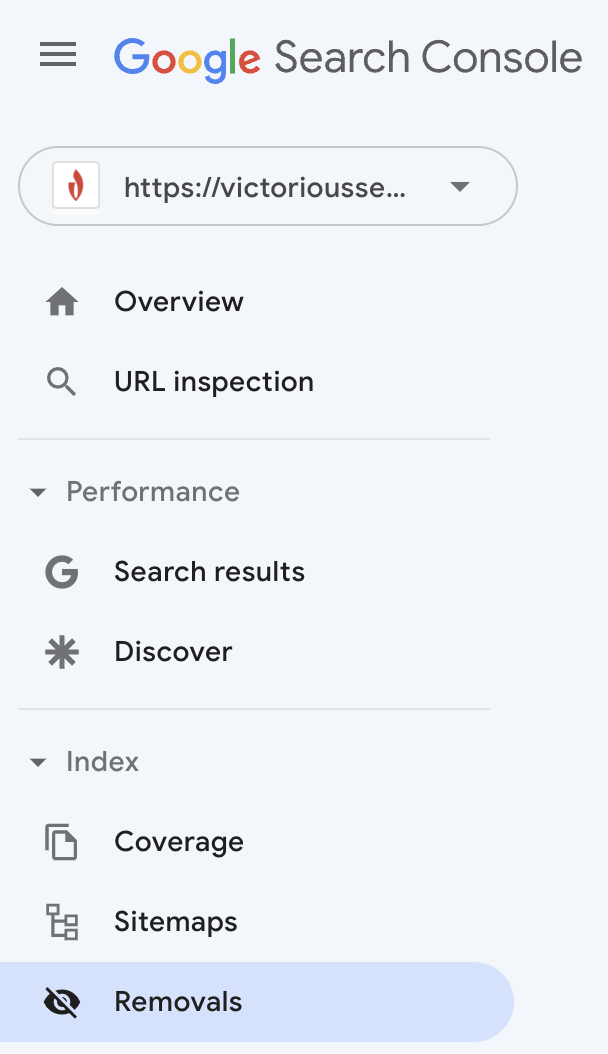
Une boîte apparaîtra pour vous informer que la soumission d'une URL la supprimera de l'index de Google pendant seulement six mois. Passé ce délai, si Google explore votre site et rencontre l'URL, celle-ci sera réindexée, sauf si elle a été redirigée ou bloquée par une balise robots. Si vous avez plusieurs URL qui partagent un préfixe, vous pouvez également soumettre le préfixe pour supprimer temporairement toutes les URL de l'index de Google.

Au bout de six mois, Google essaiera à nouveau d'explorer vos URL. Si vous les avez correctement redirigés ou non indexés, ils n'apparaîtront plus sur la page de résultats des moteurs de recherche (SERP).
Besoin d'aide pour identifier les problèmes de référencement technique ?
Vous cherchez à améliorer la capacité de classement de votre site ? Associez-vous à une agence de référencement axée sur les données qui travaillera avec vous pour identifier les problèmes techniques de référencement sur votre site Web et développer une stratégie de référencement gagnante pour vous aider à gravir les SERP. Réservez une consultation SEO gratuite dès aujourd'hui et voyez ce que nous pouvons faire pour vous !